本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
我们发现Mask R-CNN中的信息传播可以进一步被改善。具体来说,low level的特征有利于识别大型实例,但从低级特征到高级特征需要走过很长的路径,这增加了获取准确定位信息的难度。此外,每个proposal来自一个feature level,放弃了其他level中可能有用的信息。最后,mask的预测也是基于single view的,没有聚合更多不同的信息。
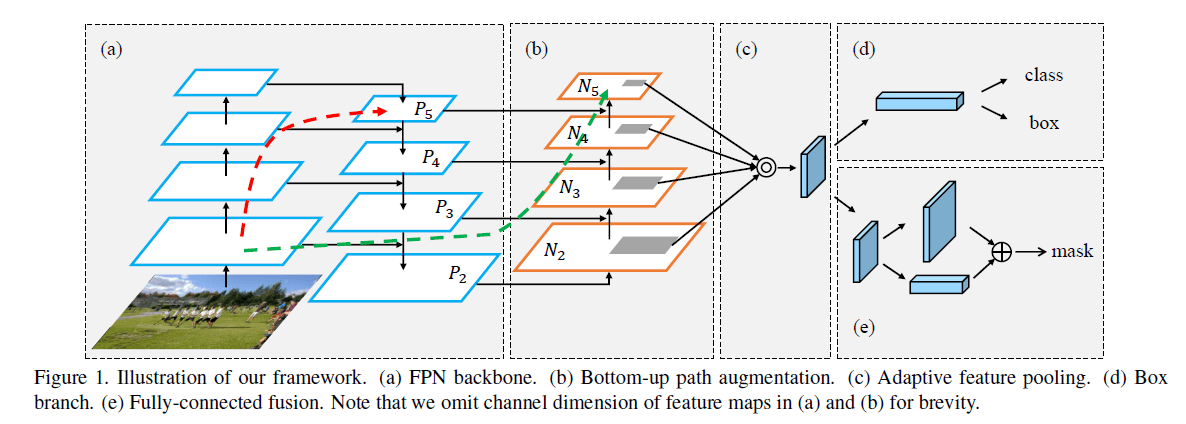
基于上述发现,我们提出了PANet用于实例分割,见Fig1。
PANet在多个数据集上都取得了SOTA的成绩。在COCO 2017 Challenge Instance Segmentation任务中获得了第一名,在Object Detection任务中获得了第二名。代码和模型见:https://github.com/ ShuLiu1993/PANet。
2.Related Work
不再详述。
3.Framework
框架结构见Fig1。路径的扩展和聚合提升了模型性能。自底向上的扩展路径使low-layer的信息更容易传播。自适应特征池化使得每个proposal可以获取所有level的信息用于预测。在mask分支中新加了一条路径。这些改进都是独立于CNN框架的。
3.1.Bottom-up Path Augmentation
👉Motivation
我们构建了一条从低级特征到高级特征的干净横向连接路径(见Fig1绿色虚线),它由不到10层构成。相比之下,在FPN中,从底层到顶层需要走过很长的路径(见Fig1红色虚线),甚至可能需要穿过100多层。
👉Augmented Bottom-up Structure
遵循FPN中的定义,生成相同大小的feature map的层处于同一个网络阶段。每个feature level对应一个阶段。和FPN一样,我们也使用ResNet作为基础结构,并使用FPN生成的$\{P_2,P_3,P_4,P_5 \}$。我们新增$\{ N_2,N_3,N_4,N_5 \}$,分别对应$\{P_2,P_3,P_4,P_5 \}$。$N_2$就是$P_2$,没有做任何处理。
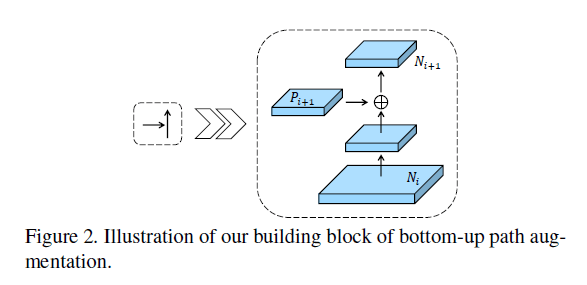
如Fig2所示,每个feature map $N_i$先通过步长为2的$3 \times 3$卷积来降低空间大小,然后对应的$P_{i+1}$通过横向连接和其相加,相加后的feature map再进行一次$3 \times 3$卷积得到$N_{i+1}$。在这个过程中,我们把通道数固定为256。所有卷积层都使用ReLU函数。
3.2.Adaptive Feature Pooling
👉Motivation
在FPN中,proposal会根据其大小被分配到不同的feature level。这就导致小的proposal被分配到低的feature level(比如$P_2$),而大的proposal被分配到更高的feature level(比如$P_5$)。尽管这一策略简单有效,但其产生的结果却不一定是最优的。例如,相差10个像素的两个proposal可能会被分到不同level,尽管这两个proposal颇为相似。因此我们提出自适应特征池化使得每个proposal都可以利用各个level的信息。
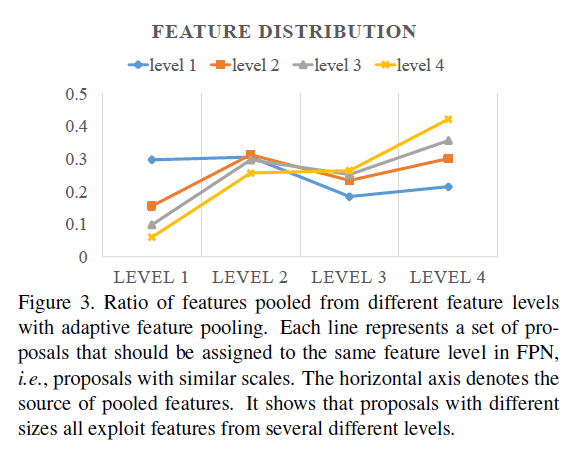
我们现在来分析通过自适应特征池化后,不同level的贡献程度。我们使用element-wise max来融合池化后的proposal,这样我们就可以知道每个像素位置的最大值来自哪个level,从而统计出每个level对最终结果的贡献程度。统计结果见Fig3,蓝色线表示在FPN中被分配到level1的小proposal,我们发现其70%的特征其实来自更高的level。黄色线是在FPN中被分配到level4的大proposal,其50%以上的特征来自更低的level。这一现象说明多个level的特征融合在一起更加有利于准确预测。
👉Adaptive Feature Pooling Structure
自适应特征池化的结构如Fig1(c)所示。首先,对于每个proposal,我们将它们映射到不同的feature level,如Fig1(b)中的灰色区域所示。遵循Mask R-CNN,使用ROIAlign对每个level的proposal进行池化操作。然后通过element-wise max或element-wise sum进行特征融合。
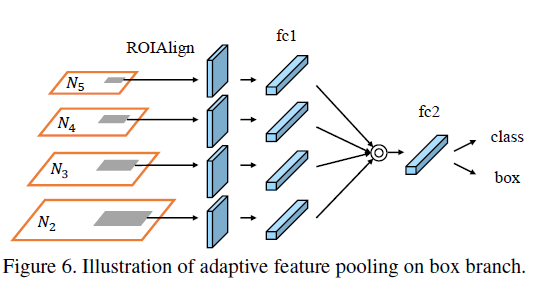
接下来说下具体实现,在Mask R-CNN的Fig4中,我们可以看到box分支有两个FC层,我们在第1个FC层之后才进行融合操作,详细见如下Fig6。
类似的,在Mask R-CNN的mask预测分支中有4个连续的卷积层,我们在第一个和第二个卷积层之间进行融合操作。
3.3.Fully-connected Fusion
👉Motivation
Mask R-CNN在mask预测分支使用了FCN。但作者认为FC层和卷积层具有不同的性质和各自的优势,将两种不同类型的层的预测融合起来,可以获得更好的mask预测。
👉Mask Prediction Structure
我们改进的mask预测分支是轻量级的,且易于实现,见Fig4。
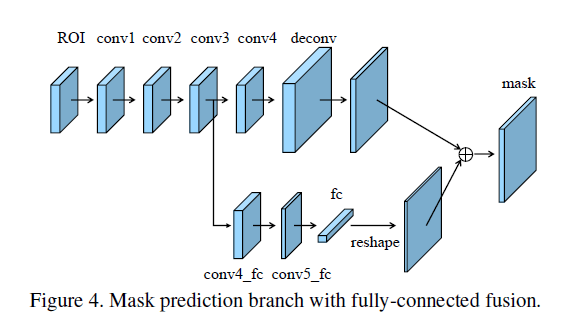
在Fig4中,main path是一个小的FCN,包含4个连续的卷积层和一个反卷积层。每个卷积层使用256个$3\times 3$的卷积核,反卷积实现2倍上采样。它为每个类别独立的预测一个二进制pixel-wise的mask。此外,我们基于conv3又创建了一个short path,其包含2个$3 \times 3$的卷积层,其中第二个卷积层将通道数减半以减少计算量。
FC层用于预测前景/背景。它不仅高效,而且允许使用更多样本来训练FC层,从而获得更好的通用性。我们使用的mask大小为$28 \times 28$,因此FC层产生的是$784 \times 1 \times 1$的向量。然后该向量被reshape为和mask一样的形状。将FCN产生的每个类别的mask预测和来自FC的前景/背景预测add起来,获得最终的mask预测结果。这里只使用了一个FC层而没有使用多个FC层,是为了避免丢失空间信息。
4.Experiments
4.1.Implementation Details
我们使用Caffe实现了Mask R-CNN+FPN。对于每张图像,采集512个ROI,正负样本比例为$1:3$。weight decay=0.0001,momentum=0.9。其他超参数会根据数据集的不同而略有变化。和Mask R-CNN一样,RPN也是单独训练的,为了方便进行消融实验和公平的比较,即目标检测和实例分割之间不共享backbone。
4.2.Experiments on COCO
👉Dataset and Metrics
COCO数据包含115k张图像用于训练,5k张图像用于验证。test-dev包含20k张图像,test-challenge包含20k张图像。test-dev和test-challenge的GT是不公开的。有80个类别的像素级别的实例分割标注。我们在train-2017 subset上训练了模型,在val-2017 subset上汇报了结果。在test-dev上也汇报了结果用于比较。
👉Hyper-parameters
训练阶段,一个batch包含16张图像。如果没有特殊说明,图像的短边和长边分别为800和1000。对于实例分割任务,前120k次迭代的学习率为0.02,后40k次迭代的学习率为0.002。对于目标检测任务,我们训练没有使用mask预测分支,前60k迭代的学习率为0.02,后20k迭代的学习率为0.002。
👉Instance Segmentation Results

ms-train指的是multi-scale training。
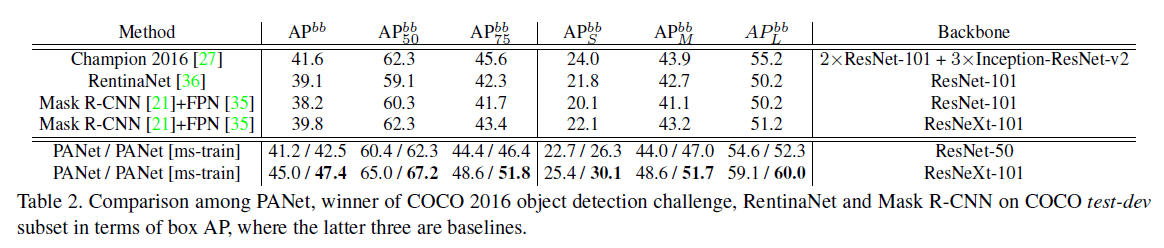
👉Object Detection Results
👉Component Ablation Studies
首先,我们分析了每个组件的重要性。除了bottom-up path augmentation、adaptive feature pooling和fully-connected fusion,我们还分析了multi-scale training、multi-GPU synchronized batch normalization和heavier head。对于multi-scale training,我们将长边设为1400,另一条边随机设为400到1400。multi-GPU synchronized batch normalization指的是一个batch内的图像可能被分散到多个GPU上进行同步训练,但用于BN的均值和方差还是基于整个batch计算的。heavier head指的是把box分支的2个FC层换成4个连续的$3 \times 3$卷积层。

表3中使用的基础模型是ResNet-50。
👉Ablation Studies on Adaptive Feature Pooling
我们对自适应特征池化进行了消融实验,来寻找最佳融合位置和最佳融合方式。”fu.fc1fc2”表示我们把融合放在了ROIAlign和fc1之间,”fc1fu.fc2”表示我们把融合放在了fc1和fc2之间,见表4。
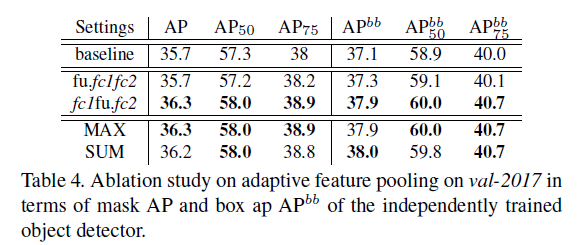
从表4可以看出,自适应特征池化对融合方式不敏感。我们最终选择了”fc1fu.fc2”+”MAX”。
👉Ablation Studies on Fully-connected Fusion
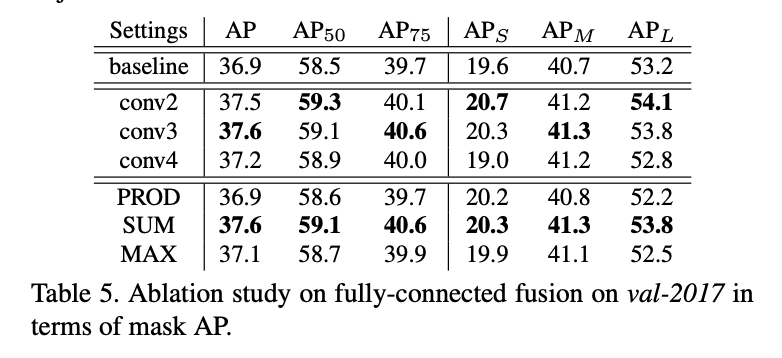
我们主要考虑了两个方面:1)从哪一层开始启动FC分支;2)FC分支和FCN分支的融合方式。我们实验了分别从conv2、conv3和conv4启动FC分支。融合方式尝试了”max”、”sum”、”product”。
👉COCO 2017 Challenge
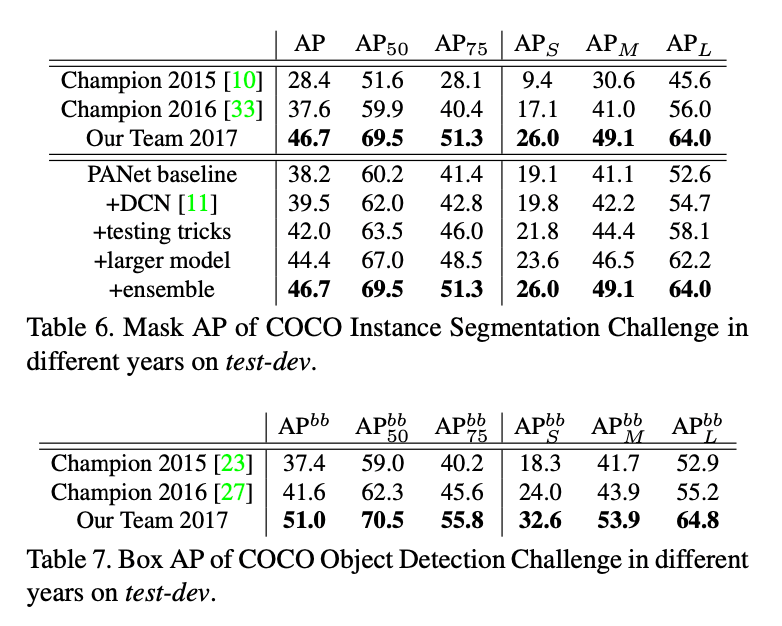
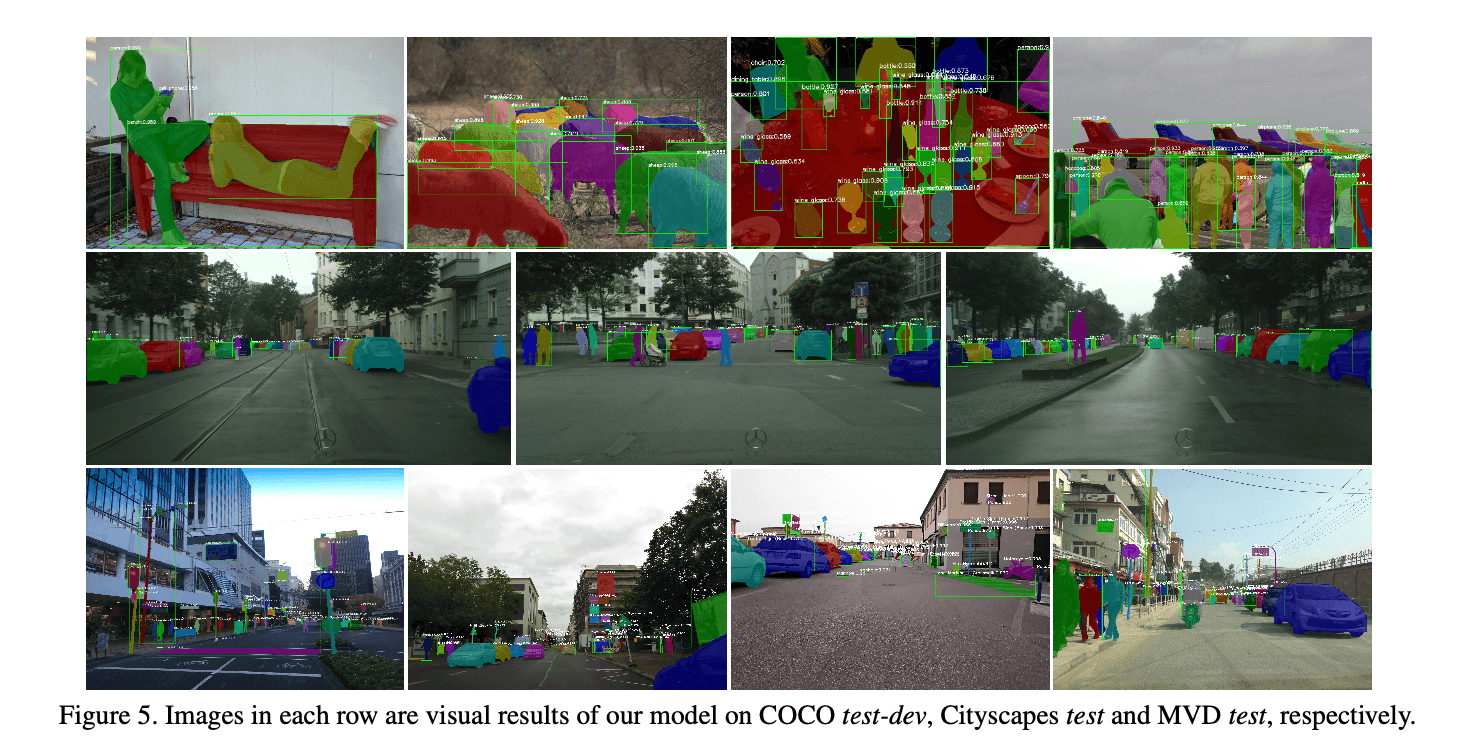
在表6中,首先,我们使用了DCN中的deformable convolutions。还使用了一些常见的testing tricks,比如multi-scale testing、horizontal flip testing、mask voting和box voting等。针对multi-scale testing,我们把长边固定为1400,短边分别resize到600、800、1000、1200(共4种尺度)。其次我们使用了多个大模型集成:3个ResNeXt-101(64$\times $4d)、2个SE-ResNeXt-101(32$\times$ 4d)、1个ResNet-269、1个SENet。此外,还有一个ResNeXt-101(64$\times $4d)作为base model用于产生proposal。一些可视化结果见Fig5。
4.3.Experiments on Cityscapes
👉Dataset and Metrics
Cityscapes数据集是由车载相机拍摄的街景图像。训练集有2975张图像,验证集有500张图像,测试集有1525张图像,都具有良好的标注。另外还有粗糙标注的20k张图像没有用于训练。我们在val和secret test subset上汇报了结果。8个语义类别都使用实例mask进行标注。每张图像的大小是$1024 \times 2048$。
👉Hyper-parameters
为了公平的比较,我们使用了和Mask R-CNN一样的超参数设置。在训练阶段,将图像短边随机resize到$\{ 800,1024 \}$;在推理阶段,将短边固定为1024。没有使用testing tricks和DCN。前18k次迭代的学习率为0.01,后6k次迭代的学习率为0.001。一个batch有8张图像(一块GPU放一张图像)。ResNet-50作为初始模型。
👉Results and Ablation Study
和SOTA方法的比较见表8:
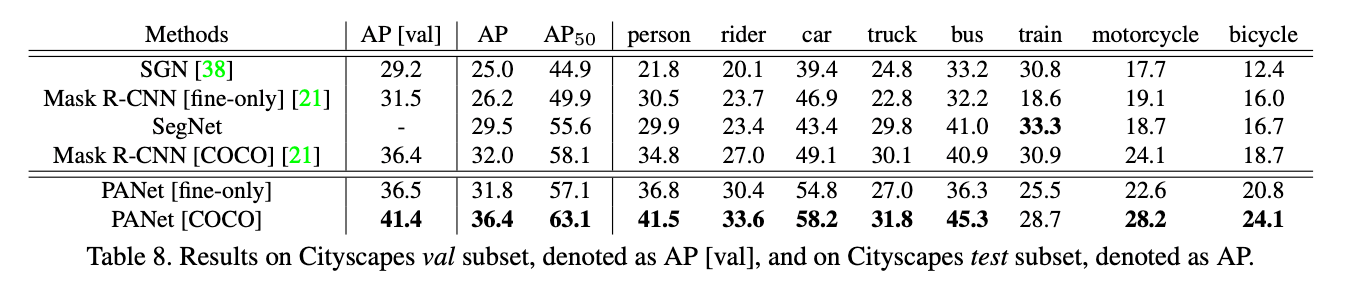
“[fine-only]”指的是只在有精细标注的训练集上进行训练。”[COCO]”指的是在COCO上进行了预训练。可视化结果见Fig5。
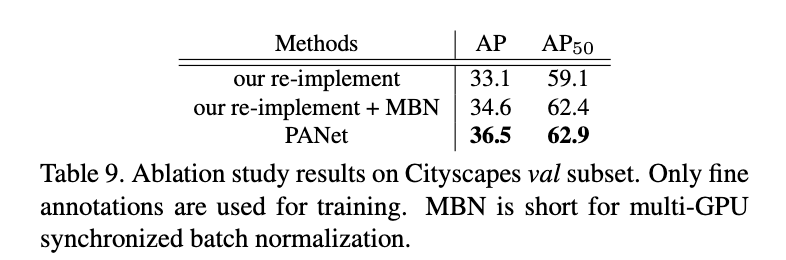
消融实验见表9:
4.4.Experiments on MVD
MVD是一个相对较新的用于实例分割的大规模数据集。它包含25,000张精细标注的街景图像,共有37个语义类别。数据集中的图像是在多个国家使用不同设备拍摄的,所以内容和分辨率差异都很大。我们使用ResNet-50作为初始模型,在训练集上进行了训练,结果见表10。
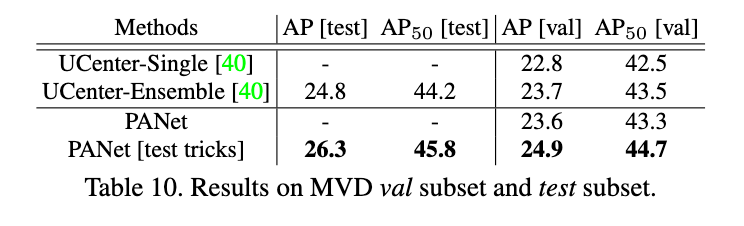
UCenter是LSUN 2017实例分割挑战在这个数据集上的冠军。我们在single-scale images上的测试结果和在COCO上预训练过的集成UCenter不相上下。如果我们使用和UCenter一样的multi-scale和水平翻转等testing tricks,我们模型的性能更胜一筹。可视化结果见Fig5。
5.Conclusion
不再详述。
6.Appendix
6.A.Training Details and Strategy of Generating Anchors on Cityscapes and MVD.
在Cityscapes数据集上,训练超参数和Mask R-CNN保持一致。和Mask R-CNN以及FPN中一样,RPN anchor有5种尺度和3种长宽比。在MVD数据集上,我们采用和UCenter一样的超参数设置。前60k次迭代的学习率为0.02,后20k次迭代的学习率为0.002。训练阶段,一个batch有16张图像。使用multi-scale training,输入图像的长边为2400个像素,短边随机resize到600-2000。同样使用multi-scale testing,短边resize到$\{1600,1800,2000 \}$。RPN anchor有7种尺度$\{ 8^2, 16^2, 32^2, 64^2, 128^2, 256^2, 512^2 \}$和5种长宽比$\{0.2, 0.5, 1, 2, 5 \}$。目标检测任务和实例分割任务使用同样的尺度来训练RPN。
6.B.Details on Implementing Multi-GPU Synchronized Batch Normalization.
不再详述。
