本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
我们的目的是在提升单阶段目标检测器定位精度的同时保留其高效性。我们发现单阶段检测器分类分数和定位精度之间的低相关性严重损害了模型的定位精度。导致低相关性的原因是分类和定位的子网络是使用独立的目标函数进行训练的,互相并不了解。在模型收敛之后,分类子网络在不知道定位精度的情况下预测每个anchor的分类分数。这就会导致分类分数和定位精度之间的错误匹配,比如高分类分数但低IoU,或者低分类分数但高IoU,如Fig1所示。在推理阶段,这样的检测会从两方面损害模型的AP。首先,根据传统的NMS算法,所有的检测框按它们的分类分数排序,分类分数最高的检测框会抑制其他与其重叠面积大于阈值的检测框。导致的结果就是,低分类分数但高IoU的检测框被高分类分数但低IoU的检测框所抑制。举个例子,如Fig1所示,准确的检测框A1、B1、C1就会被不准确的检测框A2、B2、C2所抑制。第二个方面,在计算AP时,所有的检测框也是按其分类分数排序的。基于这些排序的检测框计算precision和recall,如果高分类分数但低IoU的检测框排在低分类分数但高IoU的检测框之前,高IoU阈值下的precision将会降低,从而导致高IoU阈值下更低的AP。举个例子,如Fig1所示,按分类分数排序为C2、B2、A2,其AP低于排序A2、B2、C2。

为了解决这个问题,我们基于RetinaNet提出了IoU-aware的单阶段目标检测。
2.Related Work
不再赘述。
3.Method
3.1.IoU-aware single-stage object detector

如Fig2所示,backbone和FPN部分基本和RetinaNet一样。不同之处在于我们给regression head并行添加了一个IoU prediction head。为了保持模型的高效性,IoU prediction head只包含一个$3\times 3$的卷积层,然后是一个sigmoid激活层,以保证预测的IoU在$[0,1]$范围内。这里还有很多其他设计IoU prediction head的方法,比如单独建立一个IoU prediction分支,和classification分支以及regression分支平行,但这会损害模型的高效性。我们的设计给整个模型带来的计算负担可以忽略不计,并且仍然可以大大提高模型的性能。
3.2.Training
和RetinaNet一样,classification loss使用focal loss(见式(1)),regression loss使用smooth L1 loss(见式(2))。
\[L_{cls}=\frac{1}{N_{Pos}}\left( \sum_{i \in Pos}^N \text{FL}(p_i,\hat{p}_i) + \sum_{i \in Neg}^M \text{FL}(p_i,\hat{p}_i) \right) \tag{1}\] \[L_{loc}=\frac{1}{N_{Pos}} \sum_{i \in Pos}^N \sum_{m\in cx,cy,w,h} \text{smooth}_{L1} (l_i^m - \hat{g}_i^m) \tag{2}\]个人注解:smooth L1 loss也称Huber loss,是一种介于L1 loss和L2 loss之间的损失函数,兼具两者的优点。公式如下:
\[\text{Smooth L1 Loss}(x) = \begin{cases} 0.5x^2, & \text{if } |x| < 1, \\ |x| - 0.5, & \text{otherwise}. \end{cases}\]其中,$x$为预测值和真实值之间的误差。
IoU prediction loss使用BCE(binary cross-entropy) loss,并且只针对阳性样本计算loss,公式见式(3)。
\[L_{IoU} = \frac{1}{N_{Pos}} \sum_{i \in Pos}^N \text{BCE} (IoU_i,\hat{IoU}_i) \tag{3}\]$IoU_i$表示预测的IoU,$\hat{IoU}_i$表示预测的阳性样本的检测框$b_i$和其对应的GT box $\hat{b}_i$之间的IoU,见式(4)。
\[\hat{IoU}_i = \text{overlap} (b_i,\hat{b}_i) \tag{4}\]$L_{IoU}$梯度的计算见式(5)和Fig3。
\[\frac{\partial \text{BCE}(IoU_i,\hat{IoU}_i)}{\partial \hat{IoU}_i} = \log \frac{1-IoU_i}{IoU_i} \tag{5}\]
在训练阶段,IoU prediction head和classification head以及regression head进行联合训练。
\[L_{total} = L_{cls} + L_{loc} + L_{IoU} \tag{6}\]3.3.Inference
在推理阶段,分类分数$p_i$和预测的IoU(即$IoU_i$)相乘,得到每个检测框最终的检测置信度$S_{det}$,见式(7)。
\[S_{det} = p_i^{\alpha}IoU_i^{(1-\alpha)} \tag{7}\]其中,$\alpha$的范围为$[0,1]$,用于控制分类分数和预测IoU对最终检测置信度的贡献程度。该检测置信度可以同时注意到分类分数和定位精度,与只使用分类分数相比,检测置信度和定位精度的相关性更大。在后面的NMS以及AP计算中,也使用检测置信度对检测框进行排序。这样的话,高分类分数但低IoU的检测框的排名就会下降,而低分类分数但高IoU的检测框的排名就会上升,从而提高了模型的定位精度。
4.Experiments
4.1.Experimental Settings
👉Dataset and Evaluation Metrics.
多数实验在MS COCO数据集上进行。训练集train-2017包括118k张图像,验证集val-2017包括5k张图像,测试集test-dev包括20k张图像。数据集共有500k个标注的目标实例,共80个类别。为了验证我们方法的泛化性,在PASCAL VOC上进行了消融实验。在VOC2007中,训练集VOC2007 trainval包含5011张图像,测试集VOC2007 test包含4952张图像。在VOC2012中,训练集VOC2012 trainval包含17125张图像,测试集VOC2012 test包含5138张图像。评估指标使用COCO风格的AP。
👉Implementation Details.
所有目标检测模型的实现都是基于PyTorch和MMDetection。只使用了2块GPU,训练期间的学习率调整遵循论文“P. Goyal, P. Dollar, R. Girshick, P. Noordhuis, L.Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, K. He, Accurate, large minibatch sgd: Training imagenet in 1 hour, arXiv preprint arXiv:1706.02677 (2017).”中的线性缩放规则。对于主要的结果,所有模型都在COCO test-dev上进行评估。MMDetection提供的收敛模型作为baseline。在MMDetection的默认设置中,IoU-aware的单阶段目标检测器一共训练了12个epoch,图像尺寸范围为$[800,1333]$。一些论文使用了1.5倍的训练时间和scale jitter来获得主要结果。但我们的实验并没有这样做。在消融实验中,IoU-aware的单阶段目标检测器使用ResNet50作为backbone,在COCO train-2017上进行训练,在COCO val-2017上进行评估,所用图像尺寸范围为$[600,1000]$。对于在PASCAL VOC上进行的实验,不同backbone的模型在VOC2007 trainval和VOC2012 trainval上进行训练,在VOC2007 test上进行评估,图像尺寸范围为$[600,1000]$。除非特殊声明,均使用MMDdetection的默认设置。
4.2.Main Results

4.3.Ablation Studies
👉IoU Prediction Loss.

表2的结果没有使用式(7)中的$\alpha$。
👉Detection Confidence Computation.

表3是关于式(7)中$\alpha$取值的实验。“none”表示不用$\alpha$。
👉The Effectiveness of Computing the Gradient of $L_{IoU}$ with Respective to $\hat{IoU}_i$ During Training.
上述实验,在训练阶段的反向传播时都没有计算$L_{IoU}$关于$\hat{IoU}_i$的梯度。从表4可以看出,反向传播时如果添加$L_{IoU}$关于$\hat{IoU}_i$的梯度计算(即式(5)),会提升AP。

👉Ablation Studies on PASCAL VOC.

4.4.Discussions
👉The Upper Bound of IoU-aware RetinaNet.
为了评估IoU-aware RetinaNet的上限,我们将每次预测的IoU替换为GT IoU,用于在推理阶段计算检测置信度。我们将GT IoU定义为预测检测框和离其最近的GT检测框(不考虑类别)的IoU,记为$IoU_{truth}$。实验结果见表6。
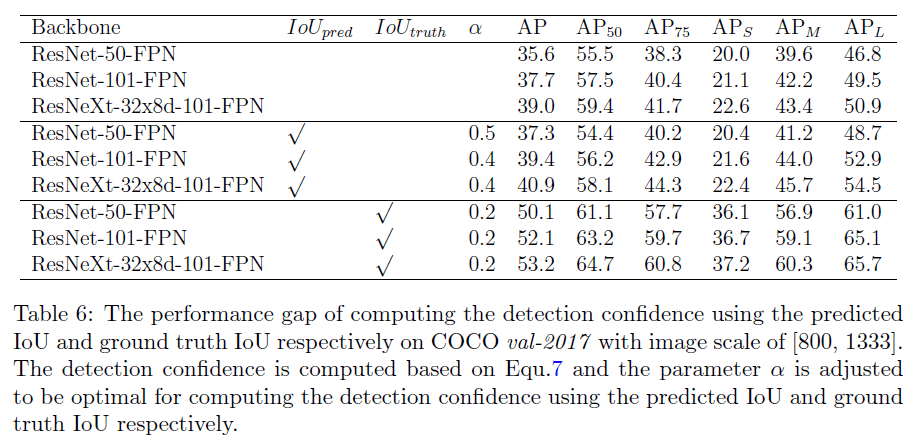
从表6可以看出,如果我们预测的IoU越来越准(即越来越接近$IoU_{truth}$),我们的AP还有很大的提升空间。
👉Why Can IoU-aware RetinaNet Improve Model’s Performance?
首先,我们定义了$IoU_{eval}$,其是预测检测框和最接近的且同类别的GT box的IoU。

在Fig4(a)中,我们基于baseline RetinaNet,随机采样了10K个检测框,纵轴的检测置信度其实就是分类分数,横轴是$IoU_{eval}$,我们可以看到,存在大量高定位精度但低检测置信度的检测框(个人注解:即有大量点分布在图的右下部分)。在Fig4(b)中,我们基于IoU-aware RetinaNet(使用预测的IoU),采样了10K个检测框,可以看到右下部分的点所有减少。在Fig4(c)中,我们基于IoU-aware RetinaNet(使用预测的$IoU_{truth}$),采样了10K个检测框,可以看到,检测置信度和定位精度有着强相关性。
👉The Error of Classification.
在Fig4(c)中,在$IoU_{eval}$位于$[0,0.3]$这个区间时,仍然有着很高的检测置信度,这意味着在推理阶段,$IoU_{truth}$的值很大但$IoU_{eval}$却很小。这可以视为是误分类检测,如Fig5所示。

5.Conclusions
不再赘述。
6.原文链接
👽IoU-aware Single-stage Object Detector for Accurate Localization
