本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
神经网络以被证明当其变得deeper和wider时,性能也会更好。但是计算成本也会越高。因此轻量级的模型受到越来越多的关注。我们研究了一些先进方法(如ResNet、ResNeXt、DenseNet)的计算成本。并进一步开发了可以高效计算的组件,使上述网络能够在不牺牲性能的情况下部署在CPU或移动端GPU上。
我们要介绍的方法称为Cross Stage Partial Network(CSPNet)。CSPNet的主要目的是实现更丰富的梯度组合,同时减少计算量。这一目的的实现是通过将base layer的feature map划分为两部分,然后通过我们提出的跨阶段层次(cross-stage hierarchy)将它们合并起来。我们的主要思路是将梯度流分开,使梯度流通过不同的网络路经传播。此外,CSPNet可以大大减少计算量,提高推理速度和精度,见Fig1。
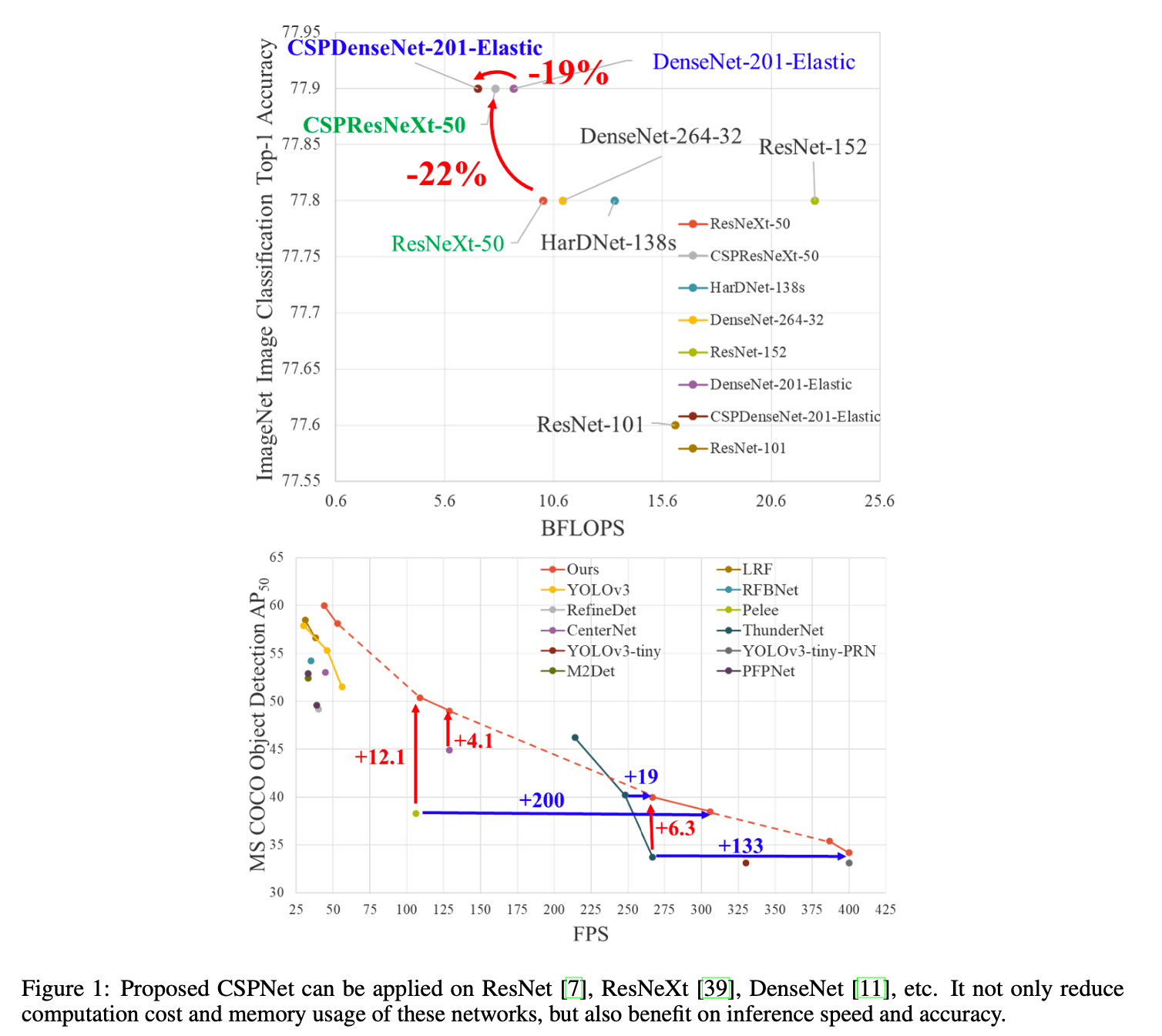
基于CSPNet的目标检测器可以解决以下3个问题:
- Strengthening learning ability of a CNN
- Removing computational bottlenecks
- 过高的计算瓶颈会加长推理过程,或者有一些计算单元会经常空闲。因此,我们希望能够在CNN中均匀地分配每一层的计算量,从而有效地提高每个计算单元的利用率,减少不必要的消耗。在MS COCO目标检测数据集上,对基于YOLOv3的模型进行测试时,我们提出的模型可以有效地减少80%的计算瓶颈。
- Reducing memory costs
- 为了减少内存使用,我们在特征金字塔生成过程中采用了跨通道的池化来压缩feature map。在PeleeNet上应用CSPNet之后,减少了75%的内存使用。
PeleeNet:Robert J Wang, Xiang Li, and Charles X Ling. Pelee: A real-time object detection system on mobile devices. In Advances in Neural Information Processing Systems (NeurIPS), pages 1963–1972, 2018.
我们提出的模型在GTX 1080ti上以109fps实现50% COCO AP$_{50}$,在Intel Core i9-9900K上以52fps实现40% COCO AP$_{50}$。
2.Related work
不再赘述。
3.Method
3.1.Cross Stage Partial Network
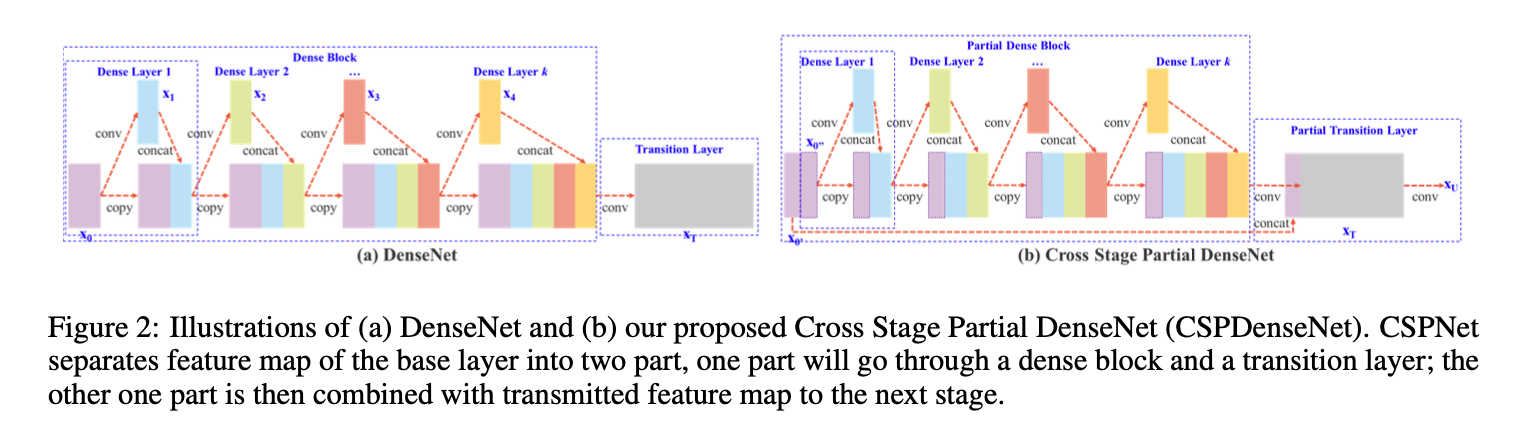
👉DenseNet.
DenseNet一个阶段的结构见Fig2(a)。DenseNet每个阶段包括一个dense block和一个transition layer,其中每个dense block包含$k$个dense layer。网络原理可用如下公式表示:

其中,$*$表示卷积操作,$[x_0,x_1,…]$表示将$x_0,x_1,…$concat在一起,$w_i$是权重,$x_i$是第$i$个dense layer的输出。
如果使用反向传播算法来更新权重,则权重更新的方程可以写成:
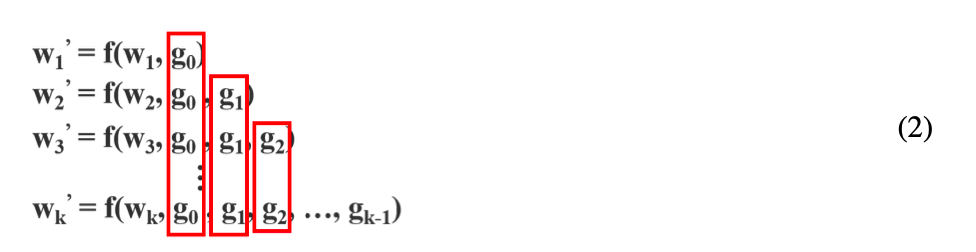
$f$是权重更新的函数,$g_i$表示传播到第$i$个dense layer的梯度。我们可以发现大量的梯度信息被重复用于更新不同dense layer的权重。这将导致不同的dense layer重复的学习这些复制的梯度信息。
👉Cross Stage Partial DenseNet.
我们提出的CSPDenseNet框架中的一个阶段的结构如Fig2(b)所示。CSPDenseNet的一个阶段包括一个partial dense block和partial transition layer。在partial dense block中,将base layer沿着通道方向分成两部分:$x_0 = [x^{‘}_0,x^{‘‘}_0]$。前一部分直接链接到阶段尾部,后一部分正常穿过dense block。CSPDenseNet的前向传播和权重更新公式见下:

用于更新权重的梯度信息,绿框内双方都不包含属于对方的重复梯度信息。
总的来说,CSPDenseNet保留了DenseNet特征复用的优势,但同时通过截断梯度流来防止过多的重复梯度信息。
👉Partial Dense Block.
设计partial dense block的目的是:
- increase gradient path:通过拆分和合并策略,梯度路径的数量可以翻倍。
- balance computation of each layer:通常,DenseNet中base layer的通道数量远大于growth rate。由于partial dense block中dense layer计算所涉及的base layer通道仅占原始数量的一半,因此可以有效解决近一半的计算瓶颈。
- reduce memory traffic:假设base layer的feature map大小为$w \times h \times c$,growth rate为$d$,一个dense block内一共有$m$个dense layer。则一个dense block的CIO为$(c \times m)+((m^2 + m) \times d) / 2$,partial dense block的CIO为$((c \times m) + (m^2 + m) \times d) / 2$。因为$m$和$d$通常远小于$c$,所以partial dense block最多可以节省网络一半的内存占用。
这里介绍下CIO,CIO出自论文“Ping Chao, Chao-Yang Kao, Yu-Shan Ruan, Chien-Hsiang Huang, and Youn-Long Lin. HarDNet: A low memory traffic network. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019.”。CIO全称是Convolutional Input/Output,是一个评估内存占用的指标,是DRAM流量的近似值,和实际的DRAM流量成正比。CIO的计算公式如下:
\[CIO = \sum_l (c_{in}^{(l)} \times w_{in}^{(l)} \times h_{in}^{(l)} + c_{out}^{(l)} \times w_{out}^{(l)} \times h_{out}^{(l)} )\]其中,$c$为feature map的通道数量,$w,h$为feature map的width和height,$l$表示第$l$层。
接下来推导一下dense block的CIO,每一层的计算分别为:
\[w \times h \times c + w \times h \times d\] \[w \times h \times (c + d \times 1) + w \times h \times d\] \[w \times h \times (c + d \times 2) + w \times h \times d\] \[\vdots\] \[w \times h \times (c + d \times (m - 1)) + w \times h \times d\]把上面每一层的计算都加起来便可得到CIO:
\[w \times h \times ( c \times m + \frac{(m^2 + m)d}{2})\]假设partial dense block将base layer按通道平均分成两部分,即只有$\frac{c}{2}$在dense block内传播,则可得到partial dense block的CIO为:
\[w \times h \times ( \frac{ c \times m + (m^2 + m)d}{2})\]👉Partial Transition Layer.
设计partial transition layer的目的是使梯度组合的差异最大化。partial transition layer是一种分层特征融合机制(hierarchical feature fusion mechanism),其通过使用截断梯度流的策略来防止不同层学习重复的梯度信息。我们展示了多种不同的融合策略,见Fig3。
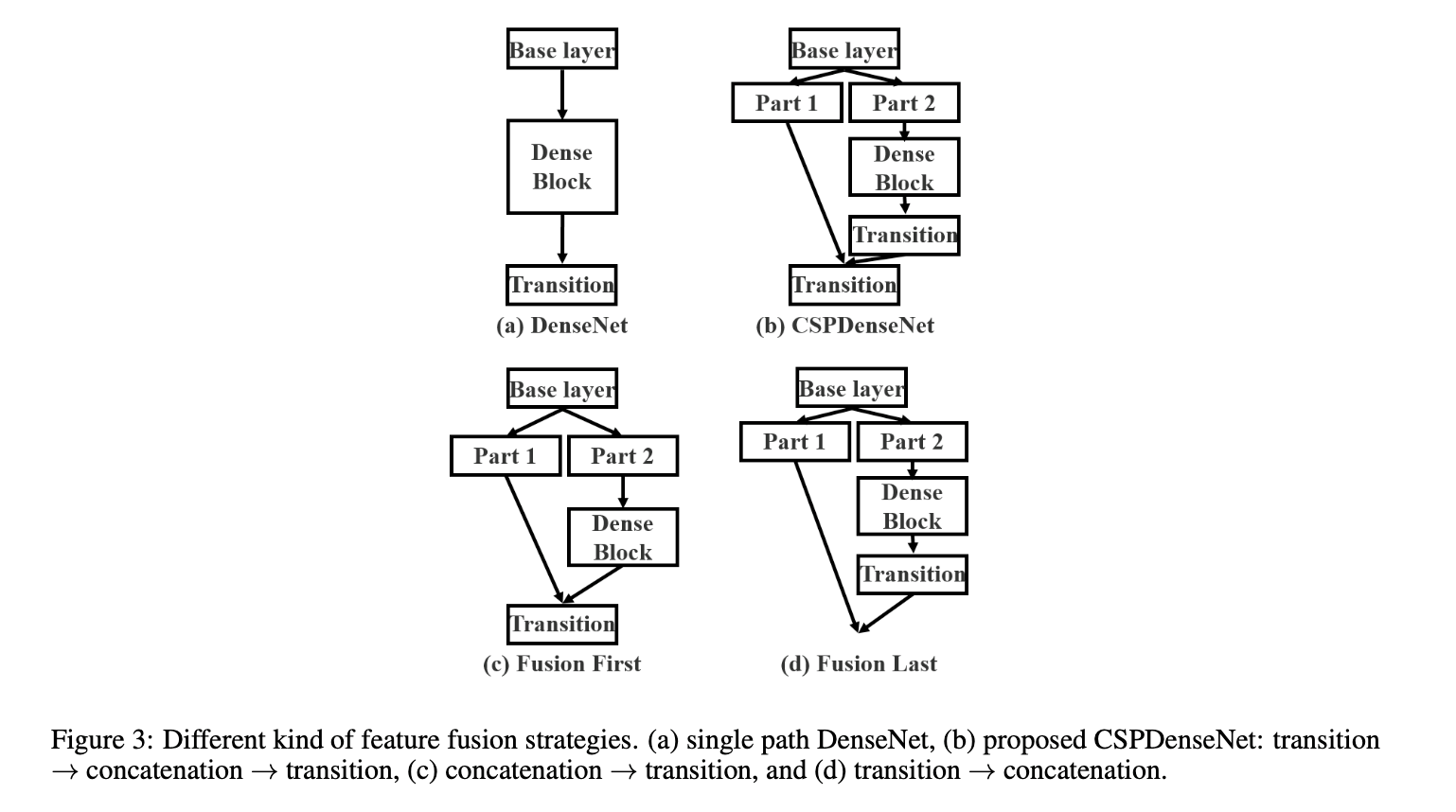
Fig2(b)对应的是Fig3(b)。Fig3(c)将重用大量的梯度信息。Fig3(d)中的梯度信息则不会被重用。如果我们使用Fig3中的四种结构来分别进行图像分类,结果见Fig4。

从Fig4的结果可以看出,如果能够有效地减少重复的梯度信息,网络的学习能力将大大提高。
👉Apply CSPNet to Other Architectures.
CSPNet也可以容易的被应用于ResNet和ResNeXt,见Fig5。
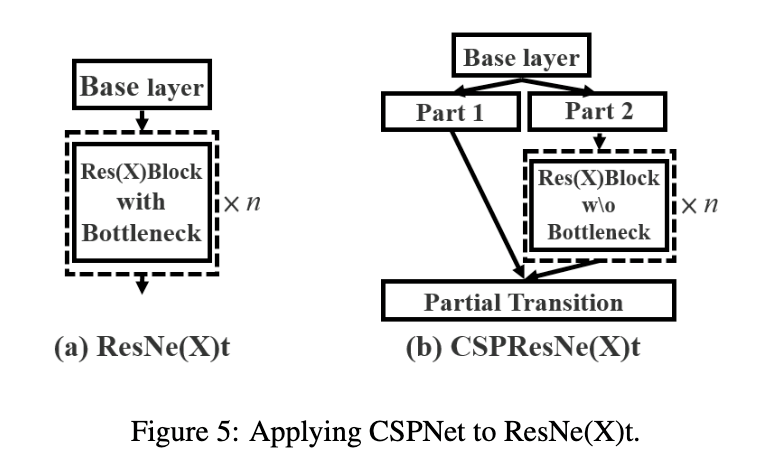
因为只有一半通道的feature map通过Res(X)Blocks,因此不再需要引入bottleneck layer。
3.2.Exact Fusion Model
提出了一种新的融合模型EFM(Exact Fusion Model):
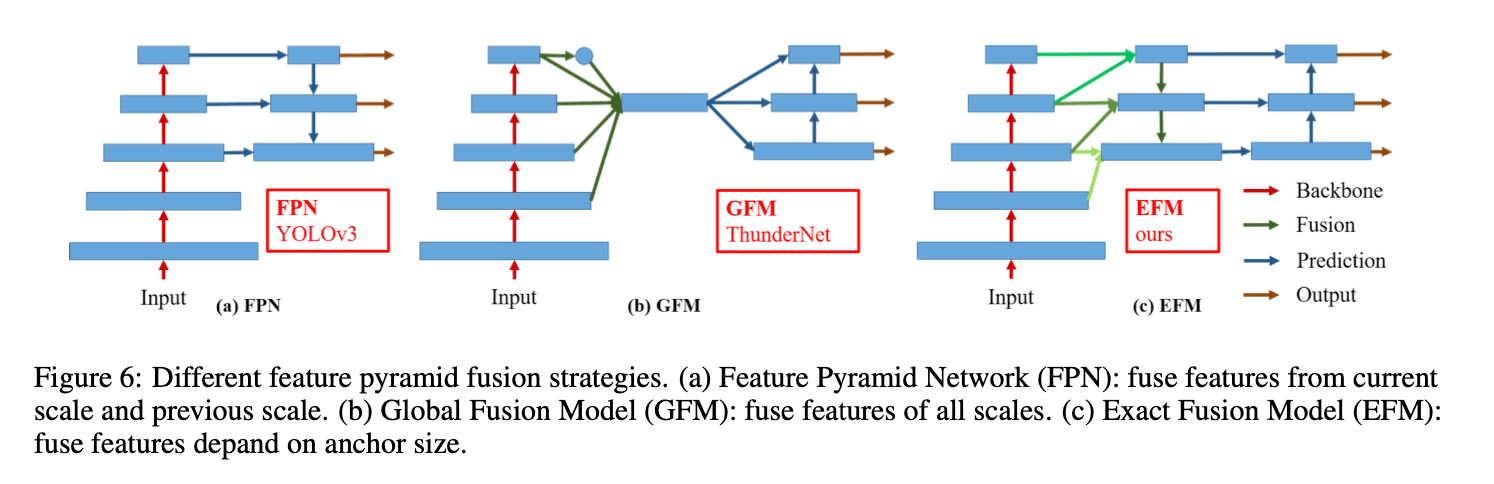
为了降低内存和计算成本,我们结合了Maxout技术来压缩feature map。
4.Experiments
我们使用ILSVRC 2012的ImageNet图像分类数据集来评估CSPNet。用MS COCO目标检测数据集来评估EFM。更多框架细节见附录。
4.1.Implementation Details
👉ImageNet.
针对ImageNet图像分类任务,所有的超参数(比如训练步数、学习率策略、优化器、数据扩展等)都遵循YOLOv3。对于基于ResNet和基于ResNeXt的模型,训练步数设为8000,000。对于基于DenseNet的模型,训练步数设为1,600,000。初始学习率设为0.1,采用多项式衰减策略。momentum=0.9,weight decay=0.005。都使用单个GPU,batch size=128。
👉MS COCO.
针对MS COCO目标检测实验,所有的超参数设置都遵循YOLOv3。训练步数为500,000。在第400,000步和第450,000步时,学习率乘以0.1。momentum=0.9,weight decay=0.0005。使用单个GPU,batch size=64。在COCO test-dev上进行评估。
4.2.Ablation Experiments
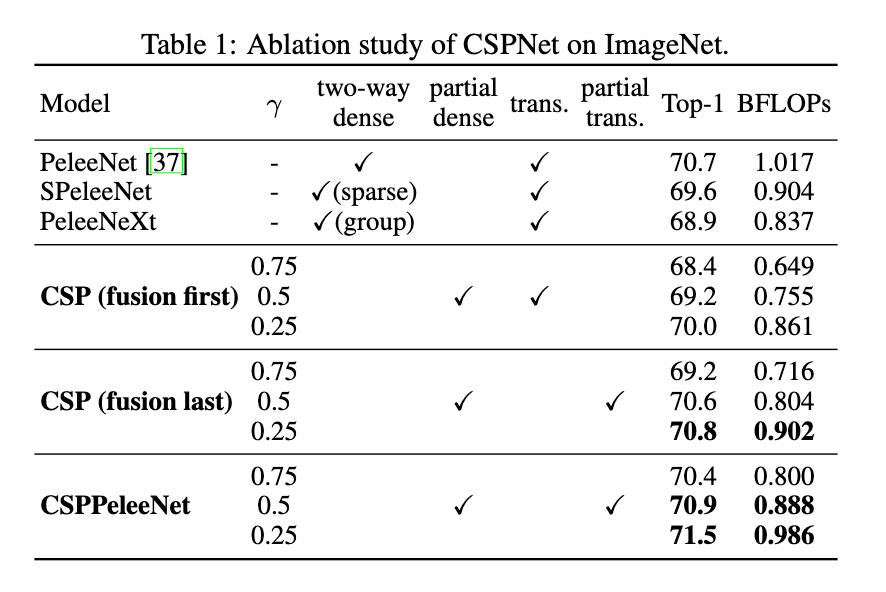
👉Ablation study of CSPNet on ImageNet.
使用PeleeNet作为baseline,使用ImageNet数据集进行评估。在消融实验中,我们测试了不同的分割比例$\lambda$(即对base layer的分割)和不同的特征融合策略。结果见表1。
👉Ablation study of EFM on MS COCO.
我们比较了Fig6中不同的特征金字塔融合策略。我们选择了两个SOTA的轻量级模型:PRN和ThunderNet。所有实验都采用CSPPeleeNet作为backbone。结果见表2。
ThunderNet:Zheng Qin, Zeming Li, Zhaoning Zhang, Yiping Bao, Gang Yu, Yuxing Peng, and Jian Sun. ThunderNet: Towards real-time generic object detection. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019.
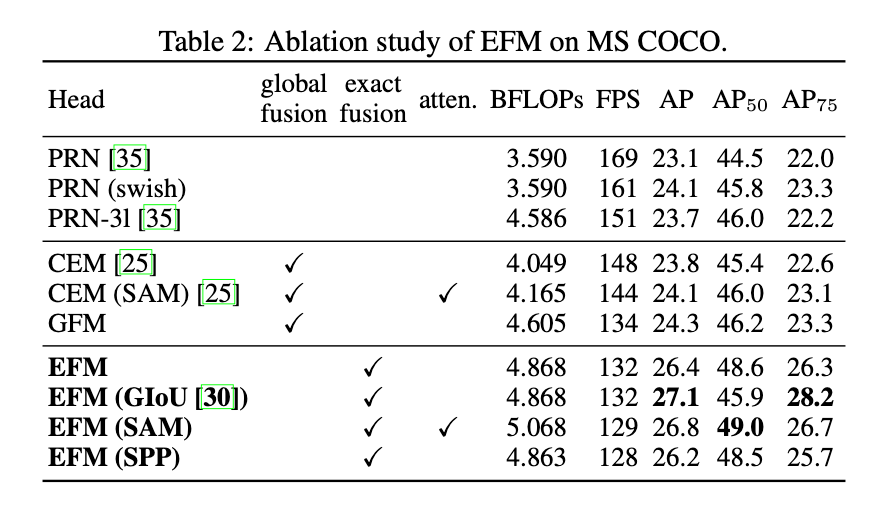
CEM(Context Enhancement Module)和SAM(Spatial Attention Module)是ThunderNet所使用的。GFM是Global Fusion Model。
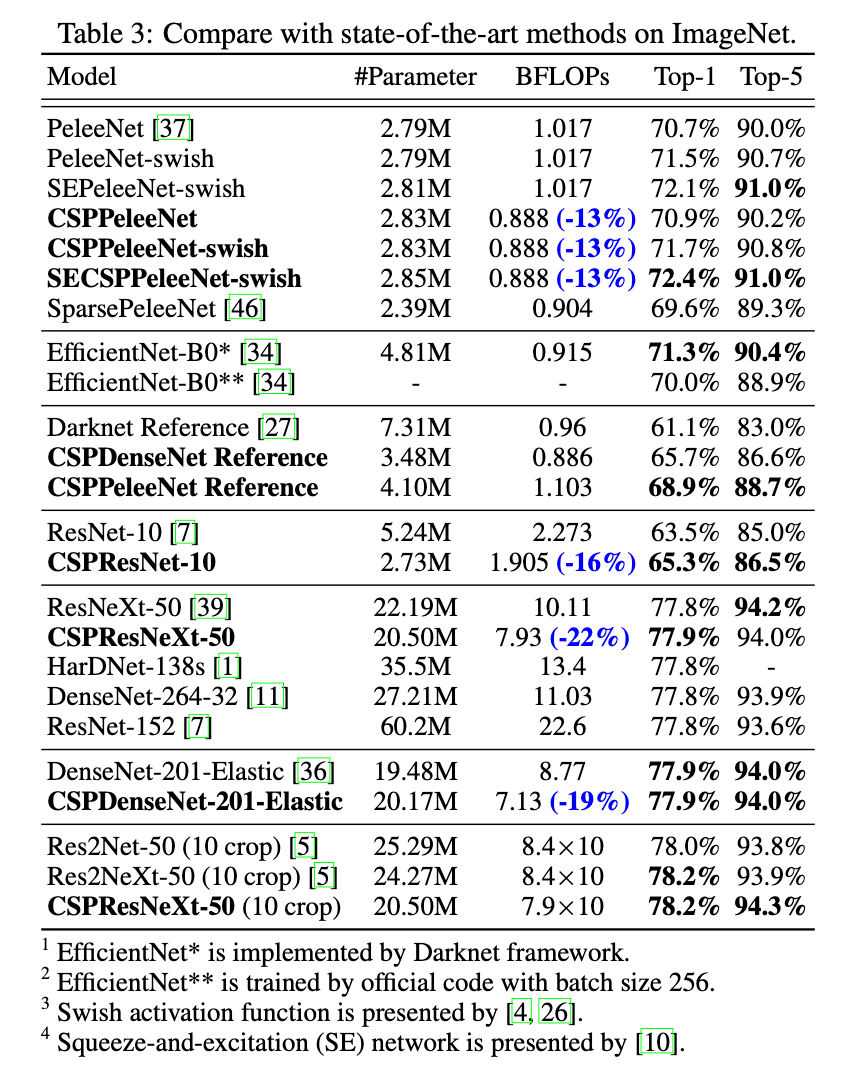
4.3.ImageNet Image Classification
4.4.MS COCO Object Detection
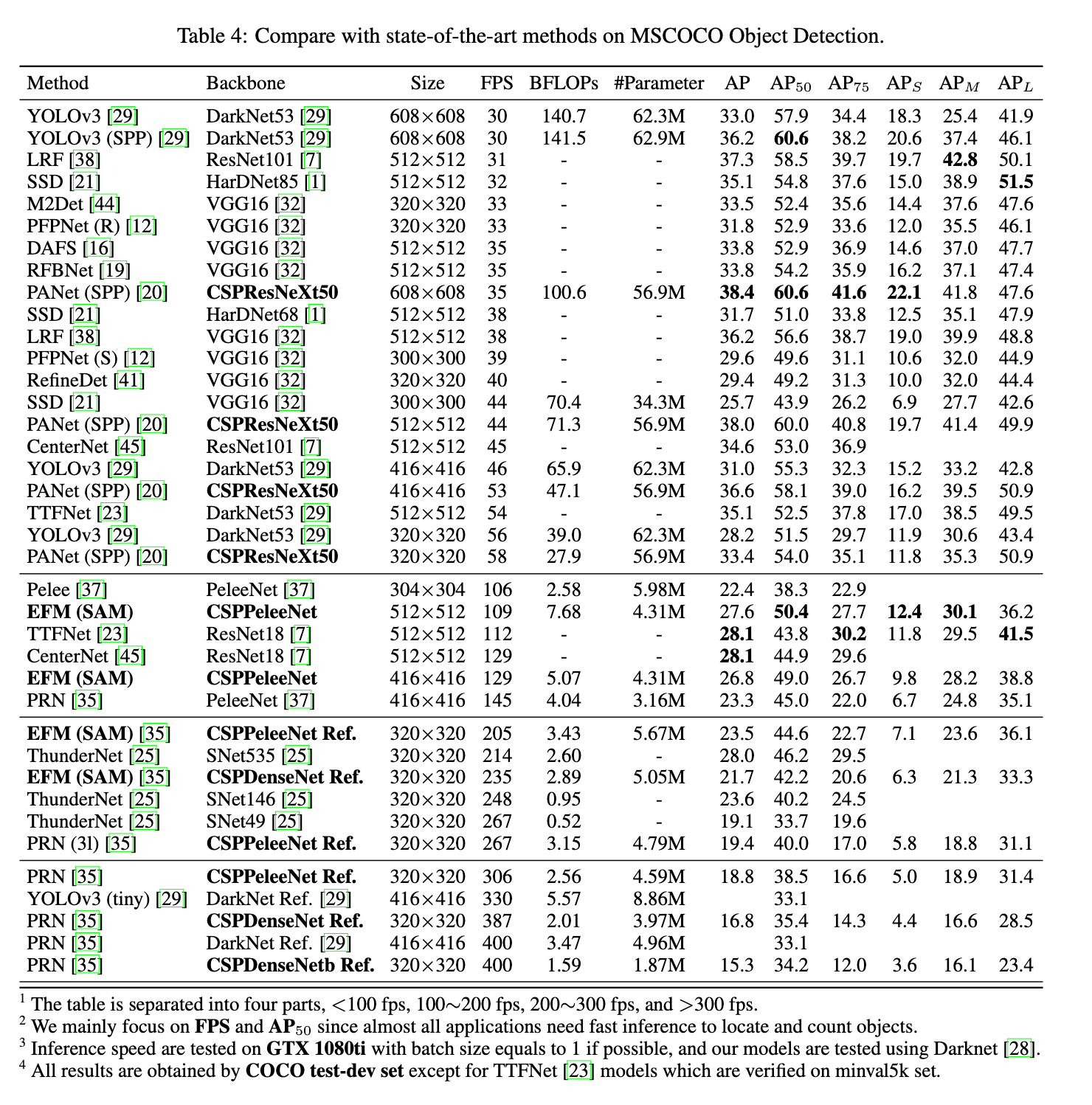
在目标检测任务中,我们主要关注三个场景:1)在GPU上的实时性;2)在移动端GPU上的实时性;3)在CPU上的实时性。结果见表4。
4.5.Analysis
👉Computational Bottleneck.
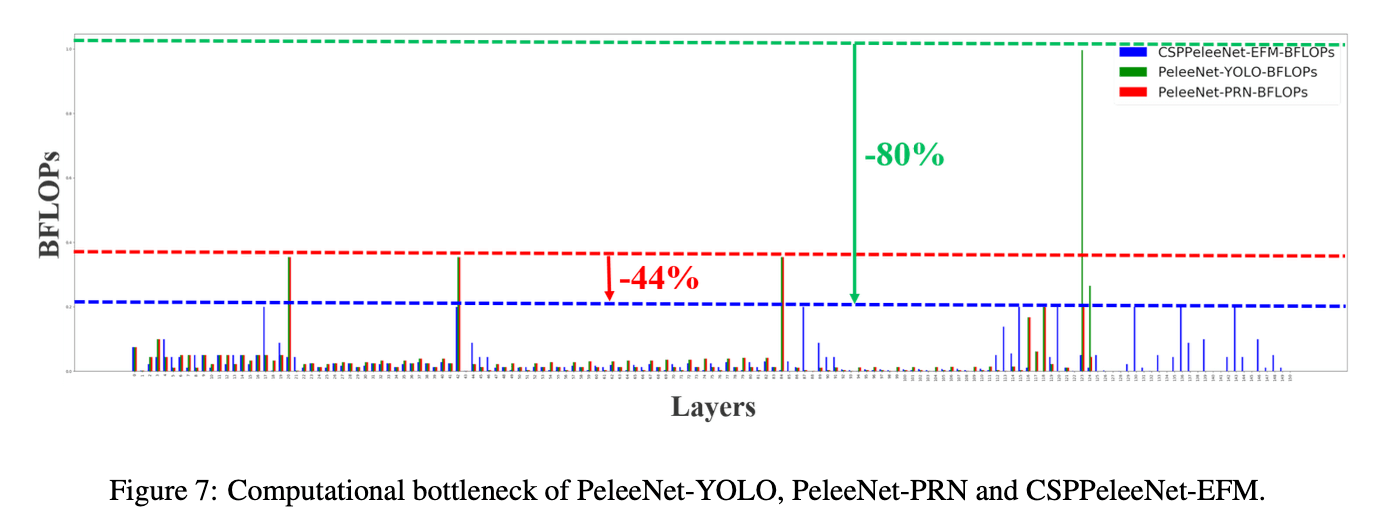
Fig7是PeleeNet-YOLO、PeleeNet-PRN、CSPPeleeNet-EFM中每一层的BLOPS。我们所提出的CSPNet可以为硬件提供更高的利用率。
👉Memory Traffic.
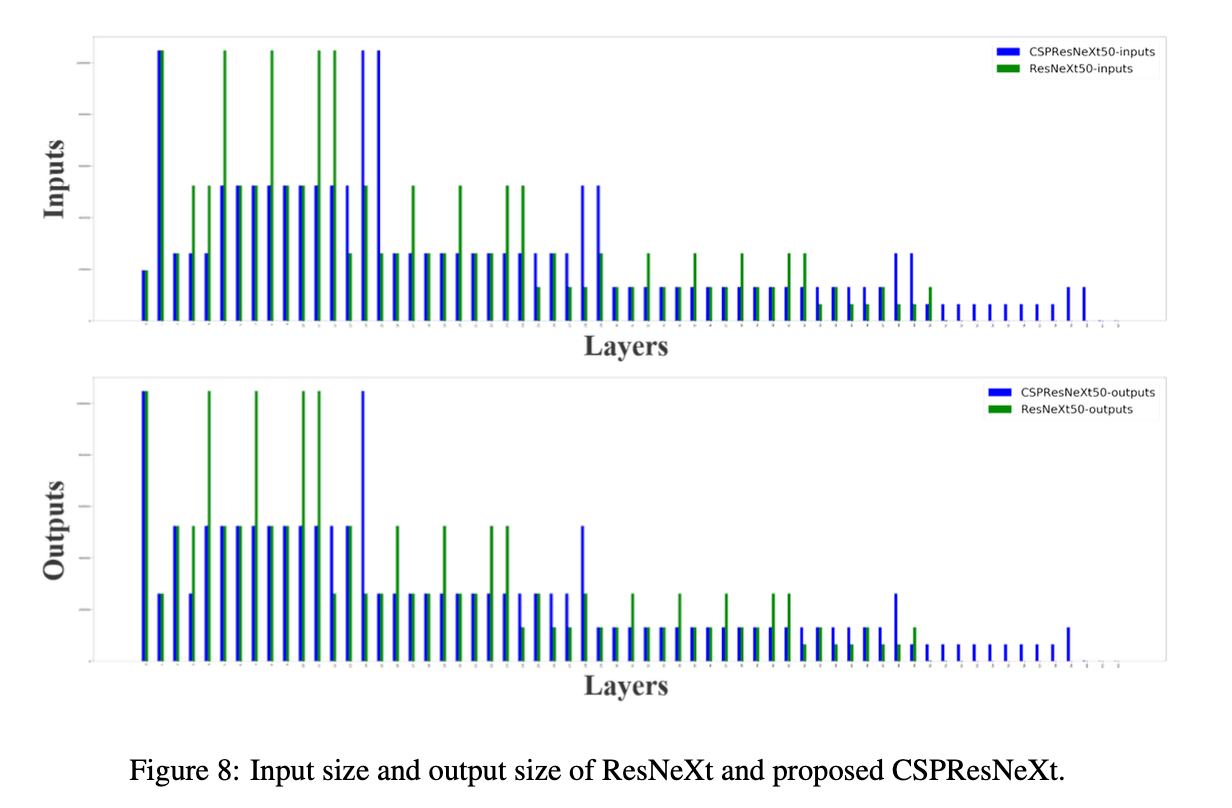
Fig8展示了ResNeXt50和CSPResNeXt50每一层的大小。CSPResNeXt的CIO为32.6M,低于ResNeXt50的34.4M。
👉Inference Rate.
我们进一步评估了我们所提出的方法是否能够部署在移动端的GPU或CPU的实时检测器上。我们的实验基于NVIDIA Jetson TX2和Intel Core i9-9900K,并使用OpenCV DNN模块评估在CPU上的inference rate。为了公平比较,我们没有对模型进行压缩或量化。结果见表5。

5.Conclusion
不再详述。
6.原文链接
👽CSPNET:A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN
