本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
本文提出了一种专为移动端和资源受限环境设计的新型神经网络架构。
2.Related Work
我们的网络设计基于MobileNetV1,保留了其简单性,无需特殊算子,同时显著提升了精度,并在多个移动端的图像分类和检测任务中达到了SOTA的水平。
3.Preliminaries, discussion and intuition
3.1.Depthwise Separable Convolutions
我们使用了深度分离卷积。
假设输入张量$L_i$的维度为$h_i \times w_i \times d_i$,卷积核维度为$K \in \mathcal{R}^{k \times k \times d_i \times d_j}$,输出张量$L_j$的维度为$h_i \times w_i \times d_j$。
常规卷积的计算成本为:
\[h_i \cdot w_i \cdot d_i \cdot d_j \cdot k \cdot k\]深度分离卷积的计算成本为:
\[h_i \cdot w_i \cdot d_i (k^2 + d_j) \tag{1}\]和MobileNetV1一样,我们也使用了$k=3$的深度分离卷积,相比常规卷积,计算成本降低了8-9倍,但精度只是轻微下降。
3.2.Linear Bottlenecks
如Fig1所示,第一张图为一个2D输入(即$x$),然后我们将输入通过矩阵$T$变换到$n$维空间(即$Bx$),然后将其通过ReLU函数(即$\text{ReLU}(Bx)$),再将ReLU函数的输出通过$T^{-1}$映射回2D平面(即$A\text{ReLU}(Bx)$),即可得到Fig1后面的几张图。从Fig1可以看出,如果ReLU函数的输入维度过低,比如$n=2,3$时,信息丢失严重,如果ReLU函数的输入维度比较高,比如$n=15,30$时,信息丢失就不是很严重。

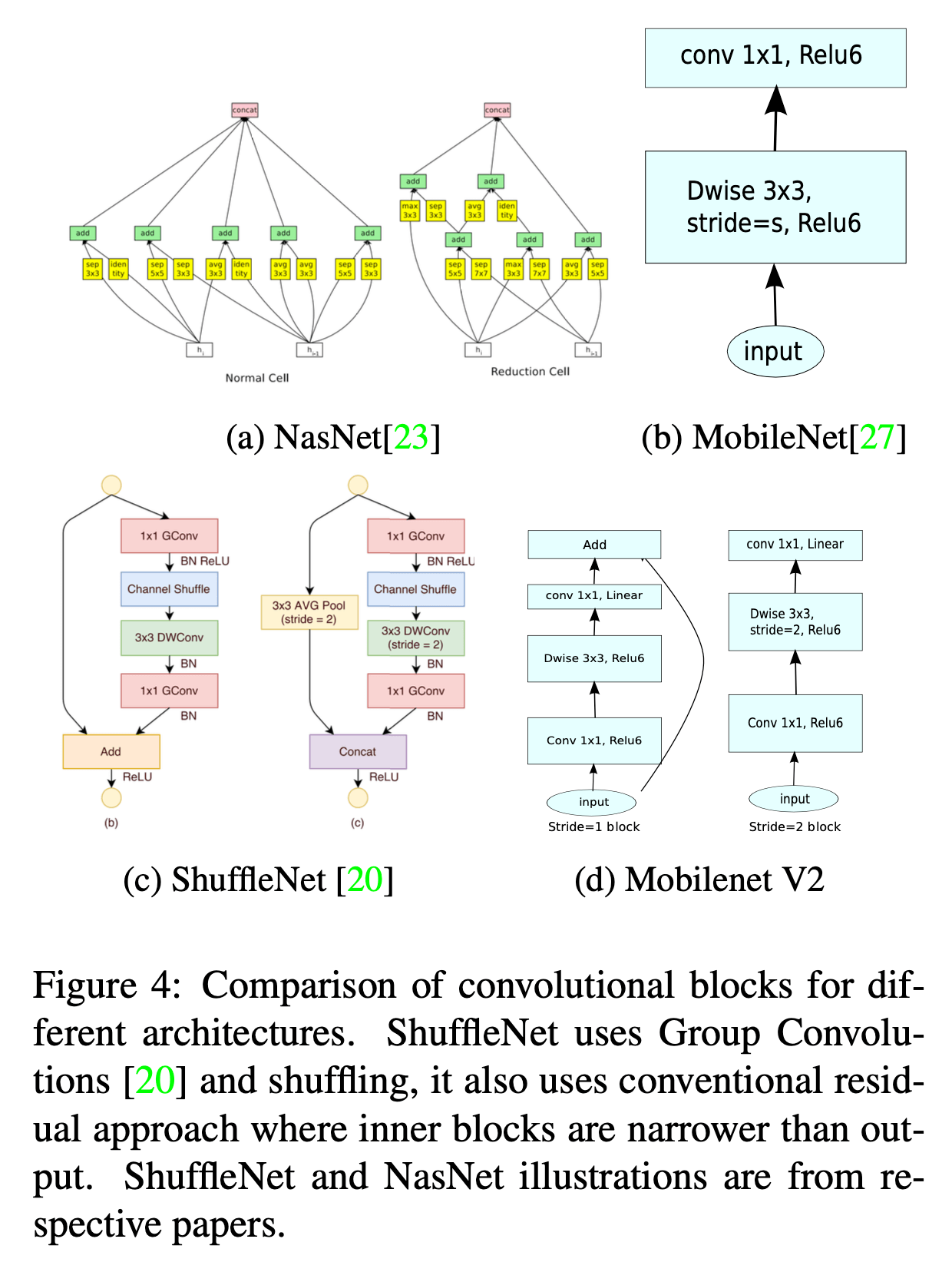
为了降低计算量,我们有时会降低ReLU函数的输入维度,为了防止丢失过多的信息,我们引入了线性瓶颈(linear bottleneck)来解决这一问题,即使用线性激活函数,可见Fig4(d)。
下面Fig2列出了分离卷积块的演变过程。Fig2(a)是普通的卷积,Fig2(b)是深度分离卷积,Fig2(c)在深度分离卷积的基础上引入了线性瓶颈,Fig2(d)又在Fig2(c)的基础上引入了扩展层,扩展层就是通过$1\times 1$卷积增加通道数。

3.3.Inverted residuals

如Fig3所示,常规的残差块两端通道数多,中间通道数少,而倒置残差块是两端通道数少,中间通道数多。
倒置残差块的详细结构见表1:

ReLU6的公式为:
\[\text{ReLU6}(x) = \min ( \max(0,x),6 )\]
3.4.Information flow interpretation
不再详述。
4.Model Architecture
模型详细结构见表2。

在表2中,每一行代表一个序列,n表示这一层在序列中重复了多少次。一个序列中所有层的输出通道数c都是相同的。一个序列中只有第一层的步长是s,其他层的步长都是1。卷积核大小都是$3\times 3$。扩展因子t的解释见表1。此外,训练还使用了dropout和BatchNorm。
在我们的实验中发现,扩展因子在5到10之间性能都差不多,较小的网络在使用较小的扩展因子时表现更好,而较大的网络在使用较大的扩展因子时表现更好。
不同卷积块之间的差异见Fig4:
👉Trade-off hyper parameters
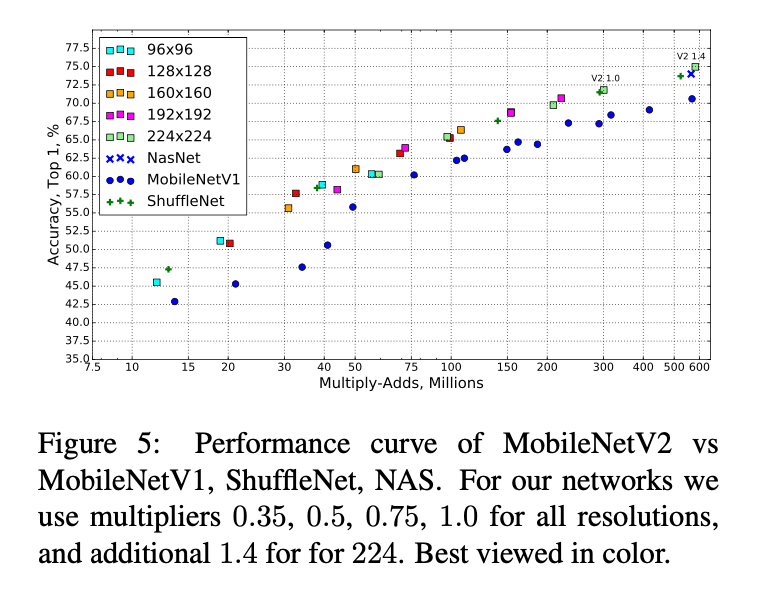
我们的标准网络的输入尺寸为$224 \times 224$,使用width multiplier等于1,模型参数量约为3.4M,共执行了约300M次乘-加运算。然后为了探索性能的trade off,我们尝试了输入尺寸从96变化到224,width multiplier从0.35变化到1.4,这些模型的乘-加运算次数从7M到585M不等,模型大小从1.7M到6.9M不等。
当width multiplier小于1时,我们将width multiplier应用到了除最后一个卷积层之外的每一层,这有助于提升较小模型的性能。
5.Implementation Notes
5.1.Memory efficient inference
本部分主要讨论了如何高效实现倒置残差块,降低其内存需求,提高推理速度,具体不再详述。
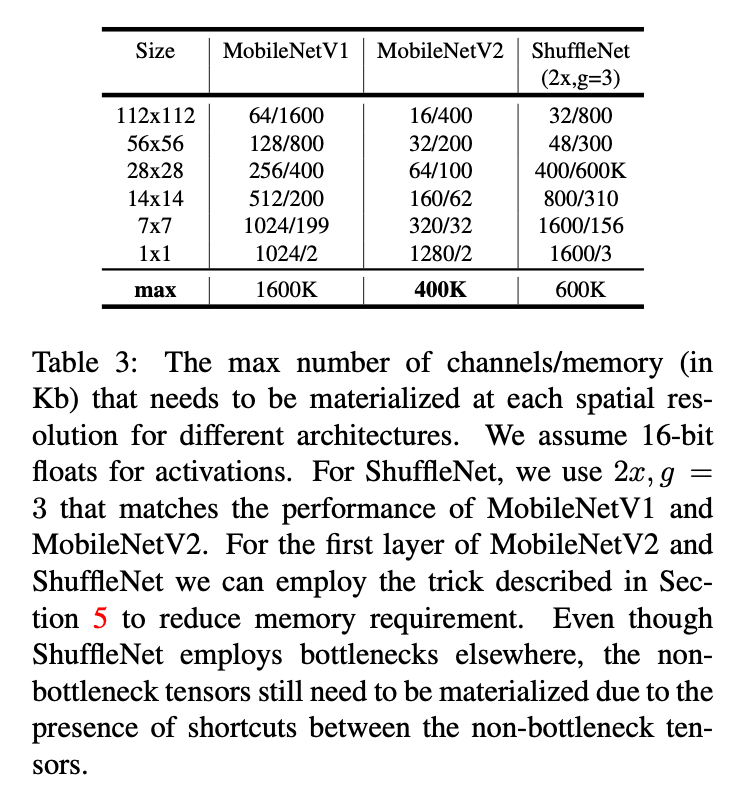
表3列出了在不同分辨率下,3种模型架构的通道数和内存需求(单位:KB)。
6.Experiments
6.1.ImageNet Classification
👉Training setup
使用TensorFlow训练模型。使用标准的RMSProp优化器,且decay和momentum都是0.9。在每一层后面都使用了BatchNorm,标准的weight decay设置为0.00004。遵循MobileNetV1的设置,初始学习率为0.045,每个epoch的学习率衰减率为0.98。使用了16块GPU异步工作,batch size为96。
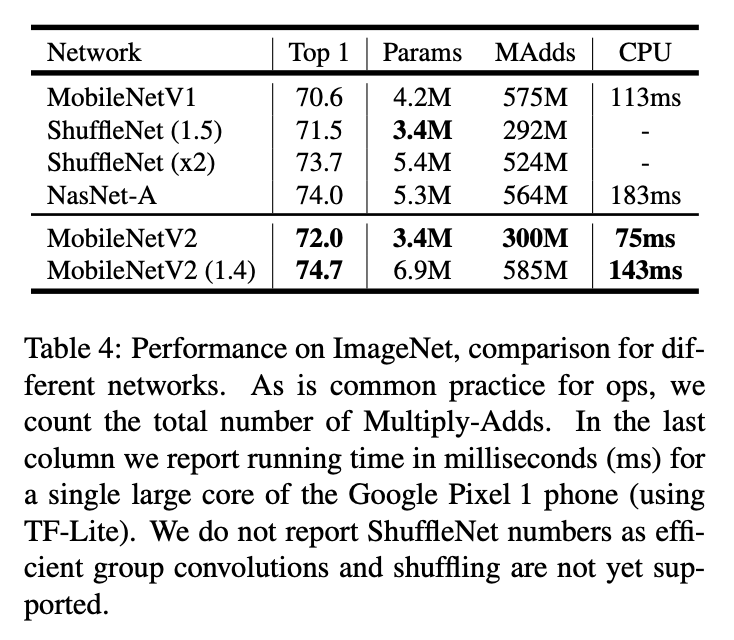
👉Results
6.2.Object Detection
在COCO数据集的目标检测任务中,我们将SSD的特征检测器分别替换为MobileNetV1和MobileNetV2,评估和比较了之间的性能差异。此外,我们还比较了YOLOv2和原始的SSD(使用VGG-16作为baseline网络)。我们没有比较其他比如Faster-RCNN和RFCN等的模型框架,因为我们关注的是移动端的实时模型。
👉SSDLite:
在本文中,我们介绍了一个移动端友好的常规SSD的变体。在SSD预测层中,我们将所有常规的卷积都替换为了深度分离卷积。我们将这一修改版本称为SSDLite。如表5所示,相比常规SSD,SSDLite的参数量和计算成本明显降低。
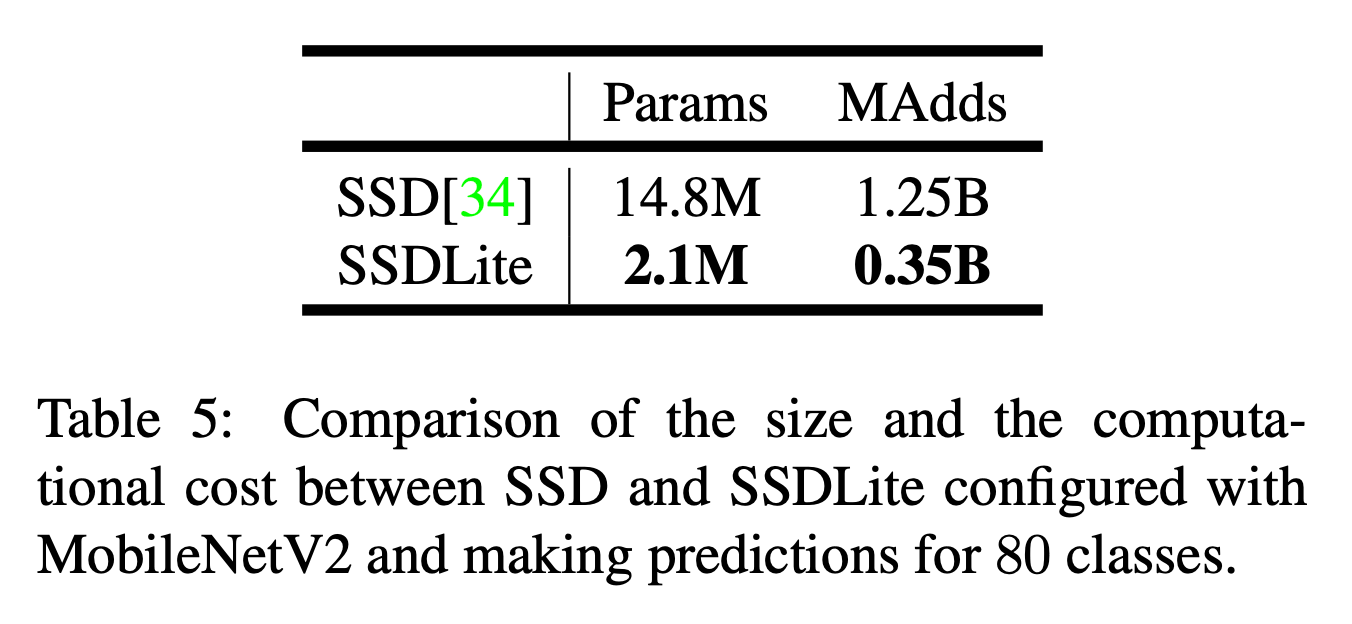
MobileNetV1和MobileNetV2分别和SSDLite结合后的结果见表6:

6.3.Semantic Segmentation
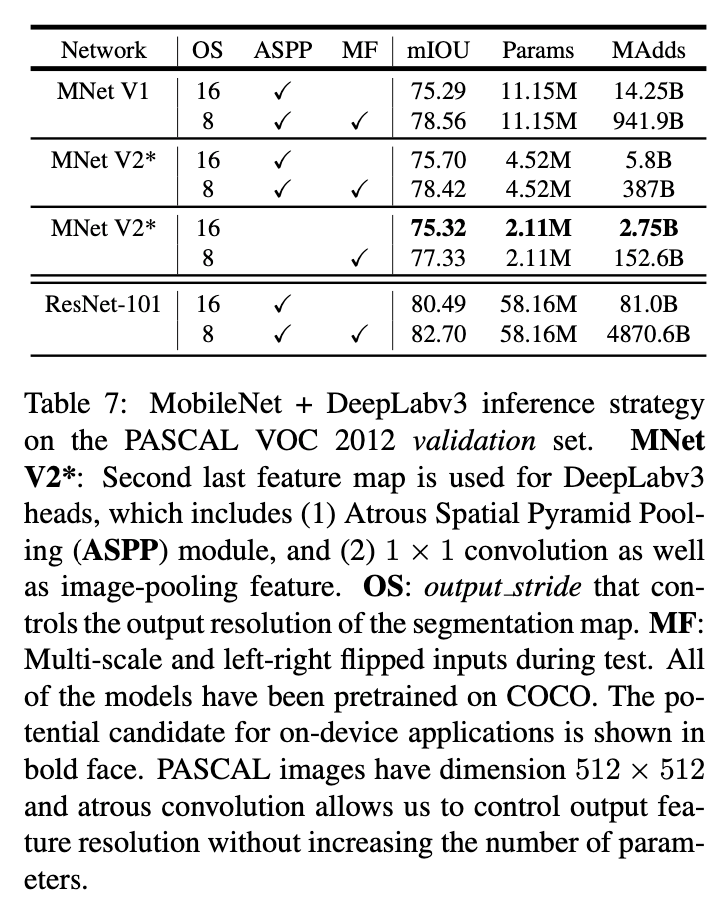
DeepLabv3原文:Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. CoRR, abs/1706.05587, 2017.。
6.4.Ablation study

👉Inverted residual connections.
见Fig6(b)。
👉Importance of linear bottlenecks.
见Fig6(a)。
7.Conclusions and future work
不再赘述。
8.Appendix
8.A.Bottleneck transformation
不再详述。
8.B.Semantic segmentation visualization results

