本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
本文训练了一个CNN,可以同时对图像中的目标进行分类、定位和检测,并提高在所有任务上的分类、定位和检测精度。在ImageNet ILSVRC 2012和2013数据集上进行了实验,并在ILSVRC 2013的定位和检测任务上达到了SOTA的结果。
2.Vision Tasks

本文中,我们主要探索了3种CV任务,这3个任务难度逐渐上升,每个任务都是下一个任务的子任务:
- 第一个任务是classification,通常一张图像只分配一个类别标签。
- 第二个任务是localization,对一些已知的特定类别的目标进行定位,预测其bbox。比如通过第一个任务我们知道图像的类别标签是狼,那么localization的任务就是定位出这些狼的位置(目标可能不止一个),见Fig1上。
- 第三个任务是detection,我们需要预测出这张图中所有的目标及其类别,见Fig1下。
3.Classification
我们的分类模型和AlexNet相似。我们改进了网络设计和推理步骤。
3.1.Model Design and Training
我们在ImageNet 2012训练集(共120万张图像,1000个类别)上进行了训练。每张图像都被下采样到短边为256个像素,然后随机提取5个大小为$221 \times 221$的crop(及其水平翻转),作为输入图像。mini-batch的大小为128。网络权重按照$(\mu, \sigma)=(0, 1\times 10^{-2})$的分布进行随机初始化。momentum=0.6,L2 weight decay=$1 \times 10^{-5}$。初始学习率为$5 \times 10^{-2}$,然后在第30、50、60、70、80个epoch时衰减50%。在分类器的全连接层(即第6和第7层)上应用dropout(rate=0.5)。
模型框架见表1和表3。表1的模型速度更快,表3的模型精度更高。

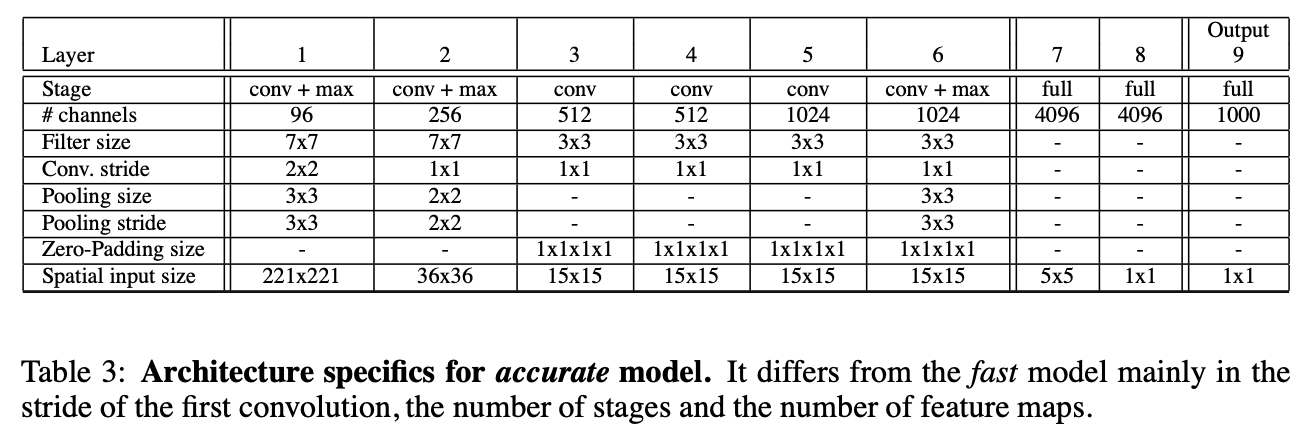
使用ReLU激活函数和max pooling,没有使用LRN,使用non-overlapping pooling。
前两个卷积层的结果可视化见Fig2。

3.2.Feature Extractor
这里的特征提取器指的就是上面表1和表3中的模型,作者将其称为“OverFeat”。AlexNet、OverFeat(fast版本和accurate版本)的模型大小比较见表4,精度比较见表2。

3.3.Multi-Scale Classification
AlexNet在推理阶段,将一张测试图像扩展为了10张。但是这种方法的缺点是忽视了图像中的很多区域,并且有很多重复计算。此外,还只考虑了一种尺度。
因此,我们提出了如Fig3所示的解决办法:

我们结合表5解释下Fig3:

- (a)我们从第5层还没pooling的feature map开始操作,之前的网络结构都保持一样。表5中列出了6种输入尺度,我们以第2种尺度(即$281 \times 317$)为例,在第5层卷积后,但pooling之前,我们可以得到大小为$20 \times 23$的feature map。Fig3只列出了一个维度的示意图。
- (b)我们使用$3 \times 3$大小的核进行max pooling(non-overlapping)。通过设置不同的开始位置(即offset),我们可以得到多个不同的pooling结果。比如在Fig3(b)中,沿着其中一个维度,我们可以得到3个结果,如果考虑两个维度的话,一共可以得到$(3 \times 3)$个pooling结果。每个pooling后的feature map大小为$(6 \times 7)$。这也就是表5中“Layer 5 post-pool”列的意思。
- (c)我们将上一步获得的feature map(大小为$6 \times 7$,通道数为256)分别送进全连接层。
- (d)因为全连接层输入大小固定为$5 \times 5$,所以进来的feature map在通过$5 \times 5$的滑动窗口后,得到的大小是$(2 \times 3)$,通道数也变成类别数$C$,这样的feature map一共有$(3 \times 3)$个。
- (e)我们将上一步的结果组合在一起,得到的维度就是$6 \times 9 \times C$。
对图像翻转后重复上述过程。最终的分类结果通过平均所有的$C$维向量获得。
3.4.Results
和AlexNet的精度比较见下表。scale的标号对应表5。

在ILSVRC 2013上的结果见Fig4。“Post competition”使用了更大的模型。

3.5.ConvNets and Sliding Window Efficiency
滑动窗口方法见Fig5,可以提升计算效率:

之前的方法中,对每个crop都需要完整的运行一遍网络,见Fig5上,对于多个crop,这当中有很多计算是重复的,效率很低。而采用如Fig5下的方式,最终输出的每个向量都对应一个crop的结果,只需运行一次网络的计算。
4.Localization
基于已经训练好的分类网络,将分类器替换为一个回归器用于预测bbox。
在分类模型中,将第1-5层(即卷积层)称为特征提取器,将第6层到输出层(即全连接层)的部分称为分类器。
4.1.Generating Predictions
分类模型和定位模型的特征提取器部分是共用的。对于每个位置和尺度,通过分类器得到最可能类别的置信度,通过回归器预测该类别的bbox。
4.2.Regressor Training
回归器包含2个全连接层和1个输出层。两个全连接层的神经元数分别为4096和1024。输出层有4个神经元,用于指定bbox。整体结构见Fig8。

Fig8还是以表5中的第2个尺度为例,整体流程和第3.3部分类似,特征提取器得到的feature map大小为$6 \times 7$,在上面运行$5 \times 5$的滑动窗口(见Fig8(a))。最后输出层每个单元对应一个4维向量,表示bbox。
回归器在训练时,在分类任务中已经训练好的特征提取器会被冻结,使用L2 loss。回归器是基于类别的,也就是说针对每个类别,都会训练一个专用的回归器,所以1000个类别就会有1000个回归器。网络训练使用的尺度集合和第3部分一样。此外,训练回归器所用的数据,其目标的GT bbox需要占到输入FOV的50%以上。我们同样也考虑多尺度方式的训练。
4.3.Combining Predictions

如Fig7所示,在单一尺度下,对于一个目标,就会预测得到多个bbox,如果考虑多个尺度,bbox会更多,因此我们就需要对这些bbox进行合并。详细步骤如下:
- 对于每个尺度$s \in 1…6$,我们都选出置信度最高的$k$个类别放入$C_s$中。比如$C_1$中就保存着第一个尺度下,置信度最高的$k$个类别。
- 对于$C_s$中的每个类别,执行对应类别的回归器,得到多个bbox的预测结果,存入$B_s$中。
- 把所有尺度的$B_s$(即$B_1,B_2,…,B_6$)都放入$B$内。
- 在$B$内执行NMS。

Fig6中,第一行是多尺度和滑动窗口的效果,第二行是使用了offset pooling后的效果,第三行是回归器的检测结果,第四行是最终合并后的bbox。
4.4.Experiments

Fig9中,SCR指的是不区分类别,使用一个回归器预测所有类别的bbox,PCR指的是每个类别都训练一个回归器用于预测各自的bbox(也就是前文所用的方法)。从Fig9可以看出,PCR的效果不如SCR,此外,还能看出多尺度带来的性能提升。

5.Detection
检测任务基本和定位任务一样,也是通过滑动窗口的机制。在训练检测模型时,负样本(即背景)是人工选取的,作者认为这样虽然工作量大,但效果更好。

“Post competition”的优化主要是更长的训练时间以及上下文信息(每个尺度都会额外使用更低分辨率尺度作为输入)的使用。
6.Discussion
我们提出了一种多尺度的、基于滑动窗口机制的方法,可用于分类、定位和检测。在ILSVRC 2013数据集上,我们的方法在分类任务中排名第4,在定位任务中排名第1,在检测任务中排名第1。
7.原文链接
👽OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
