本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.GPT1
原文链接:Improving Language Understanding by Generative Pre-Training

Google在2017年6月发表了著名的Transformer,在一年之后,OpenAI在2018年6月发表了文章Improving Language Understanding by Generative Pre-Training,即我们所谓的GPT1,GPT就是Generative Pre-training Transformer的缩写。GPT1的核心技术就是利用Transformer的解码器,在大量没有标签的文本数据上预训练得到一个语言模型,然后再在子任务上进行fine-tune,这个套路和CV基本一样。
然后在4个月之后,也就是2018年10月,Google发表了BERT,其和GPT1相反,BERT只使用了Transformer的编码器,然后使用一个更大的数据集来进行预训练,结果比GPT1好了很多。BERT有两种大小的模型:BERT-Base和BERT-Large,其中BERT-Base的大小和GPT1差不多,但性能要更好,BERT-Large就不用说了,性能相比BERT-Base得到进一步提升。
OpenAI一看,这不行啊,于是在2019年2月推出了GPT2,依旧坚持解码器的思路,但是使用了更大的数据集,训练了一个更大的模型,比BERT-Large还要大。但是效果并不是特别的惊艳。因此,OpenAI在2020年5月继续推出了GPT3。相比GPT2,GPT3的数据量和模型大小都变大了100倍,终于暴力出奇迹,GPT3的效果非常惊艳。
接下来进入正题,介绍下GPT1这篇论文。
在摘要中,作者提出,在NLP领域,大量的数据是没有标签的,只有少部分数据是带有标签的,如果只使用这些带有标签的少量数据来训练模型的话,模型性能通常不会太好。因此,我们就先在大量没有标签的数据上进行预训练(即Generative Pre-Training),然后再在带有标签的子任务上进行fine-tune(这一套流程称为半监督学习或自监督学习)。在CV领域,这是一种很常见的套路,因为在CV领域,我们有很多像ImageNet这样带有标签的大型数据集去做预训练,但是在NLP领域,我们并没有带有标签的大型数据集去做预训练,所以这在一定程度上阻碍了深度学习在NLP领域内的发展。因此,GPT1和BERT的出现,让人们知道我们在没有标签的大量数据上去做预训练也是可以的。
那么使用没有标签的数据进行预训练通常会面临两个问题:1)不知道怎么去定义损失函数;2)如何把预训练学到的表征以一种统一有效的方式传递给下游不同的子任务。
我们首先来介绍如何在没有标签的数据集上进行预训练。假设我们有一个文本$\mathcal{U} = \{ u_1,…,u_n \}$,其中$u_i$是第$i$个词。我们使用一个标准语言模型的目标函数,即最大化以下似然函数:
\[L_1 (\mathcal{U}) = \sum_i \log P(u_i \mid u_{i-k}, ... , u_{i-1} ; \Theta)\]注意公式里的$L_1$指的不是$L_1$范式,这里只是目标函数的一个表示。
我们把$u_i$前面连续的$k$个词,即$u_{i-k},…,u_{i-1}$,喂给我们的语言模型$\Theta$,预测得到这$k$个词之后的下一个词是$u_i$的概率,即$P$,我们当然希望这个概率越大越好。$k$表示上下文窗口大小。
Transformer主要有两个结构,一个是编码器,一个是解码器。对于编码器来说,当一个序列进来,在对第$i$个词进行特征抽取的时候,它是能够看到整个序列里的所有元素的。但是对于解码器来说,因为有mask的存在,在预测第$i$个词的时候,它只能看到第$i$个词之前的词,而看不到之后的词。因此,我们的语言模型$\Theta$使用的是Transformer的解码器。
\[h_0 = UW_e + W_p\] \[h_l = \text{transformer_block} (h_{l-1}) \forall i \in [1,n]\] \[P(u) = \text{softmax} (h_n W_e^T)\]其中,$U = (u_{-k},…,u_{-1})$是我们喂给模型的$k$个词,$W_e$是词嵌入矩阵,$W_p$是位置信息的编码矩阵,$n$是transformer_block的层数(因为transformer_block不会改变输入输出的形状,所以上一个block的输出可以直接拿来做下一个block的输入)。最后通过一个softmax函数得到下一个词是$u$的概率。
而BERT并没有使用标准语言模型的目标函数,它使用的是一个带mask的语言模型,类似于完形填空的做法,即把序列中间的一个词挖掉让模型去预测,也就是说在预测的时候,模型即可以看到之前的词,也可以看到之后的词,所以BERT使用了Transformer的编码器作为它的模型。相比看来,GPT1的做法要更难一些。
接下来说下如何在下游子任务上进行fine-tune。假设序列$x^1,…,x^m$的标签为$y$,我们将这个序列喂给已经预训练好的模型,得到最后一个transformer_block的输出$h_l^m$,我们对$h_l^m$进行线性变换$W_y$后通过softmax函数得到预测结果为$y$的概率:
\[P(y \mid x^1, ... , x^m) = \text{softmax} (h_l^m W_y)\]相应的目标函数为:
\[L_2 (\mathcal{C}) = \sum_{(x,y)} \log P (y \mid x^1 , ... , x^m)\]作者提出在fine-tune时,可以把$L_1$目标函数也考虑进来,于是fine-tune阶段最终的目标函数为:
\[L_3 (\mathcal{C}) = L_2 (\mathcal{C}) + \lambda * L_1 (\mathcal{C})\]但是NLP领域内的任务多种多样,差异很大,在fine-tune的时候,我们需要把这些不同的子任务统一转换成一段序列和一个标签的格式,这样我们才可以套用上面的fine-tune流程,那么该如何转换呢?
作者以NLP领域内最常见的4种子任务为例,见下图:
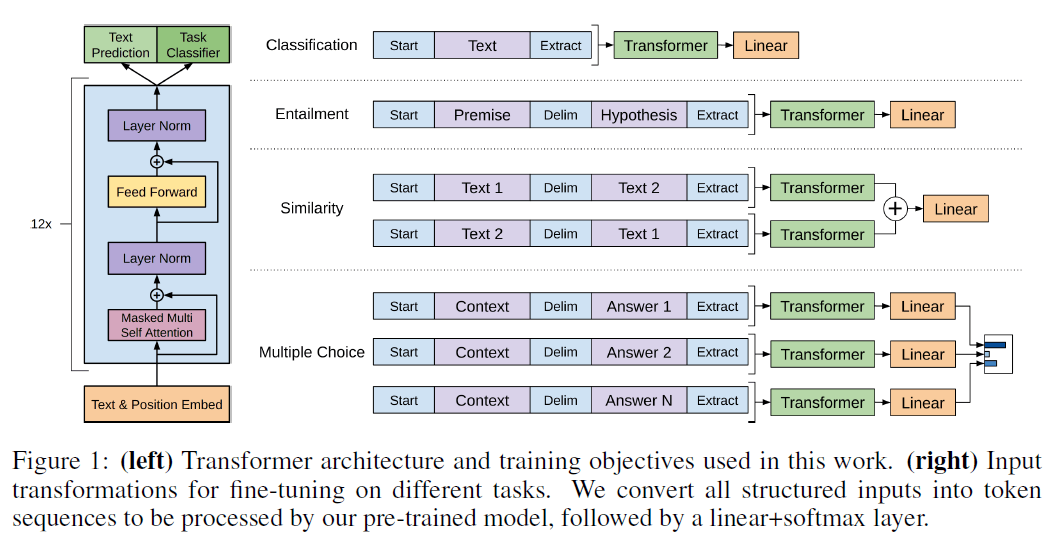
第一个任务是文本分类,给一段文本,得到其分类标签,这其实和我们要的格式基本就是一样的了。我们在文本的开始添加一个特殊的token:Start,在文本的结束也添加一个特殊的token:Extract。然后我们把添加了头尾标识的文本序列喂给transformer解码器模型,并将模型抽取到的特征输入到一个线性层,如果我们要做10分类的话,那么线性层输出的大小就是10。
第二个任务是文本蕴含,即基于一个前提(Premise),我提出一个假设(Hypothesis),模型需要判断这个前提是否能支持我提出的这个假设。举个例子,我给出的前提是:a送给b一束玫瑰,如果我的假设是a喜欢b,那么模型应该推理出这个前提是支持我的假设的,但如果我的假设是a讨厌b,则这个前提是不支持我的假设的,如果我的假设是a和b是邻居,那么这个前提对我的假设既不支持也不反对,所以这是一个3分类的问题。这个任务和第一个任务唯一的不同在于我们如何把输入也变成一个序列。很简单,序列开头依旧是Start,然后接上我们的前提,在前提和假设之间我们加一个分隔符Delim(也是一个特殊的token,注意,这些特殊的token不能是词典里的词),最后依然是Extract,表示序列结束。
第三个任务是相似,即判断两段文本是否相似。这里不再过多解释,原理和上述基本一样,唯一需要注意的就是这里做了两个序列,交换了两段文本的先后顺序。
第四个任务是多项选择。针对每个答案都做一个序列,最后通过线性层输出这个答案是正确答案的置信度。
通过这种形式,无论子任务输入和输出的形式怎么变,transformer模型的结构是不需要变的。这也是GPT1的一个核心卖点。
GPT1预训练使用了一个叫BooksCorpus的数据集,该数据集包含7000本没有发表的书。
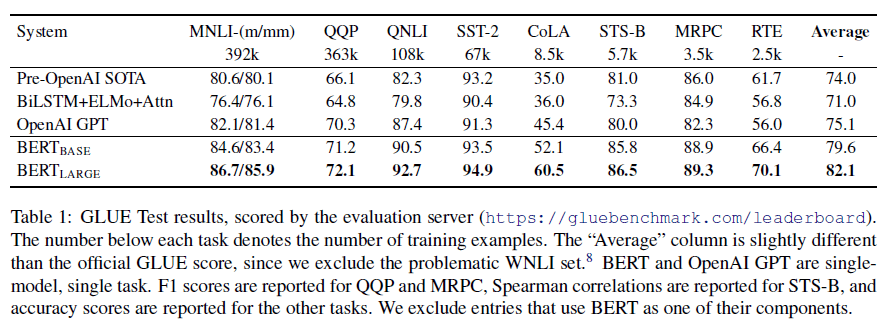
GPT1使用了12层的transformer解码器,每一层的维度是768,使用了12个注意力头。和其大小相当的BERT-Base,也是12层(编码器),维度是768,12个头,其参数量约为110M。而BERT-Large则是24层的编码器,维度是1024,16个头,参数量约为340M。BERT用的数据集也更大一些,它也用了BooksCorpus数据集(800M个词),此外还有English Wikipedia(2500M个词),总数据量几乎是GPT1的4倍。BERT与GPT1的性能比较:
2.GPT2

看到BERT使用更大的数据集,在性能上超过了GPT1,OpenAI决定使用比BERT更大的数据集再打回去,就是要证明我的解码器思路比你的编码器思路要好。GPT2使用了一个新的数据集WebText,包含超过百万的网页文本,模型参数量达到了1.5B,模型结构基本和GPT1一致。但是不幸的是,GPT2的表现相比BERT,优势并不明显。于是,作者另辟蹊径,把zero-shot作为GPT2的核心卖点。

GPT1和BERT都是在大量无标签的数据上进行预训练,然后在带有标签的子任务数据集上进行fine-tune。但这样的话,对于每个子任务,我们都要去收集有标签的数据,还要再训练一遍模型,这都是有成本的。因此我们提出zero-shot,即预训练结束后,在子任务上,我不要有标签的数据,也不需要重新训练我的模型,依旧可以有不错的性能。
对于GPT1,在fine-tune的时候,我们引入了一些特殊的token,比如Start、Delim、Extract,模型在fine-tune时会学到这些符号都是什么意思,但是在GPT2中,我们要做zero-shot,模型是不需要fine-tune的,所以我们就不能引入这些在预训练中模型没有见过的符号。那我们该怎么做呢?作者提出其实在预训练的数据集中,已经有类似这些特殊token作用的词。比如对于文本翻译(具体例子见下表),预训练数据集中的一个序列很可能包含这三个词:translate to french, english text, french text。这些词其实就起到了分隔序列的作用,这些词后来被称为prompt。再比如阅读理解任务,一个序列中可能会包含:answer the question, document, question, answer。

WebText一共包含约800万个文本,共40GB的文字。
这里说下个人理解,GPT2在面临不同的子任务时,都是使用同一个预训练好的模型,根据输入的prompt,模型的输出会有倾向性,但不像GPT1在fine-tune时后面接了一个特定的线性层用于特定的任务,GPT2的输出始终是一段文本。对于GPT2的输入,我们当然也不用像GPT1那样对于不同的子任务进行不同的格式调整,我们给GPT2的输入也是和预训练集类似,贴近正常生活中的描述,模型会自动提取描述中关键的prompt,从而知道用户想要做什么。
3.GPT3

GPT2的性能并不算是非常的惊艳,所以OpenAI觉得可能是zero-shot还是太难了,于是他们就退一步尝试了few-shot,即在子任务上,还是提供少量带标签的数据,作者还举了人类的例子,当人类碰到一个新任务时,并不需要大量的示例来学习,仅仅需要几个示例便可以举一反三掌握这个新任务,但也不能完全不给示例。因此,OpenAI就重新预训练了一个模型,即GPT3,它有175B个参数,在下游子任务上,虽然使用了few-shot,但依然不需要fine-tune(毕竟这么大的模型,fine-tune的代价也不是一般人负担的起的)。GPT3在很多NLP数据集上都取得了很好的成绩。
对于每种任务,都在3种情况下评估了GPT3:1)few-shot,提供10-100个带有标签的数据;2)one-shot,提供1个带有标签的数据;3)zero-shot,不提供带有标签的数据。结果见下图,虚线是在每个子任务上的表现,实线是平均精度。
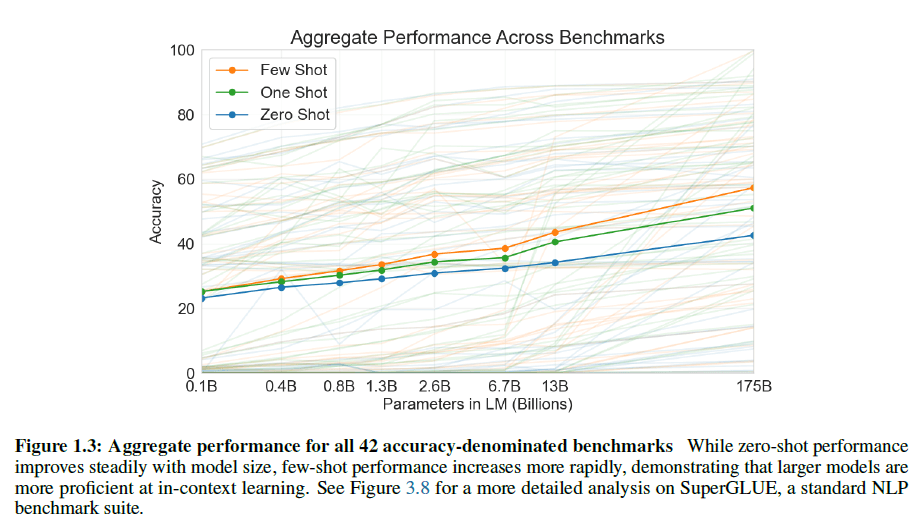
GPT2接近上图1.3B的模型,其zero-shot的平均精度只有20%多,而GPT3在使用few-shot的情况下,平均精度达到了将近60%,性能相比GPT2翻了一倍。

上图是对few-shot、one-shot、zero-shot以及传统fine-tune更加直观的介绍。注意,few-shot、one-shot、zero-shot都不会去更新模型梯度。
但是few-shot也存在2个问题:1)因为模型处理不了太长的序列,如果在子任务上,我们真的有很多带有标签的高质量数据,也无法都放在few-shot里去处理;2)假设few-shot得到的结果确实还不错,zero-shot的效果就差很多,那为了获得更好的性能,我们需要每次都输入一些例子,因为模型并不会把从这些例子学到的知识保留下来(因为没有模型的更新)。
GPT3使用了基本和GPT2一样的模型框架,一共有8种不同大小的模型。
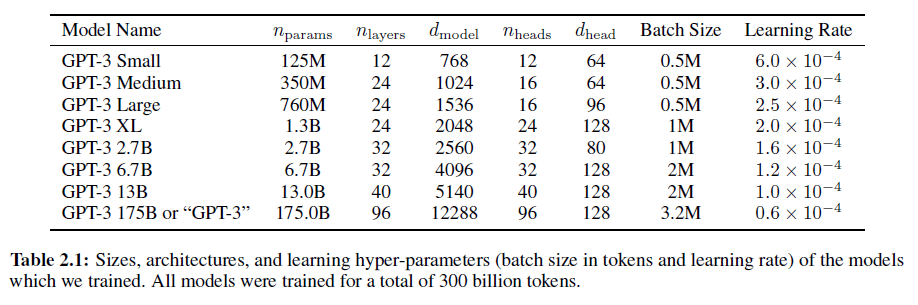
可以看到,175B模型的batch size就达到了惊人的320万,没有个几百上千台机器做并行化还真训练不下来。
GPT3所用的训练数据见下。
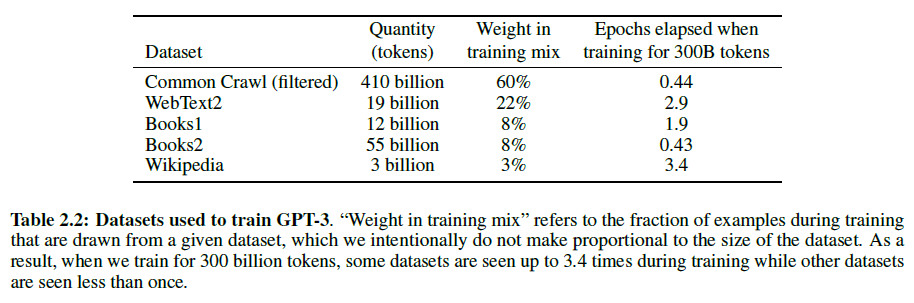
从上图我们可以看到,一个batch内对各个数据集的采样率是不同的,因为Common Crawl的数据质量相对较低,所以我们需要保证一个batch内还是有一定量的高质量数据。
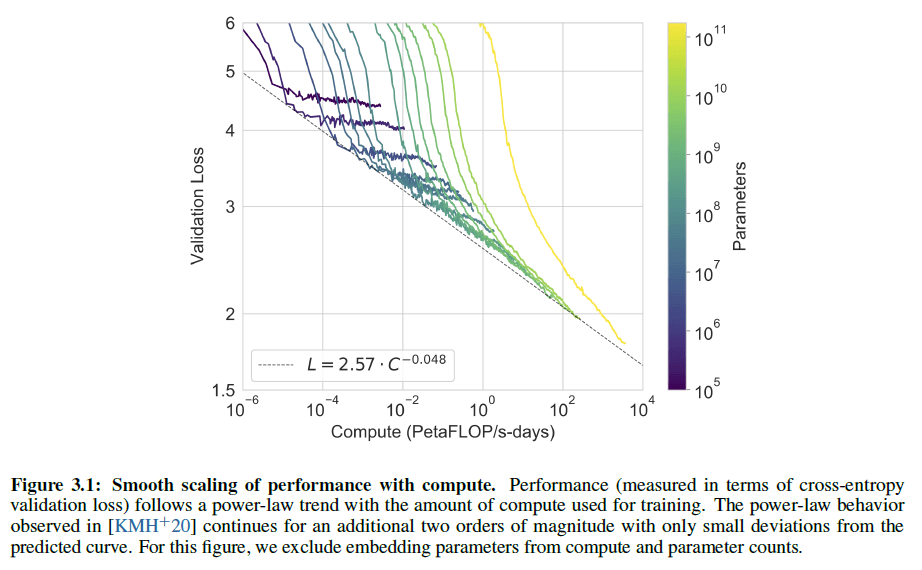
从上图可以看出,在数据量不变的情况下,随着模型计算量呈指数倍的增加,loss呈线性下降的趋势。
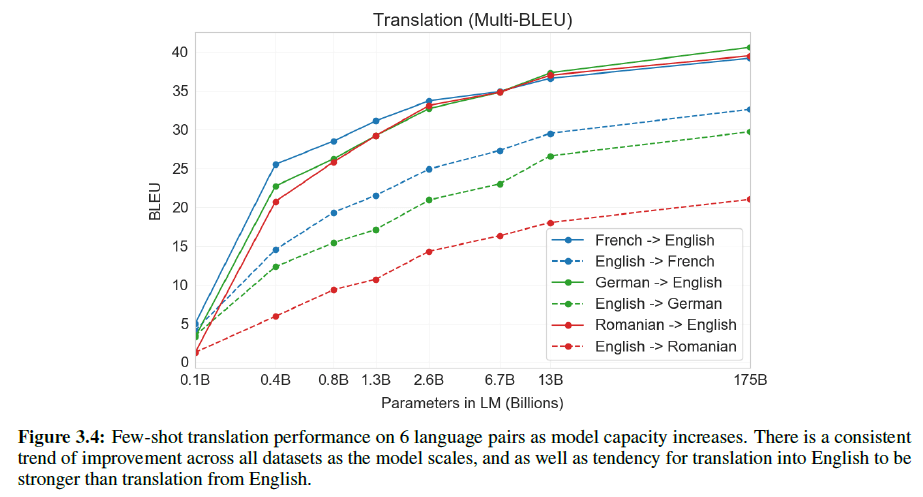
从上图可以看出,对于GPT3,其他语言翻译成英语的效果要优于英语翻译成其他语言。
最后,作者也提出GPT3可能存在的一些安全问题,比如信息造假、性别偏见、种族偏倚、宗教歧视等。
4.InstructGPT
原文链接:Training language models to follow instructions with human feedback

这两年爆火的ChatGPT的核心技术是GPT3.5,其模型框架和InstructGPT一样。InstructGPT发表于2022年的3月。
首先在摘要中,作者提出越大的语言模型并不代表着其可以按照用户的意图来做事情,它可能会生成一些虚假的、有害的内容。这些安全性上的考虑对于一个基于机器学习的工业应用来说是非常重要的,比如Google的照片识别功能将黑人识别成黑猩猩、Facebook的AI算法将黑人视频加了一个灵长类动物的标签等等,这些都是不可接受的,对应的AI功能也都被紧急下架或调整。因此,作者团队就提出通过人类的反馈对模型进行fine-tune,从而使得模型可以按照人类的意图做正确的事情。
InstructGPT是基于GPT3 fine-tune得来的,过程中使用了一种叫做RLHF(Reinforcement Learning from Human Feedback)的强化学习方法。整个过程分3个步骤,详细见下图:
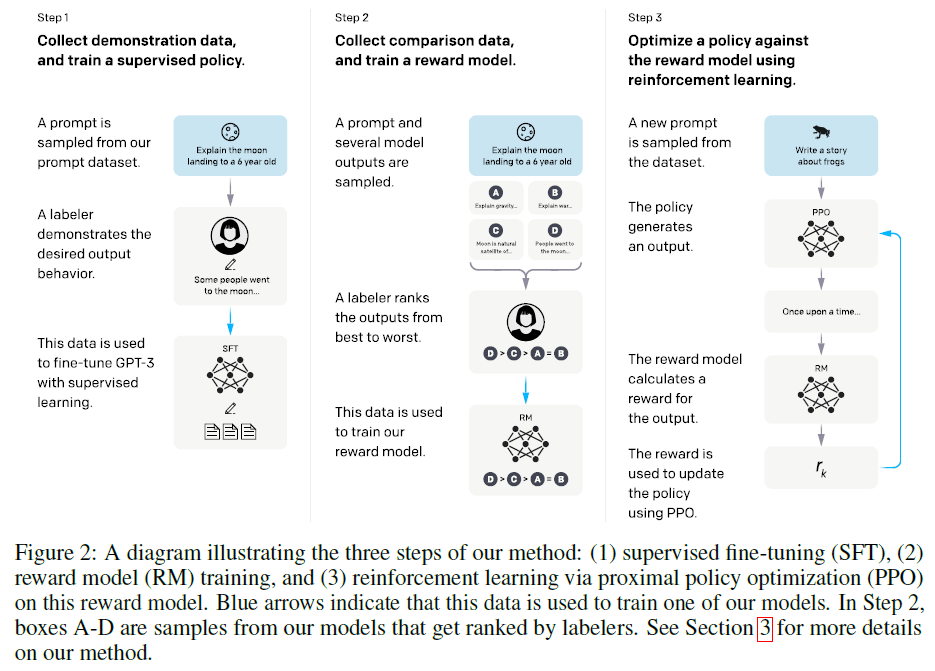
在第一步中,先是收集了一些问题,然后对这些问题进行人工回答,用这些问答数据对GPT3进行有监督的fune-tine,我们将得到的模型记为SFT(supervised fine-tuning)。一共训练了16个epoch,residual dropout为0.2,其实训练一个epoch就过拟合了,但是作者发现即使过拟合了,再继续训练多个epoch,有利于RM模型的训练。如果选择GPT3-1.3B和GPT3-6B,则设置学习率为9.65e-6、batch size为32,如果选择GPT3-175B,则设置学习率为5.03e-6、batch size=8。但是人工去回答问题是很费时间且昂贵的一件事情,我们不太可能去让人工回答大量的问题,所以就有了第二步。
在第二步中,我们收集了更多的问题,然后让SFT针对每个问题去生成多个答案,比如每个问题生成4个答案:A、B、C、D。接着我们让人工去对这些答案进行排序,比如答案D是最好的,答案C次之,答案A和B最差,即D>C>A=B。然后我们训练一个RM(奖励模型,reward model)模型,RM模型本质也是一个GPT3模型,但是在最后面加了一个FC层,这样使得GPT3模型可以输出一个标量,作为排序分数。最终选择了GPT3-6B作为RM模型,因为GPT3-175B不稳定。RM模型的输入是一对问题和答案,输出是排序分数。损失函数为pairwise ranking loss:
\[\text{loss} (\theta) = -\frac{1}{\dbinom{K}{2}} E_{(x,y_w,y_l) \sim D} [\log (\sigma (r_{\theta} (x,y_w) - r_{\theta}(x,y_l)))]\]其中,$r_{\theta}$是RM模型的输出,$x$是问题,$y_w$是好一点的答案,$y_l$是差一点的答案,$K$是针对每个问题生成的答案数量(作者取$K=9$),$\sigma$是sigmoid函数。还以上图为例,如果$y_w$表示答案D,那么$y_l$可以是[A,B,C]中的任意一个,如果$y_w$是答案C,那么$y_l$可以是[A,B]中的任意一个,如果$y_w$是答案A,那么$y_l$就是答案B。而上式的目的就是通过最小化loss把好答案的排序得分和坏答案的排序得分拉开的越大越好。
第三步我们会用到强化学习中的PPO(proximal policy optimization)算法(是OpenAI在2017年发表的)。在强化学习中,我们将模型也称为policy。在PPO算法中,我们依旧是使用GPT3模型,记作$\pi_{\phi}^{RL}$,我们用第一步得到的模型$\pi^{SFT}$来初始化$\pi_{\phi}^{RL}$。首先,我们先挑选问题,然后将问题输入给$\pi_{\phi}^{RL}$得到答案,再将问题和答案一起喂给第二步训练好的RM模型,得到排序分数$r_k$,这个$r_k$会被反馈回给$\pi_{\phi}^{RL}$,$\pi_{\phi}^{RL}$进行梯度更新以获得更好的结果,即得到排序分数更高的答案,这个过程会重复多次。第三步所用的目标函数见下:
\[\text{objective} (\phi) = E_{(x,y) \sim D_{\pi_{\phi}^{RL}}} [r_{\theta} (x,y) - \beta \log (\pi_{\phi}^{RL} (y \mid x) / \pi^{SFT} (y \mid x) )] + \gamma E_{x \sim D_{pretrain}} [\log (\pi_{\phi}^{RL} (x))]\]我们的目标就是最大化这个目标函数。$r_{\theta}(x,y)$是RM模型的输出,注意这里的$x$是问题,是不变的,$y$是答案,随着$\pi_{\phi}^{RL}$的更新,每次答案都是不一样的,最大化目标函数会迫使$r_{\theta}$得到的排序分数越来越高,即使得$\pi_{\phi}^{RL}$输出的答案越来越好。$\beta \log ( \pi_{\phi}^{RL}(y \mid x) / \pi^{SFT}(y \mid x) )$是一个正则项,使用了KL散度,用于控制$\pi_{\phi}^{RL}$的输出不会偏离$\pi^{SFT}$太远,即不会得到太离谱的输出,这一项也是PPO算法的核心思想。前面这两项都是针对某些特定任务的,即基于我们标注的那些数据,为了不牺牲模型在不同NLP任务上的通用性,这里加了第三项$\log ( \pi_{\phi}^{RL}(x) )$,这一项是在GPT3预训练数据集上计算的,是一个常规的语言模型的目标函数,即输入序列,预测下一个词,这样保证在新的数据上做拟合,但是原始的数据也不要丢。$\gamma$用于控制模型偏向原始预训练数据的程度。如果$\gamma=0$,我们将模型称为PPO模型;如果$\gamma \neq 0$,我们将模型称为PPO-ptx模型,即我们通常所说的InstructGPT。
各步骤使用的数据量见下:
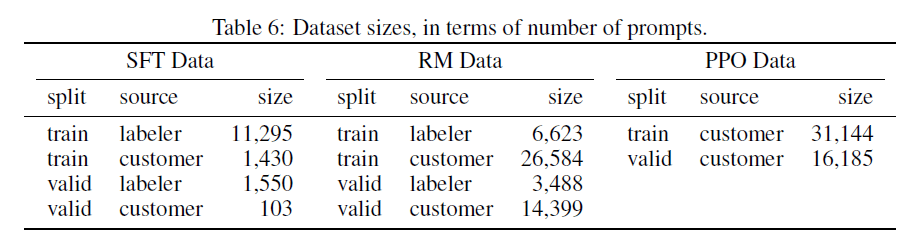
“labeler”表示是由标注工标注的数据,“customer”表示收集用户在使用过程中的数据(通过API收集)。
与SFT-175B模型相比,不同模型的胜率见下(获胜指的是输出的答案更好):
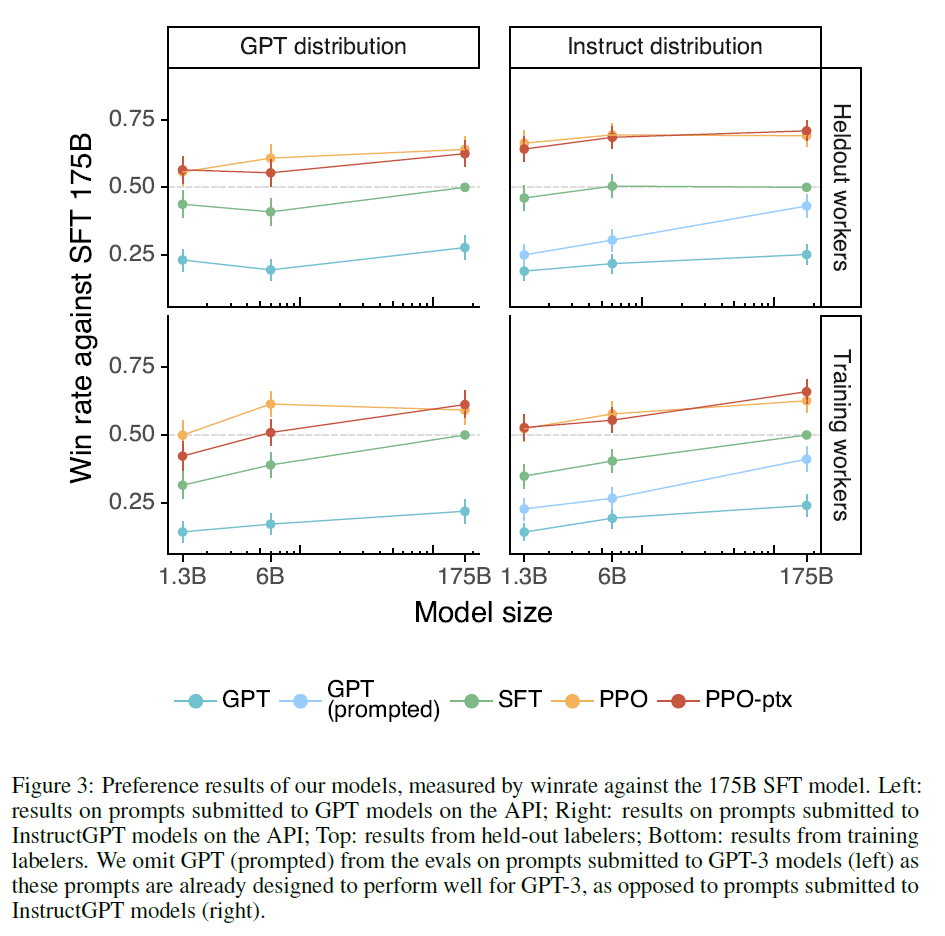
相比GPT3预训练,InstructGPT的训练成本很低,毕竟也就只用了几万个样本。
5.GPT4

OpenAI在2023年3月发布了GPT4,声称其为一个多模态模型,可以在输入端接收图片或文本,输出只能是文本(并不能输出图片)。并且在OpenAI发布的长达100页的GPT4技术报告里并没有介绍任何的技术细节(模型、数据、训练方法等都没说),所以被人们戏称为CloseAI。所以这里只列出一些GPT4的测试结果。
在律师资格证考试中,GPT3.5的成绩只能排到后10%,但GPT4的成绩就来到了前10%,以优异的成绩通过了律师资格证考试。
对于GPT4这种体量的模型,如果每次跑完才知道结果,才知道这组参数好不好,才知道这个想法是否work,那这个花销实在是太大了。一般我们都会先在较小的模型和数据集上做消融实验,看哪个work了,然后我们再在大模型上去做实验。但可惜的是,对于语言模型来说,因为其模型扩展的太大了,所以往往导致在小模型上做的实验是work的,但是换到大模型上就不work了。此外,大模型所特有的涌现能力,在小模型那边也观测不到。就算有机器有钱,像GPT4这样的大模型,训练一次也得一两个月,这个时间是非常久的。因此在这篇技术报告里,OpenAI就提出我们通过在小规模计算成本下训练出来的模型,可以准确预估大模型最后的性能。OpenAI将其称为predictable scaling,具体见下图。
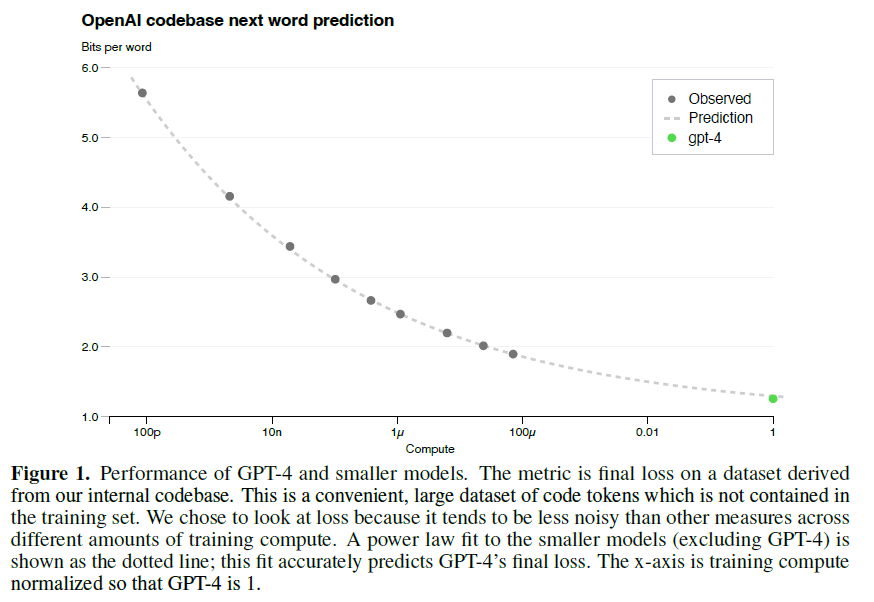
图中绿色点表示GPT4最终的loss结果,黑色点都是之前训练过的模型所能达到的最小loss。纵坐标可以简单理解成loss大小。横坐标表示用了多少算力(把模型大小和数据集大小都考虑在内),如果我们把GPT4的算力定义为1,那横坐标从右往左依次是:$0.01=10^{-2}$、$100 \mu = 10^{-4}$、$1 \mu = 10^{-6}$、$10n = 10^{-8}$、$100p = 10^{-10}$。然后我们发现,这些模型的loss曲线真的就拟合出来了。因此OpenAI就用$100 \mu$这个模型准确推导出了GPT4的loss。有了这项技术的加持,就意味着在同等资源下,可以尝试更多的方法、更多的参数,从而得到更优的模型。
下图是GPT3.5和GPT4在各种人类考试中的表现。
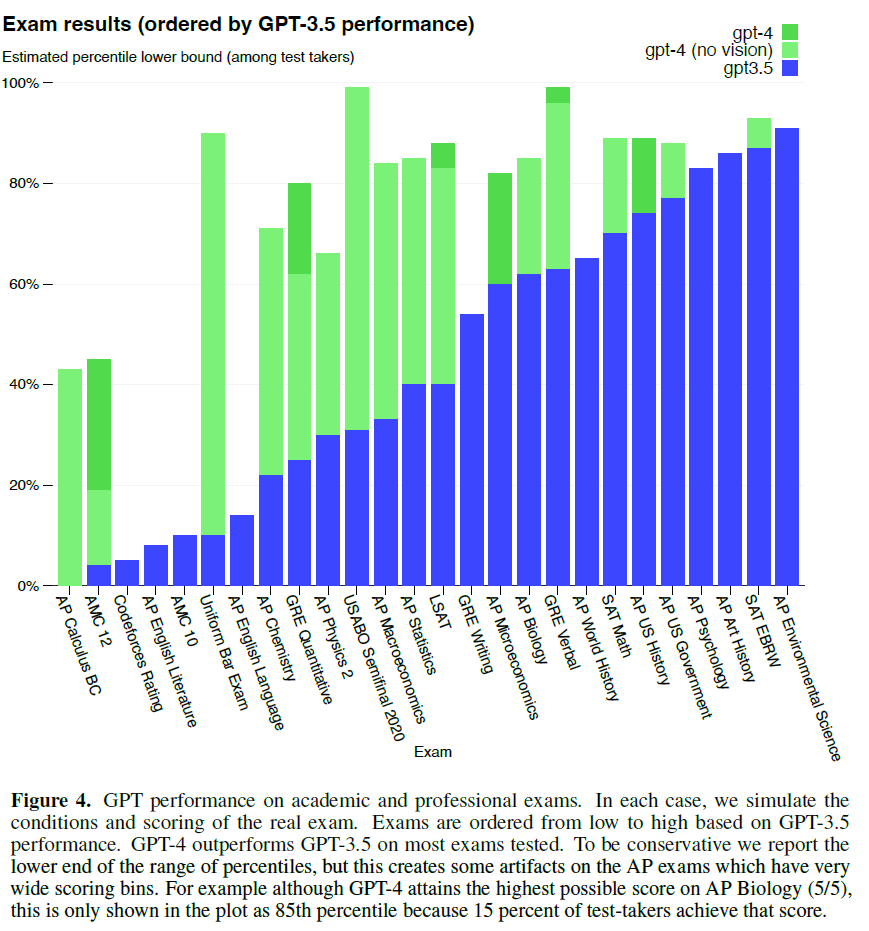
蓝色是GPT3.5的表现,浅绿色是GPT4在不输入图片情况下的表现,深绿色是GPT4在有图片输入加持下的表现。从上图可以看出,GPT系列在数学(AP Calculus BC、AMC 12、AMC 10)上的表现不太行。
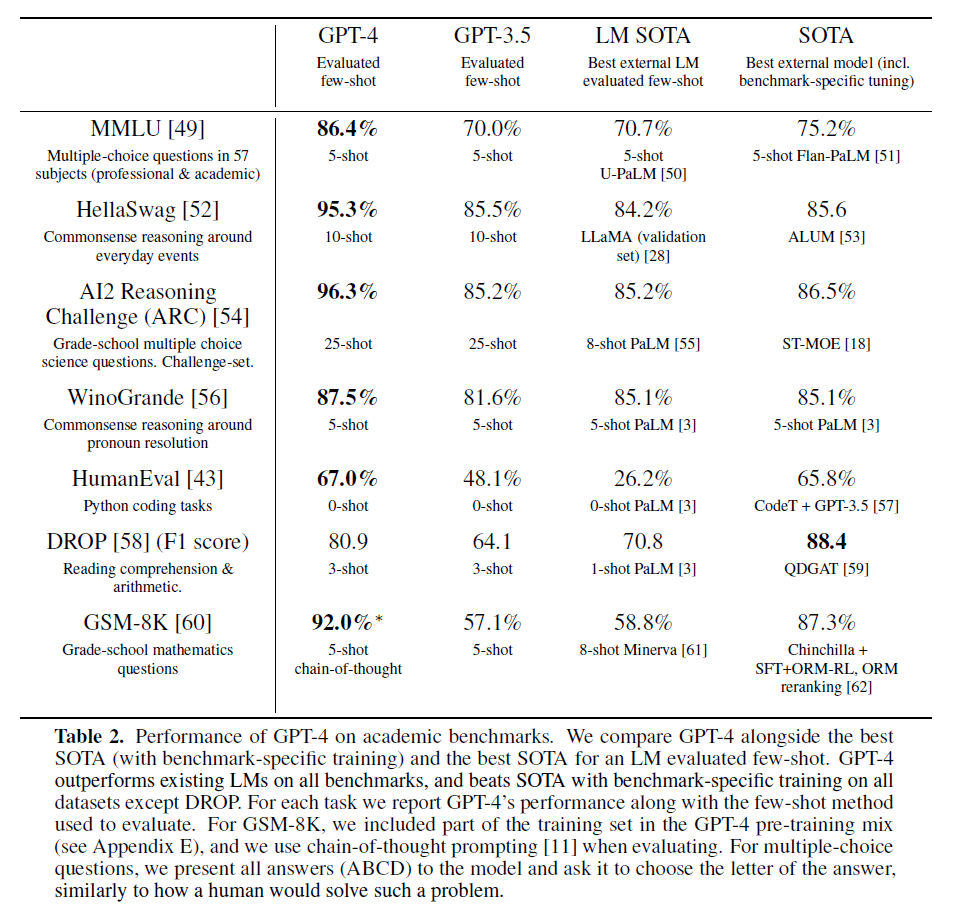
在NLP常见的benchmark上的测试结果见下:
GPT4在不同语言上的表现:
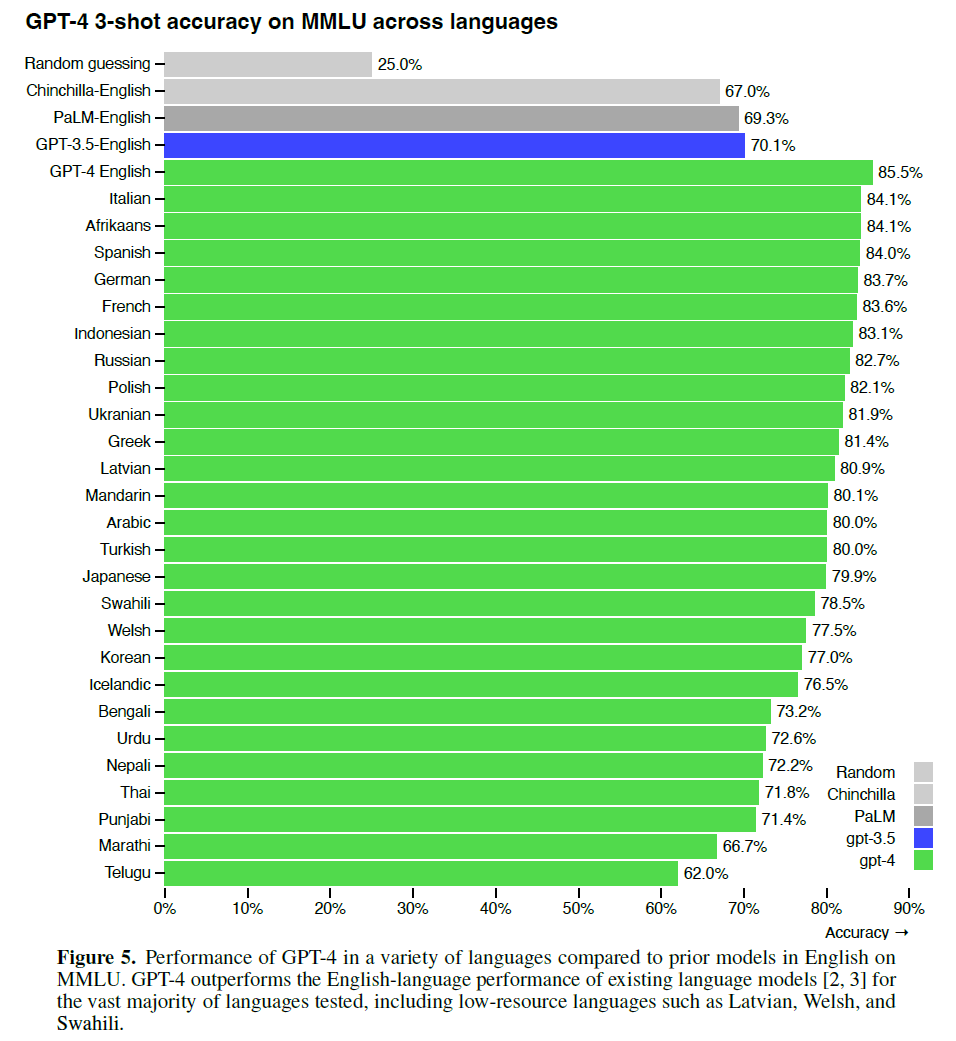
测试方式是通过做四选一的选择题,所以随机猜对的概率就是25%,即图中的第一行。可以看到,GPT4在中文上也有80.1%的高准确率,猜测可能是训练集中加入了大量中文语料库。
GPT4在多模态数据集上的表现:
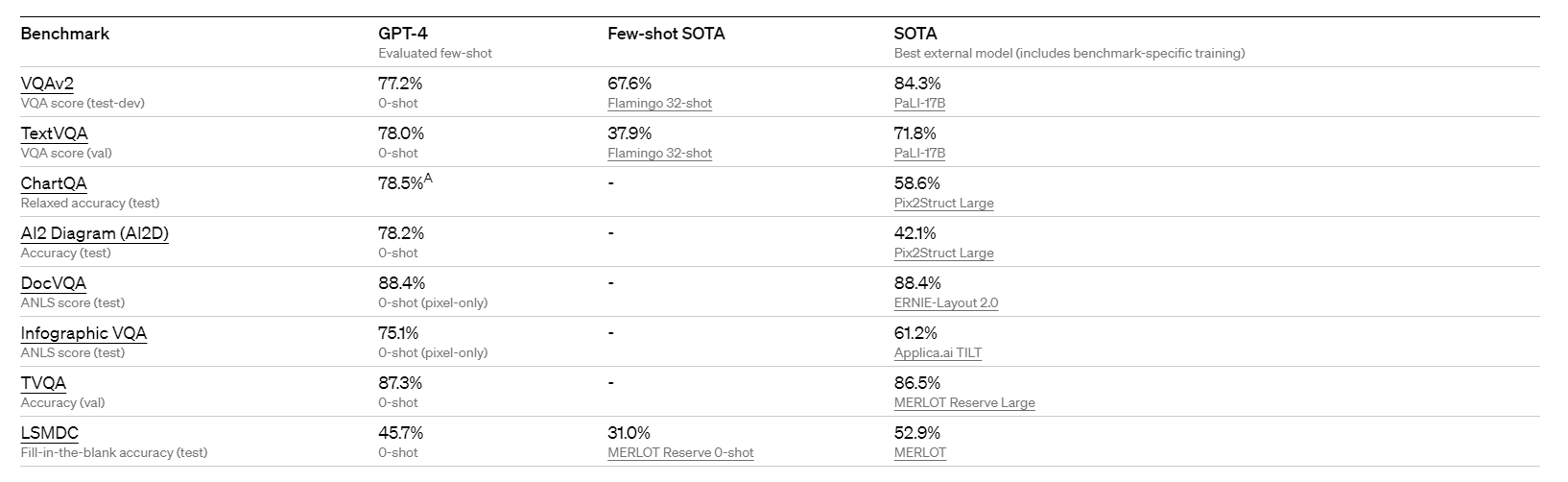
GPT4在安全性上也比GPT3.5要好很多。GPT4已经被集成在ChatGPT Plus中。
GPT4的context length为8192个token(gpt-4-32k提供32768个token的context length,几乎可以塞下一本书了),这意味着GPT4可以记住大量的上下文信息,比如可以把整个PDF输入进去。
也有许多人称GPT系列开启了AGI(Artificial General Intelligence)时代,当然这也是一个仁者见仁智者见智的问题。大语言模型的发展给人们带来了惊喜和便利之外,也让人们恐慌自己会不会被AI替代。于是,OpenAI就大语言模型对劳动市场的影响进行了研究,文章标题见下:

有兴趣的可以自己去搜一下这篇文章,这里不再过多介绍。
