本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
本文中,我们在几乎不改变计算复杂度的情况下,通过尝试不同的训练策略和模型架构refine来提升模型精度。我们所用的很多都是一些小技巧,比如修改卷积层的步长或者调整学习率策略等。我们将所有的小技巧应用于ResNet-50上,在ImageNet上的实验结果见表1。

此外,我们的这些方法可以很好的泛化到其他网络框架或任务领域中。模型及源码地址:GluonCV。
2.Training Procedures
常规的神经网络训练方法如下:

2.1.Baseline Training Procedure
我们使用“Training and investigating Residual Nets”中的ResNet实现方式作为baseline。训练和验证的预处理pipeline是不同的。在训练过程中,我们按以下步骤执行:
- 随机选择一张图像,将像素值转为$[0,255]$范围内的32位浮点数。
- 随机裁剪一块矩形区域,这个区域的长宽比为$[3/4]$或$[4/3]$,且区域面积和整幅图像的比值在$[8\%,100\%]$之间。然后将裁剪区域resize到$224 \times 224$。
- 有50%的几率进行水平翻转。
- 对hue、饱和度和亮度进行缩放,缩放系数在$[0.6,1.4]$之间均匀采样。
- 添加PCA噪声,其系数从正态分布$\mathcal{N}(0,0.1)$中采样。
- 对RGB通道进行归一化,归一化的方式为RGB对应的三个通道分别减去123.68、116.779、103.939,再分别除以58.393、57.12、57.375。
在验证阶段,在保持长宽比不变的情况下,将短边resize到256个像素。然后,在中心区域裁剪出$224 \times 244$,并对RGB通道做归一化。在验证阶段,我们没有使用任何随机的数据扩展。
卷积层和全连接层的参数初始化都使用了Xavier算法。具体来说,参数在$[-a,a]$之间均匀采样,其中,$a=\sqrt{6 / (d_{in} + d_{out})}$。这里的$d_{in}$和$d_{out}$是输入、输出通道的大小。所有的偏置项都初始化为0。对于BN层,$\gamma$向量初始化为1,$\beta$向量初始化为0。
训练使用了NAG(Nesterov Accelerated Gradient)梯度下降法。每个模型都训练了120个epoch,使用了8块Nvidia V100 GPU,batch size=256。学习率初始化为0.1,在第30、60、90个epoch时除以10。
NAG原文:Y. E. Nesterov. A method for solving the convex programming problem with convergence rate o (1/kˆ 2). In Dokl.Akad. Nauk SSSR, volume 269, pages 543–547, 1983.
2.2.Experiment Results
我们评估了3个CNN:ResNet-50、Inception-V3和MobileNet。对于Inception-V3,我们将输入图像resize到$299 \times 299$。我们使用ISLVRC2012数据集,其训练集包含1.3M张图像和1000个类别。验证精度见表2。

表2中,Baseline是我们实现的结果,Reference是原论文给出的结果。
3.Efficient Training
硬件,尤其是GPU,近年来发展迅速。因此,许多与性能相关的权衡发生了变化。例如,现在在训练中,使用较低的数值精度和较大的batch size更有效率。在本部分,我们回顾了在不牺牲模型精度的情况下实现低精度和large batch训练的各种技术。有些技术甚至可以提高准确性和训练速度。
3.1.Large-batch training
mini-batch SGD将多个样本放在一个mini-batch中,以提高并行性并降低成本。如果使用large batch size,可能会拖慢训练进程。此外,在同样的epoch数量下,large batch size还会导致验证精度的下降。
接下来,我们将介绍4种方法来缓解这个问题。
👉Linear scaling learning rate.
在mini-batch SGD中,梯度下降是一个随机过程,因为每个batch中的样本都是随机选择的。增加batch size不会改变随机梯度的期望,但会降低其方差。换言之,large batch size减少了梯度中的噪声,因此我们可以提高学习率。论文”P. Goyal, P. Doll´ar, R. B. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch SGD: training imagenet in 1 hour. CoRR, abs/1706.02677, 2017.”指出,随着batch size的增加,学习率也应该线性增加,这对训练ResNet-50是有效的。ResNet原文使用0.1作为初始学习率,其batch size为256,如果我们想用更大的batch size $b$,那么我们可以将初始学习率设置为$0.1 \times b / 256$。
👉Learning rate warmup.
在训练开始时,所有参数都是随机值,因此远离最终解。此时使用过大的学习率可能会导致数值不稳定。warmup的策略是,一开始使用较小的学习率,然后待训练过程稳定后,再切换回初始学习率。论文”P. Goyal, P. Doll´ar, R. B. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch SGD: training imagenet in 1 hour. CoRR, abs/1706.02677, 2017.”提出了一种gradual warmup的策略,该策略将学习率从0线性增加到初始学习率。换言之,假定我们用前$m$个batch(比如刚好是5个epoch)来进行warmup,初始学习率是$\eta$,对于第$i$个batch($1 \leqslant i \leqslant m$),我们将学习率设置为$i\eta / m$。
👉Zero $\gamma$.
ResNet网络包含多个残差块,每个块包含多个卷积层。给定输入$x$,块最后一层的输出为$\text{block}(x)$,则残差块的输出可表示为$x+\text{block}(x)$。块最后一层是BN层。BN层首先会标准化它的输入,记为$\hat{x}$,然后执行$\gamma \hat{x} + \beta$。其中,$\gamma$和$\beta$都是可学习的参数,分别被初始化为1和0。如果我们将$\gamma$初始化为0,会使得网络在初始阶段更容易被训练。
👉No bias decay.
weight decay通常应用于所有可学习的参数上,包括权重项和偏置项。这里我们仅将weight decay应用于卷积层和全连接层的权重上以避免过拟合,偏置项不使用weight decay。
需要注意的是,LARS提供了layer-wise的自适应学习率,声称对超大的batch size(超过16K)也是有效的。在本文中,考虑到在单个机器上进行训练,我们将batch size限制在2K以内。
LARS:B. Ginsburg, I. Gitman, and Y. You. Large batch training of convolutional networks with layer-wise adaptive rate scaling. 2018.
3.2.Low-precision training
神经网络的训练通常使用32位浮点的精度(FP32)。也就是说,所有的数字都以FP32的格式存储。对于Nvidia V100 GPU来说,FP32支持14 TFLOPS,而FP16支持100 TFLOPS。如表3所示,在V100上,将FP32改为FP16后,训练速度加快了2-3倍。
FLOP(Floating-Point Operation,浮点运算):计算机用来处理小数的运算。
FLOPS(Floating-Point Operations Per Second,每秒浮点运算次数):衡量计算机处理器的计算能力,单位是每秒能完成的浮点运算次数。FLOPS是计算能力的基本单位,常用的单位还有GFLOPS(GigaFLOPS,$10^9$次每秒)、TFLOPS(TeraFLOPS,$10^{12}$次每秒)、PFLOPS(PetaFLOPS,$10^{15}$次每秒)。

3.3.Experiment Results
消融实验见表4。

4.Model Tweaks
Model Tweaks指的是对网络框架进行微小的调整,比如改变特定卷积层的步长。这样的微调几乎不会改变计算复杂度,但可能会对模型精度产生不可忽视的影响。在本部分,我们以ResNet为例来研究模型微调的效果。
4.1.ResNet Architecture
原始的ResNet框架见下:

可以和ResNet原文中的表1结合起来看。每个stage的开始都是一个下采样块,然后接多个残差块。下采样块有A、B两条路径。路径A包含3个卷积,核大小分别为$1 \times 1$、$3 \times 3$和$1 \times 1$。第1个卷积的步长为2,用于将输入的长和宽减半,最后一个卷积输出的通道数是前面的4倍,即bottleneck结构。路径B的卷积步长为2,输出通道数和路径A一样,这样方便和路径A的输出加在一起。残差块和下采样块的结构基本一样,只不过步长都是1。
我们可以通过调整每个stage残差块的数量来获得不同的ResNet模型,比如ResNet-50和ResNet-152。
4.2.ResNet Tweaks
接下来,我们回顾了两种比较流行的ResNet调整方案,我们分别将它们称为ResNet-B和ResNet-C。之后,我们提出了一种新的调整方案,称为ResNet-D。

👉ResNet-B.
这种调整最早出自Torch的实现:S. Gross and M. Wilber. Training and investigating residual nets. http://torch.ch/blog/2016/02/04/resnets.html.。它修改了ResNet的下采样块。因为原来步长为2的$1\times 1$卷积使得路径A忽略了四分之三的输入feature map。所以,如Fig2(a)所示,ResNet-B将步长为2放在了$3\times 3$卷积中,这样就没有信息被忽略了。
👉ResNet-C.
这种调整最早是Inception-V2提出来的(见Inception-V2原文中的表1)。这个调整主要是针对ResNet中的conv1,将$7 \times 7$卷积拆分为多个连续的$3 \times 3$卷积,如Fig2(b)所示。
👉ResNet-D.
受到ResNet-B的启发,我们意识到路径B中的$1\times 1$下采样也会忽略$3/4$的输入feature map,我们对其进行修改使得没有信息再被忽略。具体做法是,在卷积之前,添加一个步长为2的$2\times 2$平均池化,并把卷积的步长改为1,如Fig2(c)所示。这个改动在实际应用中效果很好,且对计算成本影响很小。
在PaddlePaddle文档中,ResNet-C被记为ResNet-vc,ResNet-D被记为ResNet-vd。
4.3.Experiment Results
结果见表5,模型batch size=1024,使用FP16。

5.Training Refinements
本部分介绍4种训练refine方法来提升模型精度。
5.1.Cosine Learning Rate Decay
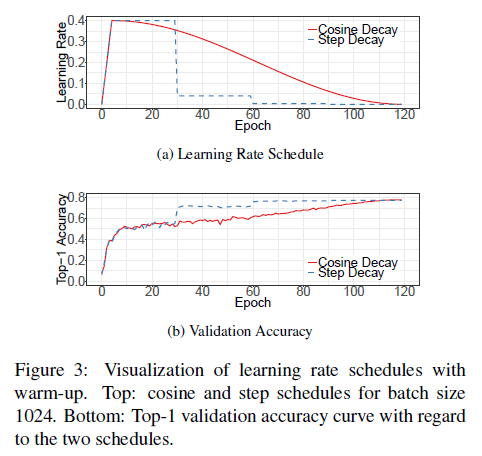
学习率的调整对训练至关重要。在经过第3.1部分提到的warmup之后,初始学习率会开始稳步降低。
论文”I. Loshchilov and F. Hutter. SGDR: stochastic gradient descent with restarts. CoRR, abs/1608.03983, 2016.”提出了余弦退火策略(cosine annealing strategy)。一个简单的版本是遵循余弦函数,将初始学习率降为0。假定总的batch数量为$T$(不考虑warmup),在第$t$个batch,学习率$\eta _t$为:
\[\eta _t = \frac{1}{2}\left( 1 + \cos \left( \frac{t \pi}{T} \right) \right) \eta \tag{1}\]其中,$\eta$是初始学习率。我们也将这种方法称为余弦衰减(“cosine” decay)。
5.2.Label Smoothing
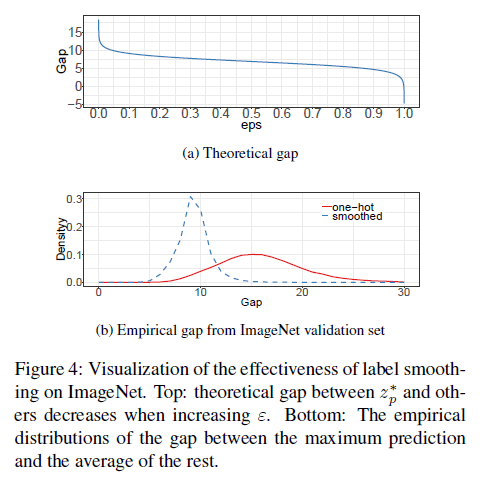
见“Model Regularization via Label Smoothing”,此处不再赘述。
5.3.Knowledge Distillation
在知识蒸馏中,我们使用教师模型来帮助训练现在的模型(即学生模型)。我们使用ResNet-152作为教师模型,ResNet-50作为学生模型。
知识蒸馏:G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
5.4.Mixup Training
见mixup,此处不再赘述。
5.5.Experiment Results


6.Transfer Learning
6.1.Object Detection

6.2.Semantic Segmentation

7.Conclusion
对全文的总结,不再详述。
8.原文链接
👽Bag of Tricks for Image Classification with Convolutional Neural Networks
