【CUDA编程】系列博客参考NVIDIA官方文档“CUDA C++ Programming Guide(v12.6)”。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Texture and Surface Memory
CUDA支持GPU的一个纹理硬件子集,用于图形访问纹理内存(texture memory)和表面内存(surface memory)。相比于全局内存(global memory),从纹理内存或表面内存中读取数据可以带来更多性能优势。
这里简单解释下纹理和纹理硬件。
纹理通常是指二维或三维的图像数据,通常被映射到3D模型的表面,以提高图形渲染的真实感。
纹理硬件是现代GPU中用于高效处理和访问图形数据的专用硬件单元。这种硬件最初设计是为3D图形渲染服务,但在CUDA编程中被重新利用,用于优化数据访问和处理。
2.Texture Memory
CUDA中,纹理内存是通过特定的函数进行访问的,这些函数被称为纹理函数(texture function)。调用纹理函数读取纹理的过程称为纹理读取(texture fetch)。每次纹理读取都会指定一个称为纹理对象(texture object)的参数,用于纹理对象API。
纹理对象指定了:
- 纹理是从纹理内存中获取的一部分数据,可以是图像、矩阵或多维数组。在运行时创建纹理对象,并在创建纹理对象时指定具体的纹理。
- 对于纹理的维度,一维纹理(一个纹理坐标)作为一维数组访问,二维纹理(两个纹理坐标)作为二维数组访问,三维纹理(三个纹理坐标)作为三维数组访问。数组中的元素称为texels(即纹理元素texture elements的缩写)。纹理的width、height和depth分别表示数组在每个维度上的大小。表21列出了在不同算力的device中,支持的纹理的最大width、height和depth。
- texels的类型必须是基本的整型或单精度浮点型,或者是由这些基本类型派生的向量类型。
- 读取模式(read mode)可以是
cudaReadModeNormalizedFloat或cudaReadModeElementType。如果读取模式是cudaReadModeNormalizedFloat,且texels为16位或8位整型,则纹理读取返回的值实际上是一个浮点类型,对于无符号整型,整数值的完整范围会被映射到$[0.0,1.0]$;对于有符号整型,整数值的完整范围会被映射到$[-1.0,1.0]$,比如一个无符号8位整型值0xff(即255),会读取为浮点值1.0。如果读取模式是cudaReadModeElementType,则不会执行任何类型转换,直接返回原始数据类型的值。 - 默认情况下,纹理坐标是浮点类型,坐标范围为$[0,N-1]$,其中,$N$是该坐标对应维度的大小。比如,一个大小为$64 \times 32$的纹理,$x,y$维度上的坐标范围分别为$[0,63]$和$[0,31]$。归一化的纹理坐标将坐标范围从$[0,N-1]$转变为$[0.0,1.0-1/N]$。
- 对于某些device函数,传入超出范围的坐标是合法的。寻址模式(addressing mode)定义了在这种情况下的处理方式。默认的寻址模式(即clamp mode)是将坐标限制在有效范围内:对于非归一化坐标,范围为$[0,N)$;对于归一化坐标,范围为$[0.0,1.0)$。如果指定了border mode,则对于超出范围的纹理坐标,纹理读取将返回零。对于归一化坐标,还可以使用wrap mode和mirror mode。当使用wrap mode时,每个x坐标会被转换为
frac(x)=x-floor(x),其中floor(x)是不大于x的最大整数。当使用mirror mode时,如果floor(x)是偶数,则每个x坐标转换为frac(x);如果是奇数,则转换为1-frac(x)。寻址模式通过一个大小为3的数组指定,其中第一个、第二个和第三个元素分别定义第一个、第二个和第三个纹理坐标的寻址模式。寻址模式包括cudaAddressModeBorder、cudaAddressModeClamp、cudaAddressModeWrap和cudaAddressModeMirror,其中,cudaAddressModeWrap和cudaAddressModeMirror仅支持归一化纹理坐标。 - 过滤模式(filtering mode)指定了根据输入纹理坐标计算纹理读取返回值的方式。线性纹理过滤仅适用于返回值为浮点类型的纹理。其在相邻texels之间执行低精度插值(因为输入坐标可能不会刚好落在texels上)。对于一维纹理执行简单的线性插值,对于二维纹理执行双线性插值,对于三维纹理执行三线性插值。过滤模式可以是
cudaFilterModePoint或cudaFilterModeLinear。如果选择cudaFilterModePoint,则返回值为最接近输入纹理坐标的texels的值。如果选择cudaFilterModeLinear,对于一维纹理,返回值是与输入纹理坐标最接近的两个texels的线性插值;对于二维纹理,返回值是与输入纹理坐标最接近的四个texels的线性插值;对于三维纹理,返回值是与输入纹理坐标最接近的八个texels的线性插值。cudaFilterModeLinear仅适用于返回浮点类型值的情况。
第2.1部分介绍了纹理对象API。
第2.2部分介绍了如何处理16位浮点类型的纹理。
第2.3部分介绍了纹理的分层。
第2.4部分和第2.5部分介绍了一种特殊类型的纹理:cubemap纹理。
第2.6部分介绍了一种特殊的纹理读取操作:纹理收集(texture gather)。
2.1.Texture Object API
使用cudaCreateTextureObject()创建纹理对象:
1
2
3
4
5
6
__host__cudaError_t cudaCreateTextureObject (
cudaTextureObject_t *pTexObject, //Texture object to create
const cudaResourceDesc *pResDesc, //Resource descriptor
const cudaTextureDesc *pTexDesc, //Texture descriptor
const cudaResourceViewDesc *pResViewDesc //Resource view descriptor
)
其中cudaTextureDesc的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
struct cudaTextureDesc
{
enum cudaTextureAddressMode addressMode[3]; //Texture address mode for up to 3 dimensions
enum cudaTextureFilterMode filterMode; //Texture filter mode
enum cudaTextureReadMode readMode; //Texture read mode
int sRGB; //Perform sRGB->linear conversion during texture read
int normalizedCoords; //Indicates whether texture reads are normalized or not
unsigned int maxAnisotropy; //Limit to the anisotropy ratio
enum cudaTextureFilterMode mipmapFilterMode; //Mipmap filter mode
float mipmapLevelBias; //Offset applied to the supplied mipmap level
float minMipmapLevelClamp; //Lower end of the mipmap level range to clamp access to
float maxMipmapLevelClamp; //Upper end of the mipmap level range to clamp access to
};
下面这段代码定义了一个CUDA kernel函数,其作用是对纹理数据进行旋转变换,并将结果写入全局内存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// Simple transformation kernel
__global__ void transformKernel(float* output,
cudaTextureObject_t texObj,
int width, int height,
float theta)
{
// Calculate normalized texture coordinates
//每个线程负责计算一个像素点对应的旋转坐标
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
//将坐标从[0,width-1]、[0,height-1]归一化到[0.0,1.0]
float u = x / (float)width;
float v = y / (float)height;
// Transform coordinates
//执行二维坐标的旋转变换
u -= 0.5f;
v -= 0.5f;
float tu = u * cosf(theta) - v * sinf(theta) + 0.5f;
float tv = v * cosf(theta) + u * sinf(theta) + 0.5f;
// Read from texture and write to global memory
//使用tex2D<float>从texObj中读取位置(tu,tv)的值,并写入output的相应位置
output[y * width + x] = tex2D<float>(texObj, tu, tv);
}
下面是对应的host端的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
// Host code
int main()
{
const int height = 1024;
const int width = 1024;
float angle = 0.5;
// Allocate and set some host data
float *h_data = (float *)std::malloc(sizeof(float) * width * height);
for (int i = 0; i < height * width; ++i)
h_data[i] = i;
// Allocate CUDA array in device memory
cudaChannelFormatDesc channelDesc =
cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat);
cudaArray_t cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
// Set pitch of the source (the width in memory in bytes of the 2D array pointed
// to by src, including padding), we dont have any padding
const size_t spitch = width * sizeof(float);
// Copy data located at address h_data in host memory to device memory
cudaMemcpy2DToArray(cuArray, 0, 0, h_data, spitch, width * sizeof(float),
height, cudaMemcpyHostToDevice);
// Specify texture
//设置资源描述符
struct cudaResourceDesc resDesc;
memset(&resDesc, 0, sizeof(resDesc));
resDesc.resType = cudaResourceTypeArray; //指定纹理资源的类型为array
resDesc.res.array.array = cuArray; //绑定到cuArray
// Specify texture object parameters
//设置纹理描述符
struct cudaTextureDesc texDesc;
memset(&texDesc, 0, sizeof(texDesc));
texDesc.addressMode[0] = cudaAddressModeWrap;
texDesc.addressMode[1] = cudaAddressModeWrap;
texDesc.filterMode = cudaFilterModeLinear;
texDesc.readMode = cudaReadModeElementType;
texDesc.normalizedCoords = 1;
// Create texture object
cudaTextureObject_t texObj = 0;
cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL);
// Allocate result of transformation in device memory
float *output;
cudaMalloc(&output, width * height * sizeof(float));
// Invoke kernel
dim3 threadsperBlock(16, 16);
dim3 numBlocks((width + threadsperBlock.x - 1) / threadsperBlock.x,
(height + threadsperBlock.y - 1) / threadsperBlock.y);
transformKernel<<<numBlocks, threadsperBlock>>>(output, texObj, width, height,
angle);
// Copy data from device back to host
cudaMemcpy(h_data, output, width * height * sizeof(float),
cudaMemcpyDeviceToHost);
// Destroy texture object
cudaDestroyTextureObject(texObj);
// Free device memory
cudaFreeArray(cuArray);
cudaFree(output);
// Free host memory
free(h_data);
return 0;
}
先解释下分配CUDA array时用到的两个API。cudaChannelFormatDesc用于指定CUDA通道格式:
1
2
3
4
struct cudaChannelFormatDesc {
int x, y, z, w; //分别表示这4个通道所占的位数
enum cudaChannelFormatKind f; //数据格式
};
举几个例子方便理解,cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat)只有一个通道有值,并且是32位的浮点数;cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsigned)中4个通道都有值,并且是8位无符号数。
cudaMallocArray用于在device上分配一个array:
1
2
3
4
5
6
7
__host__cudaError_t cudaMallocArray (
cudaArray_t *array, //Pointer to allocated array in device memory
const cudaChannelFormatDesc *desc, //Requested channel format
size_t width, //Requested array allocation width
size_t height, //Requested array allocation height
unsigned int flags //Requested properties of allocated array
)
其中,desc指定了array中每个元素的通道数和数据格式,width和height指定了array的大小。
cudaMemcpy2DToArray用于在host和device之间拷贝array:
1
2
3
4
5
6
7
8
9
10
__host__cudaError_t cudaMemcpy2DToArray (
cudaArray_t dst, //Destination memory address
size_t wOffset, //Destination starting X offset (columns in bytes)
size_t hOffset, //Destination starting Y offset (rows)
const void *src, //Source memory address
size_t spitch, //Pitch of source memory
size_t width, //Width of matrix transfer (columns in bytes)
size_t height, //Height of matrix transfer (rows)
cudaMemcpyKind kind //Type of transfer
)
对pitch的解释可参见:Device Memory。
2.2.16-Bit Floating-Point Textures
CUDA array支持的16位浮点数格式(或称半精度格式),与IEEE 754-2008 binary2格式相同。
CUDA C++不支持对应的16位浮点数数据类型,但提供了内置函数,可以通过__float2half_rn(float)将32位浮点数转换为16位浮点数,通过__half2float(unsigned short)将16位浮点数(以unsigned short存储)转换为32位浮点数。这些函数仅支持在device代码中使用。host代码可以通过OpenEXR库找到等效的函数。
在纹理读取时,16位浮点数分量会在进行任何过滤操作之前提升为32位浮点数。
可以通过调用cudaCreateChannelDescHalf*()来创建16位浮点格式的通道描述符。
2.3.Layered Textures
一维或二维的分层纹理(在Direct3D中称为纹理数组,在OpenGL中称为数组纹理)是由一系列层组成的纹理,每一层都是具有相同维度、大小和数据类型的常规纹理。
一维分层纹理通过一个整数索引和一个浮点纹理坐标进行访问,整数索引用于标识序列中的某一层,而浮点坐标用于访问该层中的某个texel。二维分层纹理通过一个整数索引和两个浮点纹理坐标进行访问,整数索引用于标识序列中的某一层,两个浮点坐标用于访问该层中的某个texel。
分层纹理只能通过调用cudaMalloc3DArray()并使用cudaArrayLayered标志来创建CUDA array(对于一维分层纹理,height必须为0)。
分层纹理的读取使用device函数tex1DLayered()和tex2DLayered()。纹理过滤仅在单个层内进行,而不会跨层进行。
分层纹理仅支持算力在2.0及以上的device。
2.4.Cubemap Textures
cubemap纹理是一种特殊类型的二维分层纹理,它有6层,分别代表立方体的6个面:
- 每层的width和height是相等的。
- cubemap使用3个纹理坐标$x,y,z$进行寻址,这三个坐标表示从立方体中心发出的方向向量,指向立方体某个面上的某个texel。我们设$m = \max (\lvert x \rvert, \lvert y \rvert, \lvert z \rvert)$,我们通过$m$来确定访问哪个面,使用$(s/m + 1) / 2$和$(t/m + 1) / 2$作为二维坐标来访问这个面上的texel。详细见表3。
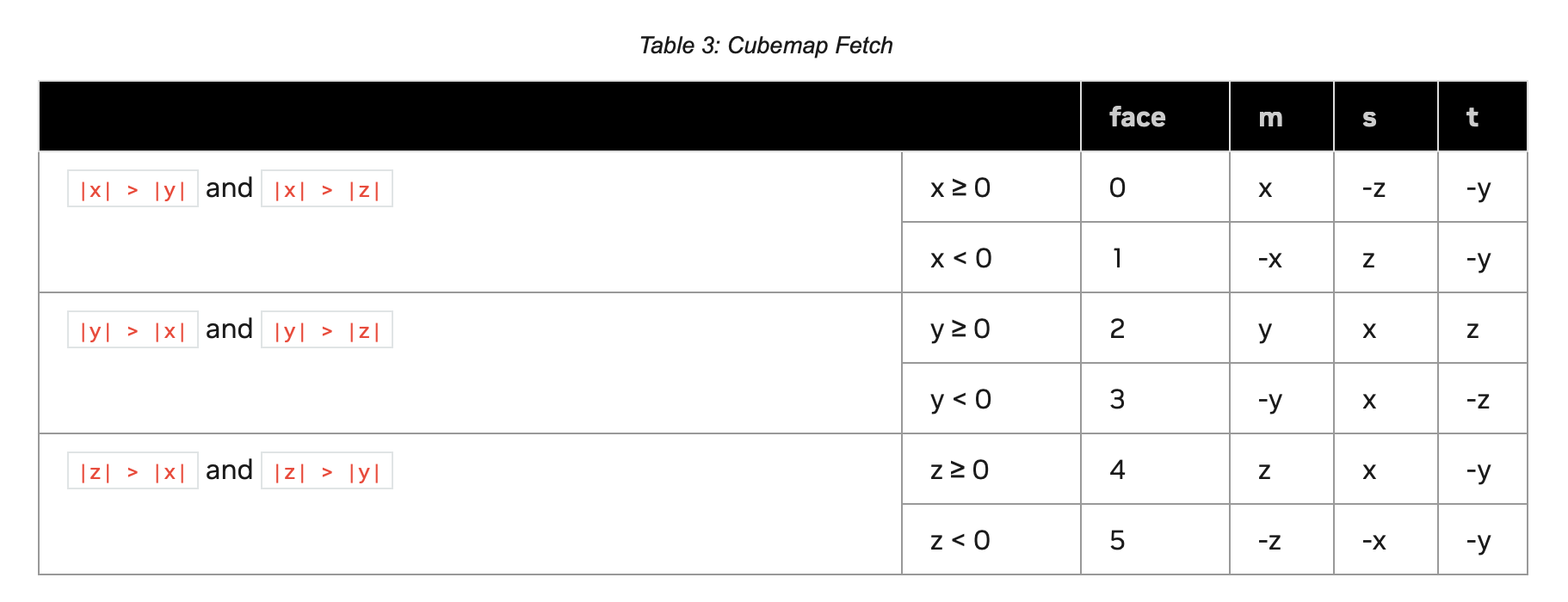
cubemap纹理只能是调用cudaMalloc3DArray()且使用cudaArrayCubemap标志的CUDA array。
cubemap纹理的读取使用device函数texCubemap()。
cubemap纹理仅支持算力在2.0及以上的device。
2.5.Cubemap Layered Textures
cubemap分层纹理是一种分层纹理,其每一层都是相同维度的cubemap。
cubemap分层纹理通过一个整数索引和三个浮点纹理坐标进行访问,整数索引用于标识序列中的某个cubemap,三个浮点纹理坐标用于指定这个cubemap中某个texel的位置。
cubemap分层纹理只能是调用cudaMalloc3DArray()并使用cudaArrayLayered和cudaArrayCubemap标志的CUDA array。
cubemap分层纹理的读取使用device函数texCubemapLayered()。纹理过滤仅在单个层内进行,不会跨层进行。
cubemap分层纹理仅支持算力在2.0及以上的device。
2.6.Texture Gather
纹理收集是一种特殊的纹理读取操作,仅适用于二维纹理。调用tex2Dgather()使用纹理收集,该函数的参数和tex2D()相同,但需额外添加一个comp参数,该参数的值为0、1、2或3,comp用于指定要提取的纹理分量,即texel的哪个通道。我们在第2部分提到过,对于二维纹理,过滤模式如果选择cudaFilterModeLinear,则纹理读取的返回值是与输入纹理坐标最接近的四个texels的线性插值,而纹理收集tex2Dgather()的返回值则是4个32位的数值,分别是这四个最接近的texel的值。比如,如果这4个texel的值为$(253, 20, 31, 255), (250, 25, 29, 254), (249, 16, 37, 253), (251, 22, 30, 250)$,且comp为2,则tex2Dgather()的返回值为$(31, 29, 37, 30)$。
需要注意的是,纹理坐标的计算仅使用8位小数精度,即分辨率为$\frac{1}{256}$。因此,当tex2D()将其中一个权重($\alpha$或$\beta$,线性过滤中用到的权重)设为1.0时,tex2Dgather()可能返回与其不同的结果。
在纹理提取中,对于二维纹理,如果使用线性过滤(必须是浮点数),则返回值为:
\[tex (x,y) = (1-\alpha)(1-\beta) T [i,j] + \alpha(1-\beta)T[i+1,j] + (1-\alpha)\beta T[i,j+1] + \alpha \beta T[i+1,j+1]\]假设先只考虑$x$坐标($y$坐标是一样的情况),有$x = 2.49805$,按照纹理提取的计算,先计算$x_B = x - 0.5 = 1.99805$,那么就有$i = floor (x_B) = 1$。但是在纹理收集中,$x_B$的小数部分被存储为8位定点格式,由于小数部分$0.99805$更接近$256.f / 256.f$,而不是$255.f / 256.f$,因此$x_B$的小数部分被视为1,加上原有整数部分的1,最终$x_B$的值为2(即有$i=2$),和纹理提取计算的结果不同。
纹理收集仅支持通过设置cudaArrayTextureGather标志创建的CUDA array,并且array的width和height必须小于表21中为纹理收集指定的最大值,这个最大值比常规纹理读取的最大值要小。
纹理收集仅支持算力在2.0及以上的device。
3.Surface Memory
对于算力在2.0及以上的device,使用cudaArraySurfaceLoadStore标志创建的CUDA array,可以通过表面对象(surface object)进行读写。
表21列出了在不同算力下,支持的最大表面width、最大表面height和最大表面depth。
表面内存和纹理内存的区别:
| 特性 | 纹理内存 | 表面内存 |
|---|---|---|
| 读写权限 | 只读 | 读写支持 |
| 插值支持 | 支持双线性、三线性插值 | 不支持 |
| 缓存优化 | 支持硬件优化缓存 | 无专用缓存优化 |
| 主要用途 | 图像采样、插值、随机读取优化 | 数据写入、结果存储、直接输出 |
3.1.Surface Object API
表面对象通过调用cudaCreateSurfaceObject()创建。与纹理内存(texture memory)通过纹理坐标访问不同,表面内存(surface memory)使用字节寻址。这意味着,如果通过纹理函数访问纹理元素时使用了$x$坐标,那么若要通过表面函数访问相同的元素时,$x$坐标需要乘以元素的字节大小。例如,一个绑定到纹理对象texObj和表面对象surfObj的一维浮点CUDA array中,位于纹理坐标$x$的元素,可以通过texObj调用tex1d(texObj, x)读取,但通过surfObj读取时,需要调用surf1Dread(surfObj, 4*x)(一个浮点数占用4个字节)。类似的,一个绑定到纹理对象texObj和表面对象surfObj的二维浮点CUDA array中,位于纹理坐标$(x,y)$的元素,可以通过texObj调用tex2d(texObj, x, y)访问,但通过surfObj访问时,需要调用surf2Dread(surfObj, 4*x, y)($y$坐标的字节偏移量由CUDA array的line pitch在内部计算得到)。
下面是使用表面对象实现二维数组拷贝的一个代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
// Simple copy kernel
__global__ void copyKernel(cudaSurfaceObject_t inputSurfObj,
cudaSurfaceObject_t outputSurfObj,
int width, int height)
{
// Calculate surface coordinates
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
uchar4 data;
// Read from input surface
surf2Dread(&data, inputSurfObj, x * 4, y);
// Write to output surface
surf2Dwrite(data, outputSurfObj, x * 4, y);
}
}
// Host code
int main()
{
const int height = 1024;
const int width = 1024;
// Allocate and set some host data
unsigned char *h_data =
(unsigned char *)std::malloc(sizeof(unsigned char) * width * height * 4);
for (int i = 0; i < height * width * 4; ++i)
h_data[i] = i;
// Allocate CUDA arrays in device memory
cudaChannelFormatDesc channelDesc =
cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsigned);
cudaArray_t cuInputArray;
cudaMallocArray(&cuInputArray, &channelDesc, width, height,
cudaArraySurfaceLoadStore);
cudaArray_t cuOutputArray;
cudaMallocArray(&cuOutputArray, &channelDesc, width, height,
cudaArraySurfaceLoadStore);
// Set pitch of the source (the width in memory in bytes of the 2D array
// pointed to by src, including padding), we dont have any padding
const size_t spitch = 4 * width * sizeof(unsigned char);
// Copy data located at address h_data in host memory to device memory
cudaMemcpy2DToArray(cuInputArray, 0, 0, h_data, spitch,
4 * width * sizeof(unsigned char), height,
cudaMemcpyHostToDevice);
// Specify surface
struct cudaResourceDesc resDesc;
memset(&resDesc, 0, sizeof(resDesc));
resDesc.resType = cudaResourceTypeArray;
// Create the surface objects
resDesc.res.array.array = cuInputArray;
cudaSurfaceObject_t inputSurfObj = 0;
cudaCreateSurfaceObject(&inputSurfObj, &resDesc);
resDesc.res.array.array = cuOutputArray;
cudaSurfaceObject_t outputSurfObj = 0;
cudaCreateSurfaceObject(&outputSurfObj, &resDesc);
// Invoke kernel
dim3 threadsperBlock(16, 16);
dim3 numBlocks((width + threadsperBlock.x - 1) / threadsperBlock.x,
(height + threadsperBlock.y - 1) / threadsperBlock.y);
copyKernel<<<numBlocks, threadsperBlock>>>(inputSurfObj, outputSurfObj, width,
height);
// Copy data from device back to host
cudaMemcpy2DFromArray(h_data, spitch, cuOutputArray, 0, 0,
4 * width * sizeof(unsigned char), height,
cudaMemcpyDeviceToHost);
// Destroy surface objects
cudaDestroySurfaceObject(inputSurfObj);
cudaDestroySurfaceObject(outputSurfObj);
// Free device memory
cudaFreeArray(cuInputArray);
cudaFreeArray(cuOutputArray);
// Free host memory
free(h_data);
return 0;
}
3.2.Cubemap Surfaces
cubemap表面作为一个二维分层表面,通过surfCubemapread()和surfCubemapwrite()访问,即通过一个整数索引来表示立方体的某个面,同时使用两个浮点纹理坐标来定位该面中的某个texel。面的次序可参照表3。
3.3.Cubemap Layered Surfaces
cubemap分层表面作为一个二维分层表面,通过surfCubemapLayeredread()和surfCubemapLayeredwrite()访问,即通过一个整数索引表示某个cubemap中的某个面,同时使用两个浮点纹理坐标来定位该面中的某个texel。面的次序可参照表3。例如索引$((2 * 6) + 3)$(索引计算公式:$(layer\_index * 6) + face\_index$)表示访问第三个cubemap的第四个面。
4.CUDA Arrays
CUDA array是一种特殊的内存结构,专门为高效处理纹理和表面数据而设计。CUDA array的内部组织细节对用户隐藏,只能通过特定的CUDA API访问,而不能像普通内存一样直接操作。CUDA array可以是一维、二维或三维的,由元素组成,每个元素可以包含1个、2个或4个分量,这些分量可以是有符号或无符号的8位、16位或32位整数,或16位浮点数,或32位浮点数。CUDA array只能通过kernel以纹理读取(见第2部分)或表面读写(见第3部分)来访问。
5.Read/Write Coherency
纹理内存和表面内存是会被缓存的,在同一个kernel调用中,写入全局内存或表面内存的数据并不会立马刷新到缓存中,如果此时对这个地址进行任何纹理读取或表面读取都将返回未定义的数据。换句话说,只有一个内存位置已经被前一个kernel调用或内存拷贝操作更新过,而不是由同一kernel调用中的同一线程或其他线程之前更新的,这个线程才能安全的读取某个纹理或表面内存位置。
