【CUDA编程】系列博客参考NVIDIA官方文档“CUDA C++ Programming Guide(v12.6)”。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.The Benefits of Using GPUs
相比CPU,在相似的价格和功耗范围内,GPU(Graphics Processing Unit)能提供更高的指令吞吐量(instruction throughput)和内存带宽(memory bandwidth)。
指令吞吐量:指的是处理器在单位时间内可以执行的指令数量。它通常用每秒执行的指令数(Instructions Per Second,IPS)来衡量。指令吞吐量越高,处理器执行任务的效率就越高。
内存带宽:指内存和处理器之间数据传输的速率,通常用每秒传输的字节数(如GB/s)来衡量。内存带宽越高,处理器就能够更快地从内存中读取数据或将数据写入内存。
GPU和CPU的性能差异源自它们的设计目标不同:
- CPU的设计目标是执行少量线程(比如几个或几十个线程),并确保这些线程以极高的速度运行。CPU非常适合运行依赖顺序处理和低延迟的任务,如操作系统管理、单线程应用程序等。
- GPU的设计目标是最大限度的并行处理成千上万个线程,尽管单个线程的执行速度可能较慢,但其能够实现极高的指令吞吐量。这种特性使得GPU在需要处理大量数据并行计算的任务中(如图形渲染、深度学习、科学计算)表现出色。
GPU和CPU在芯片资源分配的示例见Fig1:
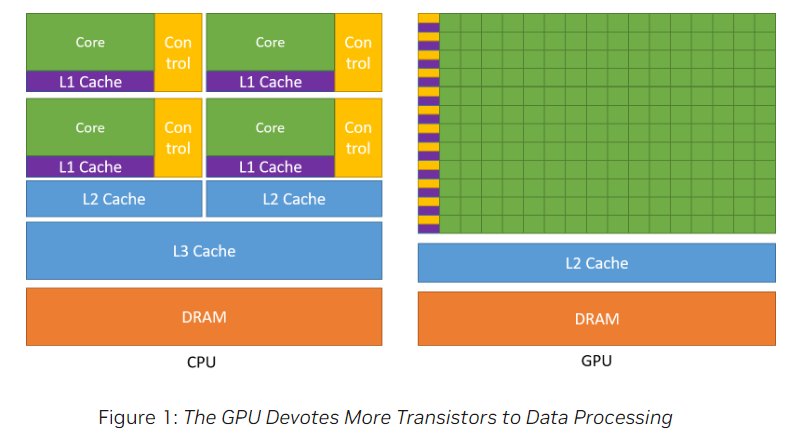
- 绿色网格代表核心(core),用于处理数据。但CPU和GPU的核心在构造上有所不同,CPU核心是高度复杂的处理单元,可用于执行复杂计算任务,而GPU核心相对简单得多,用于执行大量的简单计算任务。
- 黄色网格代表控制单元(Control Unit),用于管理和协调各种计算任务。CPU需要强大的控制逻辑来处理复杂的任务和多线程管理,因此控制单元占用了相当比例的芯片资源。而GPU主要侧重于并行处理,简化了控制逻辑以支持更多的数据处理核心。
-
紫色网格和蓝色网格是现代计算机处理器中的三级缓存结构:L1 Cache(一级缓存)、L2 Cache(二级缓存)、L3 Cache(三级缓存)。
位置 速度 大小 作用 L1 Cache L1缓存是离处理器核心最近的一层缓存,通常直接集成在每个核心内部。 L1缓存是所有缓存层次中速度最快的,因为它与处理器核心的距离最近,访问延迟极低。 L1缓存通常是最小的,容量在几十KB左右(通常是32KB到128KB)。 L1缓存分为两个部分:指令缓存(Instruction Cache,L1I)和数据缓存(Data Cache,L1D)。L1I缓存存储处理器即将执行的指令,而L1D缓存存储处理器在执行过程中需要的数据。L1缓存的主要作用是尽可能快速地提供处理器所需的指令和数据,减少访问内存的时间。 L2 Cache L2缓存通常也是集成在每个处理器核心内部,或者在多核处理器中,L2缓存可能在多个核心之间共享。 L2缓存比L1缓存稍慢,但仍然比主内存(DRAM)快很多。它的访问速度取决于具体的架构设计。 L2缓存比L1缓存大,容量通常在256KB到数MB之间。 L2缓存作为L1缓存的支援,存储更多的数据和指令。当处理器在L1缓存中找不到所需的数据或指令时,它会从L2缓存中查找。这减少了访问速度较慢的主内存的频率,提高了处理效率。 L3 Cache L3缓存通常在整个处理器芯片上共享,而不是像L1和L2缓存那样每个核心独立拥有。它被多个核心共享,以减少重复存储和提高数据传输效率。 L3缓存比L1和L2缓存慢,但比主内存快得多。它的访问时间更长,但容量也更大。 L3缓存是最大的一层缓存,容量通常在数MB到几十MB之间。 L3缓存主要用于进一步减少对主内存的访问。它作为L1和L2缓存的后备,存储更大范围的数据和指令。当L2缓存也无法命中时,处理器会尝试从L3缓存中获取数据。L3缓存还可以促进多核处理器中的数据共享,减少核心之间的数据传输延迟。 - 橙色网格代表动态随机存取存储器(Dynamic Random-Access Memory,DRAM)。它是CPU和GPU存储数据和指令的主要场所。相比于L1、L2、L3缓存,DRAM的容量大得多,但速度较慢。虽然它的访问速度不如缓存,但由于其容量较大,能够存储更多的数据和指令,供处理器随时调用。DRAM被用作系统的主要内存,用于存储当前运行的程序和数据。在CPU和GPU处理任务时,所需的数据和指令通常首先从DRAM中加载到缓存中,然后由处理器进行处理。
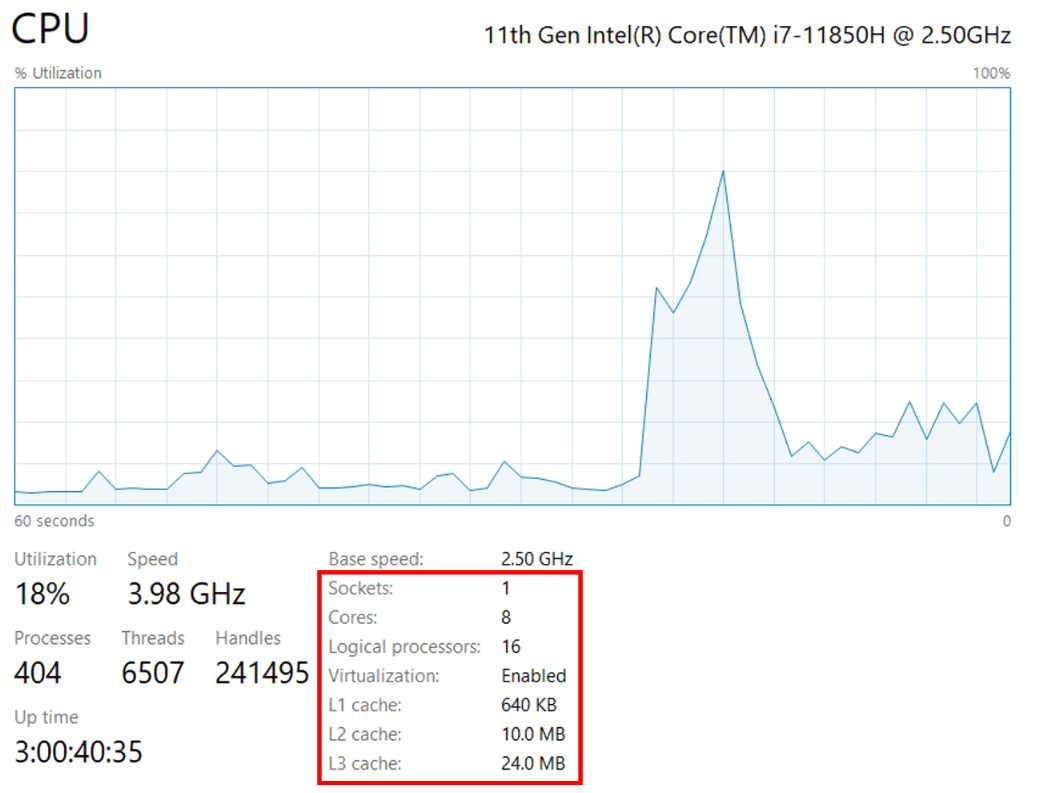
以我自己电脑的CPU为例(见下图):
- Sockets:表示处理器插槽的数量,一个Socket通常对应一个物理CPU。
- Cores:CPU的物理核心数量。通常情况下,一个核心只能处理一个线程,但如果使用了多线程技术,则允许一个核心同时处理多个线程。
- Logical processors:逻辑处理器,指的是系统中可用的虚拟处理器的数量。每个物理核心可能支持多线程技术(如Intel的超线程技术:Hyper-Threading),使得一个物理核心可以作为多个逻辑处理器来处理任务。在我的电脑上,每个核心被超线程技术划分为2个逻辑处理器,即每个核心可以处理2个线程。因此,我的电脑一共有$8 \times 2 = 16$个逻辑处理器。
- L1 Cache的大小为640KB。
- L2 Cache的大小为10.0MB。
- L3 Cache的大小为24.0MB。
如Fig1所示,GPU分配了更多的芯片资源来处理数据计算,这有利于其高度并行的计算模式。其次,由于GPU有大量的核心,它可以在等待内存读取的同时继续进行其他计算,从而有效地隐藏或减少因内存延迟带来的性能损失。
通常,一个应用程序包含并行执行的部分和顺序执行的部分,因此系统设计时会混合使用GPU和CPU,以最大化整体性能。
2.CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
2006年11月,NVIDIA推出了CUDA(Compute Unified Device Architecture),一个通用并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎,以比CPU更高效的方式解决许多复杂的计算问题。
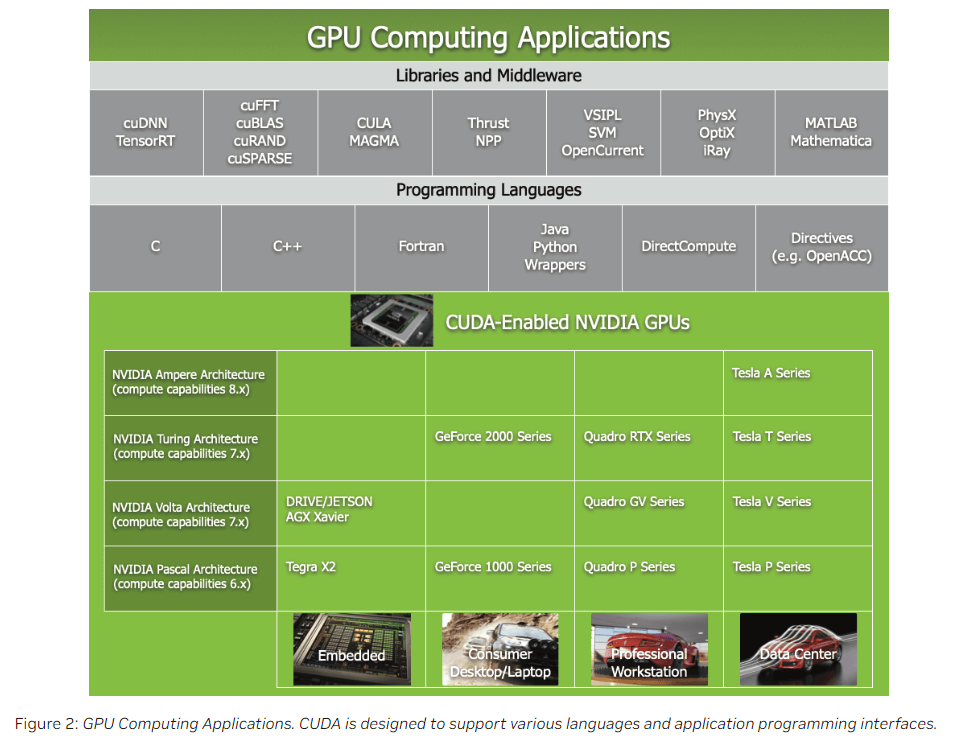
Fig2的内容分为3部分:
- Libraries and Middleware:NVIDIA或第三方提供了很多库,支持在GPU上执行高效的数据处理和计算。
- Programming Languages:CUDA支持的编程语言,主要是C和C++。
- CUDA-Enabled NVIDIA GPUs:支持CUDA的NVIDIA GPU。最后一行是这些GPU常见的应用设备。
NVIDIA的GPU架构也在不断的演变(架构名多是一些著名的科学家):
- Tesla:2006年发布。
- Fermi:2010年发布。
- Kepler:2012年发布。
- Maxwell:2014年发布。
- Pascal:2016年发布。
- Volta:2017年发布。
- Turing:2018年发布。
- Ampere:2020年发布。
- Hopper:2022年发布。
- BlackWell:2024年发布。
3.A Scalable Programming Model
CUDA程序的设计允许它们自动适应不同规模的硬件配置。一个CUDA程序可以在具有不同数量的多处理器的GPU上运行,而不需要程序员手动调整,系统会自动处理这些差异。
CUDA并行编程有3个核心抽象概念:
- 线程组的层次结构(a hierarchy of thread groups):线程被组织成组,形成层次结构,使得并行计算任务可以分配给这些组。
- 共享内存(shared memories):在组内,线程可以共享内存,从而更高效地协作解决问题。
- 屏障同步(barrier synchronization):线程在计算过程中可以进行同步,确保它们在某些计算点上协调一致。
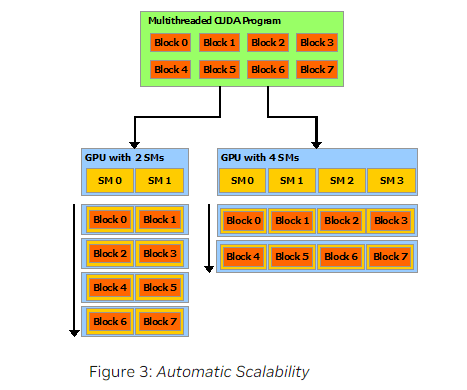
在Fig3中,“Multithreaded CUDA Program”指的是一个多线程的CUDA程序,该程序被分成多个线程块(Block0到Block7),在CUDA编程中,线程块和线程组是一个意思。每个线程块包含多个线程,用于执行特定的计算任务。“SM”全称是Streaming Multiprocessors,即流式多处理器。GPU被划分为多个GPC(Graphics Processing Cluster,图形处理簇),每个GPC又包含多个SM,每个SM又包含多个核心。SM是处理并行任务的主要单元,它可以同时处理多个线程块。
从Fig3中可以看出,CUDA程序具有自动扩展性(Automatic Scalability),其可以在具有2个SM或具有4个SM的GPU上自动调整。因此,我们在开发CUDA程序时,无需知道具体的硬件配置,这些细节由CUDA的运行时系统自动处理。
接下来解释下SM,以基于Turing架构的TU102 GPU芯片为例:
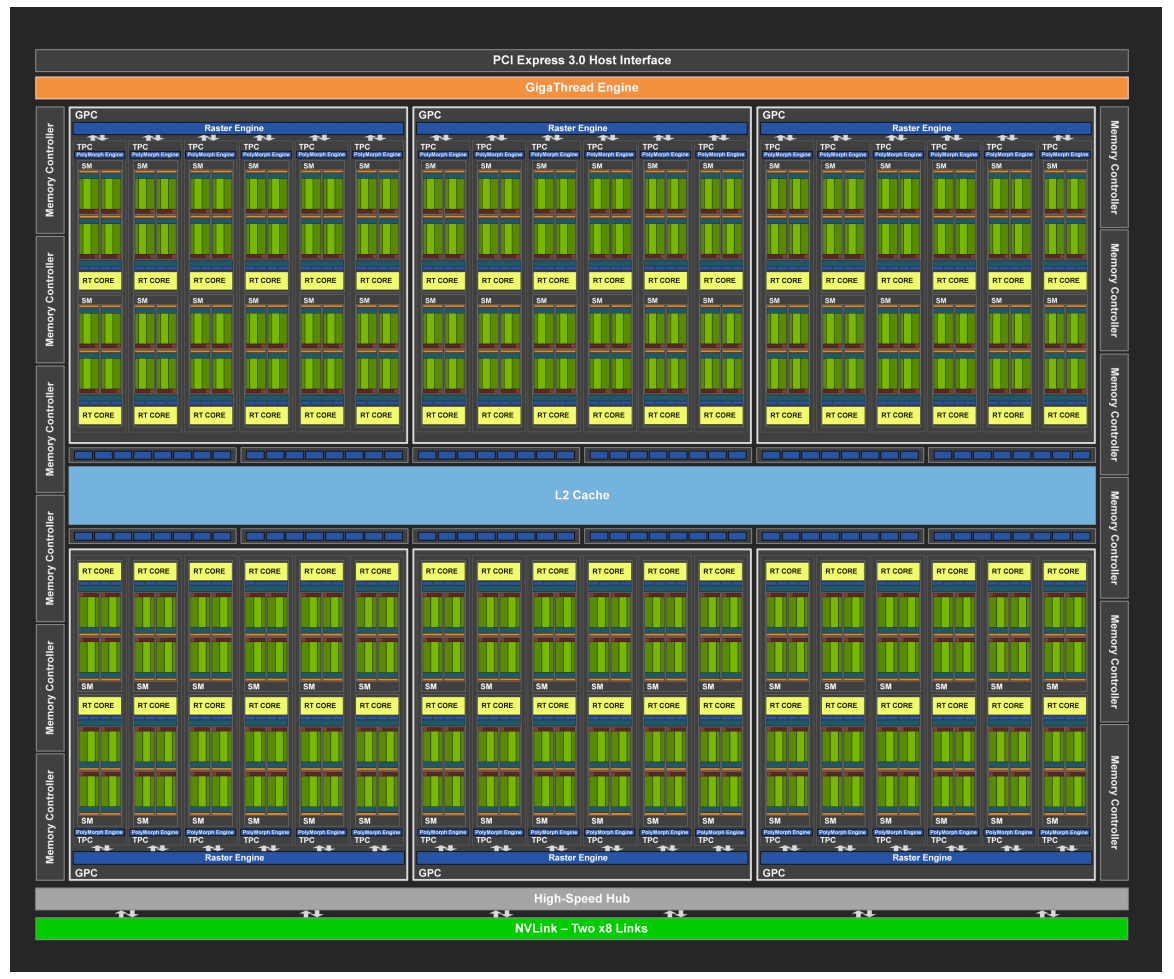
其被划分为6个GPC,每个GPC有12个SM,共$6 \times 12 = 72$个SM。
基于TU102芯片的显卡型号有RTX 2080 Ti、Quadro RTX 6000等。
SM的构造如下:

绿色网格部分(INT32、FP32、TENSOR CORES)就是核心。针对TU102 GPU芯片,每个SM包含64个CUDA核心(包含64个FP32计算单元和64个INT32计算单元)和8个Tensor核心。所以,对于TU102,CUDA核心的总数量为$64 \times 72 = 4608$;Tensor核心的总数量为$8 \times 72 = 576$个。
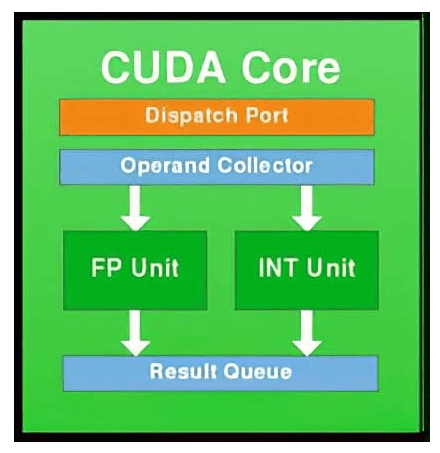
如下图所示,一个CUDA核心包含一个整数运算单元ALU(integer arithmetic logic unit)和一个浮点运算单元FPU(floating point unit):
Tensor核心:

- CUDA核心负责处理常规的浮点运算和整数运算。
- Tensor核心是一种专门设计用于矩阵乘法和累加(即“张量操作”)的处理单元,其能够高效的执行深度学习中的矩阵运算。
