本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
源码和预训练模型:PaddleDetection。
单阶段目标检测器因在速度和精度上的良好权衡,一直受到欢迎。单阶段检测器中,最著名的就是YOLO系列。
受到YOLOX的启发,我们对PP-YOLOv2进行了优化,提出了PP-YOLOE(E表示evolved version)。PP-YOLOE为了提高在不同硬件上的通用性,不再使用可变形卷积和Matrix NMS。

2.Method
2.1.A Brief Review of PP-YOLOv2
2.2.Improvement of PP-YOLOE
👉Anchor-free.
PP-YOLOv2仅为每个GT目标分配一个anchor box。然而,anchor机制引入了很多超参数,并且依赖手工设计,无法很好的推广到其他数据集。因此,我们引入了anchor-free机制。anchor-free机制遵循FCOS的思路,每个像素点视为一个anchor point,并且也为每个head都设置了上下限(详见:FCOS论文第3.2部分),将GT bbox分配到对应的feature map上。距离GT bbox中心点最近的像素点被视为正样本。遵循YOLO系列,预测4维向量$(x,y,w,h)$用于回归。尽管根据PP-YOLOv2的anchor size很仔细的设置了上下限,但anchor-based方法和anchor-free方法之间的分配结果仍存在一些微小的不一致,这可能会导致精度轻微下降。
👉Backbone and Neck.
残差连接(比如ResNet、ResNeXt)和密集连接(比如DenseNet)在现代卷积神经网络中已经被广泛使用。我们提出了新的RepResBlock用于backbone和neck中,其结合了残差连接和密集连接。
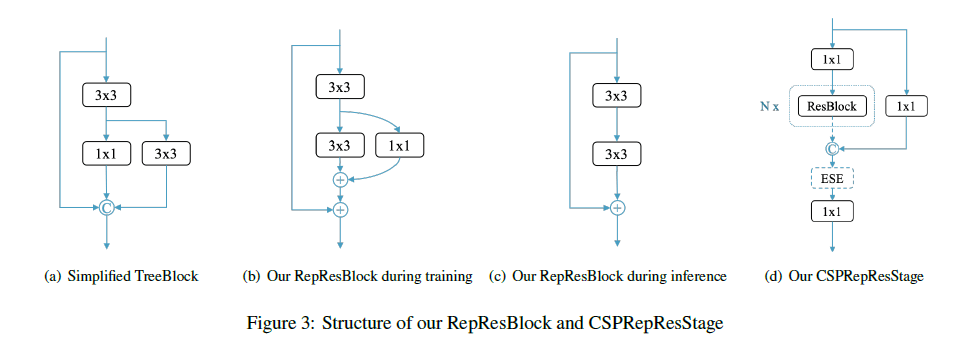
RepResBlock来源于TreeBlock,训练阶段所用的RepResBlock见Fig3(b),推理阶段所用的RepResBlock见Fig3(c)。首先,我们简化了原始的TreeBlock(见Fig3(a))。然后,我们将concat操作替换为了按元素相加的操作(见Fig3(b)),因为这两种操作在某种程度上有一定的近似性。在推理阶段,我们将RepResBlock重新构建为基本的残差块(见Fig3(c))。
TreeBlock:Lu Rao. Treenet: A lightweight one-shot aggregation convolutional network. arXiv preprint arXiv:2109.12342, 2021.。
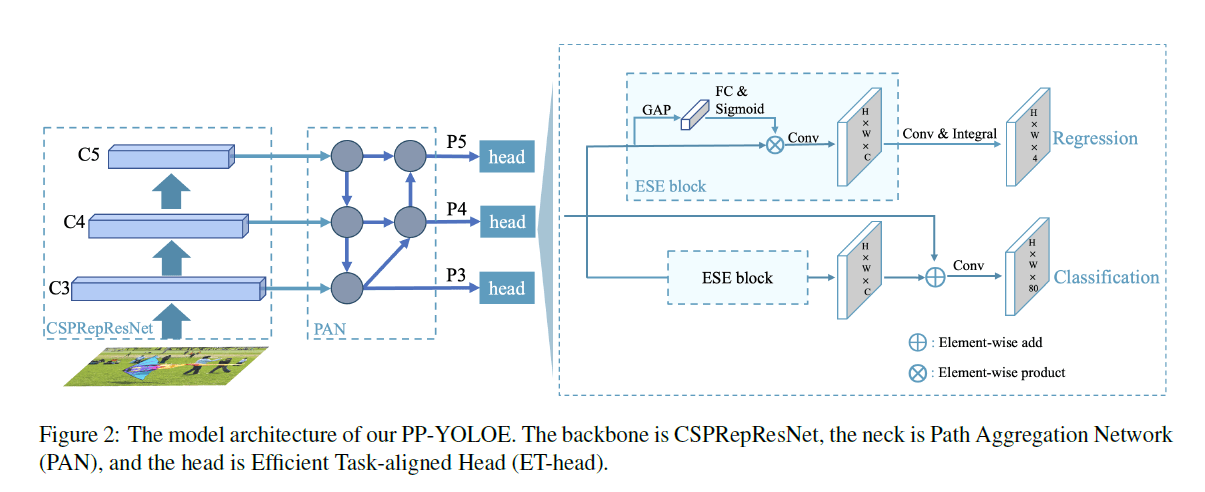
PP-YOLOE-l的整体框架可参考下图:
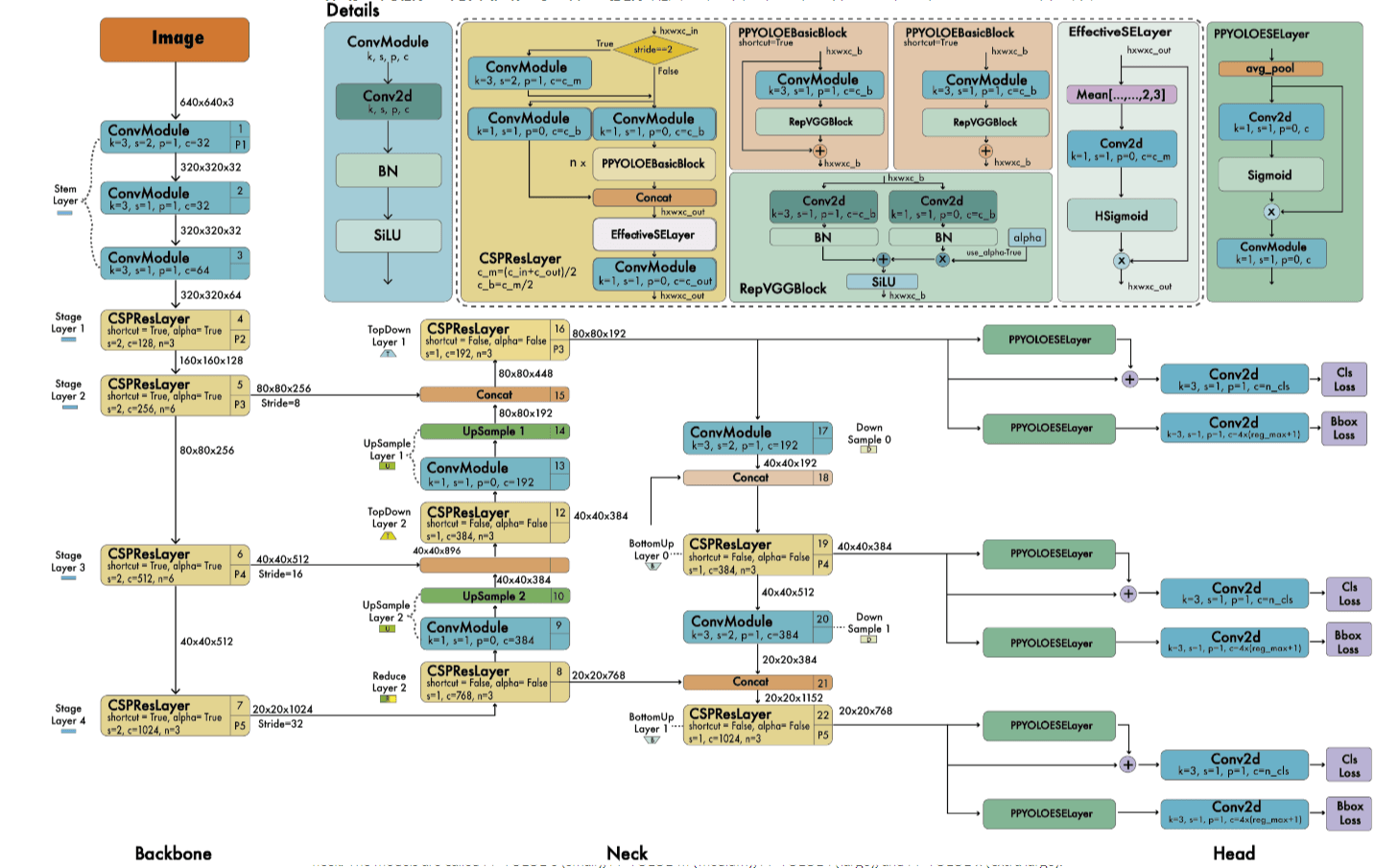
个人注解:$\oplus$表示按元素相加,$\otimes$表示按元素相乘。
我们使用RepResBlock来构建backbone和neck。我们将我们构建的backbone称为CSPRepResNet,其开始首先是3个卷积层,然后是由RepResBlock(见Fig3(d))构建的4个stage。
个人注解:CSP部分可参见CSPNet。
ESE(Effective Squeeze and Extraction)用于施加通道注意力,其结构见下(取自论文“CenterMask : Real-Time Anchor-Free Instance Segmentation”):
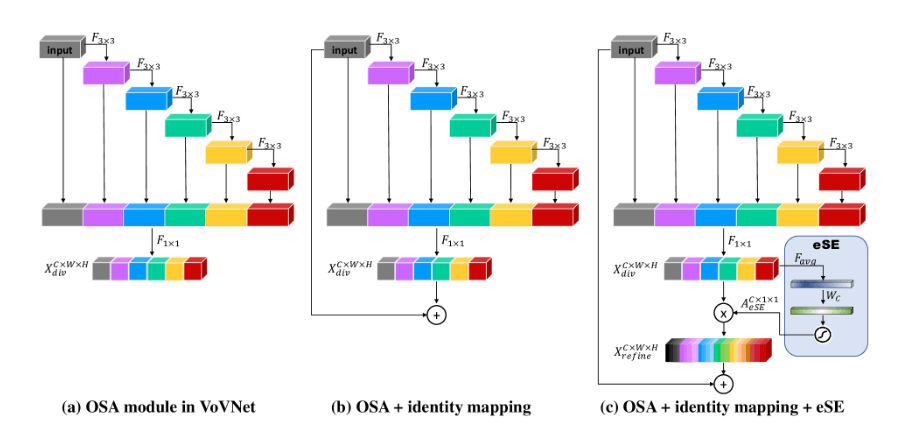
上图中,(a)是OSA(One-Shot Aggregation)模块,(b)是在OSA模块基础上添加了残差连接,(c)在(b)的基础上添加了eSE(effective Squeeze-and-Excitation)注意力模块(即(c)中右下角蓝色部分,这一部分也就是PP-YOLOE所用的ESE)。
类似YOLOv5,我们使用width multiplier $\alpha$和depth multiplier $\beta$来控制模型的大小。我们设置backbone的基础width为$[64,128,256,512,1024]$(个人注解:从PP-YOLOE-l的框架图中可以看到,在backbone中,stem layer到stage layer4的输出通道数分别为$[64,128,256,512,1024]$,即相当于此时$\alpha=1$,如果是PP-YOLOE-s模型,有$\alpha=0.5$,那么stem layer到stage layer4的输出通道数应该分别为$[32,64,128,256,512]$)。不考虑stem,设置backbone的基础depth为$[3,6,6,3]$(个人注解:分别对应backbone中stage layer1到stage layer4的数量,如果是PP-YOLOE-s,有$\beta=0.33$,则stage layer1到stage layer4中的层数应该分别为$[1,2,2,1]$)。类似的,在neck中,我们设置基础width为$[192,384,768]$,基础depth为$3$(个人注解:指的是neck中的CSPResLayer)。不同大小模型的$\alpha,\beta$设置见表1。

个人注解:width multiplier $\alpha$和框架图RepVGGBlock中的alpha不是一回事。
👉Task Alignment Learning (TAL).
我们使用了TAL中的动态标签分配。

👉Efficient Task-aligned Head (ET-head).
我们基于TOOD中的T-head,提出了简化的ET-head,如Fig2所示,我们将T-head中的layer attention替换为了ESE。
个人注解:和Fig2对比发现,上面详细框架图中的PPYOLOESELayer应该画的有问题,正确的应该如下:

使用的损失函数为:
\[Loss = \frac{\alpha \cdot loss_{VFL} + \beta \cdot loss_{GIoU} + \gamma \cdot loss_{DFL}}{\sum_i^{N_{pos}}\hat{t}}\]损失函数的形式借鉴PP-Picodet(在PP-Picodet中,$\alpha=1,\beta=2,\gamma=0.25$)。$\hat{t}$表示归一化目标分数,详见TOOD。
- PP-Picodet:Guanghua Yu, Qinyao Chang, Wenyu Lv, Chang Xu, Cheng Cui, Wei Ji, Qingqing Dang, Kaipeng Deng, Guanzhong Wang, Yuning Du, Baohua Lai, Qiwen Liu, Xiaoguang Hu, Dianhai Yu, and Yanjun Ma. Pp-picodet: A better real-time object detector on mobile devices. CoRR, abs/2111.00902, 2021.。
- VFL:【论文阅读】VarifocalNet:An IoU-aware Dense Object Detector。
- DFL:【论文阅读】Generalized Focal Loss:Learning Qualified and Distributed Bounding Boxes for Dense Object Detection。

3.Experiment
所有实验的训练都在MS COCO-2017训练集上进行,共118k张图像,80个类别。对于消融试验,我们基于MS COCO-2017验证集(共5000k张图像),使用single-scale和标准COCO AP评价指标。在MS COCO-2017 test-dev上汇报了最终结果。
3.1.Implementation details
使用SGD,momentum=0.9,weight decay=$5e-4$。使用cosine learning rate schedule,一共300个epoch,5个epoch用于warmup,基础学习率为0.01。总的batch size为64,在8块32G V100 GPU上,遵循linear scaling rule来调整学习率。使用EMA,在训练过程中设decay=0.9998。我们只使用了一些基础的数据扩展,包括随机裁剪、随机水平翻转、color distortion和多尺度。输入图像的大小在320到768范围内均匀采样32个。
linear scaling rule出自论文:Priya Goyal, Piotr Doll´ ar, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: training imagenet in 1 hour. CoRR, abs/1706.02677, 2017.。
3.2.Comparsion with Other SOTA Detectors

4.Conclusion
不再赘述。
5.原文链接
👽PP-YOLOE:An evolved version of YOLO
