【从零开始构建大语言模型】系列博客为”Build a Large Language Model (From Scratch)”一书的个人读书笔记。
- 原书链接:Build a Large Language Model (From Scratch)。
- 官方示例代码:LLMs-from-scratch。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.What is an LLM?
large language model中的large不仅仅指模型的参数规模,还指其训练所使用的庞大数据集。
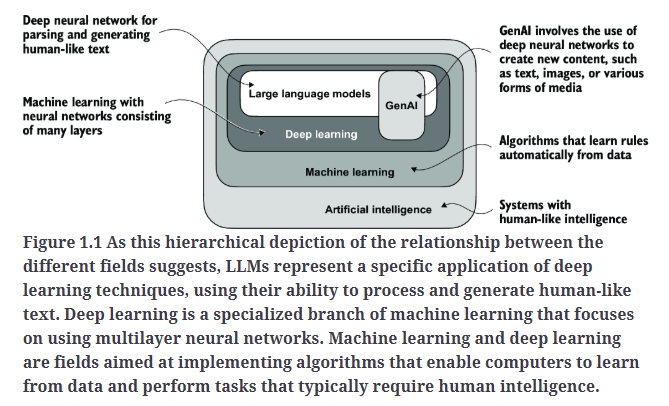
2.Applications of LLMs
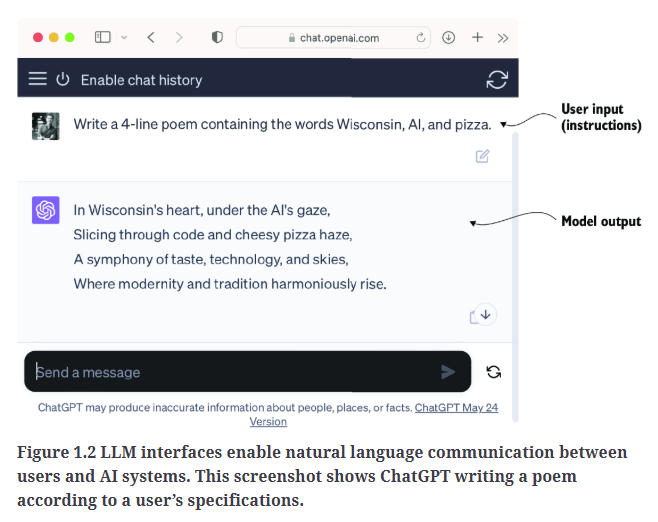
Fig1.2是一个文本生成的应用例子。
3.Stages of building and using LLMs
大多数的LLM都是基于PyTorch实现的。
研究表明,在模型性能方面,定制化的LLM(针对特定任务或领域优化的模型)往往优于通用LLM(比如ChatGPT),后者旨在适用于更广泛的应用场景。
定制化LLM的优势:
- 保护数据隐私,可以不将敏感数据共享给OpenAI等第三方LLM提供商。
- 可以开发更小型的LLM,部署在用户设备上,比如笔记本电脑或智能手机。
- 可以根据需求自由控制模型的更新和调整。
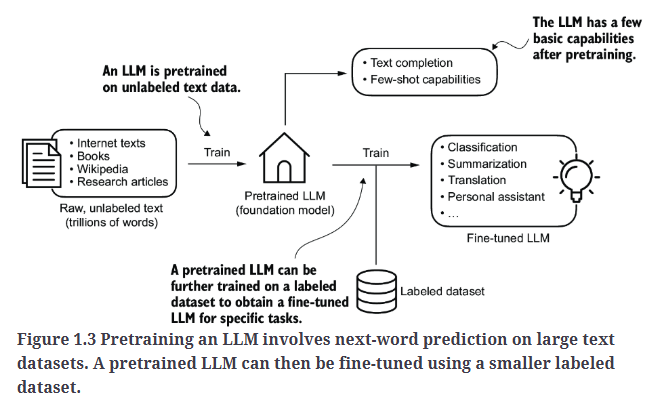
构建LLM的一般流程包括pre-train和fine-tune,如Fig1.3所示。
4.Introducing the transformer architecture
大多数的LLM都基于transformer架构,原始的transformer架构最初是用于机器翻译的,其简化示意图见Fig1.4。
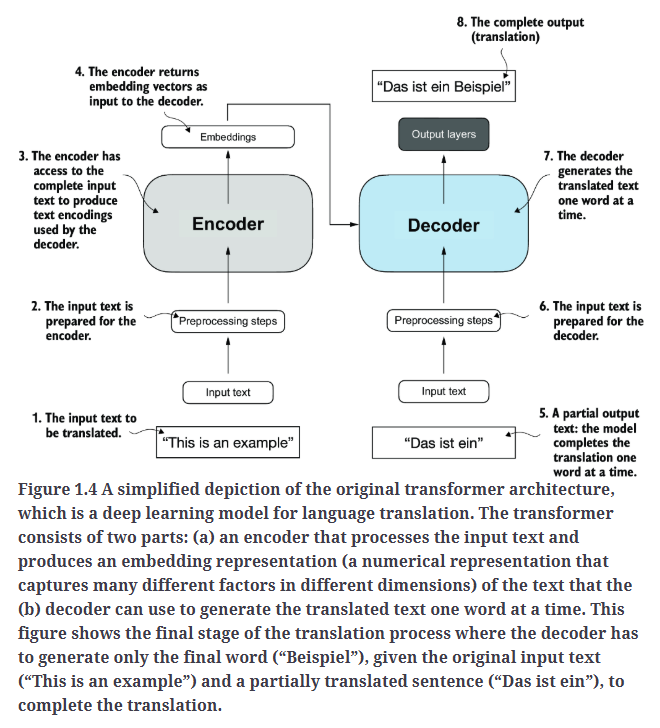
对于transformer的详细讲解,请移步另一篇博客:【论文阅读】Attention Is All You Need。
基于transformer架构的两个变体:
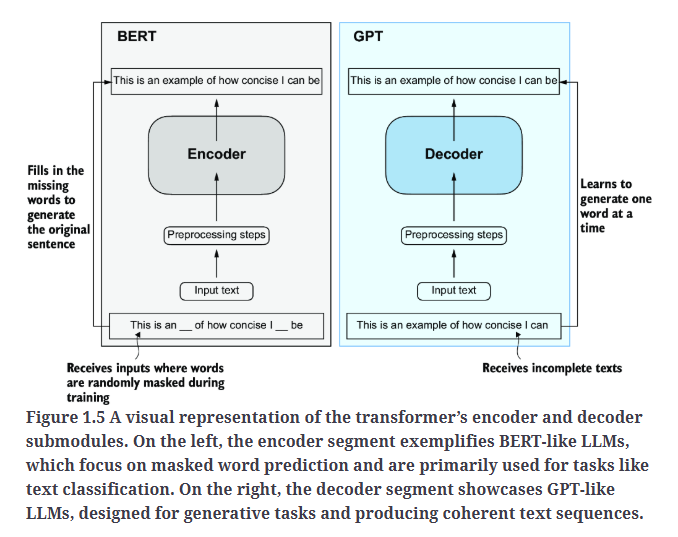
- 对于BERT的详细讲解,请移步博客:【论文阅读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding。
- 对于GPT系列的详细讲解,请移步博客:【LLM】一文读懂ChatGPT背后的技术。
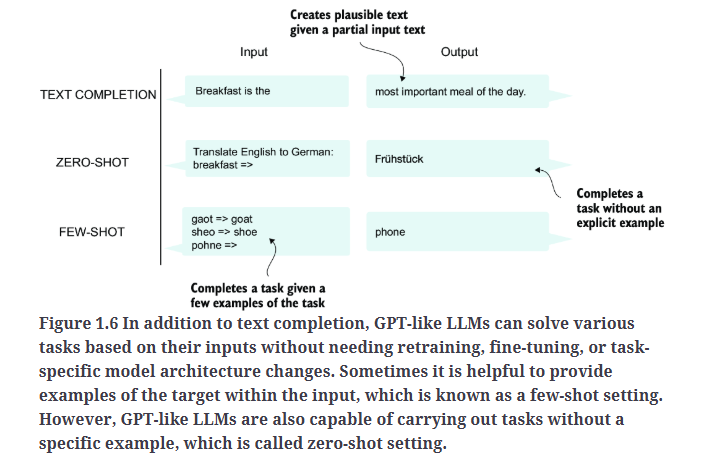
GPT系列模型擅长zero-shot learning和few-shot learning,如Fig1.6所示。
- zero-shot learning:指模型能够在完全未见过的任务上进行泛化,无需任何特定示例。
- few-shot learning:指模型能够从用户提供的极少量示例中学习,然后执行相应任务。
5.Utilizing large datasets
表1.1列出了GPT-3预训练所使用的数据集。
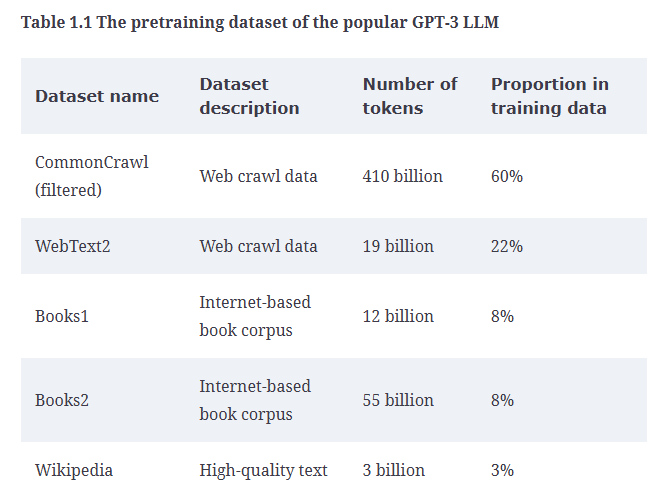
表1.1中的token指的是模型读取的最小文本单位。在数据集中,token的数量大致等同于文本中的单词和标点符号总数。
预训练LLM需要大量计算资源,成本极高,比如,GPT-3的预训练成本约为460万美元。
6.A closer look at the GPT architecture
GPT模型的预训练任务相对简单,仅基于对下一个单词的预测,如Fig1.7所示。

对下一个单词进行预测的任务属于是一种自监督学习(self-supervised learning),本质上是一种自标注(self-labeling)方法。这意味着我们不需要对训练数据进行标注,而是可以利用数据本身的结构:将句子或文档中的下一个单词作为模型要预测的标签。因此可以使用海量的无标签文本数据集来训练LLM。
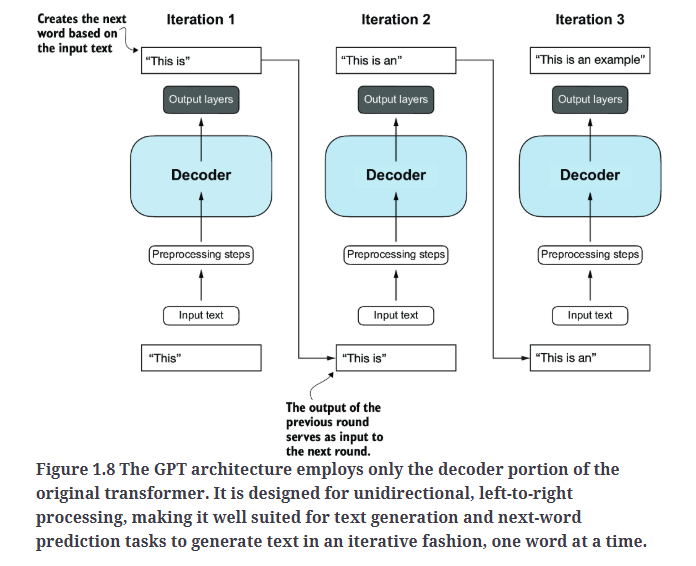
GPT的整体架构仅保留了transformer的解码器,去除了编码器,如Fig1.8所示。这些只用解码器的模型(decoder-style models),比如GPT,是逐词进行预测的,因此,这些模型也被称为自回归模型(autoregressive)。自回归模型会将之前的输出作为输入,用于未来的预测。这种机制增强了生成文本的连贯性。
模型能够执行未经过专门训练的任务,这种现象被称为涌现行为(emergent behavior)。这种能力并非通过显式训练获得,而是由于模型在训练过程中接触到了大量多语言数据,并在不同的语境下学习了语言模式,从而自然地表现出这一能力。GPT模型能够“学习”不同语言之间的翻译模式,并执行翻译任务,即使它们并未专门为此训练,这一点凸显了大型生成式语言模型的强大能力和优势。这意味着,我们可以使用单一模型来完成多种任务,而无需为每项任务训练独立的模型。
7.Building a large language model
我们将按照Fig1.9的步骤构建一个LLM。
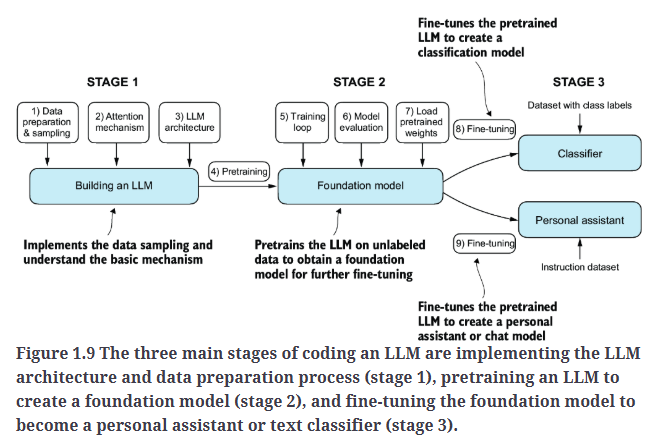
一共分为3个阶段:
- 构建LLM
- pre-train
- fine-tune
