本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
针对姿态估计和追踪,本文提出的方法简单且有效。
我们的姿态估计使用ResNet作为backbone,并在此基础上加了一些反卷积层。
我们的姿态追踪使用和ICCV’17 PoseTrack Challenge冠军相似的pipeline。所用的单人姿态估计模型还是上述我们提出的方法。姿态追踪部分使用和冠军一样的贪心匹配方法。我们唯一的修改是使用基于光流的姿态传播和相似度计算。
ICCV’17 PoseTrack Challenge冠军:Girdhar, R., Gkioxari, G., Torresani, L., Paluri, M., Tran, D.: Detect-and-track: Efficient pose estimation in videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 350–359 (2018)。
2.Pose Estimation Using A Deconvolution Head Network
我们的方法就是简单的在ResNet最后一个卷积阶段(即$C_5$)之后又加了几个反卷积层。整体网络架构见Fig1(c)。

默认情况下,会添加3个反卷积层,并且会使用BatchNorm和ReLU激活函数。每层使用256个大小为$4 \times 4$的filter。步长为2。最后会有一个$1\times 1$卷积来生成预测heatmap:$\{ H_1 … H_k \}$,分别对应$k$个关键点。
预测heatmap和GT heatmap之间的MSE被用作loss。此外,我们还和Hourglass、CPN(Cascaded Pyramid Network)进行了比较,见Fig1,在此不再详述。
3.Pose Tracking Based on Optical Flow
针对视频中的多人姿态追踪来说,首先要检测每一帧中每个人的姿态,然后要对每个人赋予一个唯一的id用于追踪。对于帧中的每个人物实例,我们用$P$来表示,有
\[P=(J,id)\]其中,id是这个人物实例唯一的追踪标号,
\[J=\{ j_i \}_{1:N_J}\]表示$N_J$个身体关键点的坐标。假设我们正在处理第$k$帧,我们将这帧记为$I^k$,上一帧记为$I^{k-1}$,$I^{k-1}$帧的检测结果记为
\[\mathcal{P}^{k-1} = \{P_i^{k-1} \}_{1:N_{k-1}}\]$I^k$帧的检测结果记为
\[\mathcal{P}^k = \{ P_i^k \}_{1:N_k}\]其中,$N_{k-1}$和$N_k$分别表示$I^{k-1}$帧和$I^k$帧中人物实例的数量。如果$I^k$中的人物$P_j^k$和$I^{k-1}$中的$P_i^{k-1}$是同一个人,则可以直接把$id_i^{k-1}$赋给$id_j^k$,因为同一个人的id应该是一样的。如果$P_j^k$是一个新出现的人物,则我们得赋给他一个新的id。
ICCV’17 PoseTrack Challenge冠军解决多人姿态追踪的方式是,先用Mask R-CNN估计人物姿态,然后使用贪心二分匹配算法(a greedy bipartite matching algorithm)逐帧进行在线追踪。
贪心匹配算法的策略是,首先如果$I^{k-1}$帧中的人物$P_i^{k-1}$和$I^k$帧中的$P_j^k$的相似性在两帧之间所有可能的人物配对中是最高的,则把$P_i^{k-1}$的id赋给$P_j^k$。然后不考虑这两个已经配对的人物实例,对剩余的人物实例重新配对(注意配对的两个人物实例必须属于不同帧),寻找相似性最高的配对,并执行和之前同样的操作。如果$I^{k-1}$中的所有人物实例都已经匹配完了,但$I^k$中还剩有未被匹配的人物实例,则意味着这个人物是新出现的,需要赋给他一个新的id。
我们遵循了ICCV’17 PoseTrack Challenge冠军的pipeline,但做了2处修改。第一处修改是bounding box,我们的方法中,有2种不同类型的box,一种类型的box是人物检测器检测到的,另一种类型的box是上一帧通过光流算法推算出来的。第二处修改是贪心匹配算法中相似性计算的方式。我们使用了一种基于流的姿态相似性指标。我们所提出的基于流的姿态追踪算法的框架见Fig2。

3.1.Joint Propagation using Optical Flow
如果直接对单帧图像进行人物检测(可用方法比如有Faster-RCNN、R-FCN等),很可能会因为运动模糊或者遮挡造成漏检或误检。如Fig2(c)所示,由于快速运动,左侧穿黑衣服的人就被漏检了。我们可以通过时序信息进行更稳健的检测。
我们可以基于相邻上一帧,通过光流算法在当前帧中生成human box。
将$I^{k-1}$帧中第$i$个人物实例的关键点坐标集合记为$J_i^{k-1}$,从$I^{k-1}$到$I^k$的光流场记为$F_{k-1 \to k}$,根据光流场,我们可以推算出$J_i^{k-1}$在$I^k$帧中的位置为$\hat{J}_i^{k}$。具体来说,假设$J_i^{k-1}$中某一关键点的坐标为$(x,y)$,该点的光流为$(\delta x, \delta y)$,则根据光流,该关键点在$I^k$帧中的位置被推算为$(x+\delta x, y+\delta y)$。在$I^k$帧中,基于$\hat{J}_i^k$,我们可以得到一个bounding box(所有关键点的x,y坐标的最小/最大值记为$x_{min},x_{max},y_{min},y_{max}$,则点$(x_{min},y_{min})$和点$(x_{max},y_{max})$便可确定一个bounding box,在实际实现时,会将bounding box再扩大15%)。如Fig2(c)所示,我们从Fig2(a)中根据光流推算出了最左侧黑衣服人的bounding box。
3.2.Flow-based Pose Similarity
使用IoU作为相似性指标(记为$S_{Bbox}$)是有问题的,比如当人物实例移动的过快从而导致box之间没有重叠部分,或者在拥挤的人群中,使用$S_{Bbox}$都是不合适的。一个更细粒度的相似性指标是姿态相似性($S_{Pose}$),即使用OKS计算两个实例之间关键点的距离。但同一个人物实例在不同帧之间的姿态可能是不一样的,所以$S_{Pose}$也是有问题的。因此,我们提出一种基于流的姿态相似性指标。
给定$I^k$帧中的一个实例$J_i^k$和$I^l$帧中的一个实例$J_j^l$,基于流的姿态相似性可表示为:
\[S_{Flow}(J_i^k, J_j^l) = OKS(\hat{J}_i^l,J_j^l) \tag{1}\]其中,根据光流场$F_{k \to l}$,我们可以推算出$J_i^k$在$I^l$中的位置为$\hat{J}_i^l$。
由于遮挡的缘故,一些人物实例可能会消失或重新出现。所以只考虑连续的两帧可能是不够的,因此我们在计算基于流的姿态相似性时会考虑多帧,表示为$S_{Multi-flow}$,也就是说,$\hat{J}_k$可能是由之前多帧共同推算出来的。通过这种方式,我们解决了人物实例在某些帧可能会消失的问题。
3.3.Flow-based Pose Tracking Algorithm
姿态追踪算法的整体框架见下:

其中的符号解释:

如Fig2(c)所示,图中既有检测器检测到的bounding box,也有通过光流推算出来的bounding box,所以这里会应用一下NMS。
$Q$是一个双端队列,长度固定为$L_Q$,表示为:
\[Q = [\mathcal{P}_{k-1},\mathcal{P}_{k-2}, ... , \mathcal{P}_{k-L_Q}] \tag{2}\]其中,$\mathcal{P}_{k-i}$是$I^{k-i}$帧中被追踪的实例集合,$L_Q$表示在匹配时会考虑之前的多少帧。
4.Experiments
4.1.Pose Estimation on COCO
我们的模型在COCO train2017数据集(包括57K张图像,共150K个人物实例)上进行了训练,没有使用额外数据,在val2017上进行了消融实验,在test-dev2017上汇报了最终结果。
👉Training
将GT bounding box的长宽比固定为$4:3$。将bounding box裁剪出来并resize到$256:192$。数据扩展使用了缩放($\pm 30\%$)、旋转($\pm 40^{\circ}$)和翻转。
我们所用的ResNet backbone在ImageNet分类任务上进行了预训练。在姿态估计的训练中,基础学习率为$1e-3$。并在第90个epoch时降为$1e-4$,在第120个epoch时降为$1e-5$。一共训练了140个epoch。mini-batch size=128。使用Adam优化器。用了4块GPU。
测试了ResNet-50,ResNet-101,ResNet-152。除非特殊说明,默认使用ResNet-50。
👉Testing
采用两阶段自上而下的范式。检测器默认使用Faster-RCNN。在预测关键点位置时,使用原始图像和翻转图像heatmap的平均。且从最高响应位置向第二高响应位置位移了四分之一作为最终的预测位置。
👉Ablation Study

👉Comparison with Other Methods on COCO val2017

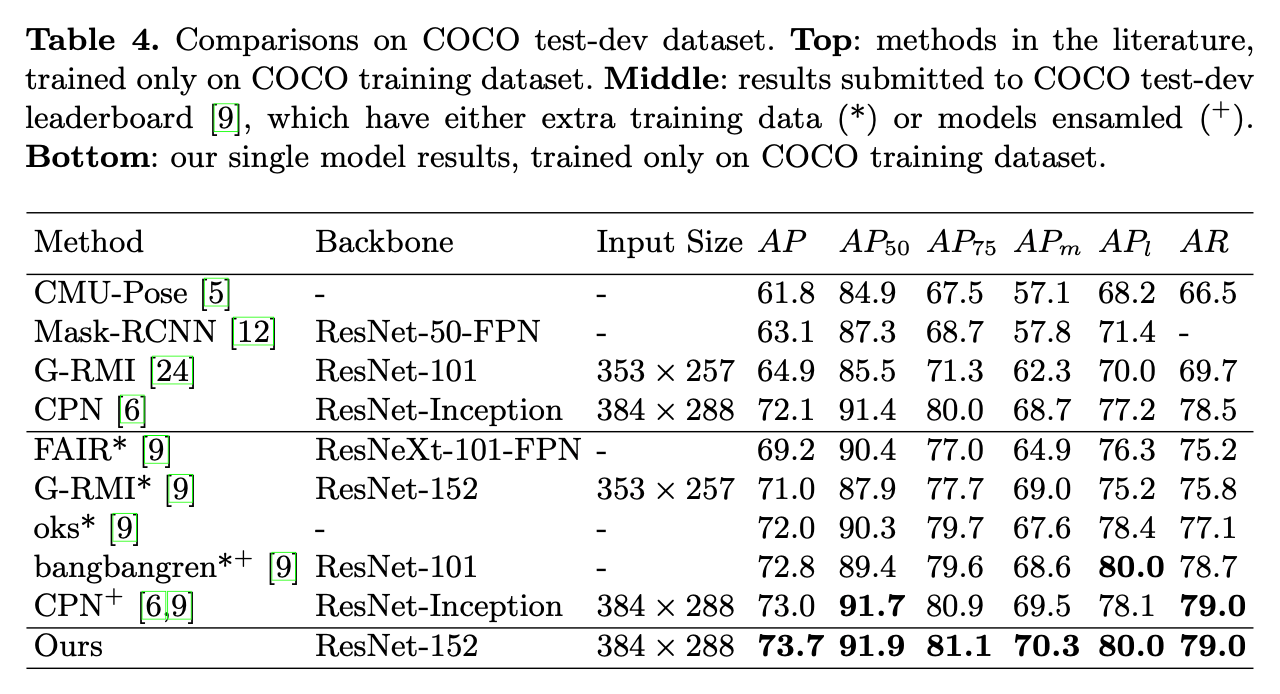
👉Comparisons on COCO test-dev dataset
4.2.Pose Estimation and Tracking on PoseTrack
PoseTrack数据集可用于视频中的多人姿态估计和追踪。该数据集共包含514个视频,共计66,374帧。其中,训练集包含300个视频,验证集包含50个视频,测试集包含208个视频。对于训练视频,中间的30帧是有标注的。对于验证和测试视频,除了中间的30帧有标注,其余每隔4帧也是有标注的,为了方便评估追踪算法的性能。每个人物实例的标注内容包括15个身体关键点、一个唯一的id和一个头部bounding box。
该数据集有3个任务。第一个任务是单帧的姿态估计,使用mAP作为评价指标。第二个任务也是姿态估计,但是允许使用多帧信息。第三个任务是使用多目标追踪指标评估追踪性能。鉴于我们使用了多帧信息,我们只汇报了在任务二和任务三上的结果。值得注意的是,我们的姿态估计baseline在任务一上取得了最好的成绩。
多目标追踪指标:Bernardin, K., Stiefelhagen, R.: Evaluating multiple object tracking performance: the clear mot metrics. Journal on Image and Video Processing 2008, 1 (2008)。
👉Training
我们基于第4.1部分已经在COCO上预训练好的模型进行了fine-tune。由于只有关键点被标注了,我们将刚好包括所有关键点的box扩大15%(一边各7.5%)作为GT box。使用和第4.1部分一样的数据扩展。训练所用的基础学习率为$1e-4$。在第10个epoch时降为$1e-5$,在第15个epoch时降为$1e-6$。一共训练了20个epoch。其他超参数和第4.1部分一样。
👉Testing
我们基于流的追踪baseline和人物检测器的性能密切相关,因为通过光流推算的box可能会影响检测器检测到的box。为了实验,我们使用了2种检测器,一种是速度更快但精度较低的R-FCN,另一种是速度较慢但精度更高的FPN-DCN。这两个检测器都使用ResNet-101作为backbone。我们也没有在PoseTrack数据集上做fine-tune。
首先,我们抛弃了置信度较低(<0.5)的检测框。此外,低置信度的关节点(<0.4)也被抛弃。
光流估计算法我们使用FlowNet2S。在测试集上的结果见Fig3。

我们主要的消融实验使用的模型是ResNet-50,输入大小为$256 \times 192$。我们最好的结果所用的模型为ResNet-152,输入大小为$384 \times 288$。
👉Effect of Joint Propagation

表5中的”With Joint Propagation”表示是否使用之前帧通过光流推算得到的bounding box。MOTA是一个评价追踪效果的指标。
👉Effect of Flow-based Pose Similarity
见表5。
👉Comparison with State-of-the-Art
我们汇报了我们的方法在PoseTrack数据集任务2和任务3上的结果。我们使用了表5中$b_6$和$c_6$的方法。
在任务2上的结果见表6。在任务3上的结果见表7。



5.Conclusions
不再赘述。
