【CUDA编程】系列博客参考NVIDIA官方文档“CUDA C++ Programming Guide(v12.6)”。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Asynchronous Concurrent Execution
CUDA将以下操作视为独立任务,这些任务可以并发执行:
- 在host上的计算。
- 在device上的计算。
- 从host到device的内存传输。
- 从device到host的内存传输。
- device内部内存之间的传输。
- device之间的内存传输。
这些操作的并发性取决于device的特性和计算能力。不同的CUDA device具有不同的硬件架构,因此能够实现的并发操作数量和类型也可能不同。
2.Concurrent Execution between Host and Device
在传统的同步操作中,host必须等待device完成任务后才能继续执行下一个操作,而异步操作允许host和device同时执行任务,从而更高效地利用计算资源。通过异步库函数实现异步调用。以下device操作相对于host来说是异步的:
- kernel启动。
- 在单个device内存中进行的内存拷贝。
- 将host的内存块(大小为64KB或更小)复制到device。
- 以
Async后缀命名的函数执行的内存拷贝。 - 内存设置函数调用。
可以通过将环境变量CUDA_LAUNCH_BLOCKING设置为1,来全局禁用kernel启动的异步性。此功能应仅用于调试目的。
如果通过分析器(Nsight、Visual Profiler)收集硬件计数器,则kernel启动是同步的,除非启用了并发kernel分析。如果Async内存复制涉及非页锁定的host内存,则它们也可能是同步的。
3.Concurrent Kernel Execution
一些计算能力2.x及以上的device可以同时执行多个kernel。应用程序可以通过检查device的concurrentKernels属性来查询这一能力,对于支持该功能的device,其值等于1。
一个CUDA程序通常对应一个进程,同时也对应一个CUDA context。来自一个CUDA context的kernel不能与另一个CUDA context的kernel同时执行。如果希望在同一个SM上同时从多个进程执行kernel,则必须启动MPS(多进程服务)。
此外,使用大量texture memory或local memory的kernel不太可能与其他kernel并发执行。
4.Overlap of Data Transfer and Kernel Execution
某些device支持在执行kernel的同时,执行GPU之间的异步内存传输。应用程序可以通过检查device的asyncEngineCount属性来查询这一功能。对于支持此功能的device,该属性值大于0。如果数据传输涉及host内存,则host内存必须是页锁定的。
在某些device上,也可以在执行kernel的同时,进行device内部的拷贝(需要device支持concurrentKernels属性)和/或device之间的拷贝(需要device支持asyncEngineCount属性)。device内部的拷贝使用标准的内存拷贝函数来执行,源地址和目标地址都位于同一device上。
5.Concurrent Data Transfers
一些计算能力2.x及以上的device可以同时进行device与host之间的数据传输。应用程序可以通过检查device的asyncEngineCount属性来查询这种能力,对于支持该功能的device,其值为2。为了实现同时传输,所有涉及传输的host内存必须是页锁定的。
6.Streams
应用程序通过stream来管理上面描述的并发操作。stream是用于管理并发操作的工具。一个stream中所有的命令(可能由不同的host线程发出)会按顺序执行,而不同stream之间的命令可能会乱序执行,或者并发执行。并且跨stream之间的命令顺序并没有严格保证,其行为是不可预测的。此外,stream的依赖关系需要被满足,比如一个命令可能依赖于同一stream中之前命令的完成或者是其他stream中的命令。
6.1.Creation and Destruction of Streams
stream的创建:
1
2
3
4
5
6
cudaStream_t stream[2]; //创建2个stream对象
for (int i = 0; i < 2; ++i)
cudaStreamCreate(&stream[i]); //创建一个异步stream
float* hostPtr;
//cudaMallocHost作用和cudaHostAlloc类似,也可用于分配页锁定host内存
cudaMallocHost(&hostPtr, 2 * size); //在页锁定内存中分配了一个float类型的数组hostPtr
每个stream的定义如下,包含一次从host到device的内存拷贝、一次kernel启动、一次从device到host的内存拷贝:
1
2
3
4
5
6
7
8
9
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
//MyKernel <<<gridDim, blockDim, sharedMemSize, stream>>>(kernel arguments);
MyKernel <<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
其中,cudaMemcpyAsync用于在host和device之间进行数据拷贝,函数定义如下:
1
2
3
4
5
6
7
8
9
//参数解释:
//dst:目标内存地址
//src:源内存地址
//count:需要拷贝的字节数
//kind:传输类型
//stream:指定stream
__host____device__cudaError_t cudaMemcpyAsync (void
*dst, const void *src, size_t count, cudaMemcpyKind kind,
cudaStream_t stream)
上述示例中,两个stream是并发的,其不同stream的数据传输和kernel启动之间存在重叠,这时就要求hostPtr必须指向页锁定的host内存,才能发生重叠行为。
stream的释放:
1
2
for (int i = 0; i < 2; ++i)
cudaStreamDestroy(stream[i]);
如果在调用cudaStreamDestroy()时,device仍在stream中执行工作,该函数将立即返回,stream相关的资源将在device完成stream中所有工作后自动释放。
6.2.Default Stream
kernel启动和host与device之间的内存拷贝,如果没有指定stream的任何参数,或者明确的将stream的参数都设置为0,则使用默认stream。因此,它们会按照顺序执行。
对于使用了--default-stream per-thread编译标志的代码,或定义了CUDA_API_PER_THREAD_DEFAULT_STREAM宏的代码(通常在CUDA头文件(比如cuda.h和cuda_runtime.h)之前定义),此时默认stream是一个常规的stream,即每个host线程都有自己独立的默认stream。
注意:
当使用
nvcc编译代码时,不能仅通过定义#define CUDA_API_PER_THREAD_DEFAULT_STREAM 1来启动这种行为,因为nvcc会在顶部隐式地包含cuda_runtime.h。在这种情况下,必须使用--default-stream per-thread编译标志,或者使用-DCUDA_API_PER_THREAD_DEFAULT_STREAM=1编译器标志来定义CUDA_API_PER_THREAD_DEFAULT_STREAM宏。
对于使用--default-stream legacy编译标志编译的代码,默认stream是一个特殊的stream,称为NULL stream,针对所有的host线程,每个device都有一个单一的NULL stream。NULL stream可以引发隐式同步。
如果代码在编译时没有指定--default-stream编译标志,那么--default-stream legacy将会是默认设置。
6.3.Explicit Synchronization
有多种方法可以显式的同步多个stream。
cudaDeviceSynchronize()会等待所有host线程的所有stream中之前的命令全部完成。
cudaStreamSynchronize()接受一个stream作为参数,用于等待指定stream中之前所有命令的完成。它可以用来同步host和指定的stream,不影响其他stream在device上的继续运行。
cudaStreamWaitEvent()接受一个stream和一个event作为参数,其要求stream在给定event完成之后再开始执行。
cudaStreamQuery()可以让应用程序知道某一stream中之前的所有命令是否已经全部完成。
6.4.Implicit Synchronization
对于不同stream中的两个命令,如果任何其中一个命令是由host线程发起的如下操作,则这两个命令不能并发运行:
- 页锁定host内存的分配。
- device内存的分配。
- device内存的设置。
- 同一device内存中两个地址之间的内存拷贝。
- 任何发送到NULL stream的CUDA命令。
- L1和共享内存之间的切换。
为了优化并发执行,程序应遵循以下两条指导方针:
- 所有独立操作应该在依赖操作之前发出。即如果某些操作没有依赖关系,应优先执行它们,以提高并行度。
- 任何形式的同步都应该尽可能延迟,以避免过早的性能损耗。
6.5.Overlapping Behavior
两个stream之间的执行重叠量取决于:
- 命令发往每个stream的顺序。
- device是否支持数据传输与kernel执行的重叠(见第4部分)。
- kernel的并发执行(见第3部分)。
- 并发的数据传输(见第5部分)。
以第6.1部分的代码为例,在不支持并发数据传输的device上,两个stream不会有任何重叠。只有等stream[0]中从device到host的内存拷贝完成,才能开始执行stream[1]中从host到device的内存拷贝。如果我们按照以下方式重写代码(假设device支持数据传输和kernel执行的重叠):
1
2
3
4
5
6
7
8
9
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < 2; ++i)
MyKernel<<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
那么,stream[1]中从host到device的内存拷贝会和stream[0]中的kernel启动重叠。
在第6.1部分的代码示例中,如果device支持数据传输的并发,那么stream[1]中从host到device的内存拷贝就会和stream[0]中从device到host的内存拷贝重叠。如果device进一步支持数据传输和kernel执行的并发,那么stream[1]中从host到device的内存拷贝就能和stream[0]中的kernel启动重叠。
6.6.Host Functions (Callbacks)
CUDA运行时提供了一种方式,允许在任意时刻通过cudaLaunchHostFunc()将一个CPU函数调用插入到stream中(称为回调函数)。当stream中回调函数之前的所有命令都完成之后,host会执行该回调函数。
1
2
3
4
5
6
7
8
9
10
void CUDART_CB MyCallback(void *data){
printf("Inside callback %d\n", (size_t)data);
}
...
for (size_t i = 0; i < 2; ++i) {
cudaMemcpyAsync(devPtrIn[i], hostPtr[i], size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(devPtrOut[i], devPtrIn[i], size);
cudaMemcpyAsync(hostPtr[i], devPtrOut[i], size, cudaMemcpyDeviceToHost, stream[i]);
cudaLaunchHostFunc(stream[i], MyCallback, (void*)i); //回调函数
}
等回调函数执行完成之后,stream才会继续往下运行。
插入的回调函数不应包含任何CUDA API调用。如果回调函数调用了CUDA API,可能会导致它等待自己,陷入死锁的情况。
6.7.Stream Priorities
stream的相对优先级可以在其创建时通过cudaStreamCreateWithPriority()指定。可允许的优先级范围[最高优先级,最低优先级]可以通过cudaDeviceGetStreamPriorityRange()函数获取。在运行时,较高优先级stream中的工作会优先于较低优先级stream中的工作。
1
2
3
4
5
6
7
8
// get the range of stream priorities for this device
int priority_high, priority_low;
cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high);
// create streams with highest and lowest available priorities
cudaStream_t st_high, st_low;
cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);
//cudaStreamNonBlocking标志表示创建的stream可以与stream 0(即NULL stream)中的工作并发执行,并且不应该与stream 0进行隐式同步
7.Programmatic Dependent Launch and Synchronization
程序化依赖启动(Programmatic Dependent Launch)机制允许在相同的CUDA stream中,次级kernel在其依赖的主要kernel还未完全执行完毕时启动。该技术从计算能力9.0的device开始使用,这一技术可以提升性能。
7.1.Background
一个CUDA应用程序可以启动并执行多个kernel,如Fig10所示。

在Fig10中,等待primary_kernel完成之后,secondary_kernel才启动。当secondary_kernel依赖primary_kernel输出的结果数据时,这种顺序执行是必要的。在这个stream中,如果secondary_kernel不依赖primary_kernel,它们两个其实是可以并发启动的。即使secondary_kernel依赖primary_kernel,它们当中也可能存在部分操作是可以并发的,例如,几乎所有的kernel都会有某种形式的前序部分(preamble section),用于执行一些诸如清空缓冲区、加载常量值等任务,如Fig11所示。

而这些前序部分是可以并发的,如Fig12所示:

7.2.API Description
在程序化依赖启动机制中,primary kernel和secondary kernel在同一个stream中启动。primary kernel应该在准备好启动secondary kernel时,调用cudaTriggerProgrammaticLaunchCompletion,通知所有线程块已经准备好。secondary kernel必须通过扩展的启动API来启动,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
__global__ void primary_kernel() {
// Initial work that should finish before starting secondary kernel
// Trigger the secondary kernel
cudaTriggerProgrammaticLaunchCompletion();
// Work that can coincide with the secondary kernel
}
__global__ void secondary_kernel()
{
// Independent work
// Will block until all primary kernels the secondary kernel is dependent on have completed and flushed results to global memory
cudaGridDependencySynchronize();
// Dependent work
}
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeProgrammaticStreamSerialization;
attribute[0].val.programmaticStreamSerializationAllowed = 1;
configSecondary.attrs = attribute;
configSecondary.numAttrs = 1;
primary_kernel<<<grid_dim, block_dim, 0, stream>>>();
cudaLaunchKernelEx(&configSecondary, secondary_kernel);
当secondary kernel使用cudaLaunchAttributeProgrammaticStreamSerialization属性启动时,CUDA驱动程序确保可以安全地启动secondary kernel,而不需要等待primary kernel完成并将数据刷入全局内存。
CUDA驱动程序在primary kernel执行了cudaTriggerProgrammaticLaunchCompletion后,可以启动secondary kernel。如果没有显式的调用cudaTriggerProgrammaticLaunchCompletion,则在primary kernel完成之后,会隐式的启动secondary kernel。
上述两种情况中,secondary kernel都有可能会在primary kernel写入数据之前启动。因此,配置了程序化依赖启动的secondary kernel必须使用cudaGridDependencySynchronize或其他方法,以验证来自primary kernel的数据已经可用。
如果依赖此方法实现并发,一定要小心可能会导致的死锁问题。
7.3.Use in CUDA Graphs
可以通过stream capture或直接通过edge data在CUDA graph中使用程序化依赖启动。如果要在使用edge data的CUDA graph中使用这个特性,需要对连接两个kernel节点的边设置cudaGraphDependencyType属性,将其属性值指定为cudaGraphDependencyTypeProgrammatic。这种边类型使得上游kernel对下游kernel中的cudaGridDependencySynchronize()是可见的。此类型必须和cudaGraphKernelNodePortLaunchCompletion或cudaGraphKernelNodePortProgrammatic这两个输出端口的其中一个一起使用。
stream capture的等效graph如下所示:

8.CUDA Graphs
CUDA graph是一系列操作的集合,例如kernel启动,这些操作通过依赖关系连接起来,并且其定义与执行是分开的。这允许graph可以定义一次,然后多次启动。将graph的定义和执行分离可以实现多种优化:首先,与stream相比,CPU启动成本得到了降低,因为大部分设置工作提前完成;其次,将整个工作流提供给CUDA,可以实现stream可能无法实现的优化。
为了理解graph的优化效果,可以考虑stream中的情况:当我们将kernel放入stream时,host驱动程序会执行一系列准备操作,以便在GPU上执行该kernel。这些操作是启动和设置kernel所必需的,是每个kernel启动时都必须承担的开销。对于在GPU上执行时间很短的kernel来说,这些开销可能占据整体端到端执行时间的相当一部分。
使用graph提交工作分为3个不同的阶段:定义、实例化和执行。
- 在定义阶段,程序创建graph中的操作描述以及它们之间的依赖关系。
- 实例化会对graph模板进行快照(snapshot)、验证,并完成大部分设置和初始化工作,目的是将启动时需要完成的工作最小化。实例化后的graph称为可执行graph(executable graph)。
- 可执行graph可以被提交到stream中,类似于其他任何CUDA工作。它可以多次启动,而不需要重复实例化。
8.1.Graph Structure
graph中的一个节点表示一个操作。操作之间的依赖关系则是graph中的边。这些依赖关系约束了操作的执行顺序。
一旦该操作所依赖的节点完成,该操作可以在任何时间被调度。调度工作由CUDA系统负责。
8.1.1.Node Types
graph的节点可以是:
- kernel
- CPU函数调用
- 内存拷贝
- 内存设置(memset)
- 空节点
- 等待一个event
- 记录一个event
- 触发一个外部信号量(external semaphore)
- 等待一个外部信号量
- 条件节点(conditional node)
- 子graph(如下图所示)

8.1.2.Edge Data
CUDA 12.3在CUDA graph中引入了边数据(edge data)。边数据修改了由边指定的依赖关系,其包括三部分:一个输出端口、一个输入端口和一个类型。输出端口用于指定何时触发关联边。输入端口用于指定节点的哪个部分依赖于关联边。类型用于修改端点之间的关系。
端口值和节点的类型与方向相关,某些边类型只能用于特定的节点类型。在所有情况下,零初始化的边数据表示默认行为。输出端口0(即端口值为0)表示它会等待所有依赖的任务都完成,才会向下游传递数据或发出信号。输入端口0表示它会阻塞当前任务,直到它所依赖的条件被满足(如上游任务的完成)。当CUDA graph中使用边类型0时,意味着两个节点之间有完全的依赖关系,这种依赖不仅要求前一个节点的计算任务必须完全完成,才能触发下一个节点的执行,还要求内存操作保持同步。也就是说,前一个节点的所有内存访问(读、写等)都必须在下一个节点开始执行之前完全完成,从而保证数据一致性和正确性。
通过调用CUDA graph的API,可以选择性的传入或不传入边数据。如果不传入边数据,则会对边数据进行零初始化。如果通过CUDA graph的API查询特定的边数据,即没有查询所有的边数据,这可能会导致一些信息被忽略,如果被忽略的边数据都是零初始化的,则这个查询操作是没有问题的,但如果被忽略的边数据中有非零值,则这个查询操作会抛出cudaErrorLossyQuery错误。
在一些stream capture API中也可以使用边数据,比如cudaStreamBeginCaptureToGraph()、cudaStreamGetCaptureInfo()和cudaStreamUpdateCaptureDependencies()。在这些情况下,还没有下游节点。数据被关联到dangling edge(或称half edge),其将连接到未来捕获的节点,或者在stream capture终止时被丢弃。需要注意的是,一些边类型不等待上游节点的完全完成。这些边在判断stream capture是否完全重新连接到原始stream时会被忽略,并且在捕获结束时不能被丢弃。
当前,没有任何节点类型定义了额外的输入端口,且只有kernel节点定义了额外的输出端口。有一种非默认的依赖类型,cudaGraphDependencyTypeProgrammatic,详见第7.3部分。
8.2.Creating a Graph Using Graph APIs
CUDA graph可以通过两种机制创建:显式API和stream capture。下面是一个graph的创建并执行的示例。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// Create the graph - it starts out empty
cudaGraphCreate(&graph, 0);
// For the purpose of this example, we'll create
// the nodes separately from the dependencies to
// demonstrate that it can be done in two stages.
// Note that dependencies can also be specified
// at node creation.
//这个例子将创建节点和定义依赖关系分开了
//通常情况下,用户可以在创建节点时就定义依赖关系
cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&b, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&c, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&d, graph, NULL, 0, &nodeParams);
// Now set up dependencies on each node
cudaGraphAddDependencies(graph, &a, &b, 1); // A->B
cudaGraphAddDependencies(graph, &a, &c, 1); // A->C
cudaGraphAddDependencies(graph, &b, &d, 1); // B->D
cudaGraphAddDependencies(graph, &c, &d, 1); // C->D
函数cudaGraphCreate用于创建一个graph:
1
2
3
4
5
//参数解释:
//1.pGraph:返回新创建的graph
//2.flags:graph创建标志,必须是0
__host__cudaError_t cudaGraphCreate (cudaGraph_t
*pGraph, unsigned int flags)
函数cudaGraphAddKernelNode用于向graph中添加kernel执行节点:
1
2
3
4
5
6
7
8
9
10
11
//参数解释:
//1.pGraphNode:返回新创建的节点
//2.graph:指定被添加节点的graph
//3.pDependencies:节点的依赖
//4.numDependencies:依赖的数量
//5.pNodeParams:GPU执行节点的参数
__host__cudaError_t cudaGraphAddKernelNode
(cudaGraphNode_t *pGraphNode, cudaGraph_t graph,
const cudaGraphNode_t *pDependencies, size_t
numDependencies, const cudaKernelNodeParams
*pNodeParams)
函数cudaGraphAddDependencies用于向graph中添加依赖边:
1
2
3
4
5
6
7
8
//参数解释:
//1.graph:指定被添加依赖的graph
//2.from:提供依赖的节点数组
//3.to:依赖的节点数组
//4.numDependencies:添加的依赖的数量
__host__cudaError_t cudaGraphAddDependencies
(cudaGraph_t graph, const cudaGraphNode_t *from, const
cudaGraphNode_t *to, size_t numDependencies)
8.3.Creating a Graph Using Stream Capture
stream capture是CUDA中的一种机制,它允许将现有的stream操作记录下来,创建一个可以复用的graph。通过这种方式,用户可以捕获一段stream中的一系列操作(例如kernel调用、库函数调用等),然后将这些操作打包成一个graph对象,供以后复用,从而避免每次都重新提交相同的任务。比如,在神经网络推理时,每次任务的计算步骤基本相同,通过stream capture,用户可以将整个任务流程捕获成graph,之后直接调度这个graph,而不必每次都提交单独的操作。该机制通过cudaStreamBeginCapture()和cudaStreamEndCapture()来开启和结束捕获。
1
2
3
4
5
6
7
8
9
10
cudaGraph_t graph;
cudaStreamBeginCapture(stream);
kernel_A<<< ..., stream >>>(...);
kernel_B<<< ..., stream >>>(...);
libraryCall(stream);
kernel_C<<< ..., stream >>>(...);
cudaStreamEndCapture(stream, &graph);
调用cudaStreamBeginCapture()会将stream置于捕获模式(capture mode)。当一个stream被捕获时,在该stream中启动的工作并不会被直接执行。相反,这些工作会被用于构建一个graph。最终通过调用cudaStreamEndCapture()将该graph返回,这同时也结束了该stream的捕获模式。该graph也称为capture graph。
stream capture可被用于除cudaStreamLegacy(即NULL stream)之外的任何CUDA stream。也可以在cudaStreamPerThread中使用stream capture。
可以通过cudaStreamIsCapturing()来查询stream是否正在被捕获。使用cudaStreamBeginCaptureToGraph()将工作捕获到一个已经存在的graph中。
8.3.1.Cross-stream Dependencies and Events
stream capture也可以处理cross-stream之间的依赖关系,通过调用cudaEventRecord()和cudaStreamWaitEvent()来实现,前提是被等待的event已经记录在同一个capture graph中。
当一个event被处于捕获模式的stream记录时,会产生一个captured event。一个captured event代表capture graph中的一组节点。
当一个captured event被一个stream等待时,其会将该stream置于捕获模式(如果这个stream之前不是捕获模式的话),然后该stream的下一个操作对这个captured event会有额外的依赖关系。两个stream因此被捕获到同一个capture graph中。
当在stream capture中出现cross-stream依赖时,必须在调用cudaStreamBeginCapture()的同一个stream中调用cudaStreamEndCapture(),称这个stream为原始stream。由于基于event的依赖关系,任何其他被捕获到同一个capture graph中的stream也必须返回到原始stream中。如下方代码所示,所有被捕获到同一个capture graph的stream都会在调用cudaStreamEndCapture()后退出捕获模式。如果不重新返回到原始stream中,则所有的捕获操作都会失败。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// stream1 is the origin stream
cudaStreamBeginCapture(stream1);
kernel_A<<< ..., stream1 >>>(...);
// Fork into stream2
//在stream1中记录event1,它会在stream1中所有先前任务(即kernel_A)完成后被标记为完成
cudaEventRecord(event1, stream1);
//stream2会等待event1的完成
//也就是说,stream2中所有后续还没有提交的任务都会在event1完成后才开始执行
cudaStreamWaitEvent(stream2, event1);
kernel_B<<< ..., stream1 >>>(...);
kernel_C<<< ..., stream2 >>>(...);
// Join stream2 back to origin stream (stream1)
//stream2中所有任务(即kernel_C)完成后,event2才会被标记为完成
cudaEventRecord(event2, stream2);
//stream1必须等待stream2完成kernel_C之后,才能继续执行接下来的任务
cudaStreamWaitEvent(stream1, event2);
kernel_D<<< ..., stream1 >>>(...);
// End capture in the origin stream
cudaStreamEndCapture(stream1, &graph);
// stream1 and stream2 no longer in capture mode
上述代码返回的graph就是Fig14。
注意:
当stream退出捕获模式时,stream中的下一个未捕获项(如果有)仍将依赖于最近的先前未捕获项,尽管已删除中间项。
8.3.2.Prohibited and Unhandled Operations
当一个stream或其关联stream处于捕获状态时,不允许同步或查询其执行状态。
当同一context中的stream正在被捕获时,如果该stream不是用cudaStreamNonBlocking创建的,那么尝试使用legacy stream(即NULL stream)是无效的。
在这种情况下,调用同步API(比如cudaMemcpy())也是无效的。
注意:
通常情况下,如果尝试创建一个捕获任务与未捕获任务之间的依赖关系,CUDA会抛出错误,而不是忽略这种依赖关系。不过,有一个例外情况,当我们正在将stream切换到捕获模式或从捕获模式退出时,这种依赖关系会被自动切断。
通过等待来自一个stream的captured event,将其与另一个capture graph中的event关联,来合并两个capture graph是无效的。同样,在没有指定cudaEventWaitExternal标志的情况下,等待一个正在被捕获的stream的非捕获event也是无效的。
有少量API将异步操作引入stream中,但它们当前不支持在capture graph中使用,并且如果当stream正在被捕获时调用这些API,这些API会返回错误。其中一个例子是cudaStreamAttachMemAsync()。
8.3.3.Invalidation
当在stream capture期间尝试无效操作时,任何关联的capture graph都将失效。当capture graph无效时,进一步使用正在捕获的任何stream或与该graph关联的captured event都将失效并返回错误,直到调用cudaStreamEndCapture()结束stream capture。此调用将使关联的stream脱离捕获模式,并返回一个错误值和一个NULL graph。
8.4.CUDA User Objects
CUDA用户对象(CUDA User Objects)可用于帮助管理CUDA异步工作中使用的资源生命周期,尤其是在CUDA graph和stream capture中很有用。
许多资源管理方案不兼容CUDA graph,如event-based pool、同步创建(synchronous-create)或异步销毁(asynchronous-destroy)等。
下面是一个event-based pool的资源管理方案:
1
2
3
4
5
6
7
8
9
10
11
// Library API with pool allocation
void libraryWork(cudaStream_t stream) {
//从资源池中获取一个临时资源
auto &resource = pool.claimTemporaryResource();
//让该资源等待指定stream中某个event的完成
resource.waitOnReadyEventInStream(stream);
//启动工作
launchWork(stream, resource);
//在指定stream中记录一个event,表示该资源已经准备完成
resource.recordReadyEvent(stream);
}
下面是一个异步销毁的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Library API with asynchronous resource deletion
void libraryWork(cudaStream_t stream) {
//动态分配资源
Resource *resource = new Resource(...);
//启动工作
launchWork(stream, resource);
//回调函数
//待stream中回调函数之前的任务都完成后,回调函数会被调用
//回调函数将资源删除
cudaStreamAddCallback(
stream,
[](cudaStream_t, cudaError_t, void *resource) {
delete static_cast<Resource *>(resource);
},
resource,
0);
// Error handling considerations not shown
}
诸如上述这些传统的资源管理方式在CUDA graph或stream capture中都难以使用。原因有以下几点:
- 在传统资源管理中,资源的指针或句柄可能是动态分配的,在程序执行期间可能变化。然而,CUDA graph要求graph中所有资源在构建阶段就被确定,并且在graph的生命周期内保持不变,这样做是为了保证graph的结构可以重复使用,而不需要每次执行前进行更新。如果资源的指针或句柄是非固定的,那么CUDA graph在每次执行时都需要更新指向这些资源的引用,这违背了graph的设计原则,导致了额外的复杂性。
- 传统的资源管理方式通常需要在每次提交任务前通过CPU代码对资源进行初始化或同步。在CUDA graph的执行中,希望减少CPU的参与,使整个graph可以在GPU上自主执行。每次都调用CPU来进行同步会降低效率,也违背了CUDA graph设计的初衷,即最大化GPU的自主执行能力。因此,这些同步CPU代码在CUDA graph中不合适,因为它们引入了额外的开销和依赖,影响graph的执行效率。
- stream capture是一种记录stream中操作序列的方式,捕获的stream可以在之后重复执行。然而,在stream capture期间,某些API(如动态内存分配或异步回调等)是被禁止的,因为它们会导致不可重复的行为。
为了解决上述问题,有两种方法,一种是将资源暴露给调用者,即让调用者手动管理资源的生命周期。另一种方法就是使用CUDA用户对象。
CUDA用户对象允许用户指定一个析构回调函数,这个函数会在对象不再需要时自动调用,以销毁或清理资源。这类似于C++中的shared_ptr。和shared_ptr一样,CUDA用户对象内部维护了一个引用计数,用于记录有多少个地方在使用该对象。当引用计数降为零时,对象会自动销毁。CPU端和CUDA graph可以使用同一个CUDA用户对象。也就是说,由CUDA用户对象管理的引用(个人理解这里的引用和C++中的引用概率类似,指的是对同一资源的调用,这里的资源即可以是内存资源,也可以是CUDA event或CUDA stream等,其概念比较宽泛),是由CUDA用户对象自动管理的,并且通过内部的引用计数来跟踪。与其不同,由用户自己创建的引用,则需要用户手动自行管理。用户可以通过将自己创建的引用移动到CUDA graph中,从而将资源管理的任务交给CUDA graph。
当一个引用关联到CUDA graph时,CUDA将自动管理该graph的操作。被克隆的cudaGraph_t会保留源cudaGraph_t中每个引用的副本。被实例化的cudaGraphExec_t也会保留源cudaGraph_t中每个引用的副本。当cudaGraphExec_t在未同步的情况下被销毁时,这些引用将一直保留,直到执行完成。
下面是一个例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
//定义一个CUDA graph对象
cudaGraph_t graph; // Preexisting graph
Object *object = new Object; // C++ object with possibly nontrivial destructor
//定义一个CUDA用户对象
cudaUserObject_t cuObject; //CUDA user object for graphs
//创建该CUDA用户对象
cudaUserObjectCreate( //Create a user object
&cuObject,
object, // Here we use a CUDA-provided template wrapper for this API,
// which supplies a callback to delete the C++ object pointer
1, // Initial refcount
cudaUserObjectNoDestructorSync // Acknowledge that the callback cannot be
// waited on via CUDA
);
cudaGraphRetainUserObject(
graph,
cuObject,
1, // Number of references
cudaGraphUserObjectMove // Transfer a reference owned by the caller (do
// not modify the total reference count)
);
// No more references owned by this thread; no need to call release API
cudaGraphExec_t graphExec;
//实例化CUDA graph,将graph转换为可执行状态
cudaGraphInstantiate(&graphExec, graph, nullptr, nullptr, 0); // Will retain a
// new reference
//销毁graph,但graphExec仍然持有cuObject的引用,因此该用户对象不会被释放
cudaGraphDestroy(graph); // graphExec still owns a reference
//在默认stream中启动graphExec,此时它可以访问用户对象
cudaGraphLaunch(graphExec, 0); // Async launch has access to the user objects
//销毁实例graphExec
//此时如果graph尚未完成,CUDA将延迟释放用户对象的引用,确保异步任务可以安全地访问资源
cudaGraphExecDestroy(graphExec); // Launch is not synchronized; the release
// will be deferred if needed
//确保默认stream中的任务同步完成
//同步后,graphExec持有的最后一个引用将释放
cudaStreamSynchronize(0); // After the launch is synchronized, the remaining
// reference is released and the destructor will
// execute. Note this happens asynchronously.
// If the destructor callback had signaled a synchronization object, it would
// be safe to wait on it at this point.
在上述代码中,cudaUserObjectCreate用于创建一个用户对象:
1
2
3
4
5
6
7
8
//Create a user object
__host__cudaError_t cudaUserObjectCreate(
cudaUserObject_t *object_out, //Location to return the user object handle
void *ptr, //The pointer to pass to the destroy function
cudaHostFn_t destroy, //Callback to free the user object when it is no longer in use
unsigned int initialRefcount, //The initial refcount to create the object with, typically 1. The initial references are owned by the calling thread.
unsigned int flags //Currently it is required to pass cudaUserObjectNoDestructorSync, which is the only defined flag. This indicates that the destroy callback cannot be waited on by any CUDA API. Users requiring synchronization of the callback should signal its completion manually.
)
参数解释:
cudaUserObject_t *object_out:返回创建的用户对象的句柄。void *ptr:指向要传递给销毁函数的指针,通常是用户创建的对象或资源的指针。这个指针在对象销毁时会被传递给destroy回调函数,用于在引用计数归零时执行清理操作。cudaHostFn_t destroy:用于释放用户对象的回调函数,当对象不再被使用时调用。该回调函数的作用是执行销毁操作,例如调用delete或释放其他资源。它在引用计数为零时触发,确保资源被正确释放。unsigned int initialRefcount:为对象创建初始引用计数,通常设为1。此计数表示调用线程最初持有的引用数。引用计数用于跟踪有多少地方在使用该对象。当引用计数降为零时,CUDA会调用destroy回调来销毁该对象。unsigned int flags:指定用户对象的选项,目前只定义了cudaUserObjectNoDestructorSync标志。该标志表示在执行销毁回调时,CUDA不会等待回调完成。这意味着销毁回调是异步的,无法通过CUDA API进行同步。如果用户需要同步,则需要在回调中手动处理。
在代码示例中,调用的cudaUserObjectCreate其实是一个封装的接口(对底层原始的cudaUserObjectCreate进行了封装),该封装为destroy参数提供了一个默认的销毁回调函数,所以在代码示例中只传入了4个参数。
cudaGraphRetainUserObject函数将一个用户对象的引用关联到一个CUDA graph,以便在graph的生命周期内保持该用户对象有效,确保graph执行过程中不被销毁:
1
2
3
4
5
6
__host__cudaError_t cudaGraphRetainUserObject(
cudaGraph_t graph,
cudaUserObject_t object,
unsigned int count,
unsigned int flags
)
参数解释:
cudaGraph_t graph:表示要与用户对象关联的graph。cudaUserObject_t object:被关联的用户对象。unsigned int count:表示要添加到graph的引用数量,通常设为1。该值必须是非零的,且小于INT_MAX。unsigned int flags:提供额外的标志,用于指定引用的处理方式。常用的标志是cudaGraphUserObjectMove,表示将当前线程持有的引用转移到graph中,而不是创建新的引用。也就是说,当使用cudaGraphUserObjectMove标志时,调用方不需要保留对象的引用,因此不需要额外调用API来释放引用。传入0则表示创建新的引用,不会影响调用方持有的引用数量。
child graph节点中的引用归child graph所有,而不是parent graph。如果child graph被更新或删除,引用也会相应地更改。如果使用cudaGraphExecUpdate或cudaGraphExecChildGraphNodeSetParams更新可执行graph(或child graph),那么源graph中的引用会被克隆并替换目标graph中的引用。在这两种情况下,如果之前的执行未同步,任何需要释放的引用都会被保留,直到执行完成。
目前,CUDA API中没有机制可以等待用户对象的析构函数执行完成。用户可以在析构函数代码中手动触发一个同步对象。此外,从析构函数中调用CUDA API是不合法的,这与cudaLaunchHostFunc的限制类似。这是为了避免阻塞CUDA内部的共享线程,影响后续操作的进行。如果依赖关系是单向的,并且执行调用的线程不会阻止CUDA工作的进展,那么可以合法地通知另一个线程去执行CUDA API调用。
8.5.Updating Instantiated Graphs
graph的使用分为三个阶段:定义(definition)、实例化(instantiation)和执行(execution)。在工作流不变的情况下,graph只需定义和实例化一次,但可以执行多次,这使得graph相比于stream具有明显的优势。
如果工作流发生变化,就需要更新graph的定义,并重新进行实例化。
但是频繁的实例化会降低使用graph的整体性能收益。但如果graph的拓扑结构保持不变,只是更改了一些节点参数(比如kernel参数或cudaMemcpy地址),CUDA提供了一种称为”Graph Update”的轻量级更新机制,允许只对特定节点参数进行修改,而无需重新实例化整个graph。
更新将在graph下次启动时生效。即使在更新时已经有graph正在执行,之前启动的graph也不会受到影响。
CUDA提供了两种机制来更新已实例化的graph:整个graph更新(whole graph update)和单个节点更新(individual node update)。整个graph更新允许用户构建一个拓扑结构相同的cudaGraph_t对象,其节点包含已更新的参数。单个节点更新允许用户显式更新单个节点的参数。
此外,CUDA还提供了启用和禁用单个节点的机制,且不会影响其当前参数。
8.5.1.Graph Update Limitations
本部分是graph更新时的一些限制。
kernel节点:
- 函数所属的context不能改变。
- 原本未使用CUDA动态并行性(“动态并行性”指的是允许kernel在运行时启动其他kernel)的节点,不能更新为使用动态并行性的节点。
cudaMemset和cudaMemcpy节点:
- 如果某个数据最初被分配或映射到了特定的CUDA device(比如GPU0),在更新graph时,这个数据不能被重新分配或映射到另一个device(比如GPU1)。
- 传输操作的源内存或目标内存必须与原始定义时使用相同的context进行分配。
- 只有一维的
cudaMemset或cudaMemcpy节点可以在更新时被修改。
额外的memcpy节点限制:
- 不支持更改源内存或目标内存的内存类型(比如
cudaPitchedPtr、cudaArray_t等),也不支持更改其传输类型(比如cudaMemcpyKind)等。
外部信号量(semaphore)等待节点和记录节点:
- 不支持更改信号量的数量。
这里简单解释下信号量。
信号量是一种用于多线程或多进程同步的机制。它是一个计数器,控制对共享资源的访问,避免竞争条件或死锁。信号量可以用来协调不同线程或进程之间的操作顺序。此处引用下百度百科中对信号量的描述和解释(参见:信号量(百度百科))。
以一个停车场的运作为例。简单起见,假设停车场只有三个车位,一开始三个车位都是空的。这时如果同时来了五辆车,看门人允许其中三辆直接进入,然后放下车拦,剩下的车则必须在入口等待,此后来的车也都不得不在入口处等待。这时,有一辆车离开停车场,看门人得知后,打开车拦,放入外面的一辆进去,如果又离开两辆,则又可以放入两辆,如此往复。在这个停车场系统中,车位是公共资源,每辆车好比一个线程,看门人起的就是信号量的作用。
抽象的来讲,信号量的特性如下:信号量是一个非负整数(车位数),所有通过它的线程/进程(车辆)都会将该整数减一(通过它当然是为了使用资源),当该整数值为零时,所有试图通过它的线程都将处于等待状态。在信号量上我们定义两种操作:Wait(等待)和Release(释放)。当一个线程调用Wait操作时,它要么得到资源然后将信号量减一,要么一直等下去(指放入阻塞队列),直到信号量大于等于一时。Release(释放)实际上是在信号量上执行加操作,对应于车辆离开停车场,该操作之所以叫做“释放”是因为释放了由信号量守护的资源。
对于条件节点(conditional nodes):
- 句柄创建和分配的顺序必须在graph之间匹配。
- 条件节点不支持更改节点参数。
- 在conditional body graph中的节点参数更改也受到上述规则的限制。
host节点、event记录节点、event等待节点的更新则没有限制。
8.5.2.Whole Graph Update
cudaGraphExecUpdate()函数允许使用相同拓扑结构的graph(称为updating graph)中的参数去更新实例化graph(称为original graph)。updating graph的拓扑结构必须和original graph相同。此外,指定依赖关系的顺序也必须匹配。最后,CUDA需要一致地排序sink节点(即没有依赖的节点或没有输出边的节点)。CUDA依赖API调用的顺序来实现一致的sink节点排序。
更明确的说,遵循以下规则将使得cudaGraphExecUpdate()可以确定性的将original graph中的节点与updating graph中的节点进行匹配:
- capture stream操作顺序的一致性。
- API调用顺序的一致性。
- sink节点的一致性。
下面是一个更新实例化graph的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
cudaGraphExec_t graphExec = NULL;
for (int i = 0; i < 10; i++) {
cudaGraph_t graph;
//cudaGraphExecUpdateResult是一个枚举类型,表示Graph Update的错误类型
cudaGraphExecUpdateResult updateResult;
//cudaGraphNode_t用于表示graph中的一个节点
cudaGraphNode_t errorNode;
// In this example we use stream capture to create the graph.
// You can also use the Graph API to produce a graph.
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal); //开始stream捕获
// Call a user-defined, stream based workload, for example
do_cuda_work(stream); //一个自定义的函数,用于在stream上执行一些CUDA操作
//结束stream的捕获,并将捕获的stream转换为一个graph
cudaStreamEndCapture(stream, &graph);
// If we've already instantiated the graph, try to update it directly
// and avoid the instantiation overhead
if (graphExec != NULL) {
// If the graph fails to update, errorNode will be set to the
// node causing the failure and updateResult will be set to a
// reason code.
//如果graphExec已经实例化过,则调用cudaGraphExecUpdate将graphExec更新为graph
//errorNode指向更新失败的节点
//updateResult指向更新失败的原因
cudaGraphExecUpdate(graphExec, graph, &errorNode, &updateResult);
}
// Instantiate during the first iteration or whenever the update
// fails for any reason
//如果graphExec未实例化,或graph更新失败
if (graphExec == NULL || updateResult != cudaGraphExecUpdateSuccess) {
// If a previous update failed, destroy the cudaGraphExec_t
// before re-instantiating it
if (graphExec != NULL) {
//如果是更新失败,则销毁之前的graphExec,为重新实例化做准备
cudaGraphExecDestroy(graphExec);
}
// Instantiate graphExec from graph. The error node and
// error message parameters are unused here.
//基于当前的graph实例化graphExec
cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0);
}
cudaGraphDestroy(graph); //销毁当前的graph并释放相应的资源
cudaGraphLaunch(graphExec, stream); //在stream中启动graphExec
cudaStreamSynchronize(stream); //等待stream中所有操作完成,以确保graph的执行完毕
}
也可以直接更新cudaGraph_t的节点(即使用cudaGraphKernelNodeSetParams()),然后更新cudaGraphExec_t,不过,使用下一部分介绍的显式节点更新的API更高效。
条件句柄标志和默认值会作为graph更新的一部分进行更新。在CUDA graph中,条件句柄是用于条件节点的控制结构,它可以根据特定条件来决定graph的执行路径。默认值是条件句柄在没有明确设定的情况下使用的值,通常用于决定在特定条件未满足时应执行的路径。
8.5.3.Individual Node Update
实例化graph的节点参数可以直接更新。这消除了重新实例化以及创建新cudaGraph_t的开销。如果需要更新的节点数量相对于graph中节点总数较少,最好单独更新节点。以下方法可用于更新cudaGraphExec_t节点:
cudaGraphExecKernelNodeSetParams()cudaGraphExecMemcpyNodeSetParams()cudaGraphExecMemsetNodeSetParams()cudaGraphExecHostNodeSetParams()cudaGraphExecChildGraphNodeSetParams()cudaGraphExecEventRecordNodeSetEvent()cudaGraphExecEventWaitNodeSetEvent()cudaGraphExecExternalSemaphoresSignalNodeSetParams()cudaGraphExecExternalSemaphoresWaitNodeSetParams()
8.5.4.Individual Node Enable
在已实例化的graph中,kernel、memset和memcpy节点可以使用cudaGraphNodeSetEnabled()来启用或禁用。节点的启用状态可以通过cudaGraphNodeGetEnabled()查询。
被禁用的节点在功能上等同于一个空节点,直到它被重新启用。启用或禁用节点不会影响其参数。单独节点更新或使用cudaGraphExecUpdate()进行的whole graph update不会影响节点的启用状态。在节点被禁用期间进行的参数更新将在节点重新启用时生效。
以下方法可用于启用/禁用cudaGraphExec_t节点,以及查询它们的状态:
cudaGraphNodeSetEnabled()cudaGraphNodeGetEnabled()
8.6.Using Graph APIs
cudaGraph_t对象不是线程安全的。用户有责任确保多个线程不并发访问同一个cudaGraph_t。
一个cudaGraphExec_t不能与自身并发运行。如果同一个cudaGraphExec_t被启动多次,其运行是按顺序依次进行的,而不是同时进行的。
graph的执行是在stream中进行的。但stream不会影响到graph内部节点的并行性,也不会对graph节点的执行位置产生影响。
8.7.Device Graph Launch
许多工作流在运行时需要根据数据做出决策,并根据这些决策执行不同的操作。与其将这些决策过程交给host处理(这可能需要device和host之间的往返通信),用户更倾向于在device端直接执行。为此,CUDA提供了一种从device端启动graph的方法。这项功能仅适用于支持统一寻址(unified addressing)的系统。
可以从device端启动的graph称为device graph,不能从device端启动的graph称为host graph。
device graph既可以从device端启动,也可以从host端启动;而host graph只能从host端启动。和host端启动graph不同,如果从device端启动graph时,之前同一个device graph的启动正在运行,则会返回cudaErrorInvalidValue错误。因此,同一个device graph不能同时在device端被启动两次。如果同时从device端和host端启动同一个device graph,则会导致未定义的行为。
8.7.1.Device Graph Creation
device graph需要被显式地实例化,才能从device端启动。这通过向cudaGraphInstantiate()传递cudaGraphInstantiateFlagDeviceLaunch标志来实现。与host graph相同,device graph的结构在实例化时固定,不能在不重新实例化的情况下更新,并且实例化只能在host端进行。为了使device graph能够成功实例化,必须满足以下一些要求。
8.7.1.1.Device Graph Requirements
一般要求:
- graph中的所有节点必须在同一个device上运行。
- graph只能包含以下类型的节点:kernel节点、memcpy节点、memset节点、child graph节点。
kernel节点:
- graph中的kernel不能使用CUDA的动态并行。
- 如果未使用MPS(多进程服务),则允许协作启动(cooperative launches)。
memcpy节点:
- 仅支持涉及device内存和页锁定host内存的拷贝。
- 不支持涉及CUDA array的拷贝。
- 在实例化时,操作数必须能够从当前device访问。需要注意的是,即使目标内存在其他device上,拷贝操作也会从graph所在的device执行。
8.7.1.2.Device Graph Upload
为了在device端启动graph,必须先将graph上传到device。可以通过以下两种方式完成。
第一种方式,可以显式的上传graph,通过调用cudaGraphUpload()或在实例化时通过cudaGraphInstantiateWithParams()请求上传。
第二种方式,可以从host端首次启动graph,在启动过程中会隐式的执行上传。
以下是这几种方法的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
// Explicit upload after instantiation
cudaGraphInstantiate(&deviceGraphExec1, deviceGraph1, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(deviceGraphExec1, stream);
// Explicit upload as part of instantiation
cudaGraphInstantiateParams instantiateParams = {0};
instantiateParams.flags = cudaGraphInstantiateFlagDeviceLaunch | cudaGraphInstantiateFlagUpload;
instantiateParams.uploadStream = stream;
cudaGraphInstantiateWithParams(&deviceGraphExec2, deviceGraph2, &instantiateParams);
// Implicit upload via host launch
cudaGraphInstantiate(&deviceGraphExec3, deviceGraph3, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphLaunch(deviceGraphExec3, stream);
8.7.1.3.Device Graph Update
device graph只能从host端更新,并且在可执行graph更新后,必须重新上传到device,以使更改生效。与host graph不同,如果从device端启动device graph时,graph正在更新,将导致未定义的行为。
8.7.2.Device Launch
device graph可以通过cudaGraphLaunch()从host端或device端启动。
device端的graph启动是基于每个线程的,且可能同时从不同线程发起多个启动。因此,用户需要确保为每个graph选择一个单独的线程以进行启动。
8.7.2.1.Device Launch Modes
与从host端启动不同,device graph不能被启动到普通的CUDA stream中,而只能被启动到特定的stream中,每个特定的stream对应一种特定的启动模式。

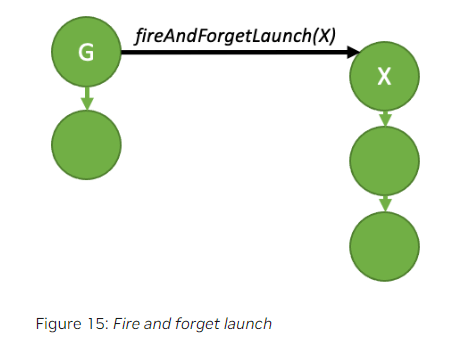
8.7.2.1.1.Fire and Forget Launch
顾名思义,”Fire and Forget Launch”的含义是:graph一旦被提交给GPU后,它会立即运行,并且与发起启动的graph独立运行。这种情况下,发起启动的graph是parent,而被启动的graph是child。
上述示意图对应的示例代码见下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
__global__ void launchFireAndForgetGraph(cudaGraphExec_t graph) {
cudaGraphLaunch(graph, cudaStreamGraphFireAndForget);
}
void graphSetup() {
cudaGraphExec_t gExec1, gExec2;
cudaGraph_t g1, g2;
// Create, instantiate, and upload the device graph.
create_graph(&g2);
cudaGraphInstantiate(&gExec2, g2, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(gExec2, stream);
// Create and instantiate the launching graph.
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
//第一个1表示grid中block的数量
//第二个1表示block中线程的数量
//第三个0表示每个block所需的动态分配的共享内存大小(单位:字节),这里表示没有动态分配额外的共享内存
launchFireAndForgetGraph<<<1, 1, 0, stream>>>(gExec2);
cudaStreamEndCapture(stream, &g1);
cudaGraphInstantiate(&gExec1, g1);
// Launch the host graph, which will in turn launch the device graph.
cudaGraphLaunch(gExec1, stream);
}
parent graph和child graph无依赖关系,即使parent graph结束运行,child graph仍然会继续执行。一个graph的执行过程中最多可以触发120个独立运行的child graph。这个数量会在每次parent graph重新启动时重置。
8.7.2.1.2.Graph Execution Environments
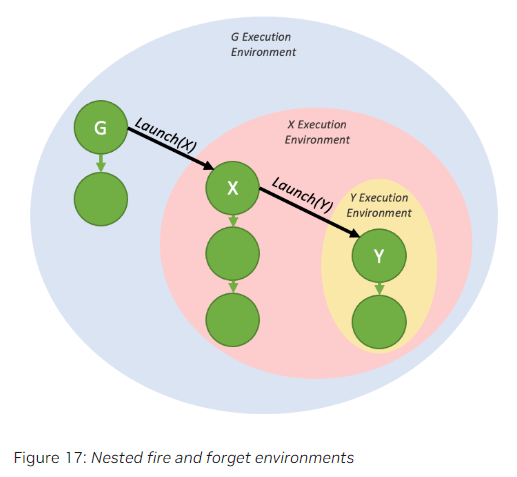
为了全面理解device端的同步模型,首先有必要了解执行环境的概念。
当一个graph从device端启动时,它会被加载到自己的执行环境中。其执行环境封装了该graph的所有工作以及通过”Fire and Forget”产生的子任务。graph在其自身完成且子任务也完成时,才被认为是“完成”的。
下面的图是上一部分中fire-and-forget示例代码所生成的执行环境封装。

如下图所示,一个graph的执行环境可以包含多个由fire-and-forget产生的具有层级结构的子执行环境。
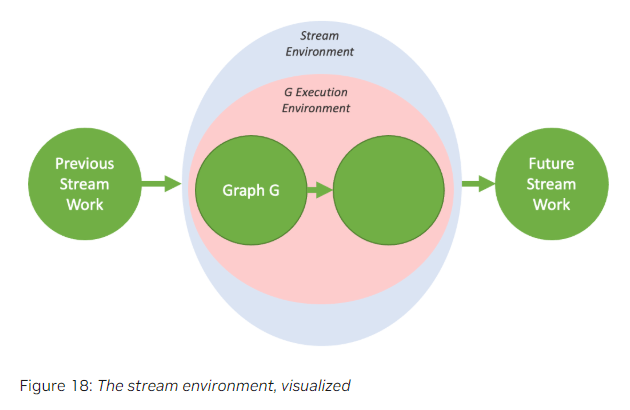
当一个graph从host端启动时,会存在一个stream环境,其将作为被启动graph的执行环境的上层封装。stream环境封装了启动过程中的所有工作。只有当stream环境整个被标记为完成时,stream启动才被认为完成(即下游依赖的工作现在可以运行了)。
8.7.2.1.3.Tail Launch
与host端不同,无法通过传统方式(比如cudaDeviceSynchronize()或cudaStreamSynchronize())与来自GPU的device graph进行同步。相反,为了实现串行工作依赖关系,引入了一种不同的启动模式:tail launch,以提供类似的功能。
当一个graph及其child graph都完成时,会执行tail launch。此时,tail launch列表中下一个graph的环境将替换完成的环境。

上图的代码示例见下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
__global__ void launchTailGraph(cudaGraphExec_t graph) {
cudaGraphLaunch(graph, cudaStreamGraphTailLaunch);
}
void graphSetup() {
cudaGraphExec_t gExec1, gExec2;
cudaGraph_t g1, g2;
// Create, instantiate, and upload the device graph.
create_graph(&g2);
cudaGraphInstantiate(&gExec2, g2, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(gExec2, stream);
// Create and instantiate the launching graph.
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
launchTailGraph<<<1, 1, 0, stream>>>(gExec2);
cudaStreamEndCapture(stream, &g1);
cudaGraphInstantiate(&gExec1, g1);
// Launch the host graph, which will in turn launch the device graph.
cudaGraphLaunch(gExec1, stream);
}
tail launch会按照graph加入队列的顺序逐个执行:
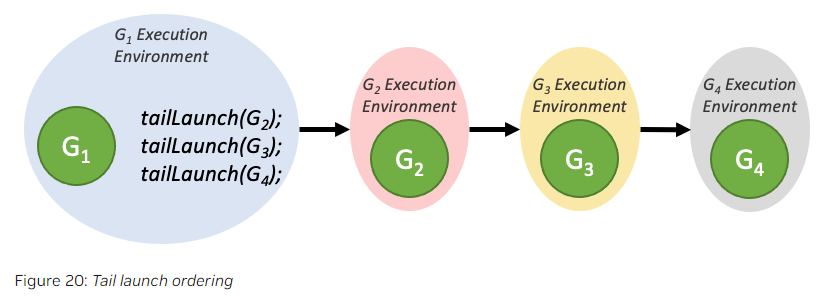
在一个tail launch队列中,如果某个graph(也称为tail graph)在执行时又生成了新的tail launch,这些新的tail launch会优先于队列中之前的graph的tail launch执行。
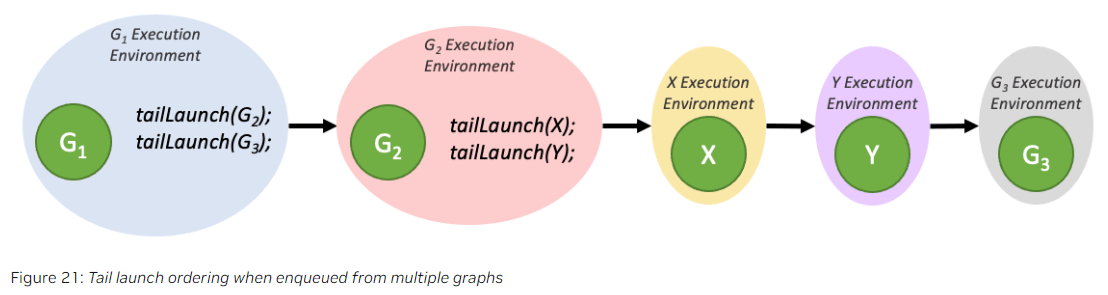
一个graph最多可以有255个pending的tail launch。
8.7.2.1.3.1.Tail Self-launch
device graph可以为自身排队一个tail launch,但一个graph在任意时刻只能排队一个self-launch。为了查询当前正在运行的device graph,以便可以重新启动它,添加了一个新的device端函数:
1
cudaGraphExec_t cudaGetCurrentGraphExec();
此函数返回正在运行的device graph的句柄。如果当前执行的kernel不是device graph中的一个节点,则此函数将返回NULL。
下面是一个使用此函数进行重新启动循环的示例代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
__device__ int relaunchCount = 0;
__global__ void relaunchSelf() {
int relaunchMax = 100;
if (threadIdx.x == 0) {
if (relaunchCount < relaunchMax) {
cudaGraphLaunch(cudaGetCurrentGraphExec(), cudaStreamGraphTailLaunch);
}
relaunchCount++;
}
}
8.7.2.1.4.Sibling Launch
sibling launch是fire-and-forget launch的一种变体,在Fig16的fire-and-forget launch示意图中,X的执行环境是G执行环境的child,而在Fig22的sibling launch示意图中,X执行环境和G执行环境是相互独立的。

上图对应的代码示例见下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
__global__ void launchSiblingGraph(cudaGraphExec_t graph) {
cudaGraphLaunch(graph, cudaStreamGraphFireAndForgetAsSibling);
}
void graphSetup() {
cudaGraphExec_t gExec1, gExec2;
cudaGraph_t g1, g2;
// Create, instantiate, and upload the device graph.
create_graph(&g2);
cudaGraphInstantiate(&gExec2, g2, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(gExec2, stream);
// Create and instantiate the launching graph.
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
launchSiblingGraph<<<1, 1, 0, stream>>>(gExec2);
cudaStreamEndCapture(stream, &g1);
cudaGraphInstantiate(&gExec1, g1);
// Launch the host graph, which will in turn launch the device graph.
cudaGraphLaunch(gExec1, stream);
}
由于sibling launch并不是launching graph执行环境的一部分,因此它们不会阻碍launching graph的tail launch队列的执行。
8.8.Conditional Graph Nodes
条件节点允许graph中包含条件执行和循环操作。条件节点的判断是在device端进行的。条件节点可以是以下两种类型之一:
- IF节点。
- WHILE节点。
条件值可以通过条件句柄访问,句柄需要在创建节点之前生成。可以通过cudaGraphSetConditional()设置条件值。还可以在句柄创建时指定每次graph启动时的默认值。
在创建条件节点时,会生成一个空的graph,并将句柄返回给用户以便填充graph。这个空的graph可以用graph API(见第8.2部分)或cudaStreamBeginCaptureToGraph()(见第8.3部分)来填充。
条件节点支持嵌套。
8.8.1.Conditional Handles
条件值使用cudaGraphConditionalHandle表示,并通过cudaGraphConditionalHandleCreate()创建。
句柄必须与单个条件节点关联。句柄无法销毁。
如果在句柄创建时指定了cudaGraphCondAssignDefault标志,条件值将在每次graph启动前被初始化为指定的默认值。如果未提供该标志,则由用户负责在条件节点上游的kernel函数中初始化条件值。如果条件值未通过这些方法之一初始化,其值将是未定义的。
句柄关联的默认值和标志会在whole graph update(见第8.5.2部分)过程中被更新。
8.8.2.Condtional Node Body Graph Requirements
本部分介绍条件节点所执行的body graph的一些要求。
一般要求:
- graph中的节点必须位于同一device上。
- graph只能包含以下类型的节点:kernel节点、空节点、memcpy节点、memset节点、child graph节点和条件节点。
对于kernel节点以及memcpy节点、memset节点的要求同第8.7.1.1部分。
8.8.3.Conditional IF Nodes
如果IF节点的条件值为非零值,则body graph将被执行一次。下图是一个包含3个节点的graph,其中节点B是一个条件节点。
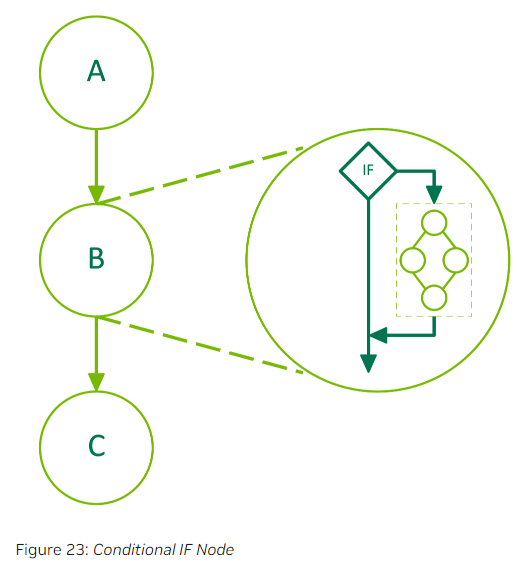
下面的示例代码是一个包含IF节点的graph的创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
__global__ void setHandle(cudaGraphConditionalHandle handle)
{
...
cudaGraphSetConditional(handle, value);
...
}
void graphSetup() {
cudaGraph_t graph;
cudaGraphExec_t graphExec;
cudaGraphNode_t node;
void *kernelArgs[1];
int value = 1;
cudaGraphCreate(&graph, 0);
cudaGraphConditionalHandle handle;
cudaGraphConditionalHandleCreate(&handle, graph);
// Use a kernel upstream of the conditional to set the handle value
//cudaGraphNodeParams是一个结构体,用于配置节点参数
//cudaGraphNodeTypeKernel属于cudaGraphNodeType
//cudaGraphNodeType是一个枚举类型,用于表示节点的类型
//cudaGraphNodeTypeKernel表示GPU kernel节点
cudaGraphNodeParams params = { cudaGraphNodeTypeKernel };
//params.kernel配置kernel节点的参数
params.kernel.func = (void *)setHandle;
params.kernel.gridDim.x = params.kernel.gridDim.y = params.kernel.gridDim.z = 1;
params.kernel.blockDim.x = params.kernel.blockDim.y = params.kernel.blockDim.z = 1;
params.kernel.kernelParams = kernelArgs;
kernelArgs[0] = &handle;
cudaGraphAddNode(&node, graph, NULL, 0, ¶ms);
//cudaGraphNodeTypeConditional属于枚举类型cudaGraphNodeType,表示一个条件节点
cudaGraphNodeParams cParams = { cudaGraphNodeTypeConditional };
cParams.conditional.handle = handle;
cParams.conditional.type = cudaGraphCondTypeIf; //IF条件节点
cParams.conditional.size = 1;
cudaGraphAddNode(&node, graph, &node, 1, &cParams);
cudaGraph_t bodyGraph = cParams.conditional.phGraph_out[0]; //获取body graph
// Populate the body of the conditional node
...
cudaGraphAddNode(&node, bodyGraph, NULL, 0, ¶ms); //向body graph中添加节点
cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0);
cudaGraphLaunch(graphExec, 0);
cudaDeviceSynchronize();
cudaGraphExecDestroy(graphExec);
cudaGraphDestroy(graph);
}
cudaGraphAddNode用于向graph中添加任意类型的节点:
1
2
3
4
5
6
7
8
9
10
//参数详解:
//pGraphNode:返回新创建的节点
//graph:用于添加节点的graph
//pDependencies:节点的依赖
//numDependencies:依赖的个数
//nodeParams:节点参数
__host__cudaError_t cudaGraphAddNode
(cudaGraphNode_t *pGraphNode, cudaGraph_t graph,
const cudaGraphNode_t *pDependencies, size_t
numDependencies, cudaGraphNodeParams *nodeParams)
8.8.4.Conditional WHILE Nodes
WHILE节点的body graph在条件值为非零时重复执行。条件将在节点执行以及body graph执行完成后进行评估。下面是一个包含了3个节点的graph,其中节点B是一个条件节点。
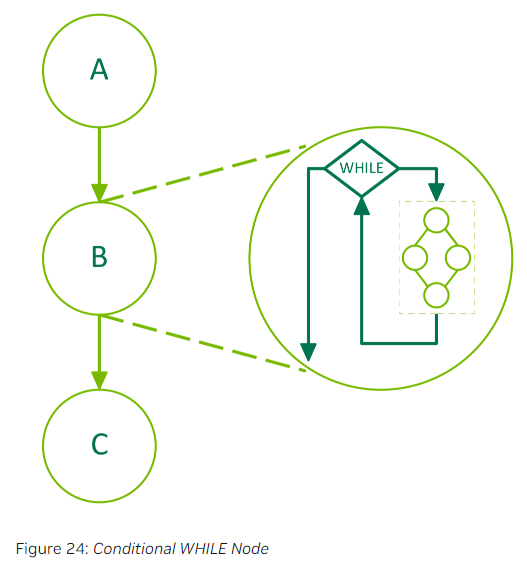
以下是代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
__global__ void loopKernel(cudaGraphConditionalHandle handle)
{
static int count = 10;
cudaGraphSetConditional(handle, --count ? 1 : 0);
}
void graphSetup() {
cudaGraph_t graph;
cudaGraphExec_t graphExec;
cudaGraphNode_t node;
void *kernelArgs[1];
cudaGraphCreate(&graph, 0);
cudaGraphConditionalHandle handle;
//创建条件句柄
//__host__cudaError_t cudaGraphConditionalHandleCreate
//(cudaGraphConditionalHandle *pHandle_out, cudaGraph_t
//graph, unsigned int defaultLaunchValue, unsigned int flags)
//参数解释:
//pHandle_out:返回条件句柄的指针
//graph:目标graph
//defaultLaunchValue:条件值的默认值
//flags:目前只支持设置为cudaGraphCondAssignDefault或0,设置为cudaGraphCondAssignDefault表示使用defaultLaunchValue初始化条件值
cudaGraphConditionalHandleCreate(&handle, graph, 1, cudaGraphCondAssignDefault);
cudaGraphNodeParams cParams = { cudaGraphNodeTypeConditional };
cParams.conditional.handle = handle;
cParams.conditional.type = cudaGraphCondTypeWhile; //WHILE节点
cParams.conditional.size = 1;
cudaGraphAddNode(&node, graph, NULL, 0, &cParams);
cudaGraph_t bodyGraph = cParams.conditional.phGraph_out[0];
cudaGraphNodeParams params = { cudaGraphNodeTypeKernel };
params.kernel.func = (void *)loopKernel;
params.kernel.gridDim.x = params.kernel.gridDim.y = params.kernel.gridDim.z = 1;
params.kernel.blockDim.x = params.kernel.blockDim.y = params.kernel.blockDim.z = 1;
params.kernel.kernelParams = kernelArgs;
kernelArgs[0] = &handle;
cudaGraphAddNode(&node, bodyGraph, NULL, 0, ¶ms);
cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0);
cudaGraphLaunch(graphExec, 0);
cudaDeviceSynchronize();
cudaGraphExecDestroy(graphExec);
cudaGraphDestroy(graph);
}
9.Events
运行时还提供了一种密切监控device进度以及执行精确计时的方法,具体来说,就是让应用程序异步记录程序中任何点的event,并且可以查询这些event何时完成。当event之前所有的任务(或给定stream中的所有命令)都已经完成时,event被标记为完成。默认stream中的event会在所有srteam中所有前置任务和命令都完成后,才会被标记为完成。
9.1.Creation and Destruction of Events
下面的代码示例创建了两个event:
1
2
3
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
销毁方式:
1
2
cudaEventDestroy(start);
cudaEventDestroy(stop);
9.2.Elapsed Time
通过在代码中创建和销毁event,可以测量GPU上某段代码的运行时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
cudaEventRecord(start, 0); //记录start event,但此时start并不一定被标记为完成状态,不会阻塞下面代码的执行
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>
(outputDev + i * size, inputDev + i * size, size);
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
cudaEventRecord(stop, 0);
//cudaEventSynchronize用于等待某个event结束
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
因为event的记录是异步的,所以在记录start event时,start并不一定是完成状态,同理,在记录stop event时也不能确保stop是完成状态。cudaEventSynchronize可以用来等待stop被标记为完成。cudaEventElapsedTime计算的是两个event完成时间的间隔,但在上述代码中,for循环可能在start被标记为完成之前就开始执行了,所以代码中的elapsedTime有可能并不能准确代表for循环的运行时间。
10.Synchronous Calls
在调用同步函数时,在device完成所请求的任务之前,控制权不会返回给host线程。可以通过调用cudaSetDeviceFlags()来指定host线程在等待device完成任务时的行为,比如可指定的标志有:
cudaDeviceScheduleYield:host线程将让出CPU使用权,允许其他线程或任务执行。这可能有助于提高系统的整体效率。cudaDeviceScheduleBlockingSync:host线程将被挂起,直到device完成任务为止。这种方式可能导致较高的延迟,但减少了CPU的开销。cudaDeviceScheduleSpin:host线程将不断轮询设备状态,直到任务完成。这种方式可能带来更低的延迟,但会消耗大量的CPU资源。
