【CUDA编程】系列博客参考NVIDIA官方文档“CUDA C++ Programming Guide(v12.6)”。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Hardware Implementation
NVIDIA GPU架构围绕可扩展的多线程SM构建。GPU会将线程块动态分配到具有可用执行能力的SM上。一个SM可以同时处理一个或多个线程块内的线程,实现高效的并行计算。当一个线程块完成任务后,新的线程块会被分配到空闲的SM上。
一个SM能够同时处理数百个线程。为了管理如此大量的线程,使用了SIMT(Single-Instruction,Multiple-Thread,即单指令多线程)框架,详见第2部分。这里的指令指的是计算机硬件执行的最小单位,通常由编译语言编译后生成(可以参考:【程序是怎样跑起来的】第1章:对程序员来说CPU是什么)。指令通常由操作码和操作数组成。操作码(opcode)定义了要执行的操作类型(例如加法、乘法、数据加载等),操作数(operand)用于指定数据来源或目标的数据部分。NVIDIA GPU利用了单线程内的指令级并行性(instruction-level parallelism,ILP)和多线程之间的线程级并行性(thread-level parallelism,TLP,详见第3部分),使得其可以高效的处理大规模计算任务。这里的指令并行性指的是指令是流水线的(the instructions are pipelined),举个例子帮助大家理解,一个指令的执行分为5个阶段:
- 取指(Instruction fetch)
- 解码(Instruction decode and register fetch)
- 执行(Execute)
- 访存(Memory access)
- 写回(Register write back)
这5个阶段分别由处理器内部的不同硬件单元负责完成,因此可以在单个线程内实现指令级并行性:
- 第1个时钟周期:指令1进入取指阶段。
- 第2个时钟周期:指令1进入解码阶段,同时指令2进入取指阶段。
- 第3个时钟周期:指令1进入执行阶段,指令2进入解码阶段,指令3进入取指阶段。
- …

注意,虽然有指令级并行性,但其指令依然是顺序执行的,而在CPU中,可能根据指令之间的依赖关系,动态调整指令的执行顺序,以更高效地利用硬件资源。并且,CPU还有一点不同,就是当程序遇到条件分支(如if或for语句)时,CPU需要提前预测分支的执行路径,以避免停顿,如果预测正确,性能会得到提升;如果错误,CPU会丢弃错误路径上的指令并重新执行正确路径(称为branch prediction或speculative execution),而NVIDIA GPU则没有这种机制。
NVIDIA GPU采用小端(little-endian)字节序来表示数据。字节序是计算机存储和读取多字节数据时的顺序规则。它描述了如何将数据的字节按顺序存储在内存中。字节序有两种主要形式:
- 小端字节序(little-endian):低位字节存储在内存的低地址,高位字节存储在内存的高地址。
- 大端字节序(big-endian):高位字节存储在内存的低地址,低位字节存储在内存的高地址。
假设一个浮点数3.14159在内存中表示为4字节的十六进制数0x40490FDB,在小端字节序中存储为DB 0F 49 40。
2.SIMT Architecture
将32个并行线程组合成一个warp,多处理器(multiprocessor,即SM)就是以warp的形式来创建、管理、调度和执行线程的。一个warp内的每个线程都会从相同的程序地址开始执行,且每个线程都是相互独立的,拥有自己的指令地址计数器(instruction address counter)和寄存器状态(register state)。half-warp指的是一个warp的前半部分或后半部分(每个部分包含16个线程)。quarter-warp指的是一个warp的第一个、第二个、第三个或第四个四分之一部分(每个部分包含8个线程)。
个人注解:warp的划分是局限在单个线程块内的。
当一个多处理器被分配一个或多个线程块进行执行时,它会将这些线程块划分为多个warp,并由一个warp调度器(warp scheduler)为每个warp分配执行任务。在一个线程块内,warp的划分方式是固定的,每个warp包含的线程的ID都是连续递增的,且第一个warp包含线程ID为0的线程。举个例子,假设一个线程块中有128个线程,线程ID范围为0到127,那么第一个warp的线程ID从0到31,第二个warp的线程ID从32到63,第三个warp的线程ID从64到95,第四个warp的线程ID从96到127。线程ID和线程块内线程索引之间的关系见Thread Hierarchy。
这里先简单介绍下几种不同的框架:
- SISD(Single Instruction Single Data)
- SIMD(Single Instruction Multiple Data)
- MISD(Multiple Instruction Single Data)
- MIMD(Multiple Instruction Multiple Data)

PU是Processing Unit的缩写。而NVIDIA提出的SIMT框架像是一个多线程版本的SIMD,每个warp内做的事情就是SIMD(个人理解,如有不同意见,欢迎评论区一起讨论):

在SIMT框架中,一个warp在同一时间执行一条公共指令,因此,当warp中的32个线程在执行路径上完全一致时,可以实现最高效率。这里简单解释下,一个warp内的所有32个线程执行同一个指令,但每个线程处理不同的数据,如果遇到比如像if-else这种有不同分支的操作时,如果一个warp内的所有线程都走了if分支(或都走了else分支),那么此时效率是最高的,但如果有的线程需要走if分支,有些线程需要走else分支,即发生了所谓的分支分裂(branch divergence,仅在warp内发生),那么此时warp会先执行走if分支的线程,禁用掉走else分支的线程,等走if分支的线程完成之后,再执行走else分支的线程(并禁用掉走if分支的线程),很明显,此时的效率会受到影响。
Volta架构引入了独立线程调度(Independent Thread Scheduling),对SIMT进行了优化。在Volta架构之前,一个warp内的32个线程共享一个程序计数器(program counter,缩写为PC),在Volta架构之后,一个warp内的每个线程都有自己的程序计数器和调用栈(call stack)。
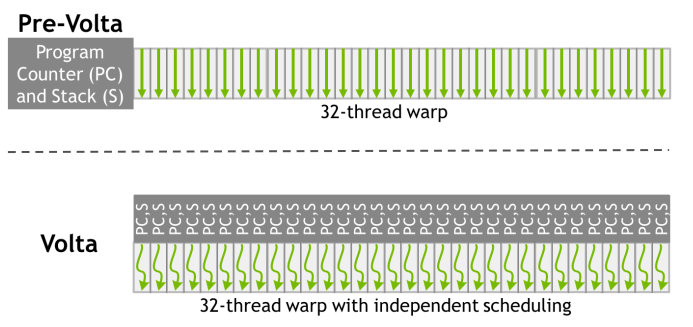
在Volta架构之后,分支分裂问题依然存在,但是因为引入了独立线程调度,可以实现线程级的调度(在Volta架构之前,以warp为单位进行调度),所以通过下图所示的方式对延迟做了优化。

也正因为此,在Volta架构之前,许多程序是假定warp同步(warp-synchronicity)的,但在Volta架构之后,这一假定不再适用,这有可能导致之前的程序出现错误或结果不一致。
warp-synchronicity是指代码隐式的假设同一warp中的线程在每一条指令上都是同步的。
注意:
一个warp中正在参与当前指令执行的线程被称为活跃线程(active threads),而不在当前指令中的线程被称为非活跃线程(inactive/disabled threads)。成为非活跃线程的原因有多种,包括:
- 比其所在warp的其他线程更早退出。
- 选择了与当前warp执行路径不同的分支路径。
- 是线程块中最后的几个线程,且线程总数不是warp大小的整数倍。
如果一个warp执行的是非原子指令,该指令是向全局内存或共享内存的同一位置执行写操作,当多个线程同时向同一个位置进行写操作时,这些写操作并不会真的同时发生,而是按照某种顺序逐一完成(但非原子指令无法保证写操作的完整性,可能会被其他线程中断),这个顺序取决于device的计算能力。此外,最终哪个线程的写操作结果被保存留下来是未定义的。
如果一个warp中的多个线程通过原子指令对全局内存的同一位置进行读/修改/写操作,这些操作都会依次发生,并且这些操作可以被完整完成,但这些操作的执行顺序是未定义的。
3.Hardware Multithreading
多处理器在整个warp的生命周期中,始终将每个warp的执行上下文(包括程序计数器、寄存器等)保存在芯片中。因此,从一个执行上下文切换到另一个执行上下文时没有开销。在指令发出时,warp调度器会选择一个已经准备好执行下一条指令的活跃线程所在的warp,并将指令发给这些活跃线程执行。
特别的,每个多处理器配备了一组32位寄存器,这些寄存器分配给多个warp使用。此外,每个多处理器还有一个并行数据缓存或共享内存,用于分配给线程块使用。
对于一个给定的kernel,在多处理器上可以同时驻留和被处理的线程块数量和warp数量取决于以下因素:
- kernel使用的寄存器数量和共享内存大小。
- 多处理器上可用的寄存器数量和共享内存大小。
此外,每个多处理器能够驻留的最大线程块数量和最大warp数量是有限制的。这些限制以及多处理器上可用的寄存器数量和共享内存大小与device的计算能力相关。如果多处理器上可用的寄存器或共享内存不足以处理至少一个线程块,kernel将无法启动。
一个线程块的warp总数为:
\[\text{ceil} \left( \frac{T}{W_{size}} , 1 \right)\]其中,$T$是每个线程块中的线程数量,$W_{size}$是warp大小(即32)。ceil(x,y)表示将x向上舍入到最接近的y的倍数。
为单个线程块分配的寄存器总数和共享内存总量记录在CUDA Toolkit提供的CUDA Occupancy Calculator中。
