【CUDA编程】系列博客参考NVIDIA官方文档“CUDA C++ Programming Guide(v12.6)”。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Kernels
在CUDA编程中,kernel是一个在GPU上执行的并行函数。每个kernel会对应一个grid,一个grid里包含多个线程块,这些线程块会交给SM处理,每个SM可以同时处理多个线程块。
需要注意的是,线程块可以是1维、2维或3维的。

图中“Thread (0,0,0)”中的“(0,0,0)”是线程的索引,其对应线程ID的计算可见本文第2部分。
选择线程块的维度通常取决于数据结构和计算模式:
- 1维:如果数据是线性的,如一维数组,那么一维线程块是最自然的选择。它可以简化线程索引计算,并使内存访问模式更加高效。
- 2维:当处理二维数据时,如图像、矩阵或表格,二维线程块可以直接映射到数据的行和列。这样可以简化计算索引,并且使得每个线程块能够有效地处理二维数据块。
- 3维:适用于三维数据集,如体数据(volumetric data),或当计算逻辑本身是三维的(例如三维网格计算时),三维线程块可以更直观地映射到问题空间。
kernel的定义需要使用__global__声明符,kernel调用的线程数通过<<<...>>>来指定。kernel的每个实例都对应一个线程,这些线程可以并行执行,且这些线程都有一个唯一的线程ID,我们可以通过变量threadIdx来获取线程索引。
下面是一个将两个长度为$N$的向量相加的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x; //获取线程索引
//此处用线程索引作为向量的位置索引,相当于每个线程只执行一个位置上的加法运算
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
//1表示启动一个线程块
//N表示指定每个线程块内包含N个线程,即线程块的大小
VecAdd<<<1, N>>>(A, B, C);
...
}
2.Thread Hierarchy
- 对于一维线程块,线程ID就等于线程的索引。
- 对于大小为$(Dx,Dy)$的二维线程块,索引为$(x,y)$的线程所对应的线程ID为$(x+yDx)$。
- 对于大小为$(Dx,Dy,Dz)$的三维线程块,索引为$(x,y,z)$的线程所对应的线程ID为$(x+yDx+zDxDy)$。
如下是两个大小为$N \times N$的矩阵$A,B$相加的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j]; //每个线程只执行一个位置上的加法运算
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
目前,一个线程块最多包含1024个线程。一个grid中线程块的数量通常由要处理的数据大小决定。
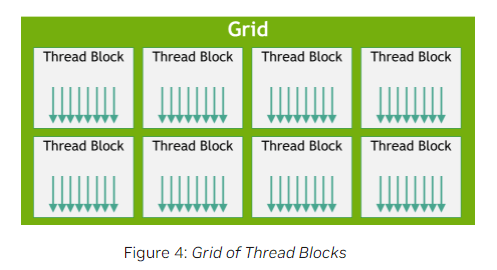
<<<...>>>中第一个参数用于指定每个grid中线程块的数量(格式可以是int或dim3),第二个参数用于指定每个线程块中线程的数量(格式可以是int或dim3)。
可以通过blockIdx和blockDim分别获取线程块的索引和维度。我们将上述矩阵相加的例子扩展到多个线程块上执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); //不一定非得整除
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
在上述例子中,线程块的大小为$16\times 16$(即256个线程),这个大小是一个常见的选择。在该例中,每个矩阵元素都有一个线程负责。
线程块都是独立执行的,可以以任意顺序,并行或串行的执行它们。
同一线程块内的线程可以通过共享内存来协作,并通过同步它们的执行来协调内存访问。更具体地说,可以通过调用__syncthreads()在kernel中指定同步点;__syncthreads()作为一个屏障,在这个屏障处,块内的所有线程必须等待,直到所有线程都到达该点后,才能继续执行。
为了实现高效的协作,共享内存应该是一种位于每个处理器核心附近的低延迟内存(类似L1 cache),并且__syncthreads()也应该是轻量级的。
2.1.Thread Block Clusters
随着NVIDIA Compute Capability 9.0的引入,CUDA编程在grid和block之间引入了一个新的层级,即cluster。一个Thread Block Cluster由多个线程块组成。
在一个线程块内,所有的线程被保证在同一个SM上共同调度。在一个cluster内,所有的线程块被保证在同一个GPU Processing Cluster(GPC)上共同调度。
类似线程块,cluster也可以是1维、2维或3维的。通常,一个cluster最多支持8个线程块。可以通过cudaOccupancyMaxPotentialClusterSize查询GPU中单个cluster所支持的最大线程块数量。
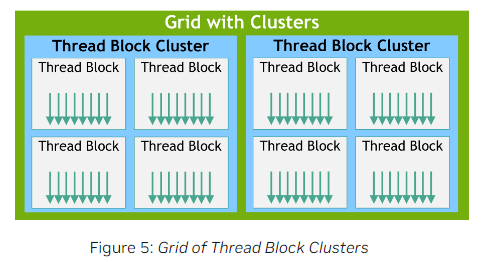
可以通过在kernel中使用编译属性__cluster_dims__(X,Y,Z)或调用API(cudaLaunchKernelEx)来启动Thread Block Cluster。
__cluster_dims__(X,Y,Z)必须在编译时就设定好cluster的大小,运行时无法再修改。下面是一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// Kernel definition
// Compile time cluster size 2 in X-dimension and 1 in Y and Z dimension
__global__ void __cluster_dims__(2, 1, 1) cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
// Kernel invocation with compile time cluster size
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension must be a multiple of cluster size.
cluster_kernel<<<numBlocks, threadsPerBlock>>>(input, output);
}
cudaLaunchKernelEx可以在运行时再设置cluster的大小:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// Kernel definition
// No compile time attribute attached to the kernel
__global__ void cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// Kernel invocation with runtime cluster size
{
cudaLaunchConfig_t config = {0};
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension should be a multiple of cluster size.
config.gridDim = numBlocks;
config.blockDim = threadsPerBlock;
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeClusterDimension;
attribute[0].val.clusterDim.x = 2; // Cluster size in X-dimension
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
config.attrs = attribute;
config.numAttrs = 1;
cudaLaunchKernelEx(&config, cluster_kernel, input, output);
}
}
使用cluster.sync()对cluster内的线程块进行同步。使用num_threads()和num_blocks()分别查询cluster内的线程数量和线程块数量。使用dim_threads()查询block的维度(以线程数为单位),使用dim_blocks()查询cluster的维度(以block数为单位)。
上述都是Cluster Group提供的成员函数。
属于同一个cluster的线程块可以访问分布式共享内存(Distributed Shared Memory)。cluster中的线程块能够对分布式共享内存中的任何地址进行读取、写入以及执行原子操作。
3.Memory Hierarchy
如Fig6所示,CUDA线程在执行过程中可以访问多个内存空间。每个线程都有私有的本地内存。每个线程块有共享内存,该内存对线程块中的所有线程可见,并且其生命周期与线程块相同。同一cluster内的线程块可以对彼此的共享内存执行读、写和原子操作。所有线程都可以访问相同的全局内存(global memory)。

所有线程还可以访问两个额外的只读内存空间:constant memory和texture memory。三种内存空间(global、constant、texture)分别针对不同的内存使用方式进行了专门的优化。这3个内存空间在同一应用程序的多个kernel之间是保持不变的,不会因为kernel的结束而被自动清除。
Memory Hierarchy:
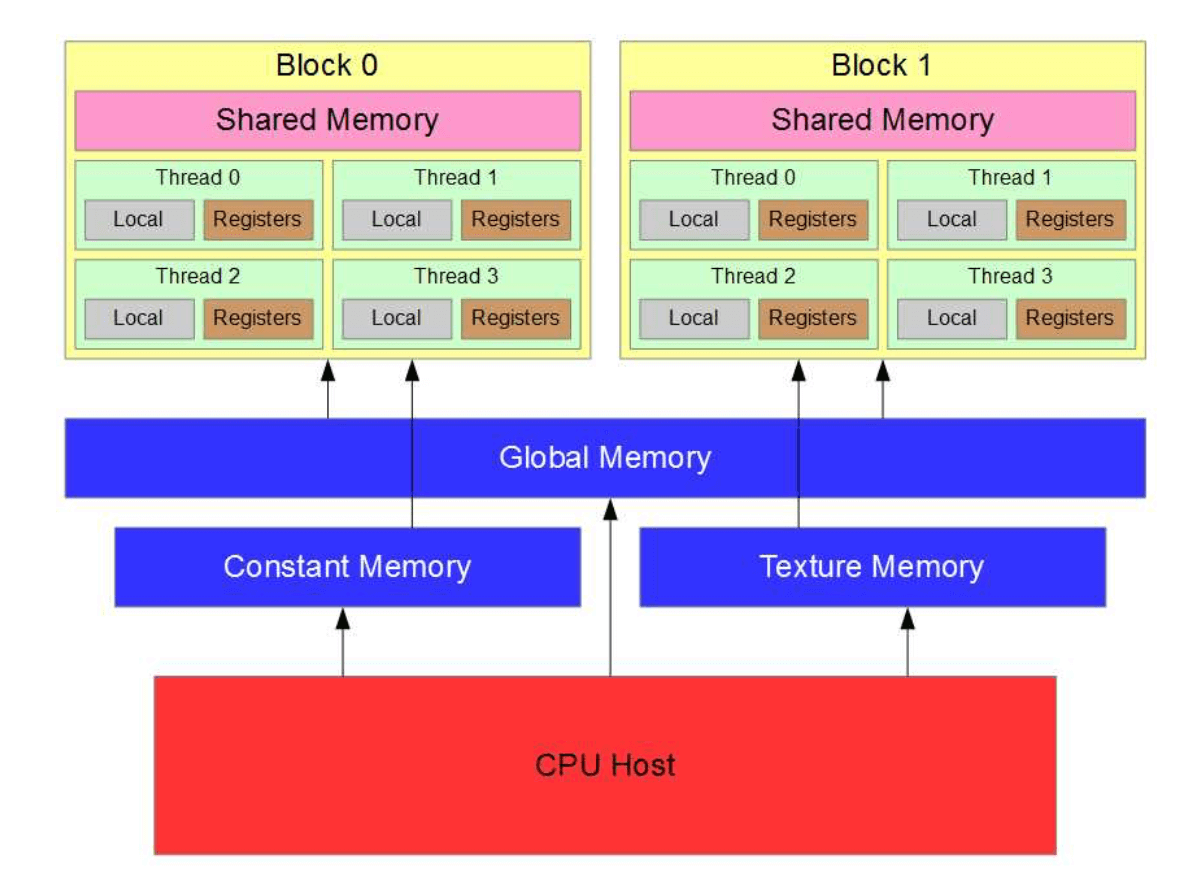
Memories ordered by access speed:

Memory spaces on a CUDA device:
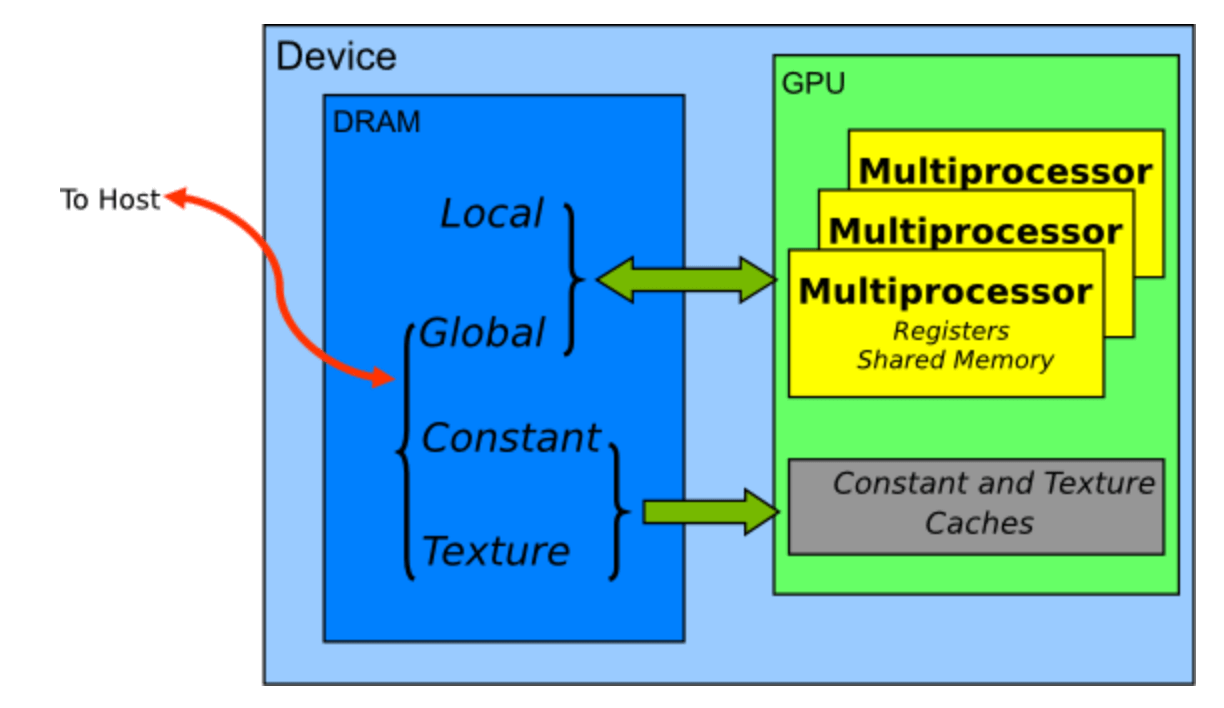
Salient Features of Device Memory:

4.Heterogeneous Programming
异构编程:

在Fig7中,“Host”指的是CPU,“Device”指的是GPU,顺序执行的部分依旧在CPU上运行,而并行部分可以转到GPU上运行,这中间还涉及CPU和GPU之间的数据传递。
5.Asynchronous SIMT Programming Model
通过异步编程模型(asynchronous programming model),CUDA程序可以更有效地并行处理内存操作和计算任务,显著提高性能。
异步编程模型有两个关键功能:
- 异步屏障(Asynchronous Barrier):异步屏障是一种同步机制,用于在CUDA线程之间实现非阻塞的同步。传统的同步方法通常会阻塞线程,直到所有线程都到达同步点。而异步屏障允许线程在等待其他线程的同时继续执行其他任务,从而提高效率。
- 异步数据传输(
cuda::memcpy_async):cuda::memcpy_async允许在GPU执行计算的同时,从全局内存中异步地移动数据。传统的cudaMemcpy是同步操作,会阻塞执行,直到数据传输完成。而cuda::memcpy_async不会阻塞线程,数据传输可以与计算并行进行。
一张图简单解释下同步和异步的区别:
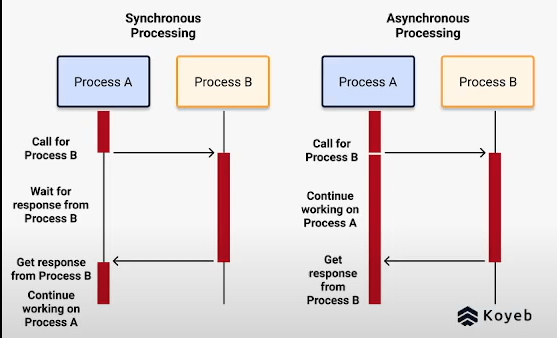
5.1.Asynchronous Operations
异步操作被定义为由某个CUDA线程发起。在异步操作中,我们还需要一个同步对象(synchronization object)来进行同步,同步对象的主要作用是协调不同任务或操作的执行顺序,确保在正确的时间点完成特定任务,从而避免竞态条件和数据不一致性。即使在异步编程中,某些关键点依然需要同步,以确保数据的完整性和程序逻辑的正确性。
在CUDA编程中,这样的同步对象可以由用户显式管理(比如cuda::memcpy_async)或在库中隐式管理(比如cooperative_groups::memcpy_async)。
同步对象可以是cuda::barrier或cuda::pipeline。这些同步对象可以在不同的线程域(thread scope)内使用,下表是CUDA C++支持的线程域:
| 线程域 | 描述 |
|---|---|
cuda::thread_scope::thread_scope_thread |
只有发起异步操作的那个CUDA线程参与同步 |
cuda::thread_scope::thread_scope_block |
发起异步操作的线程块中的所有CUDA线程参与同步 |
cuda::thread_scope::thread_scope_device |
发起异步操作的整个GPU设备上的所有CUDA线程参与同步 |
cuda::thread_scope::thread_scope_system |
发起异步操作的整个系统中的所有CUDA或CPU线程参与同步 |
6.Compute Capability
GPU的计算能力(compute capability)用$X.Y$表示,其中$X$是主要版本号,$Y$是次要版本号。
主要版本号相同的GPU具有相同的核心架构。比如:
- Hopper架构的主要版本号是9。
- Ampere架构的主要版本号是8。
- Volta架构的主要版本号是7。
- Pascal架构的主要版本号是6。
- Maxwell架构的主要版本号是5。
- Kepler架构的主要版本号是3。
次要版本号对应于对核心架构的增量改进,可能包括新功能。比如,Turing架构的计算能力为7.5,是基于Volta架构的增量更新。
计算能力版本和CUDA版本不是一回事。CUDA版本指的是CUDA软件平台的版本。
从CUDA 7.0开始不再支持Tesla架构,从CUDA 9.0开始不再支持Fermi架构。
https://developer.nvidia.com/cuda-gpus列出了所有支持CUDA的device的计算能力。
