本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
目标检测任务可以视为两个任务的结合:目标定位和目标识别。
目前,基于CNN的目标检测方法通常可以分为三步:1)获取region proposal;2)将proposal喂给CNN进行识别和分类;3)使用bbox回归对proposal进行调整以得到更准确的检测框。这种pipeline中,region proposal算法是主要的瓶颈。
因此,本文提出了一种高效的基于CNN的目标检测网络:UnitBox。UnitBox采用全卷积网络框架,直接在feature map上预测目标边界和pixel-wise的分类分数。特别是,UnitBox使用了一种新的IoU loss来进行bbox预测(见Fig1)。UnitBox不仅检测框预测的准,并且训练收敛也很快。

2.IOU LOSS LAYER
对于图像中的每个像素$(i,j)$,GT bbox可表示为:
\[\tilde{\mathbf{x}}_{i,j} = (\tilde{x}_{t_{i,j}},\tilde{x}_{b_{i,j}},\tilde{x}_{l_{i,j}},\tilde{x}_{r_{i,j}}) \tag{1}\]其中,$\tilde{x}_{t_{i,j}},\tilde{x}_{b_{i,j}},\tilde{x}_{l_{i,j}},\tilde{x}_{r_{i,j}}$分别表示像素点$(i,j)$到GT bbox上(top)、下(bottom)、左(left)、右(right)四个边界的距离。为了方便,后续表示省略脚注$i,j$。预测的bbox表示为$\mathbf{x}=(x_t,x_b,x_l,x_r)$,如Fig1所示。
2.1.L2 Loss Layer
$\ell_2$ loss经常被用来回归bbox,其定义为:
\[\mathcal{L}(\mathbf{x},\tilde{\mathbf{x}}) = \sum_{i \in \{t,b,l,r\}} (x_i - \tilde{x}_i)^2 \tag{2}\]其中,$\mathcal{L}$为localization error。
$\ell_2$ loss有两个主要的缺点。第一个缺点是bbox的坐标($x_t,x_b,x_l,x_r$)被视为四个独立的变量。这违背了bbox边界是高度相关的事实。这会导致很多失败的情况,比如预测框的一个或两个边界非常接近GT,但整个框却是不被接受的;此外,根据式(2)可以看出,大的bbox和小的bbox对于惩罚的敏感度是不一样的。这种不平衡导致CNN更多的关注较大的目标,而忽略较小的目标。
2.2.IoU Loss Layer: Forward
因此,我们提出了一种新的损失函数,即IoU loss,完美解决了上述问题。给定一个预测的bbox $\mathbf{x}$(在ReLU层之后,我们有$x_t,x_b,x_l,x_r \geqslant 0$),对应的GT为$\tilde{\mathbf{x}}$,IoU loss的计算如下:

与$\ell_2$ loss相比,IoU loss将bbox视为一个整体。此外,无论bbox的大小如何,IoU都在$[0,1]$范围内,这一优势使UnitBox可以用多尺度目标进行训练,并且仅在单尺度图像上进行测试。
2.3.IoU Loss Layer: Backward
本部分是IoU loss的反向传播计算。首先计算$\nabla_x X$:
\[\frac{\partial X}{\partial x_t(\text{or}\ \partial x_b)}=x_l+x_r \tag{3}\] \[\frac{\partial X}{\partial x_l (\text{or}\ \partial x_r)}=x_t + x_b \tag{4}\]然后计算$\nabla_x I$:
\[\frac{\partial I}{\partial x_t (\text{or } \partial x_b)} = \begin{cases} I_w, & \text{if } x_t < \tilde{x}_t (\text{or } x_b < \tilde{x}_b) \\ 0, & \text{otherwise}, \end{cases} \tag{5}\] \[\frac{\partial I}{\partial x_l (\text{or } \partial x_r)} = \begin{cases} I_h, & \text{if } x_l < \tilde{x}_l (\text{or } x_r < \tilde{x}_r) \\ 0, & \text{otherwise}. \end{cases} \tag{6}\]最后我们可以计算localization loss $\mathcal{L}$的梯度:
\[\begin{align} \frac{\partial \mathcal{L}}{\partial{x}} &= \frac{I(\nabla_x X-\nabla_x I)-U\nabla_x I}{U^2IoU} \\&= \frac{1}{U} \nabla_x X - \frac{U+I}{UI} \nabla_x I \end{align} \tag{7}\]3.UNITBOX NETWORK
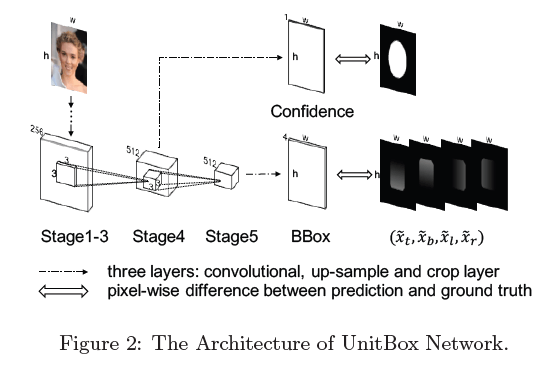
基于IoU loss层,我们提出了pixel-wise的目标检测网络,即UnitBox。如Fig2所示,UnitBox框架来源于VGG-16,我们去除了VGG-16后面的全连接层,改成两个全卷积层的分支,分别用于预测pixel-wise的bbox和分类分数。在训练阶段,UnitBox需要被喂入三个同样大小的输入:1)原始图像;2)置信度heatmap,是一个二值图像,1表示该像素点落在目标上(positive),0表示该像素点落在背景上(negative);3)bbox heatmap,对于每个落在目标上的像素点,都记上其GT box的坐标。
个人注解:第一个输入(原始图像)是模型的输入,后两个输入(置信度heatmap和bbox heatmap)是用来计算loss用的,并不是模型的输入。
对于预测置信度,我们在VGG stage-4后面加了3层,分别是:1)一个卷积层,步长为1,核大小为$512 \times 3 \times 3 \times 1$;2)一个上采样层,通过线性插值直接将feature map上采至原始图像大小;3)一个裁剪层,用于将feature map和输入图像对齐。最终,我们得到一个1通道且和输入图像大小一样的feature map,我们使用sigmoid交叉熵损失来计算这个分支的loss。对于另一个预测bbox的分支,在VGG stage-5后面加了类似的3层,卷积核大小为$512 \times 3 \times 3 \times 4$。此外,我们加了ReLU层来使得bbox的预测值都是非负的。这个分支使用IoU loss。最终的loss是这两个分支loss的加权平均。
个人注解:按照UnitBox的原始设计,只能预测一个类别。
以人脸检测为例,检测结果见Fig3。

4.EXPERIMENTS
以人脸检测为例,在FDDB benchmark上进行评估。使用了在ImageNet上预训练过的VGG-16,然后在公开的面部数据集WiderFace上进行fine tune。batch size=10。momentum=0.9,weight decay=0.0002。学习率为$10^{-8}$。fine tune阶段没有使用data augmentation。
4.1.Effectiveness of IoU Loss
为了和$\ell _2$ loss进行比较,我们将IoU loss层替换为$\ell _2$ loss层,并将学习率降为$10^{-13}$,其他设置不变。

对于Fig4(b),选择的都是最优模型,UnitBox训练了约16k次迭代,UnitBox-$\ell _2$训练了约29k次迭代。

在Fig5中,我们将测试图像resize到不同大小,从60到960个像素。检测框都是基于红点所在像素预测出来的。
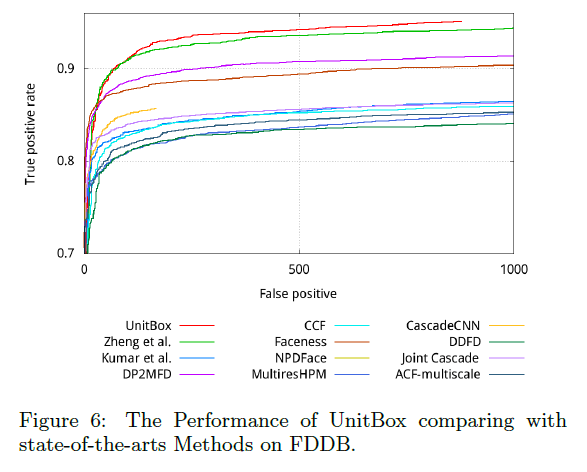
4.2.Performance of UnitBox
5.CONCLUSIONS
不再赘述。
