【CUDA编程】系列博客参考NVIDIA官方文档“CUDA C++ Programming Guide(v12.6)”。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Warp Reduce Functions
__reduce_sync(unsigned mask, T value)内置函数在同步由mask指定的线程后,对提供的value数据执行归约操作(reduction operation)。对于{add, min, max}操作,类型T可以是有符号或无符号;对于{and, or, xor}操作,类型T只能是无符号。
仅支持计算能力在8.x及以上的device。
1.1.Synopsis
1
2
3
4
5
6
7
8
9
10
11
12
// add/min/max
unsigned __reduce_add_sync(unsigned mask, unsigned value);
unsigned __reduce_min_sync(unsigned mask, unsigned value);
unsigned __reduce_max_sync(unsigned mask, unsigned value);
int __reduce_add_sync(unsigned mask, int value);
int __reduce_min_sync(unsigned mask, int value);
int __reduce_max_sync(unsigned mask, int value);
// and/or/xor
unsigned __reduce_and_sync(unsigned mask, unsigned value);
unsigned __reduce_or_sync(unsigned mask, unsigned value);
unsigned __reduce_xor_sync(unsigned mask, unsigned value);
1.2.Description
👉__reduce_add_sync、__reduce_min_sync、__reduce_max_sync:
对mask指定的所有线程中的value执行加、最小值或最大值等算术归约操作,并返回结果。
👉__reduce_and_sync、__reduce_or_sync、__reduce_xor_sync:
对mask指定的所有线程中的value执行与、或、异或等逻辑归约操作,并返回结果。
mask用于指定哪些线程将参与操作。
以上这些内置函数不保证存在内存屏障。
2.Warp Shuffle Functions
__shfl_sync、__shfl_up_sync、__shfl_down_sync、__shfl_xor_sync用于在一个warp内的线程之间交换变量。
仅支持计算能力在5.0及以上的device。
__shfl、__shfl_up、__shfl_down、__shfl_xor在CUDA 9.0中已经被弃用。
对于计算能力在7.x及以上的device,将不再支持__shfl、__shfl_up、__shfl_down、__shfl_xor,推荐使用它们对应的sync版本。
2.1.Synopsis
1
2
3
4
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);
类型T可以是int、unsigned int、long、unsigned long、long long、unsigned long long、float或double。当包含cuda_fp16.h头文件时,类型T可以是__half或__half2。当包含cuda_bf16.h头文件时,类型T可以是__nv_bfloat16或__nv_bfloat162。
2.2.Description
__shfl_sync()内置函数允许warp内线程之间交换变量,而无需使用共享内存。交换同时发生在warp内的所有活跃线程(由mask指定)之间。根据数据类型,每个线程可以移动4或8字节的数据。
一个warp内的线程也被称为lane,其索引范围从0到warpSize-1(包含两端)。对threadIndex、warpIndex、laneIndex的解释(Index和ID是一个意思):

这里说的laneIndex(或称为lane ID)指的是物理lane ID,其编号始终是从0到warpSize-1。注意和下文提到的逻辑lane ID区分。
接下来解释下这4个函数都有的参数mask和width:
mask用于指定哪些线程是活跃的。只能从活跃的线程读取数据,如果从不活跃的线程中读取数据,则读取值是未定义的。width用于warp内线程的分组。width的值只能是2的幂且范围在[1, warpSize]内,也就是说,width的值只能是1、2、4、8、16、32。如果width是其他值,则结果是未定义的。width的默认值为warpSize,即32。如果width的值小于warpSize,则warp内的线程会被划分为多个子组,每个子组内线程的逻辑lane ID范围为[0:width-1]。
👉__shfl_sync():
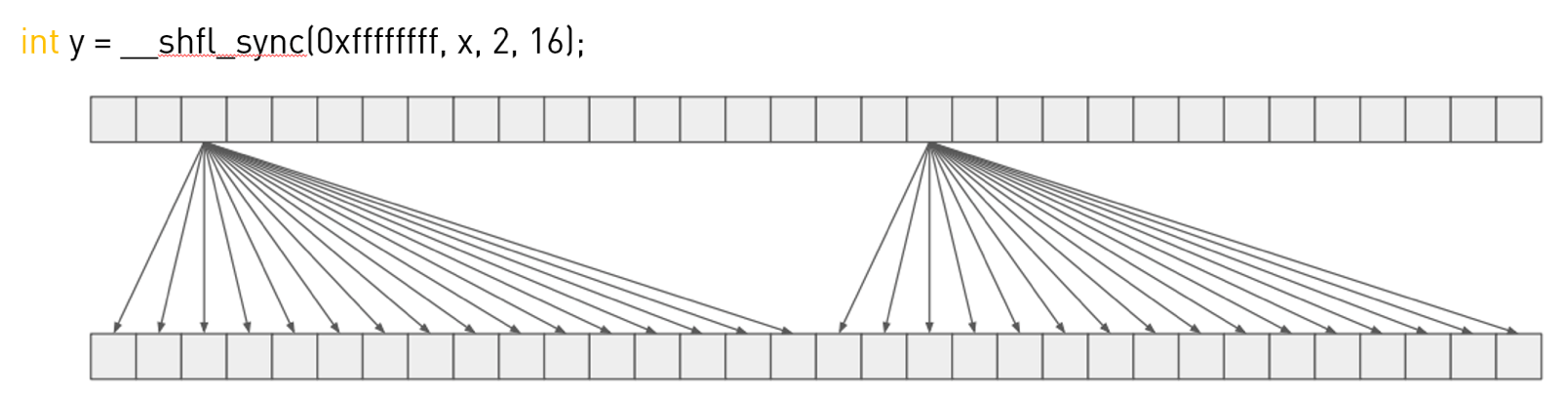
对应的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include "cuda_runtime.h"
#include <stdio.h>
__global__ void test_shfl_sync() {
int laneId = threadIdx.x % 32;
int x = threadIdx.x;
unsigned mask = 0xffffffff;
int width = 16;
//返回值y为逻辑lane ID为2的线程中变量x的值
int y = __shfl_sync(mask, x, 2, width); //和int y = __shfl_sync(mask, x, 18, 16);结果一样
printf("physical lane ID %d (logical lane ID %d): x=%d, y=%d\n", laneId, (laneId % width), x, y);
}
int main() {
test_shfl_sync << <1, 32 >> > ();
cudaDeviceSynchronize();
return 0;
}
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
physical lane ID 0 (logical lane ID 0): x=0, y=2
physical lane ID 1 (logical lane ID 1): x=1, y=2
physical lane ID 2 (logical lane ID 2): x=2, y=2
physical lane ID 3 (logical lane ID 3): x=3, y=2
physical lane ID 4 (logical lane ID 4): x=4, y=2
physical lane ID 5 (logical lane ID 5): x=5, y=2
physical lane ID 6 (logical lane ID 6): x=6, y=2
physical lane ID 7 (logical lane ID 7): x=7, y=2
physical lane ID 8 (logical lane ID 8): x=8, y=2
physical lane ID 9 (logical lane ID 9): x=9, y=2
physical lane ID 10 (logical lane ID 10): x=10, y=2
physical lane ID 11 (logical lane ID 11): x=11, y=2
physical lane ID 12 (logical lane ID 12): x=12, y=2
physical lane ID 13 (logical lane ID 13): x=13, y=2
physical lane ID 14 (logical lane ID 14): x=14, y=2
physical lane ID 15 (logical lane ID 15): x=15, y=2
physical lane ID 16 (logical lane ID 0): x=16, y=18
physical lane ID 17 (logical lane ID 1): x=17, y=18
physical lane ID 18 (logical lane ID 2): x=18, y=18
physical lane ID 19 (logical lane ID 3): x=19, y=18
physical lane ID 20 (logical lane ID 4): x=20, y=18
physical lane ID 21 (logical lane ID 5): x=21, y=18
physical lane ID 22 (logical lane ID 6): x=22, y=18
physical lane ID 23 (logical lane ID 7): x=23, y=18
physical lane ID 24 (logical lane ID 8): x=24, y=18
physical lane ID 25 (logical lane ID 9): x=25, y=18
physical lane ID 26 (logical lane ID 10): x=26, y=18
physical lane ID 27 (logical lane ID 11): x=27, y=18
physical lane ID 28 (logical lane ID 12): x=28, y=18
physical lane ID 29 (logical lane ID 13): x=29, y=18
physical lane ID 30 (logical lane ID 14): x=30, y=18
physical lane ID 31 (logical lane ID 15): x=31, y=18
👉__shfl_up_sync():
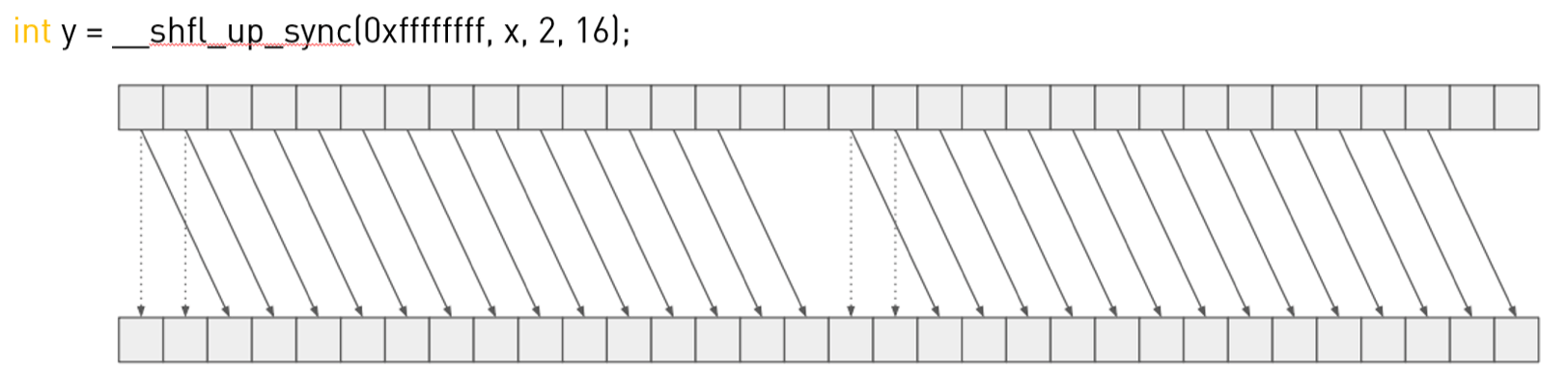
对应的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include "cuda_runtime.h"
#include <stdio.h>
__global__ void test_shfl_sync() {
int laneId = threadIdx.x % 32;
int x = threadIdx.x;
unsigned mask = 0xffffffff;
int width = 16;
int y = __shfl_up_sync(mask, x, 2, width);
printf("physical lane ID %d (logical lane ID %d): x=%d, y=%d\n", laneId, (laneId % width), x, y);
}
int main() {
test_shfl_sync << <1, 32 >> > ();
cudaDeviceSynchronize();
return 0;
}
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
physical lane ID 0 (logical lane ID 0): x=0, y=0
physical lane ID 1 (logical lane ID 1): x=1, y=1
physical lane ID 2 (logical lane ID 2): x=2, y=0
physical lane ID 3 (logical lane ID 3): x=3, y=1
physical lane ID 4 (logical lane ID 4): x=4, y=2
physical lane ID 5 (logical lane ID 5): x=5, y=3
physical lane ID 6 (logical lane ID 6): x=6, y=4
physical lane ID 7 (logical lane ID 7): x=7, y=5
physical lane ID 8 (logical lane ID 8): x=8, y=6
physical lane ID 9 (logical lane ID 9): x=9, y=7
physical lane ID 10 (logical lane ID 10): x=10, y=8
physical lane ID 11 (logical lane ID 11): x=11, y=9
physical lane ID 12 (logical lane ID 12): x=12, y=10
physical lane ID 13 (logical lane ID 13): x=13, y=11
physical lane ID 14 (logical lane ID 14): x=14, y=12
physical lane ID 15 (logical lane ID 15): x=15, y=13
physical lane ID 16 (logical lane ID 0): x=16, y=16
physical lane ID 17 (logical lane ID 1): x=17, y=17
physical lane ID 18 (logical lane ID 2): x=18, y=16
physical lane ID 19 (logical lane ID 3): x=19, y=17
physical lane ID 20 (logical lane ID 4): x=20, y=18
physical lane ID 21 (logical lane ID 5): x=21, y=19
physical lane ID 22 (logical lane ID 6): x=22, y=20
physical lane ID 23 (logical lane ID 7): x=23, y=21
physical lane ID 24 (logical lane ID 8): x=24, y=22
physical lane ID 25 (logical lane ID 9): x=25, y=23
physical lane ID 26 (logical lane ID 10): x=26, y=24
physical lane ID 27 (logical lane ID 11): x=27, y=25
physical lane ID 28 (logical lane ID 12): x=28, y=26
physical lane ID 29 (logical lane ID 13): x=29, y=27
physical lane ID 30 (logical lane ID 14): x=30, y=28
physical lane ID 31 (logical lane ID 15): x=31, y=29
👉__shfl_down_sync():
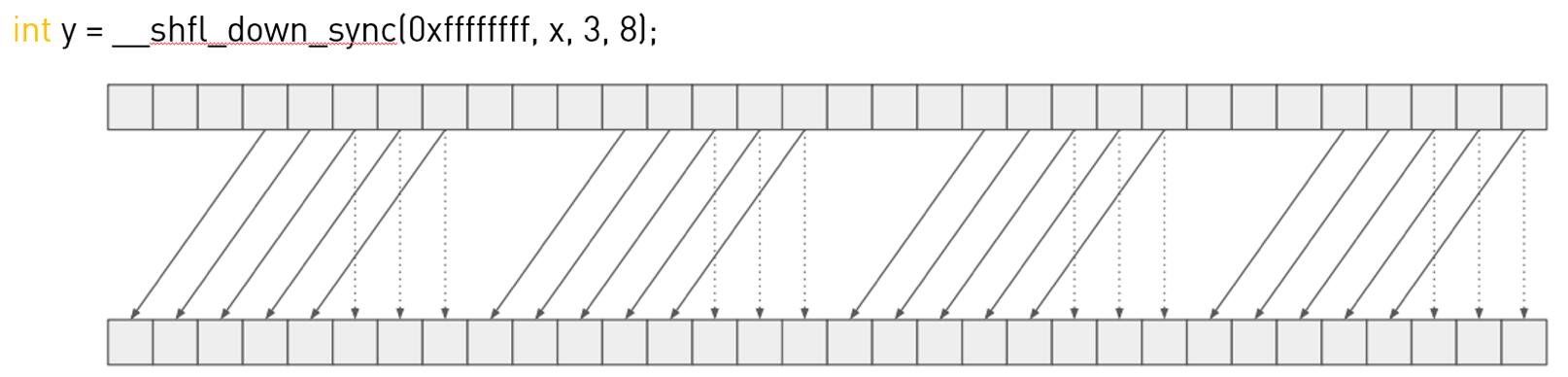
对应的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include "cuda_runtime.h"
#include <stdio.h>
__global__ void test_shfl_sync() {
int laneId = threadIdx.x % 32;
int x = threadIdx.x;
unsigned mask = 0xffffffff;
int width = 8;
int y = __shfl_down_sync(mask, x, 3, width);
printf("physical lane ID %d (logical lane ID %d): x=%d, y=%d\n", laneId, (laneId % width), x, y);
}
int main() {
test_shfl_sync << <1, 32 >> > ();
cudaDeviceSynchronize();
return 0;
}
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
physical lane ID 0 (logical lane ID 0): x=0, y=3
physical lane ID 1 (logical lane ID 1): x=1, y=4
physical lane ID 2 (logical lane ID 2): x=2, y=5
physical lane ID 3 (logical lane ID 3): x=3, y=6
physical lane ID 4 (logical lane ID 4): x=4, y=7
physical lane ID 5 (logical lane ID 5): x=5, y=5
physical lane ID 6 (logical lane ID 6): x=6, y=6
physical lane ID 7 (logical lane ID 7): x=7, y=7
physical lane ID 8 (logical lane ID 0): x=8, y=11
physical lane ID 9 (logical lane ID 1): x=9, y=12
physical lane ID 10 (logical lane ID 2): x=10, y=13
physical lane ID 11 (logical lane ID 3): x=11, y=14
physical lane ID 12 (logical lane ID 4): x=12, y=15
physical lane ID 13 (logical lane ID 5): x=13, y=13
physical lane ID 14 (logical lane ID 6): x=14, y=14
physical lane ID 15 (logical lane ID 7): x=15, y=15
physical lane ID 16 (logical lane ID 0): x=16, y=19
physical lane ID 17 (logical lane ID 1): x=17, y=20
physical lane ID 18 (logical lane ID 2): x=18, y=21
physical lane ID 19 (logical lane ID 3): x=19, y=22
physical lane ID 20 (logical lane ID 4): x=20, y=23
physical lane ID 21 (logical lane ID 5): x=21, y=21
physical lane ID 22 (logical lane ID 6): x=22, y=22
physical lane ID 23 (logical lane ID 7): x=23, y=23
physical lane ID 24 (logical lane ID 0): x=24, y=27
physical lane ID 25 (logical lane ID 1): x=25, y=28
physical lane ID 26 (logical lane ID 2): x=26, y=29
physical lane ID 27 (logical lane ID 3): x=27, y=30
physical lane ID 28 (logical lane ID 4): x=28, y=31
physical lane ID 29 (logical lane ID 5): x=29, y=29
physical lane ID 30 (logical lane ID 6): x=30, y=30
physical lane ID 31 (logical lane ID 7): x=31, y=31
👉__shfl_xor_sync():
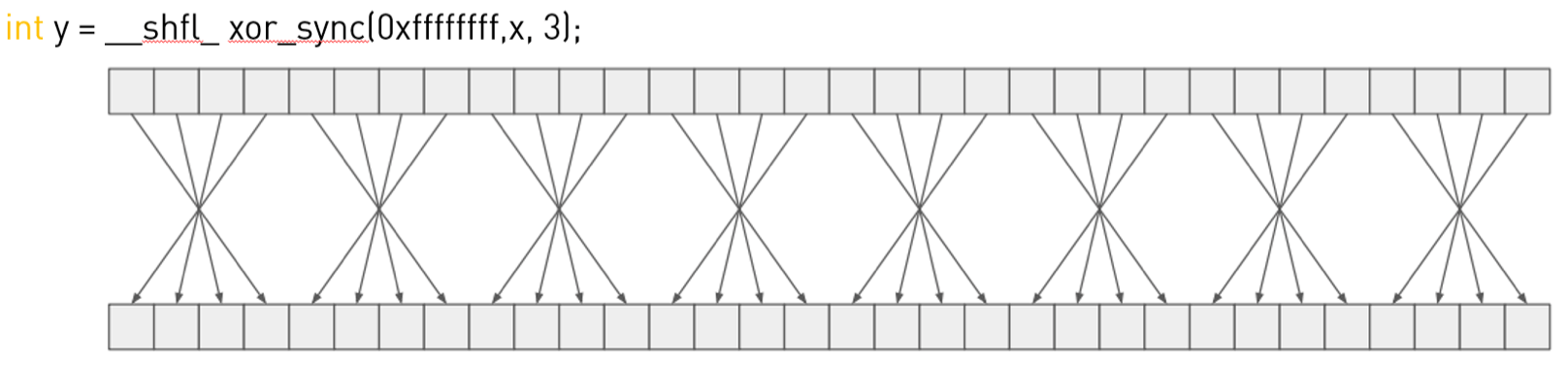
对应的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include "cuda_runtime.h"
#include <stdio.h>
__global__ void test_shfl_sync() {
int laneId = threadIdx.x % 32;
int x = threadIdx.x;
unsigned mask = 0xffffffff;
int width = 32;
int y = __shfl_xor_sync(mask, x, 3, width);
printf("physical lane ID %d (logical lane ID %d): x=%d, y=%d\n", laneId, (laneId % width), x, y);
}
int main() {
test_shfl_sync << <1, 32 >> > ();
cudaDeviceSynchronize();
return 0;
}
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
physical lane ID 0 (logical lane ID 0): x=0, y=3
physical lane ID 1 (logical lane ID 1): x=1, y=2
physical lane ID 2 (logical lane ID 2): x=2, y=1
physical lane ID 3 (logical lane ID 3): x=3, y=0
physical lane ID 4 (logical lane ID 4): x=4, y=7
physical lane ID 5 (logical lane ID 5): x=5, y=6
physical lane ID 6 (logical lane ID 6): x=6, y=5
physical lane ID 7 (logical lane ID 7): x=7, y=4
physical lane ID 8 (logical lane ID 8): x=8, y=11
physical lane ID 9 (logical lane ID 9): x=9, y=10
physical lane ID 10 (logical lane ID 10): x=10, y=9
physical lane ID 11 (logical lane ID 11): x=11, y=8
physical lane ID 12 (logical lane ID 12): x=12, y=15
physical lane ID 13 (logical lane ID 13): x=13, y=14
physical lane ID 14 (logical lane ID 14): x=14, y=13
physical lane ID 15 (logical lane ID 15): x=15, y=12
physical lane ID 16 (logical lane ID 16): x=16, y=19
physical lane ID 17 (logical lane ID 17): x=17, y=18
physical lane ID 18 (logical lane ID 18): x=18, y=17
physical lane ID 19 (logical lane ID 19): x=19, y=16
physical lane ID 20 (logical lane ID 20): x=20, y=23
physical lane ID 21 (logical lane ID 21): x=21, y=22
physical lane ID 22 (logical lane ID 22): x=22, y=21
physical lane ID 23 (logical lane ID 23): x=23, y=20
physical lane ID 24 (logical lane ID 24): x=24, y=27
physical lane ID 25 (logical lane ID 25): x=25, y=26
physical lane ID 26 (logical lane ID 26): x=26, y=25
physical lane ID 27 (logical lane ID 27): x=27, y=24
physical lane ID 28 (logical lane ID 28): x=28, y=31
physical lane ID 29 (logical lane ID 29): x=29, y=30
physical lane ID 30 (logical lane ID 30): x=30, y=29
physical lane ID 31 (logical lane ID 31): x=31, y=28
以int y = __shfl_xor_sync(mask, x, 3, width);为例,假设线程逻辑lane ID为4,对应的二进制为100,参数laneMask为3,对应的二进制为011,二者按位异或的结果是111,即十进制的7,也就是说逻辑lane ID为4的线程和逻辑lane ID为7的线程进行交换。
以上这些内置函数不保证存在内存屏障。
2.3.Examples
2.3.1.Broadcast of a single value across a warp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <stdio.h>
__global__ void bcast(int arg) {
int laneId = threadIdx.x & 0x1f;
int value;
if (laneId == 0) // Note unused variable for
value = arg; // all threads except lane 0
value = __shfl_sync(0xffffffff, value, 0); // Synchronize all threads in warp, and get "value" from lane 0
if (value != arg)
printf("Thread %d failed.\n", threadIdx.x);
}
int main() {
bcast<<< 1, 32 >>>(1234);
cudaDeviceSynchronize();
return 0;
}
2.3.2.Inclusive plus-scan across sub-partitions of 8 threads
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <stdio.h>
__global__ void scan4() {
int laneId = threadIdx.x & 0x1f;
// Seed sample starting value (inverse of lane ID)
int value = 31 - laneId;
// Loop to accumulate scan within my partition.
// Scan requires log2(n) == 3 steps for 8 threads
// It works by an accumulated sum up the warp
// by 1, 2, 4, 8 etc. steps.
for (int i=1; i<=4; i*=2) {
// We do the __shfl_sync unconditionally so that we
// can read even from threads which won't do a
// sum, and then conditionally assign the result.
int n = __shfl_up_sync(0xffffffff, value, i, 8);
if ((laneId & 7) >= i)
value += n;
}
printf("Thread %d final value = %d\n", threadIdx.x, value);
}
int main() {
scan4<<< 1, 32 >>>();
cudaDeviceSynchronize();
return 0;
}
2.3.3.Reduction across a warp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
__global__ void warpReduce() {
int laneId = threadIdx.x & 0x1f;
// Seed starting value as inverse lane ID
int value = 31 - laneId;
// Use XOR mode to perform butterfly reduction
for (int i=16; i>=1; i/=2)
value += __shfl_xor_sync(0xffffffff, value, i, 32);
// "value" now contains the sum across all threads
printf("Thread %d final value = %d\n", threadIdx.x, value);
}
int main() {
warpReduce<<< 1, 32 >>>();
cudaDeviceSynchronize();
return 0;
}
3.Nanosleep Function
3.1.Synopsis
1
void __nanosleep(unsigned ns);
3.2.Description
__nanosleep(ns)使线程暂停大约ns纳秒的时间。最大睡眠时间大约为1毫秒。
该函数只支持计算能力在7.0及以上的device。
3.3.Example
1
2
3
4
5
6
7
8
9
10
11
12
13
__device__ void mutex_lock(unsigned int *mutex) {
unsigned int ns = 8;
while (atomicCAS(mutex, 0, 1) == 1) {
__nanosleep(ns);
if (ns < 256) {
ns *= 2;
}
}
}
__device__ void mutex_unlock(unsigned int *mutex) {
atomicExch(mutex, 0);
}
4.Warp Matrix Functions
C++ warp矩阵操作利用Tensor核心加速形如D=A*B+C的矩阵运算。这些操作支持混合精度浮点数据,适用于计算能力7.0及以上的device。这需要一个warp内的所有线程协同操作。此外,这些操作仅在整个warp中的条件计算结果相同的情况下才能在条件代码中运行,否则代码执行可能会卡住。
4.1.Description
以下所有函数和类型都定义在nvcuda::wmma命名空间中。子字节操作(sub-byte operations,指操作的数据粒度小于8比特)尚不稳定,即其数据结构和API可能会发生变化,且在未来版本中可能不兼容。此附加功能定义在nvcuda::wmma::experimental命名空间中。
1
2
3
4
5
6
7
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
fragment是一个重载的类(参见:类模板),包含一个矩阵片段,该矩阵片段分布在warp中的所有线程上。矩阵元素在fragment中的内部存储方式未指定,并可能在未来架构中发生变化。
只有某些模板参数组合是允许的。第一个参数Use的值可以是:
matrix_a:表示D=A*B+C中的矩阵A,维度为m x k。matrix_b:表示D=A*B+C中的矩阵B,维度为k x n。accumulator:表示D=A*B+C中的矩阵C或矩阵D,维度为m x n。
参数T表示数据类型,可以是:
- 适用于
matrix_a或matrix_b:double、float、__half、__nv_bfloat16、char、unsigned char。 - 适用于
accumulator:double、float、int、__half。
matrix_a、matrix_b、accumulator的数据类型组合以及对应的矩阵大小是有限制的,详见第4.6部分。当Use为matrix_a或matrix_b时,在定义matrix_a矩阵或matrix_b矩阵时,必须指定参数Layout。参数Layout可以是:
row_major:矩阵行中的元素在内存中是连续存储的。col_major:矩阵列中的元素在内存中是连续存储的。
当Use为accumulator时,如果是定义accumulator矩阵,则参数Layout应为void(默认值),但如果加载或存储accumulator矩阵时(即调用load_matrix_sync或store_matrix_sync时),则需要指定参数Layout。
load_matrix_sync函数会在所有warp lanes到达load_matrix_sync调用点后,从内存中加载矩阵片段。mptr必须是一个256位对齐的指针,指向矩阵中的第一个元素。ldm为连续行(针对row major layout)或连续列(针对column major layout)之间的步长,如果矩阵元素类型为__half,则ldm必须是8的倍数;如果矩阵元素类型为float,则ldm必须是4的倍数。如果加载accumulator矩阵,必须指定参数layout为mem_row_major或mem_col_major。如果加载matrix_a矩阵或matrix_b矩阵,则参数layout会从定义该矩阵时指定的layout推断出来。mptr、ldm、layout以及a中所有的模板参数必须在warp的所有线程中保持一致。load_matrix_sync必须被warp中的所有线程所调用,否则结果是未定义的。
store_matrix_sync函数会在所有warp lanes到达store_matrix_sync调用点后,将矩阵片段保存至内存中。mptr必须是一个256位对齐的指针,指向矩阵中的第一个元素。ldm为连续行(针对row major layout)或连续列(针对column major layout)之间的步长,如果矩阵元素类型为__half,则ldm必须是8的倍数;如果矩阵元素类型为float,则ldm必须是4的倍数。输出矩阵的layout必须是mem_row_major或mem_col_major。mptr、ldm、layout以及a中所有的模板参数必须在warp的所有线程中保持一致。
fill_fragment用常量值v填充一个矩阵片段。由于矩阵元素在矩阵片段中的映射方式未指定,因此该函数通常需要由warp中的所有线程调用,并且使用相同的常量值v。
mma_sync函数在等待所有warp lanes到达mma_sync调用点后,执行warp同步矩阵的乘-加运算D=A*B+C。也支持C=A*B+C运算。satf的值以及每个矩阵片段的模板参数在warp的所有线程中必须都是一样的。mma_sync必须被warp中的所有线程所调用,否则结果是未定义的。
当satf(saturate to finite value)为true时,矩阵加操作会遵循以下规则:
- 当矩阵元素的值为正无穷时,保存为
+MAX_NORM。 - 当矩阵元素的值为负无穷时,保存为
-MAX_NORM。 - 当矩阵元素的值为NaN时,保存为
+0。
由于每个线程的fragment中矩阵元素的映射方式未指定,所以必须在调用store_matrix_sync后,从内存(共享内存或全局内存)中访问单独的矩阵元素。访问单个元素:
1
2
enum fragment<Use, m, n, k, T, Layout>::num_elements;
T fragment<Use, m, n, k, T, Layout>::x[num_elements];
一个例子:
1
2
3
4
5
wmma::fragment<wmma::accumulator, 16, 16, 16, float> frag;
float alpha = 0.5f; // Same value for all threads in warp
/*...*/
for(int t=0; t<frag.num_elements; t++)
frag.x[t] *= alpha;
4.2.Alternate Floating Point
Tensor Cores在计算能力8.0及更高的device上支持多种浮点运算类型。
__nv_bfloat16
这种数据格式是fp16(半精度浮点数)的替代格式,它的数值范围与f32(单精度浮点数)相同,但精度降低(仅7位精度)。引入cuda_bf16.h头文件后可以直接使用__nv_bfloat16类型。matrix_a矩阵和matrix_b矩阵可以使用__nv_bfloat16类型,但此时accumulator矩阵必须是float类型。__nv_bfloat16支持的矩阵大小和操作与__half相同。
tf32
这种数据格式是Tensor Cores支持的一种特殊的浮点类型,它的数值范围与f32(单精度浮点数)相同,但精度降低(大于等于10位精度)。tf32格式的内部存储方式由硬件实现决定,用户无法直接控制。如果想在WMMA(Warp Matrix Multiply-Accumulate)操作中使用这种数据格式,必须手动将输入矩阵转换为tf32格式。
为了方便这种转换,提供了内置函数__float_to_tf32。该内置函数的输入和输出的数据类型都是float,但数值计算实际上是以tf32精度执行的。注意,该精度仅能在Tensor Cores上使用,且不能与其他float类型混用,否则结果的精度和范围是未定义的。
如果输入矩阵(matrix_a或matrix_b)使用了tf32精度,那么accumulator就必须使用float类型,且只支持矩阵大小为$16 \times 16 \times 8$(m-n-k),具体见mma.h头文件中的相关代码:
1
2
3
4
5
template<> class fragment<matrix_a, 16, 16, 8, precision::tf32, row_major> : public __frag_base<precision::tf32, 4> {};
template<> class fragment<matrix_a, 16, 16, 8, precision::tf32, col_major> : public __frag_base<precision::tf32, 4> {};
template<> class fragment<matrix_b, 16, 16, 8, precision::tf32, row_major> : public __frag_base<precision::tf32, 4> {};
template<> class fragment<matrix_b, 16, 16, 8, precision::tf32, col_major> : public __frag_base<precision::tf32, 4> {};
template<> class fragment<accumulator, 16, 16, 8, float> : public __frag_base<float, 8> {};
需要注意的是,数据仍然是按照float格式存储的,但实际计算时的格式为tf32。调用storage_element_type<T>可以得到内部存储所用的数据格式,即float。调用element_type<T>可以得到实际计算时所用的数据格式,即tf32。
4.3.Double Precision
在计算能力8.0及以上的device中,Tensor Cores支持双精度浮点运算。要使用这个新功能,fragment必须指定数据类型为double。mma_sync操作将遵循.rn规则。.rn全称为rounds to nearest even,其规则是四舍六入五取最近的偶数,比如:
1
2
3
4
5
6
7
8
9
10
roundeven(+2.4) = +2.0
roundeven(-2.4) = -2.0
roundeven(+2.5) = +2.0
roundeven(-2.5) = -2.0
roundeven(+2.6) = +3.0
roundeven(-2.6) = -3.0
roundeven(+3.5) = +4.0
roundeven(-3.5) = -4.0
roundeven(-0.0) = -0.0
roundeven(-Inf) = -inf
4.4.Sub-byte Operations
子字节WMMA运算可以利用Tensor Cores的低精度计算能力,其定义在nvcuda::wmma::experimental命名空间中:
1
2
3
4
5
6
7
8
9
10
11
12
namespace experimental {
namespace precision {
struct u4; // 4-bit unsigned
struct s4; // 4-bit signed
struct b1; // 1-bit
}
enum bmmaBitOp {
bmmaBitOpXOR = 1, // compute_75 minimum
bmmaBitOpAND = 2 // compute_80 minimum
};
enum bmmaAccumulateOp { bmmaAccumulateOpPOPC = 1 };
}
对于4比特精度,可用的API保持不变,但必须显式指定experimental::precision::u4或experimental::precision::s4作为fragment的数据类型。由于fragment内的元素是紧凑存储的,因此num_storage_elements小于num_elements。num_elements表示子字节数据类型的总元素数量。从element_type<T>到storage_element_type<T>的映射如下:
1
2
3
4
experimental::precision::u4 -> unsigned (8 elements in 1 storage element) //8个4比特的元素存储在1个32比特的存储单元中
experimental::precision::s4 -> int (8 elements in 1 storage element) //8个4比特的元素存储在1个32比特的存储单元中
experimental::precision::b1 -> unsigned (32 elements in 1 storage element) //32个1比特元素存储在1个32比特的存储单元中
T -> T //all other types
对于子字节fragment的layout,matrix_a必须使用row_major,matrix_b必须使用col_major。
对于子字节运算,load_matrix_sync中的ldm参数必须满足:
- 对于
experimental::precision::u4和experimental::precision::s4,ldm必须是32的倍数。 - 对于
experimental::precision::b1,ldm必须是128的倍数。
注意:
如下MMA指令将在
sm_90中被废除:
experimental::precision::u4experimental::precision::s4- 当
bmmaBitOp设置为bmmaBitOpXOR时,experimental::precision::b1
bmma_sync函数在等待所有warp lanes到达bmma_sync调用点后,执行warp同步比特矩阵的乘-加运算D = (A op B) + C,其中,op由逻辑运算bmmaBitOp和bmmaAccumulateOp定义的累加操作组成。可用的操作有:
bmmaBitOpXOR:matrix_a的128比特的行与matrix_b的128比特的列进行按位异或操作。bmmaBitOpAND:matrix_a的128比特的行与matrix_b的128比特的列进行按位与操作,仅支持计算能力在8.0及以上的device。- 累加操作通常是
bmmaAccumulateOpPOPC,即统计1的数量。
4.5.Restrictions
Tensor Cores要求的特殊格式在不同的主要(major)和次要(minor)device架构之间可能有所不同。这使得WMMA计算更加复杂,因为线程仅持有矩阵片段fragment(即架构特定的ABI数据结构),而不是完整的矩阵。开发者无法假设fragment是如何映射到寄存器的,因为映射策略取决于GPU架构。
ABI:Application Binary Interface,译为应用二进制接口,是二进制级别定义程序如何在系统上运行的一组规则,包括函数调用约定、寄存器使用规则、内存布局、指令集兼容性、动态链接和共享库格式等。
由于fragment是基于特定架构的,如果函数A和函数B分别为不同架构编译,并在同一个设备上链接执行,则跨架构传递fragment是不安全的。在这种情况下,fragment的大小和layout可能因架构不同而变化,在不匹配的架构上使用WMMA API,可能导致错误结果甚至数据损坏。
不同架构之间,比如sm_70和sm_75之间,fragment的layout是不同的。
1
2
fragA.cu: void foo() { wmma::fragment<...> mat_a; bar(&mat_a); }
fragB.cu: void bar(wmma::fragment<...> *mat_a) { // operate on mat_a }
1
2
3
4
5
6
// sm_70 fragment layout
$> nvcc -dc -arch=compute_70 -code=sm_70 fragA.cu -o fragA.o
// sm_75 fragment layout
$> nvcc -dc -arch=compute_75 -code=sm_75 fragB.cu -o fragB.o
// Linking the two together
$> nvcc -dlink -arch=sm_75 fragA.o fragB.o -o frag.o
这种未定义行为可能在编译时和运行时工具中都无法被检测到,因此需要特别注意确保fragment的layout保持一致。这种链接问题最有可能发生在:当链接到一个旧版库时,且该库是采用不同架构编译的。
请注意,在弱链接的情况下(例如CUDA C++内联函数),链接器可能会选择任何可用的函数定义,这可能会导致不同编译单元之间的fragment发生隐式传递。
为了避免此类问题,矩阵应始终先存储到内存,然后再通过外部接口进行传输(例如使用wmma::store_matrix_sync(dst, …);),这样,矩阵就可以作为指针类型传递给bar(),例如float *dst,以确保数据在不同架构之间的兼容性和正确性。
请注意,sm_70代码可以在sm_75设备上运行,因此上面的sm_75代码可以更改为sm_70,并且仍然可以在sm_75上正确执行。然而,当你的应用程序需要与其他单独编译的sm_75二进制文件进行链接时,推荐使用sm_75原生代码,以确保最佳兼容性和性能。
4.6.Element Types and Matrix Sizes
Tensor Cores支持多种元素类型和矩阵大小。下表展示了matrix_a、matrix_b和accumulator支持的各种组合:

支持的浮点运算:

支持的双精度运算:

支持的子字节操作:
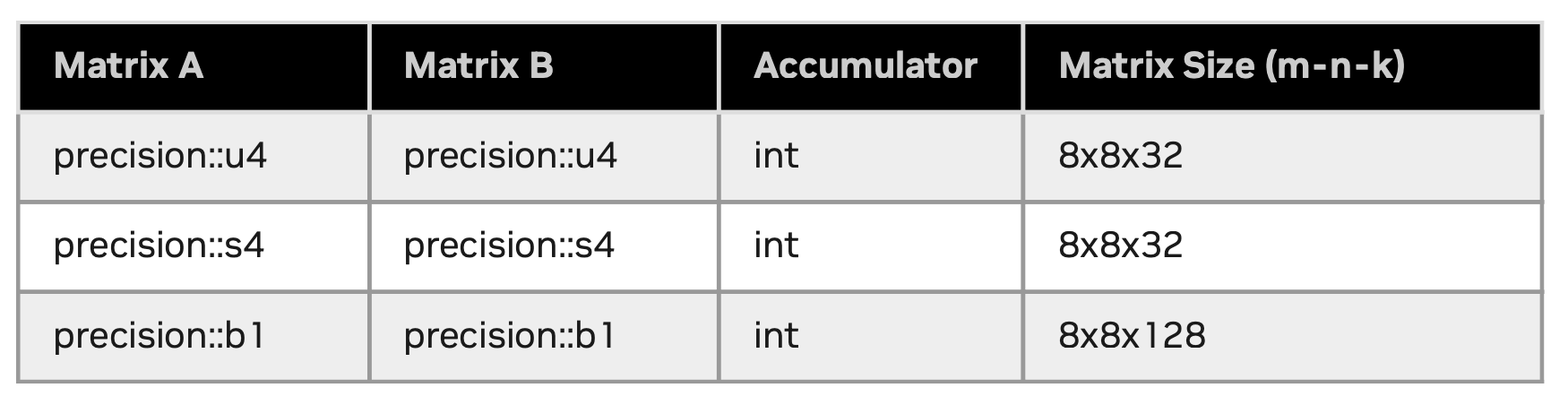
4.7.Example
下面的代码示例是在一个warp内执行$16 \times 16 \times 16$的矩阵乘法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <mma.h>
using namespace nvcuda;
__global__ void wmma_ker(half *a, half *b, float *c) {
// Declare the fragments
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
// Initialize the output to zero
wmma::fill_fragment(c_frag, 0.0f);
// Load the inputs
wmma::load_matrix_sync(a_frag, a, 16);
wmma::load_matrix_sync(b_frag, b, 16);
// Perform the matrix multiplication
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// Store the output
wmma::store_matrix_sync(c, c_frag, 16, wmma::mem_row_major);
}
5.DPX
DPX是一组函数,最多支持三个16位和32位的有符号或无符号整数参数,并可选使用ReLU函数。DPX支持的操作有:
- 计算三个参数中的最大值或最小值:
__vimax3_s32、__vimax3_s16x2、__vimax3_u32、__vimax3_u16x2__vimin3_s32、__vimin3_s16x2、__vimin3_u32、__vimin3_u16x2
- 计算两个参数中的最大值或最小值,并应用ReLU函数:
__vimax_s32_relu、__vimax_s16x2_relu__vimin_s32_relu、__vimin_s16x2_relu
- 计算三个参数中的最大值或最小值,并应用ReLU函数:
__vimax3_s32_relu、__vimax3_s16x2_relu__vimin3_s32_relu、__vimin3_s16x2_relu
- 计算两个参数中的最大值或最小值:
__vibmax_s32、__vibmax_u32、__vibmax_s16x2、__vibmax_u16x2__vibmin_s32、__vibmin_u32、__vibmin_s16x2、__vibmin_u16x2
- 比较前两个参数之和与第三个参数:
__viaddmax_s32、__viaddmax_s16x2、__viaddmax_u32、__viaddmax_u16x2__viaddmin_s32、__viaddmin_s16x2、__viaddmin_u32、__viaddmin_u16x2
- 比较前两个参数之和与第三个参数,并应用ReLU函数:
__viaddmax_s32_relu、__viaddmax_s16x2_relu__viaddmin_s32_relu、__viaddmin_s16x2_relu
这些指令在计算能力9及以上的device上进行硬件加速,并在较老的device上提供软件仿真(software emulation)。
DPX在实现动态规划算法时尤其有用,例如基因组学中的Smith-Waterman算法或Needleman-Wunsch算法,以及在路径优化中的Floyd-Warshall算法。
5.1.Examples
三个32位整数,计算最大值,并应用ReLU:
1
2
3
4
5
6
7
const int a = -15;
const int b = 8;
const int c = 5;
int max_value_0 = __vimax3_s32_relu(a, b, c); // max(-15, 8, 5, 0) = 8
const int d = -2;
const int e = -4;
int max_value_1 = __vimax3_s32_relu(a, d, e); // max(-15, -2, -4, 0) = 0
计算前两个参数的和,将其和第三个参数比较求最大值,然后应用ReLU函数:
1
2
3
4
5
6
const int a = -5;
const int b = 6;
const int c = -2;
int max_value_0 = __viaddmax_s32_relu(a, b, c); // max(-5 + 6, -2, 0) = max(1, -2, 0) = 1
const int d = 4;
int max_value_1 = __viaddmax_s32_relu(a, d, c); // max(-5 + 4, -2, 0) = max(-1, -2, 0) = 0
两个32位无符号整型数,求最小值:
1
2
3
4
const unsigned int a = 9;
const unsigned int b = 6;
bool smaller_value;
unsigned int min_value = __vibmin_u32(a, b, &smaller_value); // min_value is 6, smaller_value is true
求3个无符号16位整型数的最大值:
1
2
3
4
const unsigned a = 0x00050002;
const unsigned b = 0x00070004;
const unsigned c = 0x00020006;
unsigned int max_value = __vimax3_u16x2(a, b, c); // max(5, 7, 2) and max(2, 4, 6), so max_value is 0x00070006
