本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
目前精度比较高的网络模型都不能做到实时检测,并且需要多个GPU来完成训练。我们提出一个可以实时检测的CNN模型,且训练只需要一块GPU即可。我们提出的YOLOv4的性能结果见Fig1。
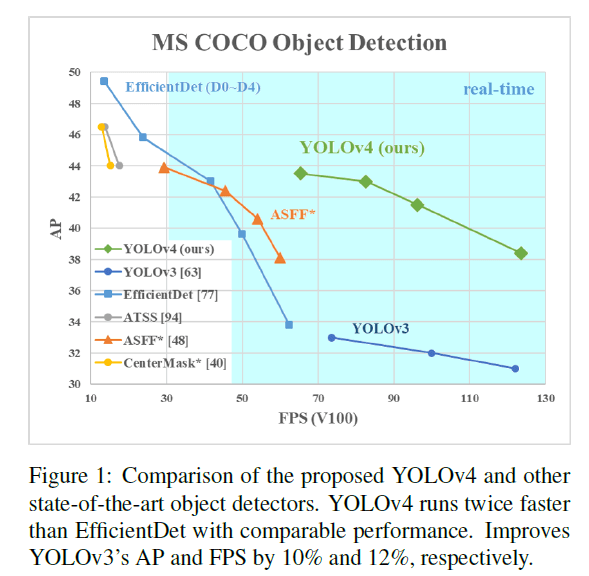
我们的贡献总结如下:
- 我们开发了一个高效且强大的目标检测模型,并且用一块1080 Ti或2080 Ti GPU就可以进行训练。
- 我们验证了一些SOTA的Bag-of-Freebies和Bag-of-Specials对目标检测的影响。
- 我们修改了一些SOTA方法,使其更有效且更适合单GPU训练,这些方法包括CBN、PAN、SAM等。
CBN:Zhuliang Yao, Yue Cao, Shuxin Zheng, Gao Huang, and Stephen Lin. Cross-iteration batch normalization. arXiv preprint arXiv:2002.05712, 2020.。
SAM:Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018.。
2.Related work
2.1.Object detection models
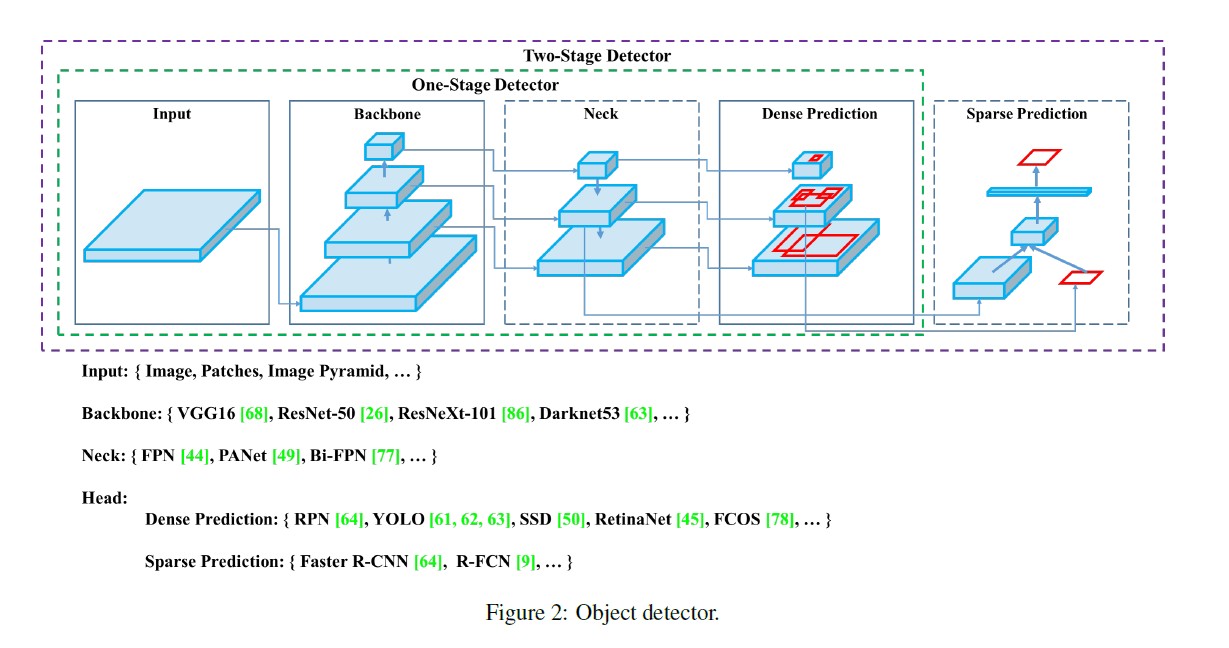
如Fig2所示,一个常见的目标检测器通常由4部分组成:
- Input:Image,Patches,Image Pyramid
- Backbone:VGG16,ResNet-50,SpineNet,EfficientNet-B0/B7,CSPResNeXt50,CSPDarknet53
- Neck:
- Head:
- Dense Prediction (one-stage):
- Sparse Prediction (two-stage):
- anchor based:Faster R-CNN,R-FCN,Mask R-CNN
- anchor free:RepPoints
其中,Neck位于Backbone和Head之间,通常包含几个自下而上和自上而下的路径。
2.2.Bag of freebies
BoF(Bag of freebies)指的是在不增加推理成本的前提下,通过改变训练策略或只增加训练成本,从而提升模型精度的一些方法。

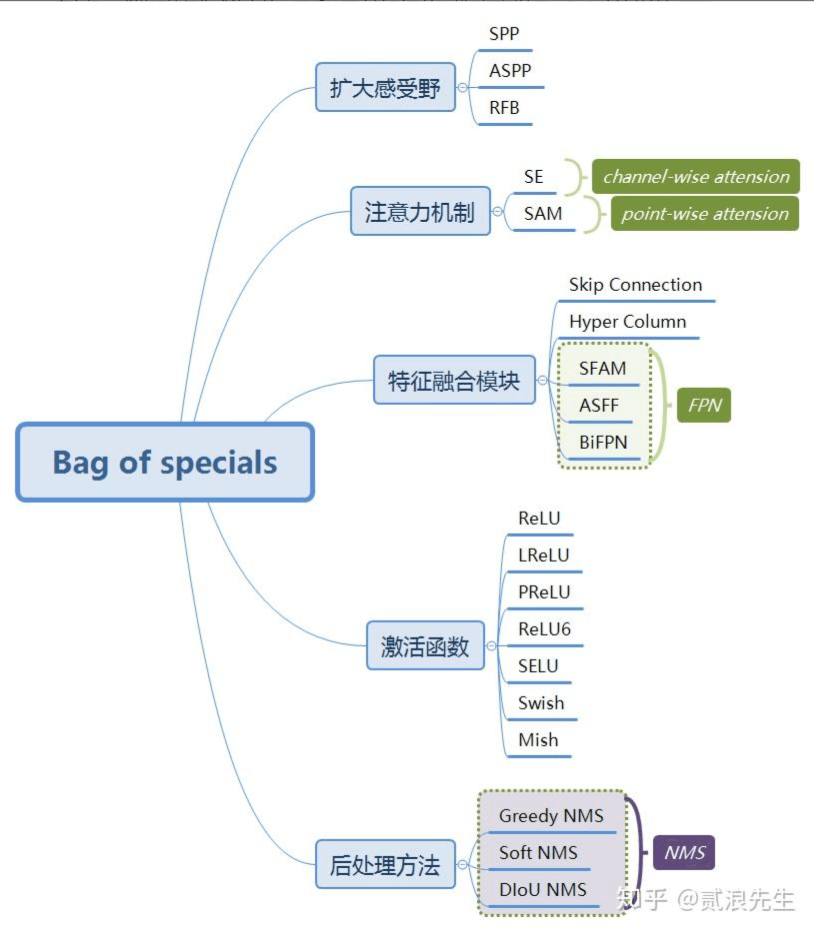
2.3.Bag of specials
BoS(Bag of specials)指的是只增加少量推理成本就能显著提升模型精度的一些方法。
3.Methodology
我们的目标不是降低BFLOP,而是优化神经网络的运行速度。我们列出了两种实时神经网络的选择:
- For GPU:CSPResNeXt50/CSPDarknet53。
- For VPU:EfficientNet-lite/MixNet/GhostNet/MobileNetV3。
3.1.Selection of architecture
我们的目标就是在网络输入分辨率、卷积层数量、参数数量(即filter_size$^2$ * filters * channel / groups)和输出层数量(即filters)之间找到最佳平衡。例如,我们的大量实验表明,在ILSVRC2012(ImageNet)数据集上,对于目标分类任务,CSPResNeXt50的精度要比CSPDarknet53好得多。但是,在MS COCO数据集上,对于目标检测任务,CSPDarknet53的精度要比CSPResNeXt50要好得多。
下一个目标是选择一个额外的block来增加感受野,并且选择一个最优的方法(比如FPN、PAN、ASFF、BiFPN)来聚合来自backbone不同level的信息。
分类任务上的最优模型对于检测任务来说并不一定是最优的。与分类器相比,检测器需要以下内容:
- 更大的网络输入(即更高的分辨率)——用于检测多个小目标。
- 更多的层——获取更大的感受野,以cover更大的网络输入。
- 更多的参数——提升模型的capacity,以在单张图像上检测多个不同大小的目标。
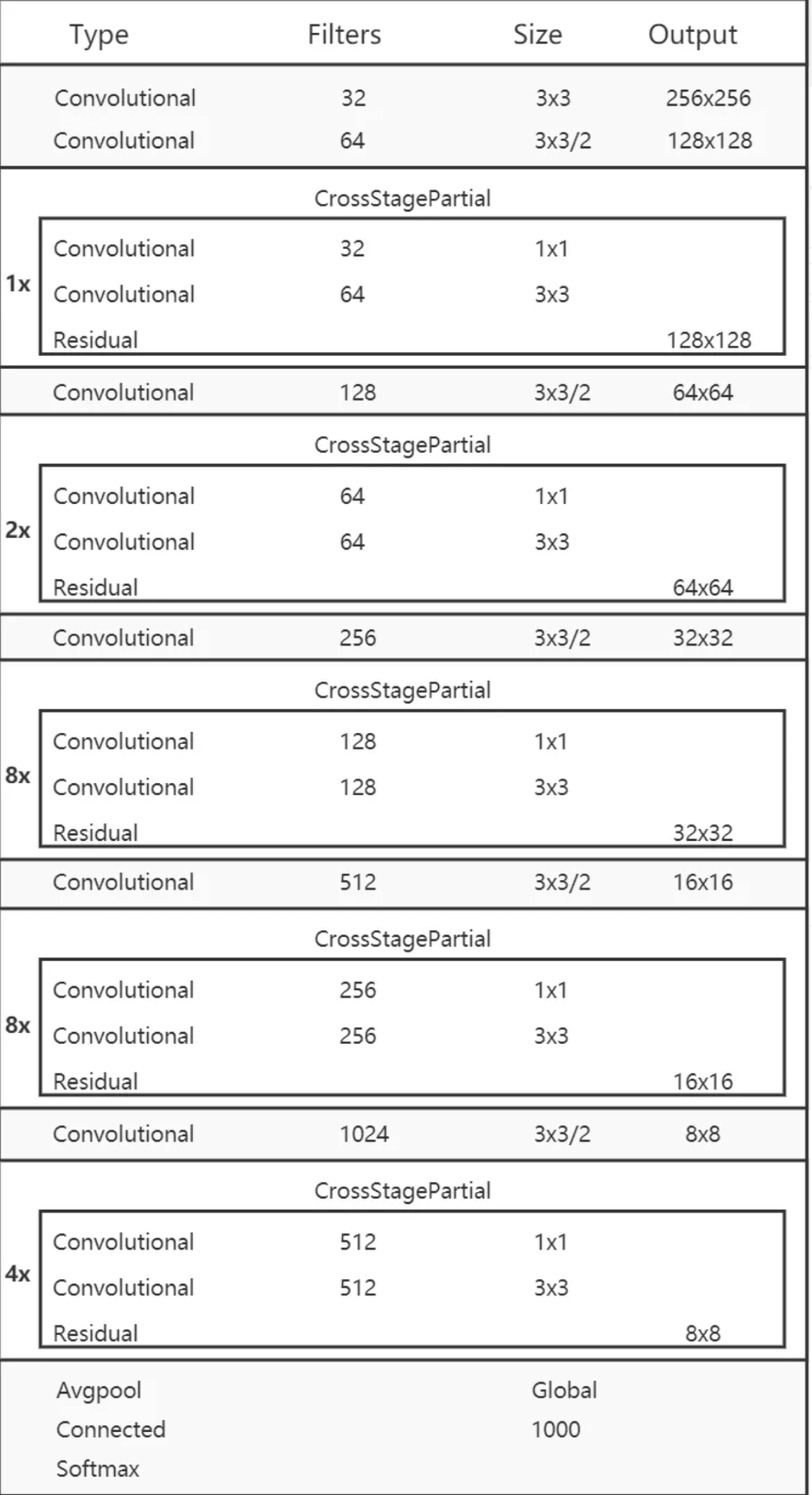
所以我们理应选择具有更大感受野(即更多数量的$3\times 3$卷积层)和更多参数的模型作为backbone。表1是一些备选模型。CSPResNeXt50包含16个$3\times 3$卷积层,感受野大小是$425 \times 425$,参数量为$20.6M$。CSPDarknet53包含29个$3\times 3$卷积层,感受野大小是$725 \times 725$,参数量为$27.6M$。除了以上理论分析,我们还做了大量实验,都表明CSPDarknet53是更优的backbone。

我们在CSPDarknet53上添加了SPP block,因为它能显著增加感受野,分离出最重要的上下文特征,并且几乎不会降低网络运行速度。我们使用PANet来聚合backbone不同level的信息,而不是YOLOv3中所用的FPN。
最终,在YOLOv4框架中,CSPDarknet53为backbone,添加了额外的SPP模块,PANet为neck,YOLOv3(anchor based)为head。
我们没有使用Cross-GPU Batch Normalization(CGBN或SyncBN)或昂贵的专用设备。每个人都可以使用常见的GPU,比如GTX 1080Ti或RTX 2080Ti,复现出我们SOTA的结果。
3.2.Selection of BoF and BoS
为了改进目标检测训练,CNN通常采用以下内容:
- Activations:ReLU,leaky-ReLU,parametric-ReLU,ReLU6,SELU,Swish,Mish
- Bounding box regression loss:MSE,IoU,GIoU,CIoU,DIoU
- Data augmentation:CutOut,MixUp,CutMix
- Regularization method:DropOut,DropPath,Spatial DropOut,DropBlock
- Normalization of the network activations by their mean and variance:Batch Normalization(BN),Cross-GPU Batch Normalization(CGBN或SyncBN),Filter Response Normalization(FRN),Cross-Iteration Batch Normalization(CBN)
- Skip-connections:Residual connections,Weighted residual connections,Multi-input weighted residual connections,Cross stage partial connections(CSP)
对于激活函数,由于PReLU和SELU很难训练,并且ReLU6是专门为量化网络设计的,因此我们没有考虑这几个激活函数。对于正则化,基于之前研究的比较结果,我们选择了DropBlock。此外,我们关注的是仅使用一个GPU训练的场景,所以也没有考虑syncBN。
3.3.Additional improvements
为了使我们设计的检测器更适合在单个GPU上进行训练,我们进行了额外的改进:
- 我们提出了一种新的data augmentation方法:Mosaic和Self-Adversarial Training(SAT)。
- 使用遗传算法选择最优超参数。
- 我们修改了SAM,PAN为neck,YOLOv3和Cross mini-Batch Normalization(CmBN),使其可以更有效的训练和检测。
遗传算法是计算数学中用于解决最佳化的搜索算法,是进化算法的一种。
Mosaic是一种新的data augmentation方法,其混合了4张不同的训练图像。但CutMix只混合了2张图像。Mosaic使得模型能够检测到正常context之外的目标,并且Mosaic还可以显著降低对mini-batch size的需求。

SAT也是一种新的data augmentation方法,分为前向和后向两个阶段。第一个阶段,通过网络的后向传播更新图像,而不是网络权重,通过这种方法改变原始图像。第二个阶段,在被修改的图像上正常训练网络。
CmBN是CBN的修改版,见Fig4。
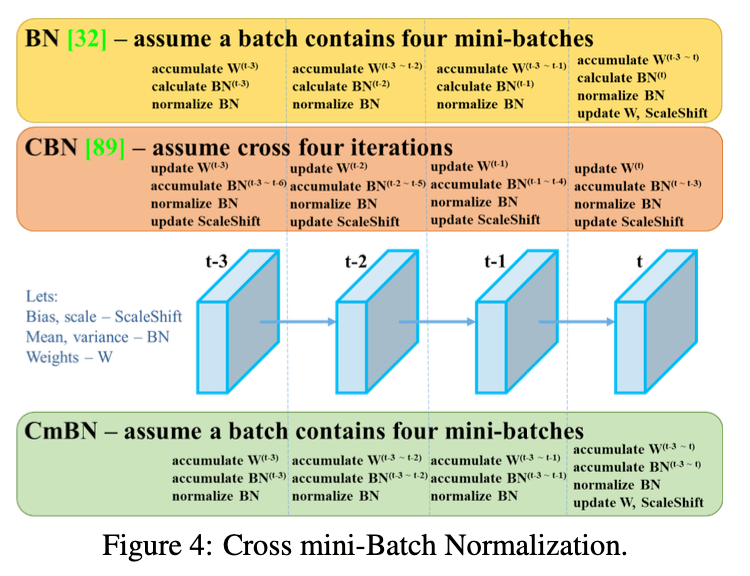
BN有一个致命的缺陷,那就是我们在设计BN的时候有一个前提条件就是当batch size足够大的时候,用mini-batch算出的BN参数($\mu$和$\sigma$)来近似等于整个数据集的BN参数,但是当batch size较小的时候,BN的效果会很差。
batch size太小,本质上还是数据太少不足以近似整个训练集的BN参数,所以CBN就通过计算前几次迭代计算好的BN参数($\mu$和$\sigma$)来一起计算这次迭代的BN参数。详细原理见CBN论文:Zhuliang Yao, Yue Cao, Shuxin Zheng, Gao Huang, and Stephen Lin. Cross-iteration batch normalization. arXiv preprint arXiv:2002.05712, 2020.。
CmBN是基于CBN进行的修改,但CmBN只会统计4个mini-batch的参数。
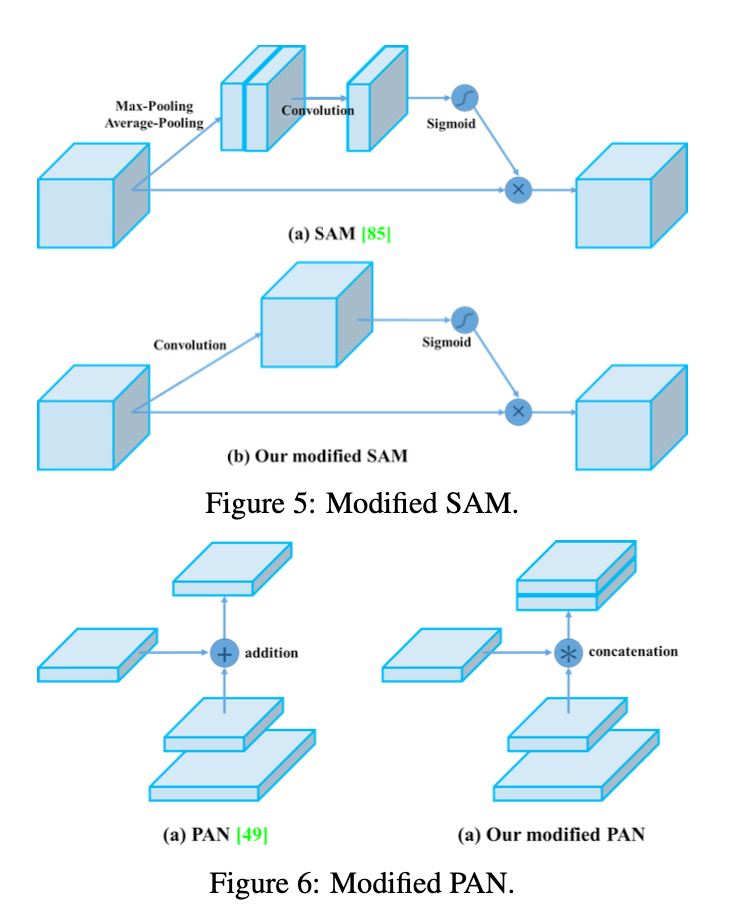
针对SAM的修改,我们把spatial-wise attention改成了point-wise attention,见Fig5。针对PAN的修改,我们把shortcut connection的连接方式从相加改成了concat,见Fig6。
3.4.YOLOv4
本节详细介绍YOLOv4的细节。
YOLOv4包括:
YOLOv4使用了:
- BoF for backbone:CutMix,Mosaic,DropBlock,Class label smoothing
- BoS for backbone:Mish激活函数,CSP,Multi-input weighted residual connections(MiWRC)
- BoF for detector:CIoU-loss,CmBN,DropBlock,Mosaic,SAT,Eliminate grid sensitivity,Using multiple anchors for a single ground truth,Cosine annealing scheduler,Optimal hyperparameters,Random training shapes
- BoS for detector:Mish激活函数,SPP-block,SAM-block,PAN path-aggregation block,DIoU-NMS
YOLOv4的整体框架见下:
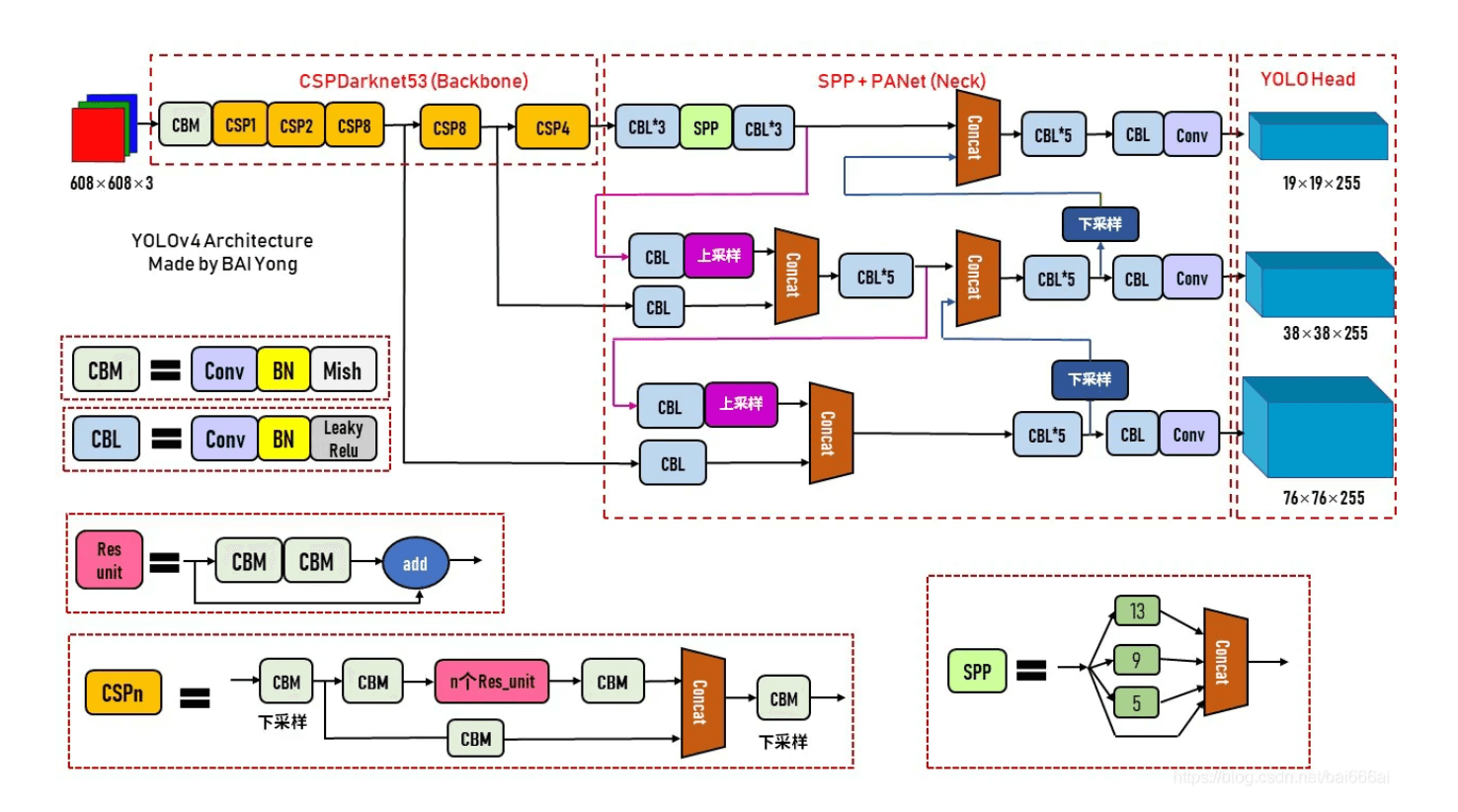
CSPDarknet53的结构见下:
在YOLOv4的SPP模块中,spatial bin的划分为$\{ 1 \times 1, 5 \times 5, 9 \times 9, 13 \times 13 \}$,最后将不同尺度的feature map进行concat操作:

CutMix是对一对图像做操作,随机生成一个裁剪框,裁剪掉A图的相应位置,然后用B图相应位置的ROI放到A图中被裁剪的区域形成新的样本:

Mosaic则使用了4张图像,每一张图像都有其对应的bounding box,利用随机缩放、随机裁剪、随机排布的方式进行拼接,将4张图像拼接之后就获得一张新的图像,同时也获得这张图像对应的bounding box。如下图所示:

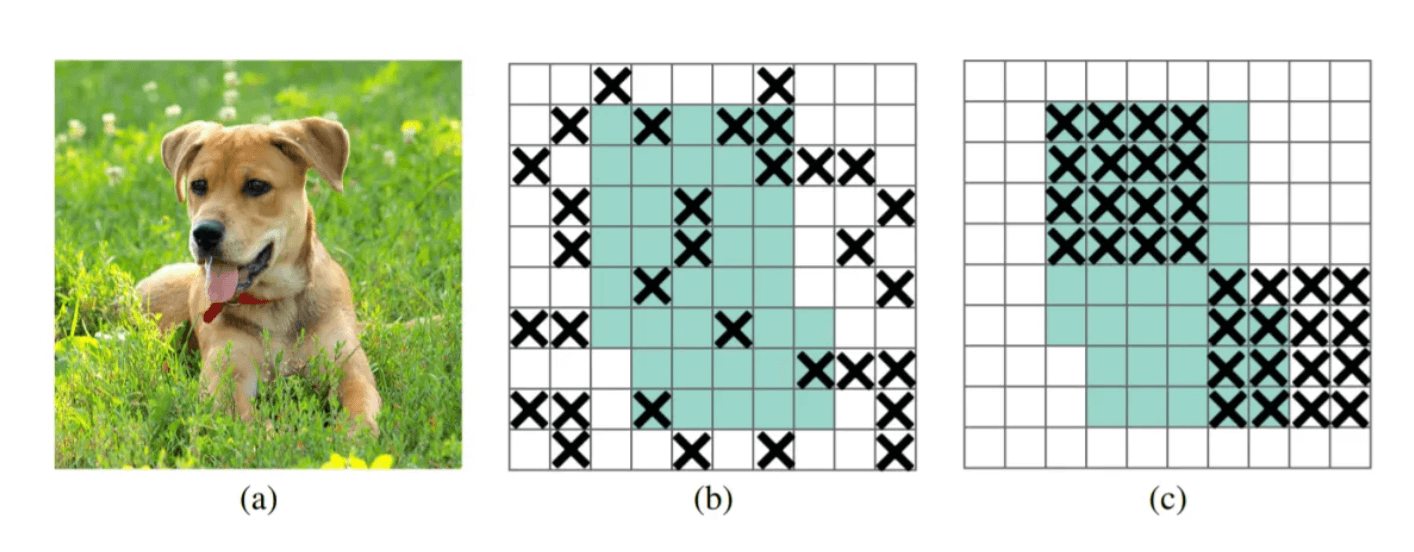
DropBlock与DropOut功能类似,也是避免过拟合的一种正则化方法,而原本DropOut是随机drop特征,这一点对于FC层是有效的,但在卷积层是无效的,因为网络仍可以从相邻的激活单元学习到相同信息,信息仍能传送到下一层,则无法避免过拟合。所以YOLOv4采用一块一块的去drop,即DropBlock,如下图所示,中间是DropOut,右边是DropBlock,一个feature map连续的部分就会被drop,那么模型为了拟合数据,网络就会往别处寻找新的证据。
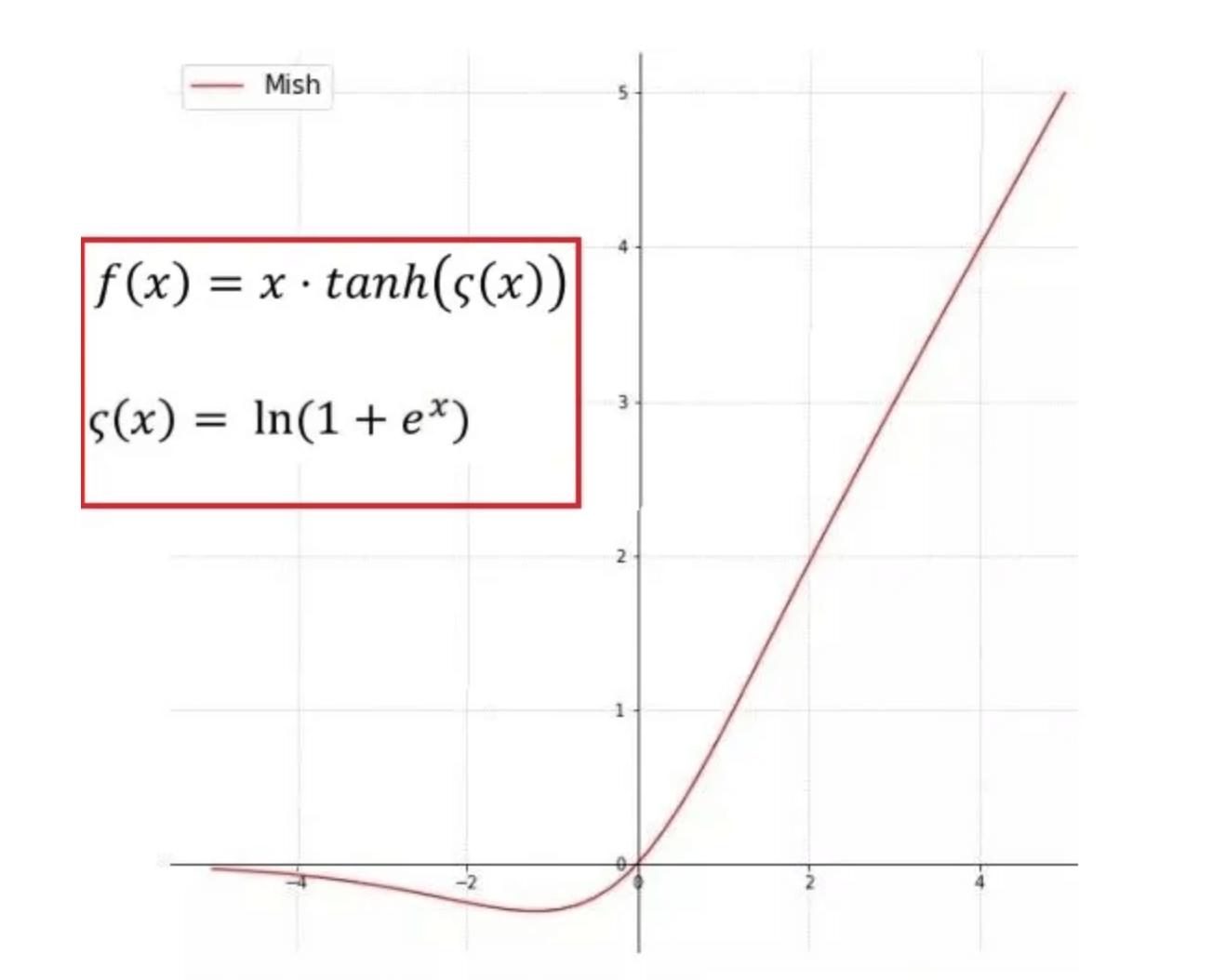
Mish是连续可微分的非单调、上无界、有下界的激活函数,Mish的梯度更平滑,可以稳定网络梯度流,具有更好的泛化能力。但作者只在backbone使用Mish,后面的网络部分还是使用leaky-ReLU。以下为Mish的公式:
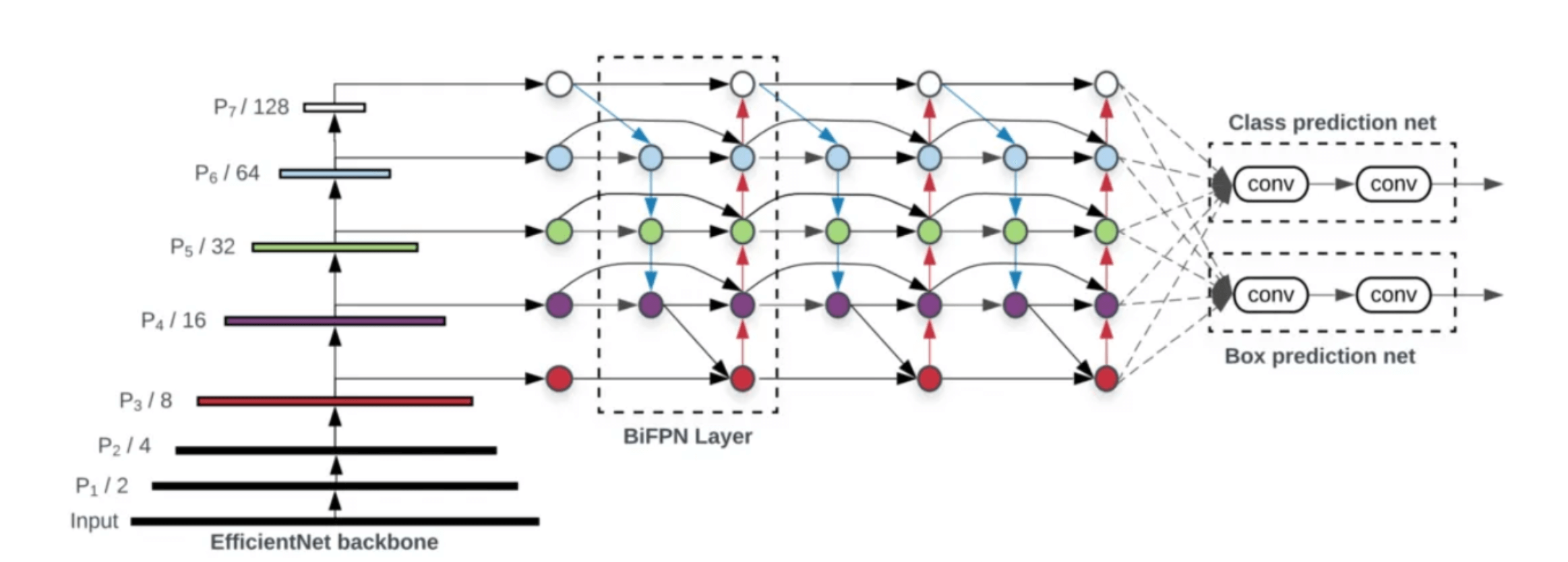
MiWRC参考EfficientDet框架中的BiFPN,被用在neck阶段。EfficientDet的框架结构见下:
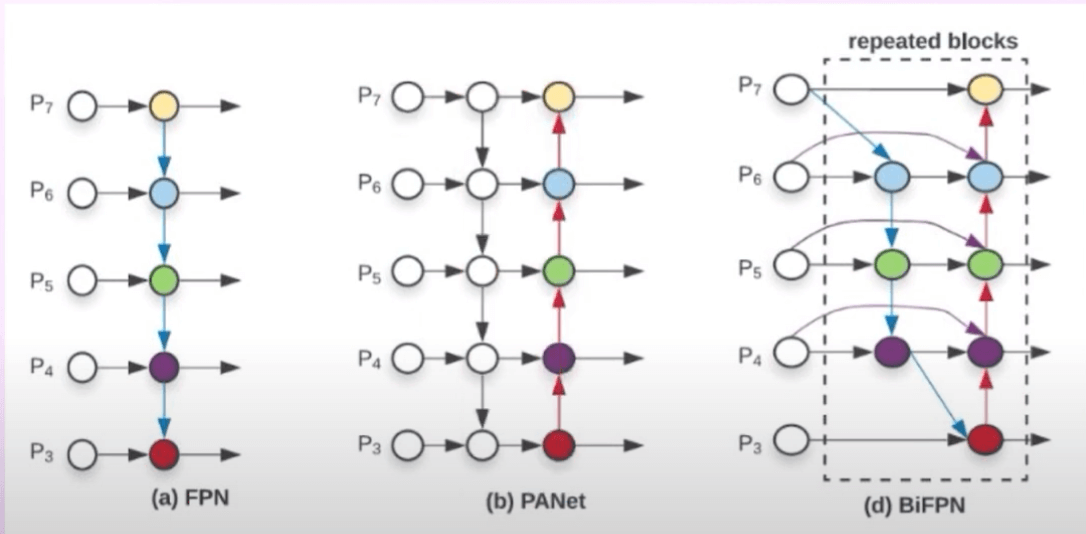
其中,BiFPN是基于PAN做的改进:
BiFPN的计算方式:

我们以$P_6^{out}$为例,其有3个加权输入:1)$P_6^{in}$(残差连接);2)$P_6^{td}$;3)$P_5^{out}$。所以我们又把这个结构称为Multi-input weighted residual connections(MiWRC)。
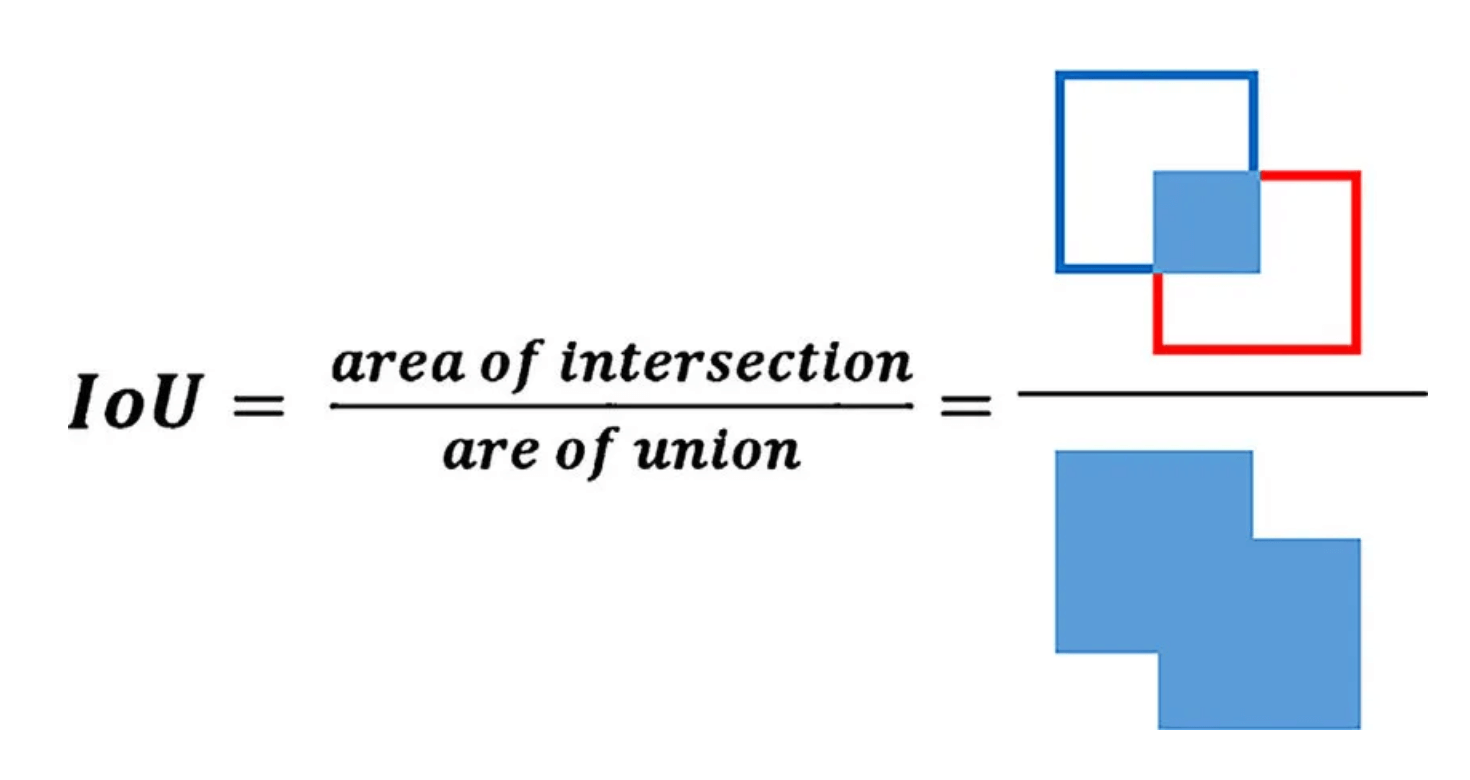
IoU的计算方式如下:
IoU Loss就是1-IoU。IoU Loss有以下2个问题:
- 如果两个框没有相交,那么IoU=0,不能反映出2个框之间的距离,而loss也为0,没有梯度就不能训练更新、优化参数。
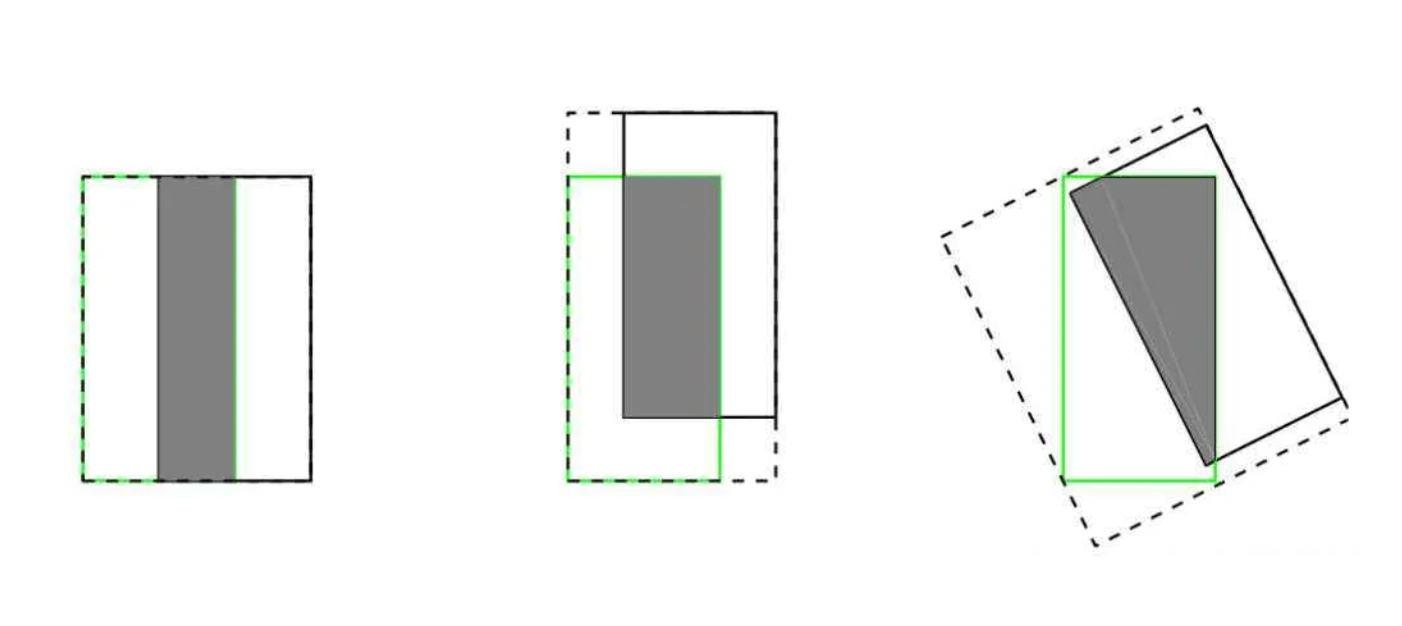
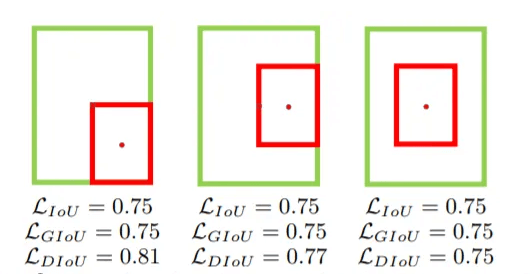
- IoU无法精确反映2个框间重合度大小。如下图所示,3张图IoU都相等,但是重合程度看得出来不一样的,左边的图比较好,右边的图最差。
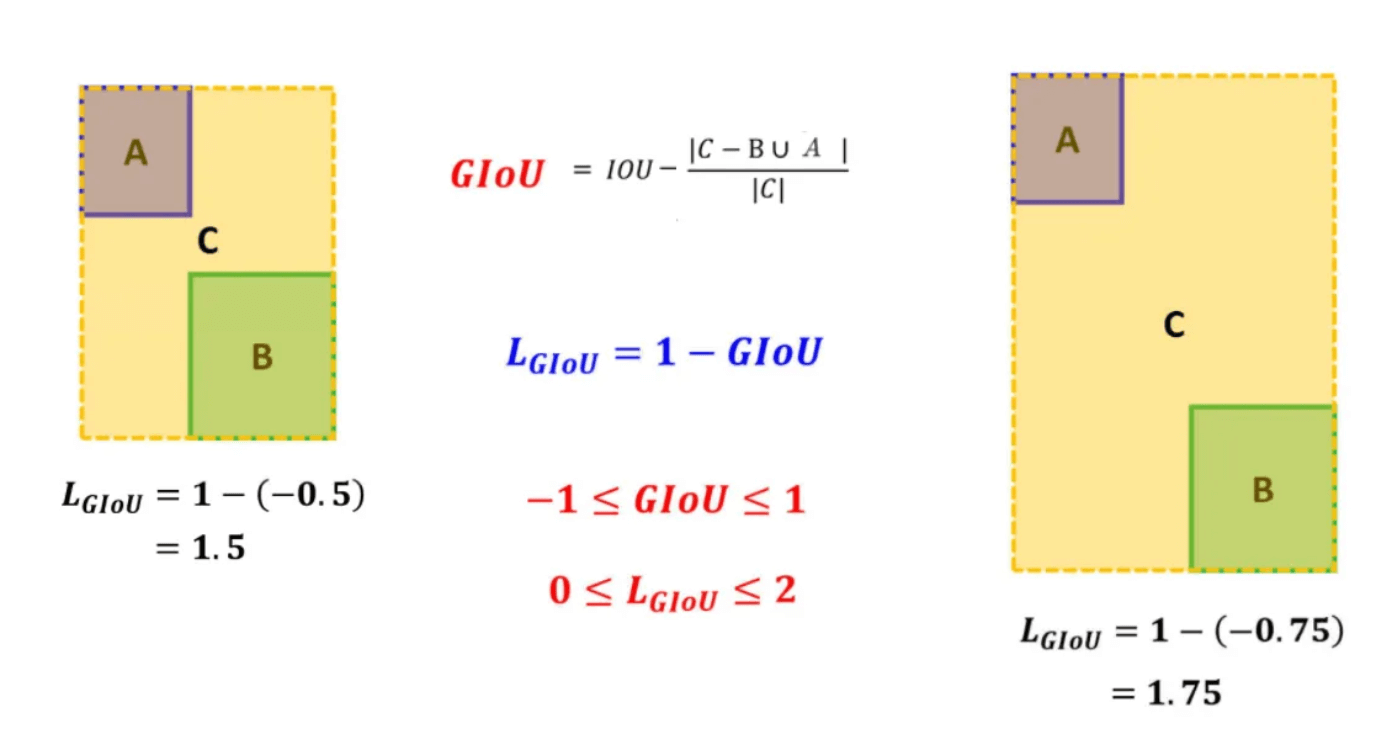
GIoU(Generalized IoU)为了解决无重叠情况的梯度消失问题,在IoU Loss的基础上增加一个惩罚项,比IoU更能反映两个框的接近程度和重合度。公式如下图所示,C是A、B两个框可以圈出的最小封闭矩形。可以看到左右两张图都没相交,但是因为左图A和B距离比较短,所以loss比较低。
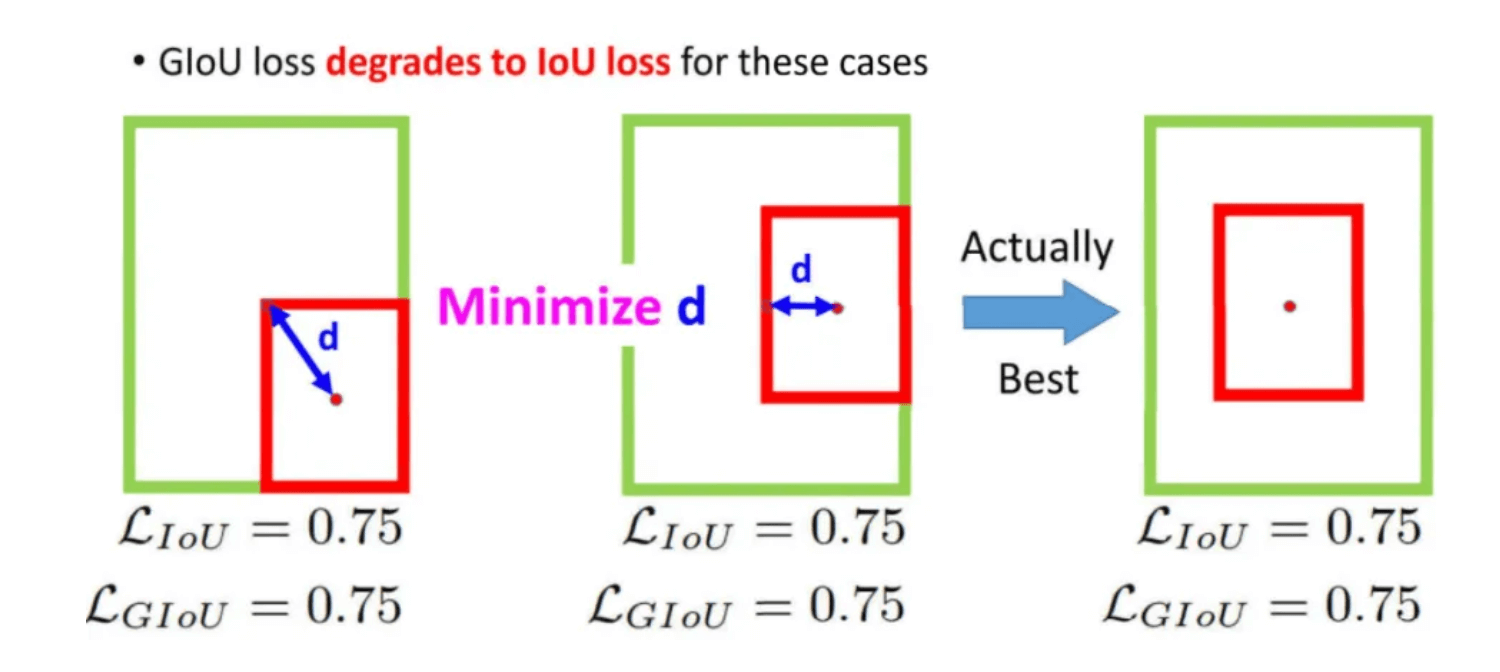
但GIoU Loss也有问题,如下图所示,此时IoU和GIoU的loss都是一样的值,但显然最右边的预测是比较好的,问题就出在中心点的距离d没办法去缩小。
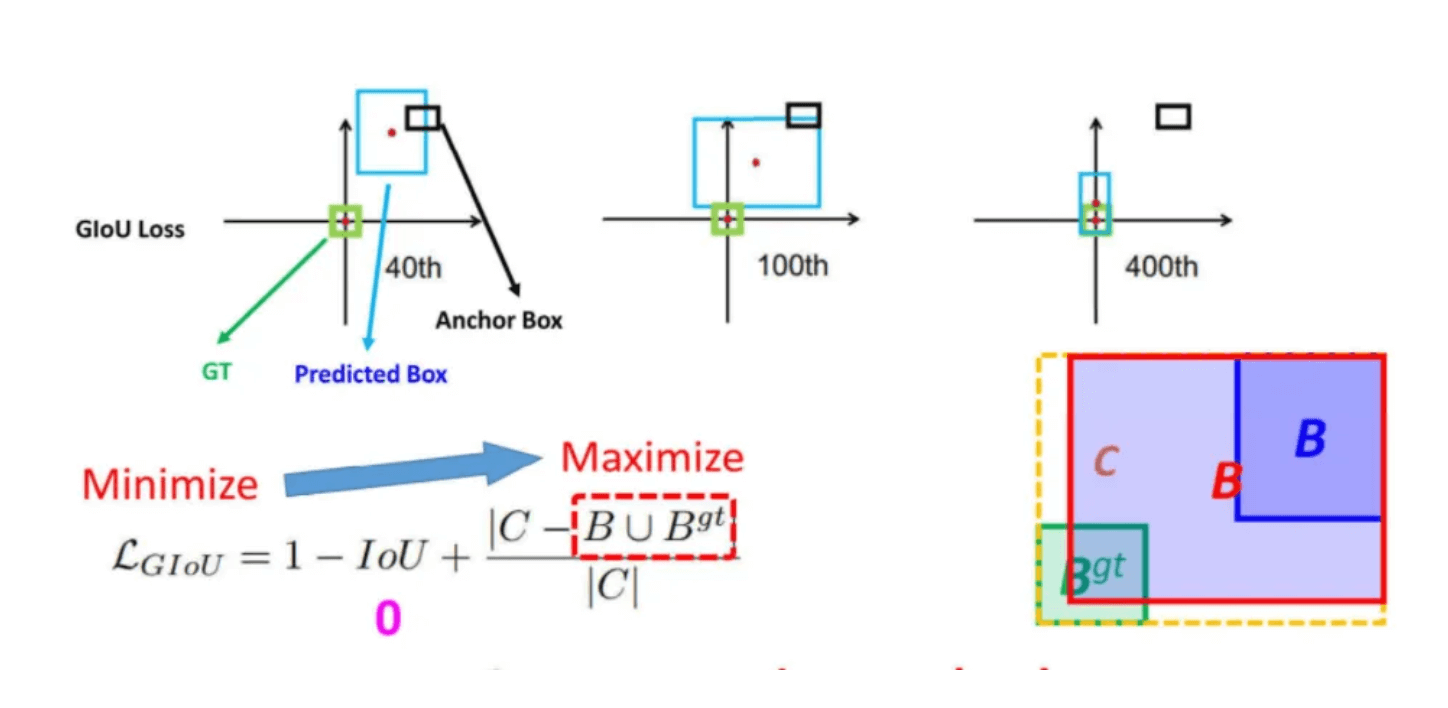
GIoU Loss还有一个问题,如下图所示,在训练过程中,GIoU会倾向于先增大预测框的大小,为了要和GT重叠,如下图Maximize红色框公式所示,这样会导致收敛速度变得很慢,会很花费时间,像是下图到第400次迭代才快要收敛完成。
无论是IoU还是GIoU都只考虑了重叠面积,因此提出DIoU(Distance IoU),考虑了中心点距离,要去最小化两个中心点的距离,增加一个惩罚项用于最小化两个框中心点的距离,公式如下图所示。
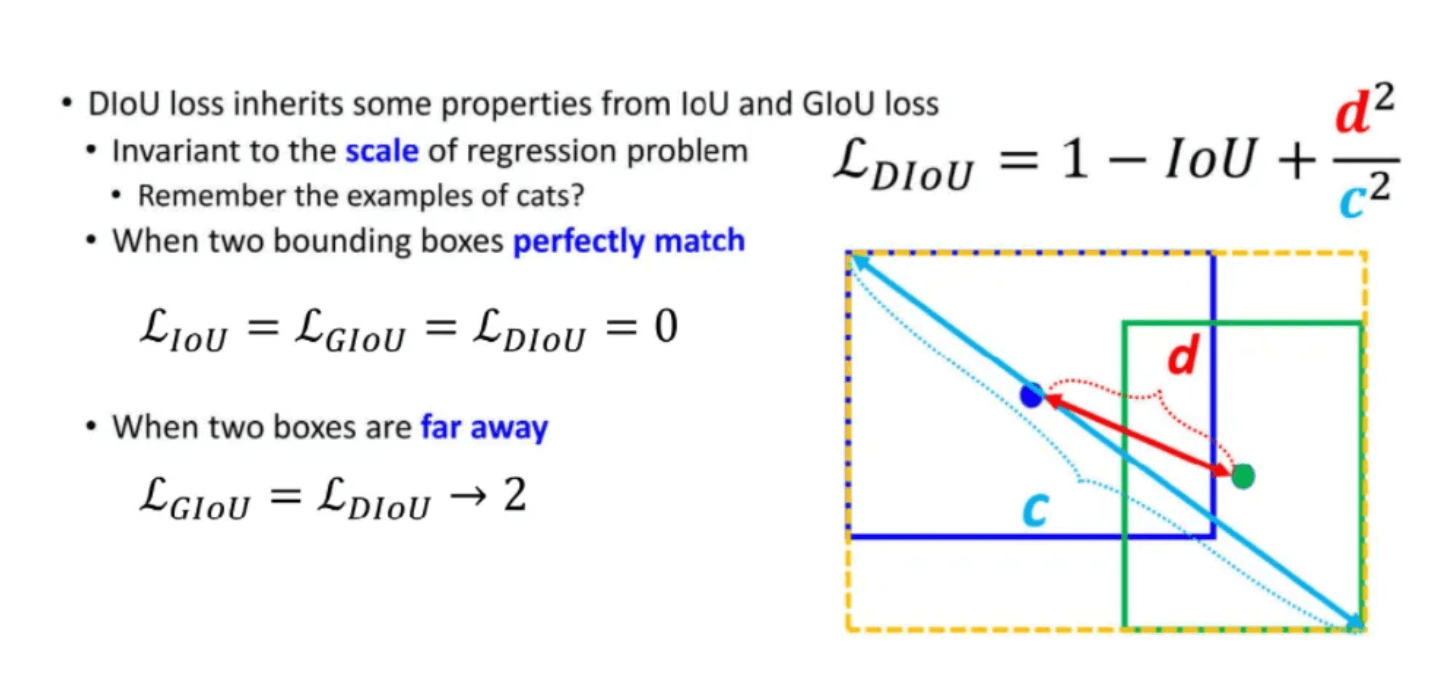
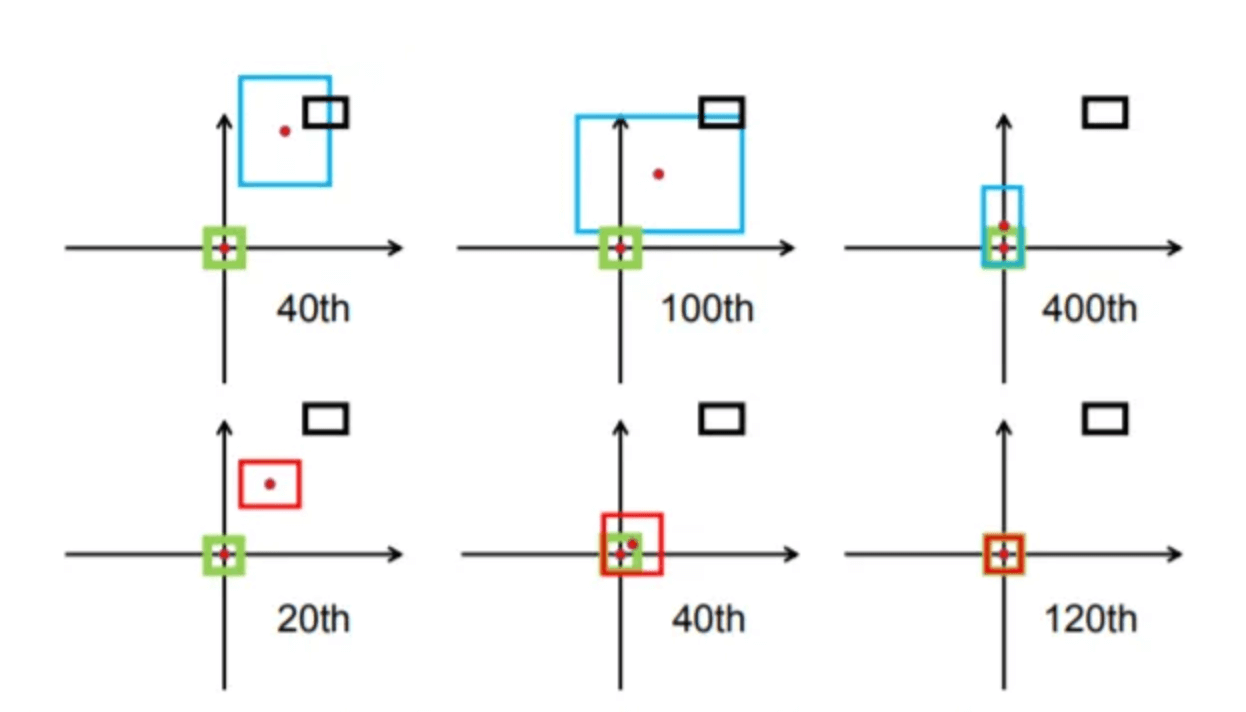
DIoU Loss的收敛速度比GIoU Loss快很多,如下图所示,上面一行是GIoU Loss的收敛,下面一行是DIoU Loss的收敛。
刚刚提到的GIoU Loss问题之一,当预测框在目标框内时,GIoU Loss与IoU Loss值相同,此时IoU和GIoU都无法区分其相对位置,而DIoU Loss则不一样,可以更好的去解决这个问题。
而YOLOv4最终使用的CIoU(Complete IoU) Loss,不但考虑了重叠面积和中心点,还考虑了长宽比。

至于Eliminate grid sensitivity,在YOLOv3中,预测的bounding box的中心点计算公式为:
\[b_x = \sigma (t_x) + c_x\] \[b_y = \sigma (t_y) + c_y\]其中,
- $t_x$是网络预测的bounding box中心点x坐标的偏移量(相对于网格左上角)。
- $t_y$是网络预测的bounding box中心点y坐标的偏移量(相对于网格左上角)。
- $c_x$是对应网格左上角的x坐标。
- $c_y$是对应网格左上角的y坐标。
- $\sigma$是sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的grid cell区域。
但在YOLOv4中,作者认为这样做并不合理,比如当bounding box的中心点非常靠近网格的左上角($\sigma (t_x)$和$\sigma (t_y)$应该趋近于0)或右下角($\sigma (t_x)$和$\sigma (t_y)$应该趋近于1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。为了解决这个问题,作者引入了一个大于1的缩放系数($\text{scale}_{xy}$):
\[b_x = ( \sigma (t_x) \cdot \text{scale}_{xy} - \frac{\text{scale}_{xy} - 1}{2} ) + c_x\] \[b_y = ( \sigma (t_y) \cdot \text{scale}_{xy} - \frac{\text{scale}_{xy} - 1 }{2} ) + c_y\]比如在YOLOv5中,把$\text{scale}_{xy}$设为2。$y=\sigma (x)$(蓝色曲线)和$y = 2 \cdot \sigma (x) - 0.5$(橙色曲线)对应的曲线见下:
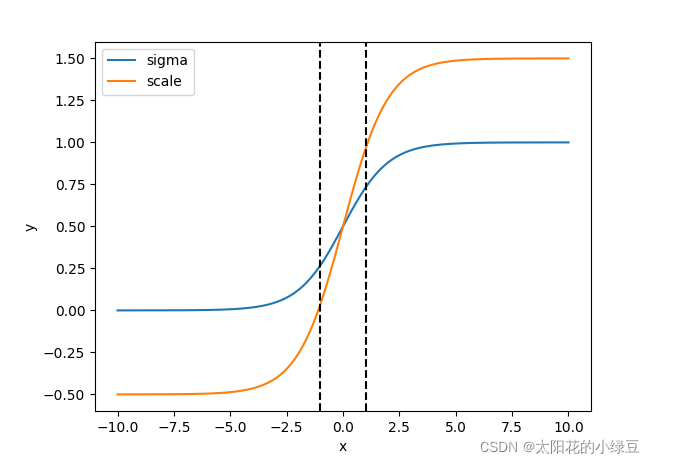
可以看到,修改之后,x不需要取到正无穷或者负无穷,y就能取到1和0。y的范围也从原来的$(0,1)$扩大到了$(-0.5,1.5)$,也就是说,预测的bounding box的中心点可能会超出grid cell,但不会远离这个grid cell太多。
接下来解释Using multiple anchors for a single ground truth,上面我们提到了,bounding box中心点的偏移范围已经从原来的$(0,1)$扩大到了$(-0.5,1.5)$,所以,对于同一个GT box,可以分配给多个anchor box,即正样本的数量更多了。如下图所示:

- 将每个GT box与每个anchor box模板进行匹配(这里直接将GT box和anchor box模板左上角对齐,然后计算IoU,在YOLOv4中IoU的阈值设置的是0.213)。
- 如果GT box与某个anchor box模板的IoU大于给定阈值,则将GT box分配给该anchor box模板,如图中的
AT 2。 - 将GT box投影到对应预测特征层上,根据GT box的中心点定位到对应cell(图中有三个对应的cell)。比如GT box的中心点落在grid的左上角这个象限内,那么就考虑左边和上边的cell。
- 则这3个cell对应的
AT 2都为正样本。
注意,这里没考虑左上角的cell,按理来说,左上角cell的AT 2也应该是正样本,但在YOLOv5源码中,只考虑了向GT box中心点所在cell的上、下、左、右四个方向扩展,不会向左上、右上、左下、右下四个方向扩展。更多例子:

使用Cosine annealing scheduler(余弦退火)进行学习率衰减:
\[\eta _t = \eta_{min} + \frac{1}{2} (\eta_{max} - \eta_{min}) (1+\cos (\frac{T_{cur}}{T_{max}} \pi))\]- $\eta_t$:学习率。
- $\eta_{max}$:最大学习率。
- $\eta_{min}$:最小学习率。
- $T_{cur}$:当前迭代次数。
- $T_{max}$:最大迭代次数。
至于Optimal hyperparameters,在YOLOv3中使用的anchor模板是:

而在YOLOv4中,作者针对$512 \times 512$尺度采用的anchor模板是:

至于Random training shapes,是为了提高泛化能力,随机调整输入图像的大小,实现multi-scale training。
SAM(Spatial Attention Module)源自CBAM(Convolutional Block Attention Module)论文:
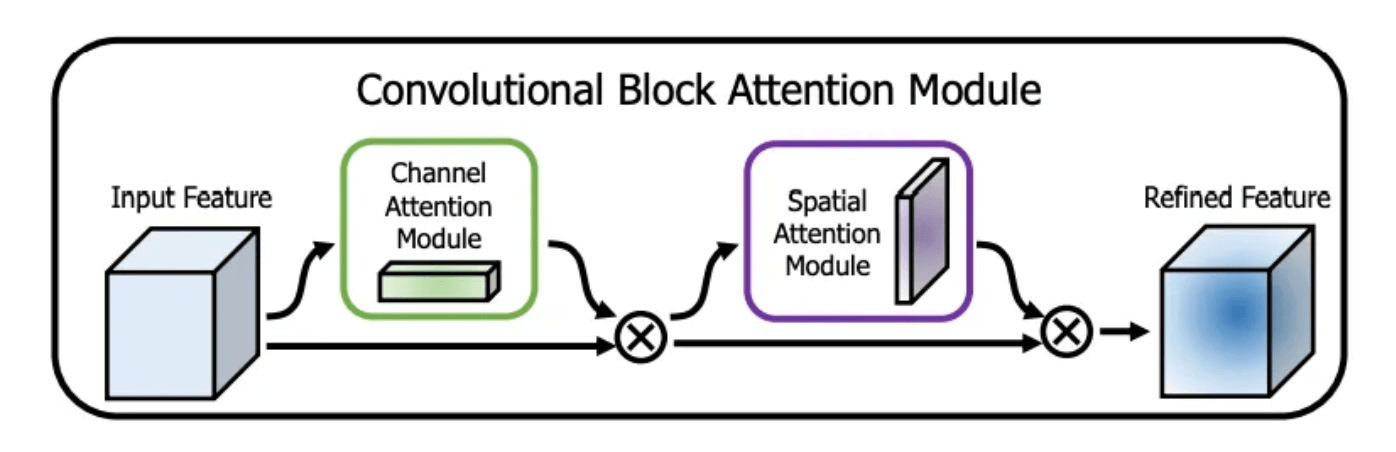
从上图可以看出,CBAM包括2个主要模块:CAM和SAM。两个模块的细节见下:
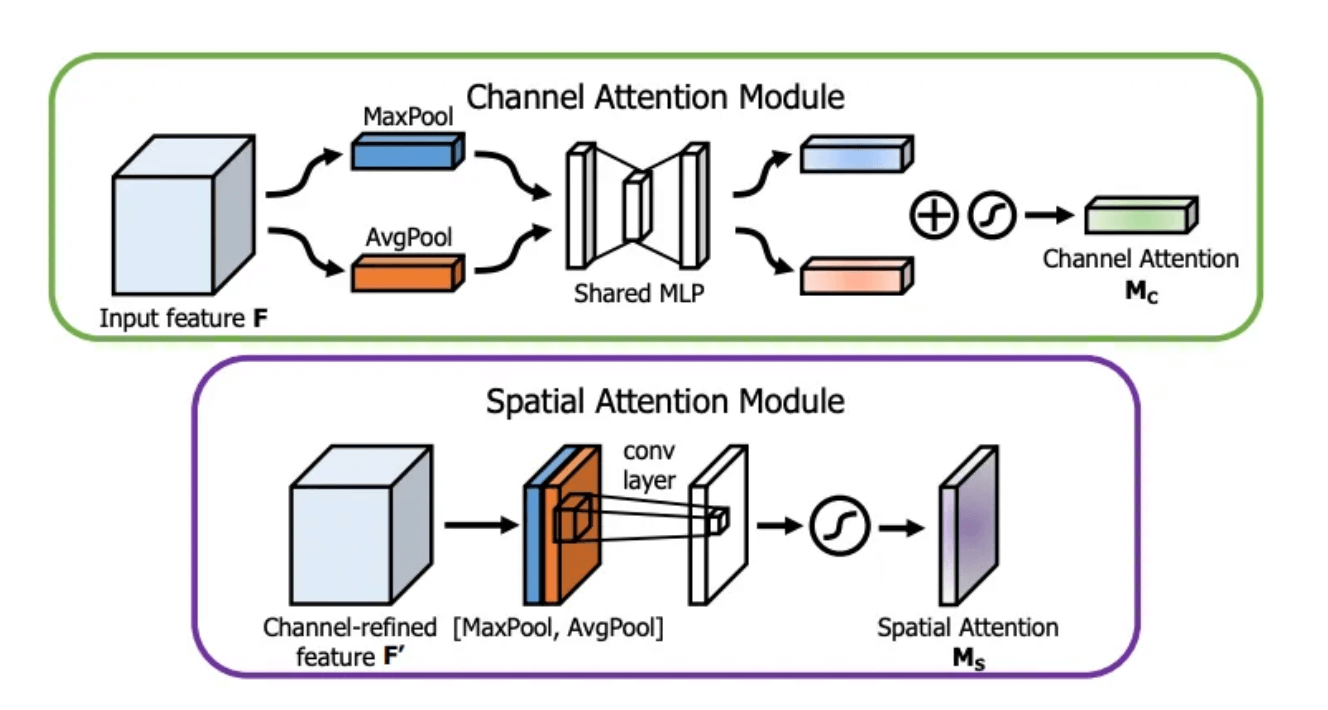
在SAM中,先分别进行$1\times 1$的AvgPool和$1\times 1$的MaxPool,得到两个$H \times W \times 1$的feature map,将这两个feature map按照通道方向concat在一起,然后经过一个$7 \times 7$的卷积层,激活函数为sigmoid,得到权重系数$\mathbf{M_s}$,最后将$\mathbf{M_s}$和经过CAM refine后的$\mathbf{F’}$相乘得到缩放后的新特征。而在YOLOv4中,作者没有使用pooling而是直接使用$7 \times 7$的卷积层,见Fig5。
4.Experiments
我们在ImageNet(ILSVRC 2012 val)数据集上测试了在分类任务上的性能,在MS COCO(test-dev 2017)数据集上测试了在检测任务上的性能。
4.1.Experimental setup
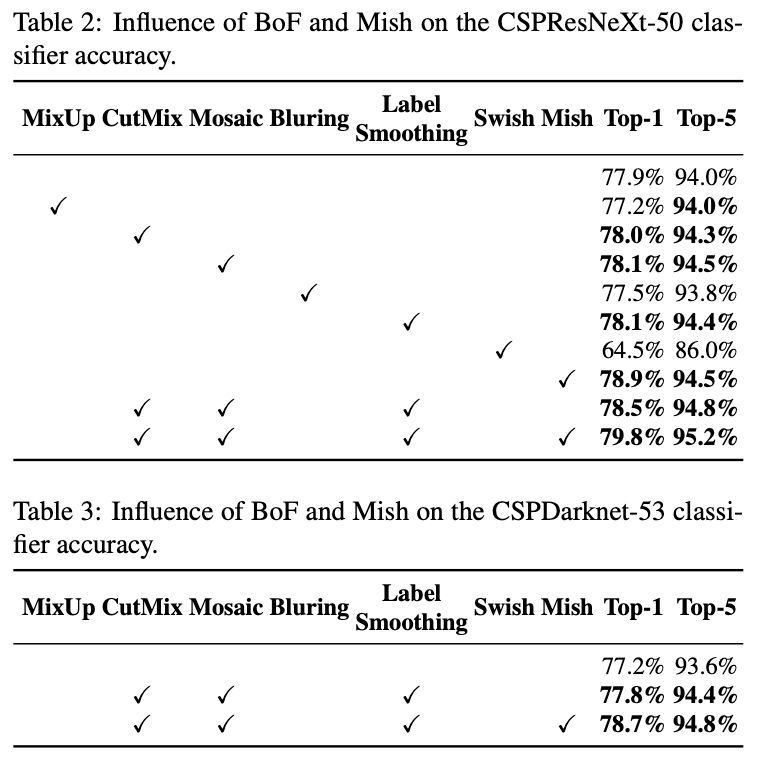
在ImageNet图像分类实验中,超参数设置如下:训练步数为8,000,000;batch size=128,mini-batch size=32;采用多项式学习率衰减策略,初始学习率为0.1;warm up step为1000;momentum=0.9,weight decay=0.005。所有的BoS实验都使用和默认设置相同的超参数,而在BoF实验中,我们增加了50%的训练步数。在BoF实验中,我们验证了MixUp,CutMix,Mosaic,Bluring data augmentation,label smoothing regularization。在BoS实验中,我们比较了LReLU,Swish,Mish激活函数。所有实验都是在1080 Ti或2080 Ti上训练的。
步数(step)和迭代次数是同一含义,即进行一次参数更新的操作。
多项式学习率衰减策略(the polynomial decay learning rate scheduling strategy):
\[learning\_rate = (initial\_learning\_rate - end\_learning\_rate) * (1 - \frac{step}{total\_steps})^{power} + end\_learning\_rate\]其中,initial_learning_rate是初始学习率,end_learning_rate是训练结束时预期的最小学习率,total_steps是训练的总步数,step是当前的训练步数,power用于控制学习率随时间下降的速度。
在COCO目标检测实验中,超参数设置如下:训练步数为500,500;使用step decay learning rate scheduling strategy,即设初始学习率为0.01,在第400,000和第450,000步时,学习率缩小10倍;momentum=0.9,weight decay=0.0005。所有框架都使用单个GPU,使用multi-scale training,batch size=64,取决于GPU的内存限制,mini-batch size等于8或4。除了使用遗传算法进行超参数搜索的实验外,其他所有实验都使用默认设置。遗传算法使用YOLOv3-SPP,基于GIoU loss进行训练,在min-val 5k sets上搜索300个epoch。在遗传算法实验中,学习率为0.00261,momentum为0.949,IoU和GT的阈值为0.213,loss normalizer为0.07。我们验证了大量BoF方法,包括grid sensitivity elimination、mosaic data augmentation、IoU阈值、遗传算法、class label smoothing、CmBN、SAT、cosine annealing scheduler、dynamic mini-batch size、DropBlock、Optimized Anchors、不同的IoU loss。我们也评估了很多BoS方法,包括Mish、SPP、SAM、RFB、BiFPN、Gaussian YOLO。对于所有的实验,我们都只使用一个GPU进行训练,所以像syncBN那种针对多GPU优化的技术并没有被使用。
4.2.Influence of different features on Classifier training

不同形式的data augmentation见Fig7。比较结果见下:
4.3.Influence of different features on Detector training
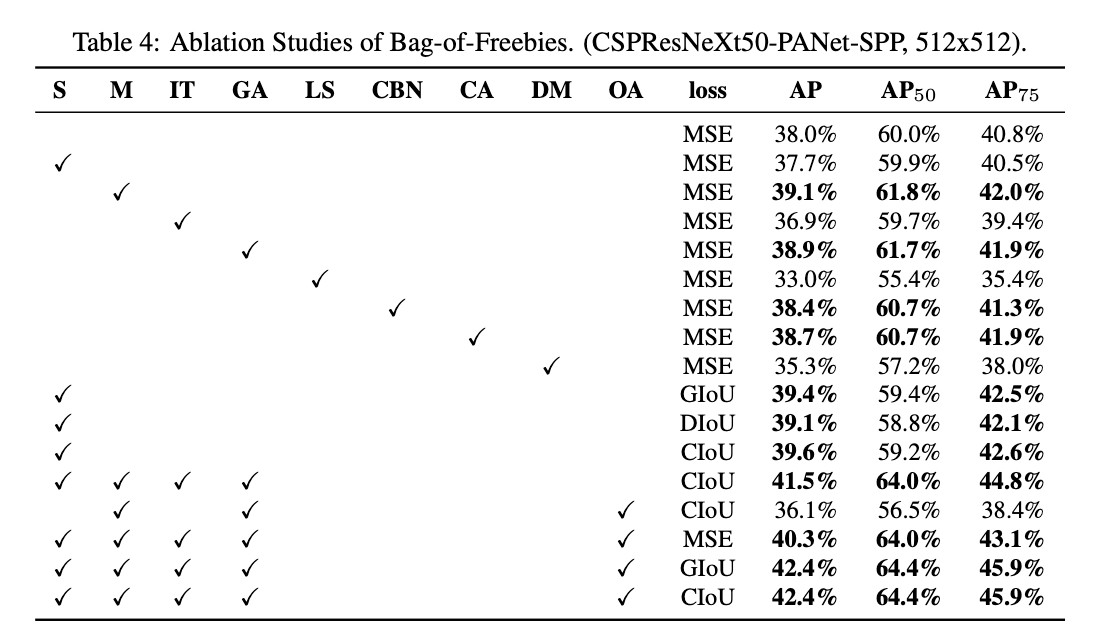
- S:Eliminate grid sensitivity。
- M:Mosaic data augmentation。
- IT:IoU threshold。即Using multiple anchors for a single ground truth。
- GA:Genetic algorithms。训练阶段前10%的时间使用遗传算法搜索最优超参数。
- LS:Class label smoothing。
- CBN:CmBN。
- CA:Cosine annealing scheduler。
- DM:Dynamic mini-batch size。当输入图像较小时,自动增加mini-batch的大小。
- OA:Optimized Anchors。网络输入为$512 \times 512$时,训练使用optimized anchors。
- GIoU,CIoU,DIoU,MSE:bounding box回归所用的不同loss。
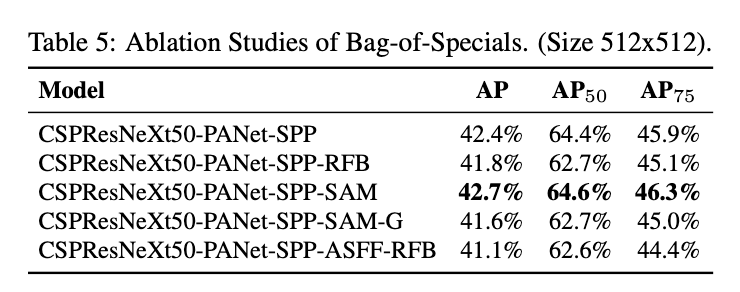
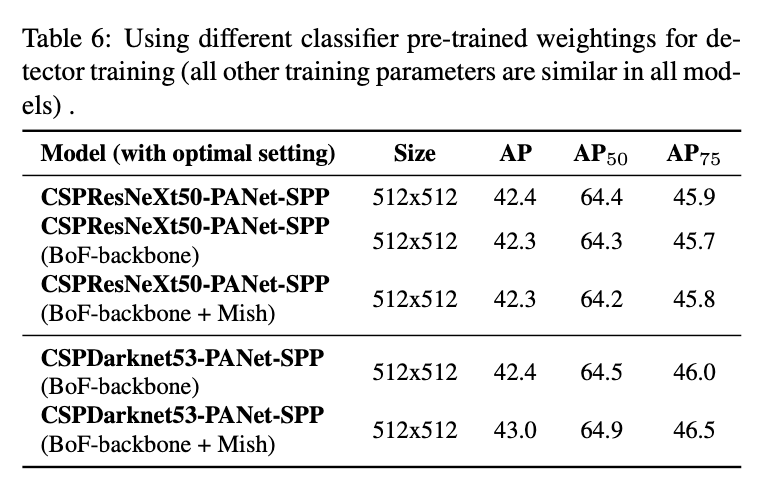
4.4.Influence of different backbones and pre-trained weightings on Detector training
4.5.Influence of different mini-batch size on Detector training
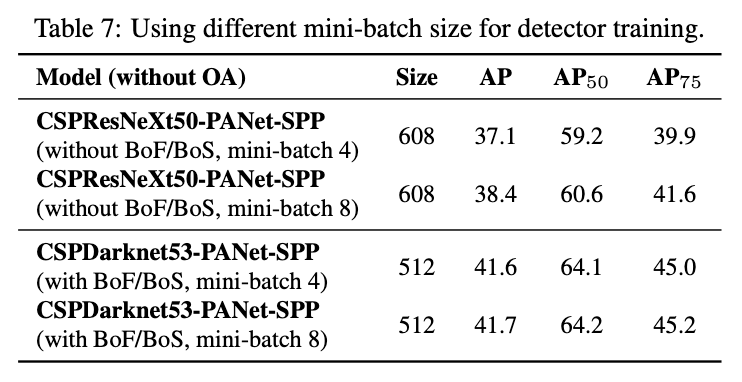
从表7中可以看出,在添加BoF和BoS之后,mini-batch size对性能的提升就不明显了。这一结果说明在引入BoF和BoS之后,就不再需要使用过于昂贵的GPU资源来进行训练了。
5.Results
和其他SOTA的目标检测方法的比较见Fig8。
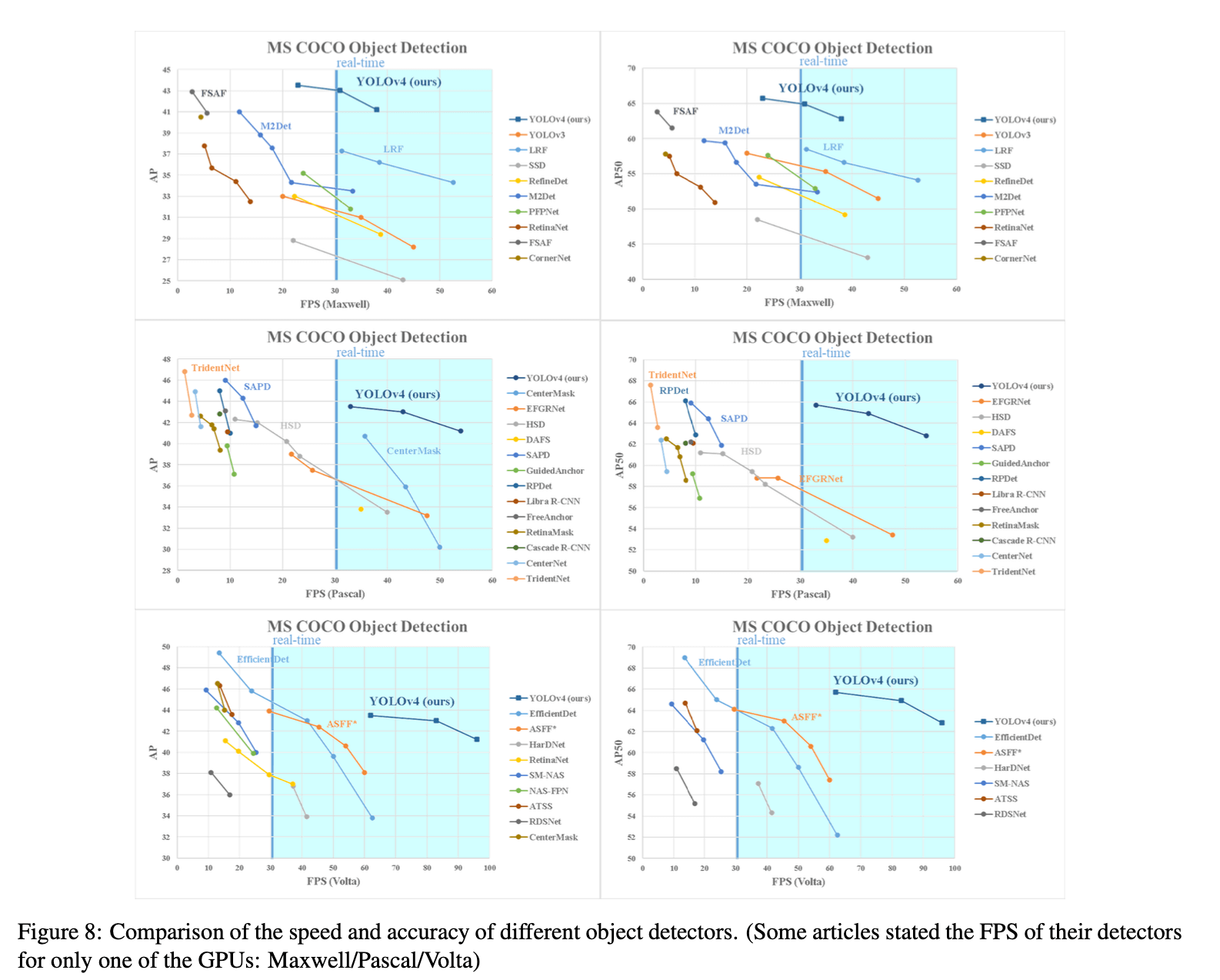
我们还测试了SOTA方法在不同GPU架构上的表现。表8是在Maxwell GPU(比如GTX Titan X (Maxwell)或Tesla M40 GPU)上的测试结果:
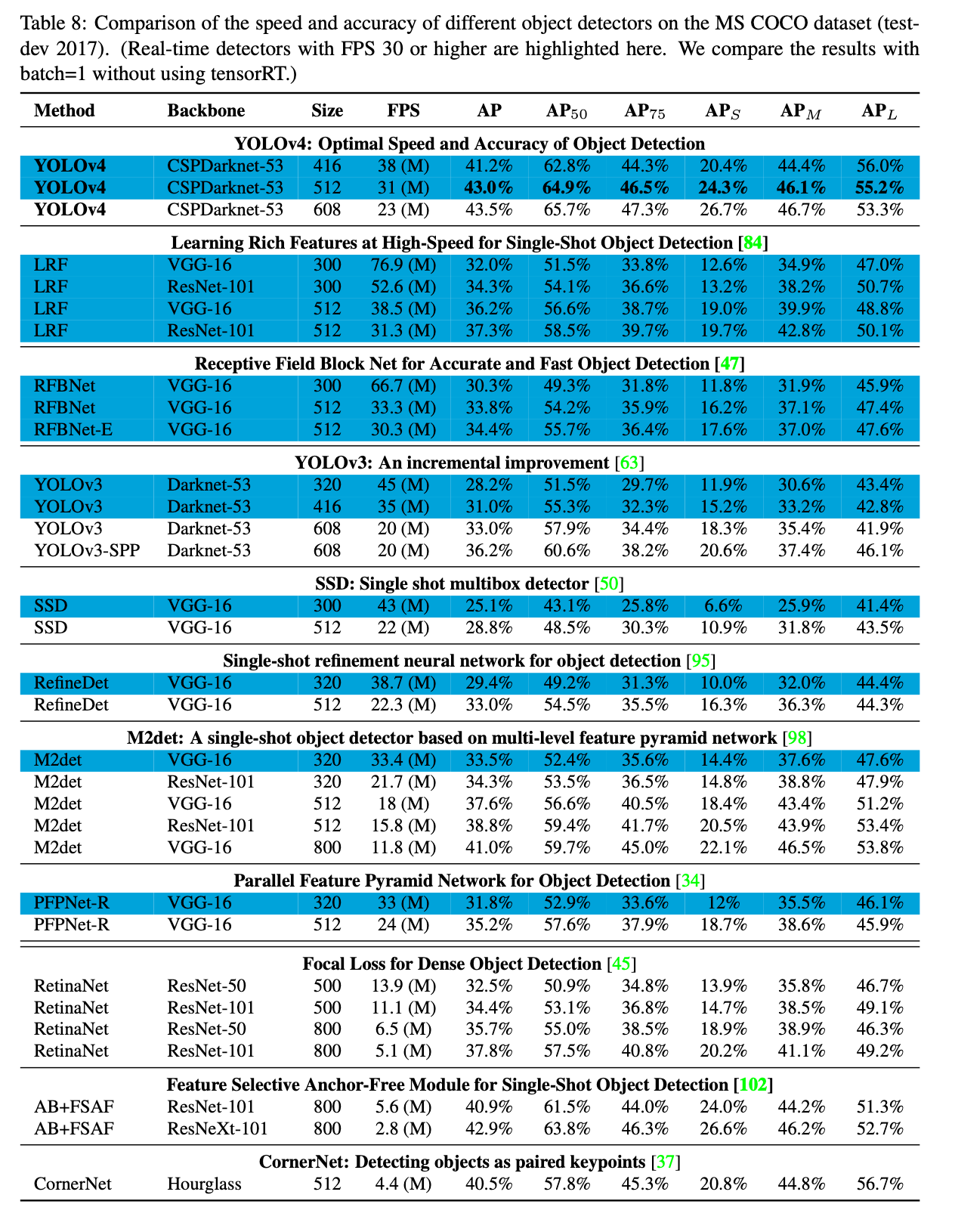
表9是在Pascal GPU(比如Titan X (Pascal),Titan Xp,GTX 1080 Ti或Tesla P100 GPU)上的测试结果:

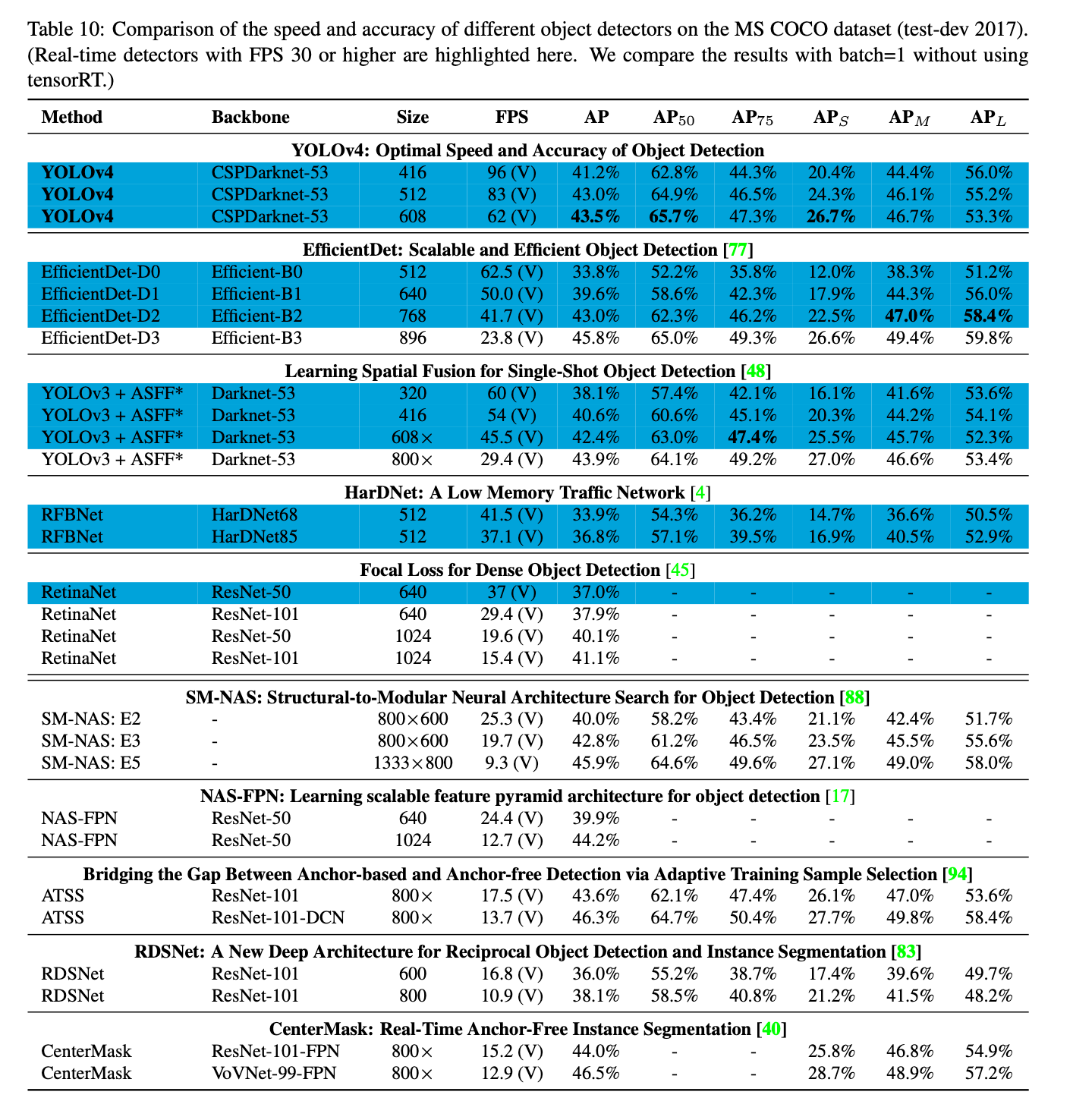
表10是在Volta GPU(比如Titan Volta或Tesla V100 GPU)上的测试结果:
6.Conclusions
不再详述。
7.原文链接
👽YOLOv4:Optimal Speed and Accuracy of Object Detection
