本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
在我们的实验中(见表4),我们发现基于DenseNet的检测器相比基于ResNet的检测器,前者参数量和计算量更小且性能更高。
ResNet和DenseNet之间的主要区别在于它们聚合特征的方式不同。ResNet通过相加的方式聚合来自浅层的特征,这可能会导致浅层的feature map所携带的信息被冲淡。而DenseNet则通过concat的方式进行聚合,使得原始信息得以保留。
然而,我们在实验中也发现,虽然基于DenseNet的检测器在计算量和模型参数量上更少,但其能耗和运行时间却高于基于ResNet的检测器。这是因为除了计算量和模型大小之外,还有其他因素会影响能耗和时间开销。首先,中间feature map在存取过程中的内存访问开销(memory access cost,MAC)是影响能耗和时间的重要因素之一。如Fig1(a)所示,由于DenseNet中采用密集连接的方式,所有前面的feature map都会作为输入传递给后续层,这会导致内存访问开销随着网络深度呈二次方增长,从而带来计算上的额外负担并导致更高的能耗。
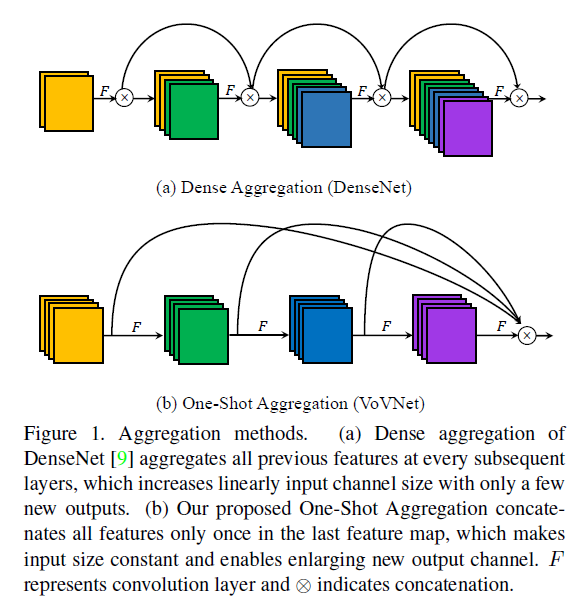
其次,在GPU并行计算方面,DenseNet也存在计算瓶颈的限制。通常情况下,参与计算的张量维度较大时,GPU并行计算的利用率才能最大化。然而,由于DenseNet的输入通道数会线性增长,为了降低输入维度和计算量,DenseNet采用了$1\times 1$卷积的瓶颈结构。这种设计虽然减小了输入尺寸,但也导致网络中具有较小张量维度的层数增加,结果导致GPU计算效率变低。
因此,我们提出了一种新颖的一次性聚合(One-Shot Aggregation,OSA)方法,如Fig1(b)所示,该方法将中间特征一次性进行聚合。这种聚合方式在保留concat优势的同时,大大改善了MAC和GPU计算效率。基于OSA模块,我们提出了VoVNet(Variety of View Network),这是一个面向实时检测任务的高能效backbone网络。
2.Factors of Efficient Network Design
2.1.Memory Access Cost
在CNN中,能耗的主要来源不是计算本身,而是内存访问。具体来说,从DRAM(Dynamic Random Access Memory)中读取操作所需的数据,其能耗要比执行计算高出若干个数量级。此外,内存访问在总体时间消耗中也占据了很大比例,甚至可能成为GPU处理过程的瓶颈。
内存占用的主要来源是filter参数和中间feature map。如果中间feature map较大,即便模型参数量相同,内存访问的成本也会显著增加。因此,我们将MAC视为网络设计中的一个重要因素,因为它同时考虑了filter参数和中间feature map的内存占用情况。MAC的计算方式如下:
\[\text{MAC} = hw(c_i + c_o) + k^2c_i c_o \tag{1}\]$k$是kernel size,$h$和$w$分别表示输入和输出的height和width,$c_i$和$c_o$表示输入和输出的通道数。
2.2.GPU-Computation Efficiency
那些通过减少计算量(FLOPs)来提升速度的网络架构,通常基于这样一个假设:在同一设备上,每一次浮点运算的处理速度是相同的。然而,当网络被部署到GPU上时,这一假设并不成立。这是由于GPU的并行处理机制所导致的。GPU能够同时处理多个浮点运算,因此如何高效地利用其计算能力变得尤为重要。我们将这一概念称为GPU计算效率。
随着待计算的数据张量变大,GPU的并行计算能力能够得到更充分的利用。将一次大的卷积操作拆分为多个零散的小操作会降低GPU的计算效率,因为可并行处理的计算数量减少了。在网络设计的背景下,这意味着如果实现的功能相同,采用更少的网络层数会更优。此外,引入额外的网络层会带来内核启动(kernel launching)和同步(synchronization)等操作,从而产生额外的时间开销。
因此,为了验证网络架构的计算效率,我们引入了每秒浮点运算次数(FLOPs per Second,简写为FLOP/s)这一指标,其计算方式是将模型的总FLOPs除以实际的GPU推理时间。较高的FLOP/s意味着该架构能够更高效的利用GPU的计算能力。
3.Proposed Method
3.1.Rethinking Dense Connection
首先,密集连接会引起较高的内存访问开销,这会带来额外的能耗和运行时间。对于一个卷积层,在给定计算量$B$的情况下,MAC存在一个理论下界:
\[\text{MAC} \geqslant 2 \sqrt{\frac{hwB}{k^2}} + \frac{B}{hw}, \quad B = k^2 hw c_i c_o\]当输入通道数和输出通道数相等时,MAC达到这个理论下界。然而,在DenseNet中,由于密集连接不断增加输入通道数,而输出通道数保持不变,导致每一层的输入和输出通道数严重不平衡。因此,在计算量或参数量相同的情况下,DenseNet的MAC高于其他模型,从而消耗更多的能耗和运行时间。
其次,DenseNet引入了瓶颈结构,通过增加$1\times 1$卷积层来保持$3\times 3$卷积层的输入通道数不变。虽然这种设计可以减少FLOPs和参数量,但它也降低了GPU并行计算的效率。瓶颈结构将一个$3\times 3$卷积操作拆分成两个较小的层,导致更多的顺序计算,从而降低了推理速度。
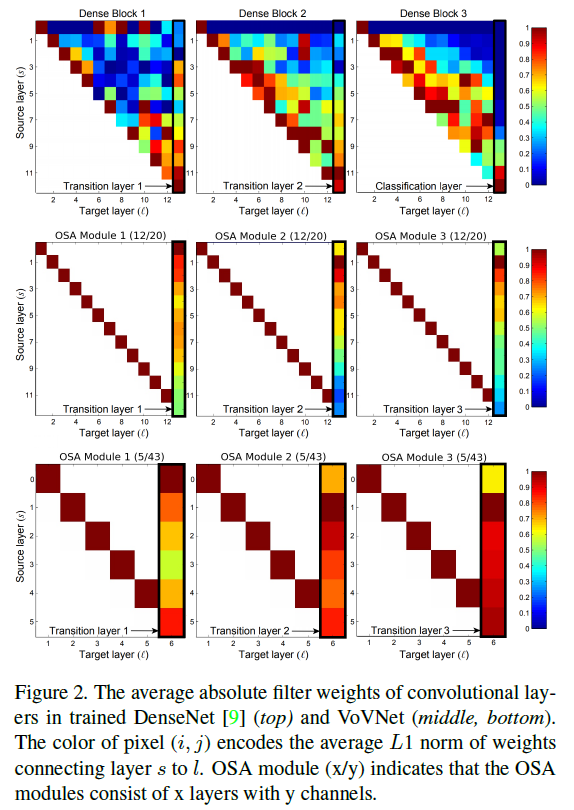
在Fig2中,图中的数值反映了每个前置层对当前层的相对影响程度。
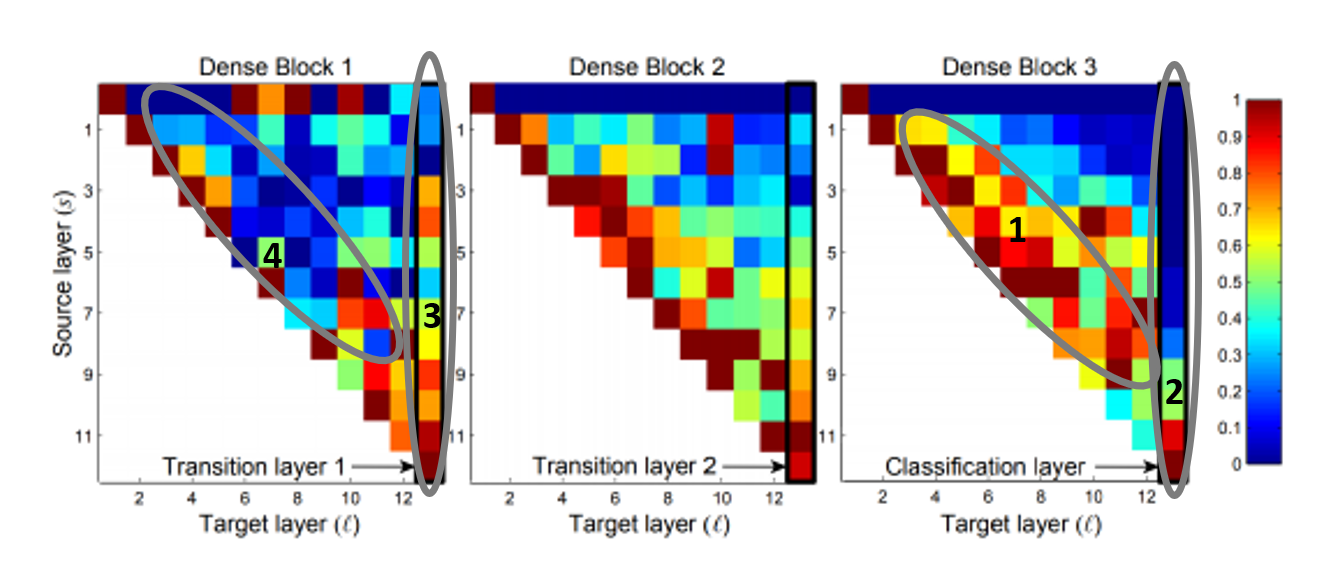
我们先来分析Fig2(top),如上所示,在Dense Block 3中,区域1整体呈现红色,说明中间的多数层都很好的受到了之前层的影响,我们说中间层的聚合是活跃的。而对于分类层,即区域2,仅有一小部分中间特征被实际使用。而在Dense Block 1中,情况却反过来了,transition layer(区域3)很好的聚合了大部分输入特征,而中间层(区域4)整体呈蓝色,说明其聚合不够活跃。
基于上述观察,我们提出一个假设:中间层的聚合强度与最终层的聚合强度之间是负相关的。如果中间层的聚合强度高,那么较后的中间层生成的特征质量就会更高,但也会和之前层的特征非常相似,在这种情况下,最终层就没必要从太之前的层学习了,只从较后的层学习即可,因此导致前面的中间层对最终层的影响变小。
由于最终层会聚合所有中间层的特征来生成最终特征,因此,生成彼此互补或相关性较低的中间特征将更加有效。为了验证这一想法,我们设计了OSA模块,该模块仅在每个block的最终层对其中间特征进行聚合。
3.2.One-Shot Aggregation
如Fig1(b)所示,在OSA模块中,每个卷积层都有两个路径,一个是将特征传递给下一个卷积层,另一个是其输出将在最后被聚合一次。与DenseNet的不同之处在于,每一层的输出不会再传递给所有后续的中间层,从而使中间层的输入通道数保持不变。
为了验证我们的两个假设:1)中间层的聚合强度与最终层的聚合强度之间是负相关的;2)密集连接在中间层是冗余的。我们将OSA模块的参数量和计算量设计的与DenseNet-40中使用的dense block相当。首先,我们研究了与dense block层数相同(均为12层)的OSA模块的实验结果,见Fig2(middle)。从图中可以看出,随着中间层的密集连接被移除,最终层的聚合变得更活跃。此外,在CIFAR-10图像分类任务上,采用OSA模块的网络获得了93.6%的准确率,虽然相比DenseNet略微下降了1.2%,但仍然高于参数规模相近的ResNet。
此外,OSA模块中transition layer的权重分布模式也与DenseNet明显不同。浅层的特征在transition layer中被聚合得更多,反而深层的特征对transition layer的影响较弱。因此,我们可以在不显著影响性能的前提下减少层数。基于此,我们重新配置了OSA模块,使其只包含5层,每层有43个通道,结果如Fig2(bottom)所示。使用该模块后,我们实现了5.44%的错误率,与DenseNet-40的5.24%相当。
尽管采用OSA模块的网络在CIFAR-10上的性能略有下降,但这并不意味着它在检测任务中也会表现不佳。同时,相较于使用dense block的网络,OSA模块的MAC大幅减少。根据式(1)计算,将DenseNet-40中的dense block替换为包含5层、每层43个通道的OSA模块后,MAC从3.7M降低至2.5M。这是因为OSA模块中的中间层具有相同的输入和输出通道数,从而使MAC达到理论下界。这意味着,如果能耗和运行时间的主要瓶颈在于MAC,那么我们就可以构建出更快且更节能的网络。
此外,OSA模块还提升了GPU的计算效率。由于OSA模块中各个中间层的输入尺寸保持不变,因此无需额外引入$1 \times 1$卷积这样的瓶颈结构来降低维度。另外,由于OSA模块聚合的是浅层特征,其整体层数也更少。因此,OSA模块只包含少量可以在GPU上高效计算的层,从而进一步提升了计算效率。
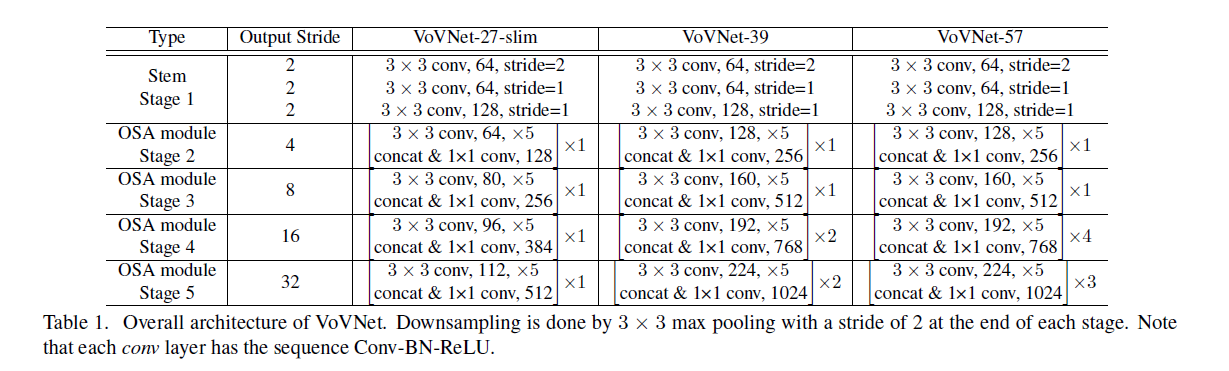
3.3.Configuration of VoVNet
4.Experiments
4.1.Experimental setup
👉Speed Measurement.
为了公平比较模型的推理速度,我们在同一台GPU工作站上对所有模型进行了测试。配置为TITAN X GPU(Pascal架构)、CUDA v9.2和cuDNN v7.3。
👉Energy Consumption Measurement.
使用nvidia-smi监测GPU的能耗,每100毫秒采样一次,并计算能耗的平均值。每张图像的能耗通过下式进行计算:
此外,我们还测量了模型的总内存使用情况。
4.2.DSOD
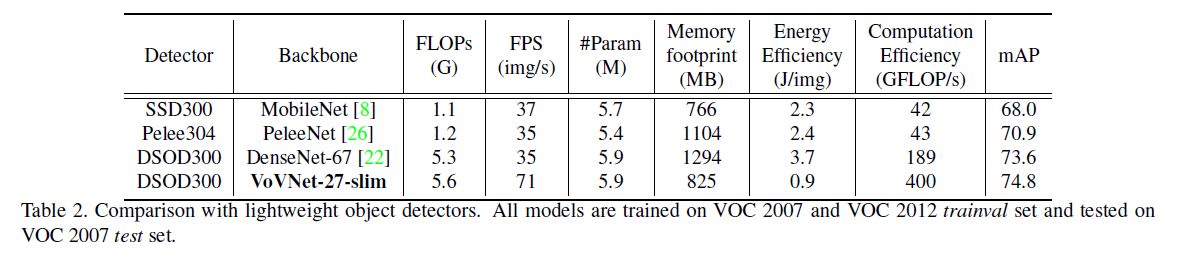
为了验证backbone部分的有效性,我们将DSOD中的DenseNet-67替换为了VoVNet-27-slim,其他设置均保持不变。
👉VoVNet vs. DenseNet.
👉Ablation study on 1×1 conv bottleneck.
为了评估$1 \times 1$卷积瓶颈对模型效率的影响,我们进行了一个消融实验,在OSA模块中每个$3 \times 3$卷积操作前添加一个$1 \times 1$卷积层,其通道数为输入通道数的一半。实验结果见表3。

👉GPU-Computation Efficiency.
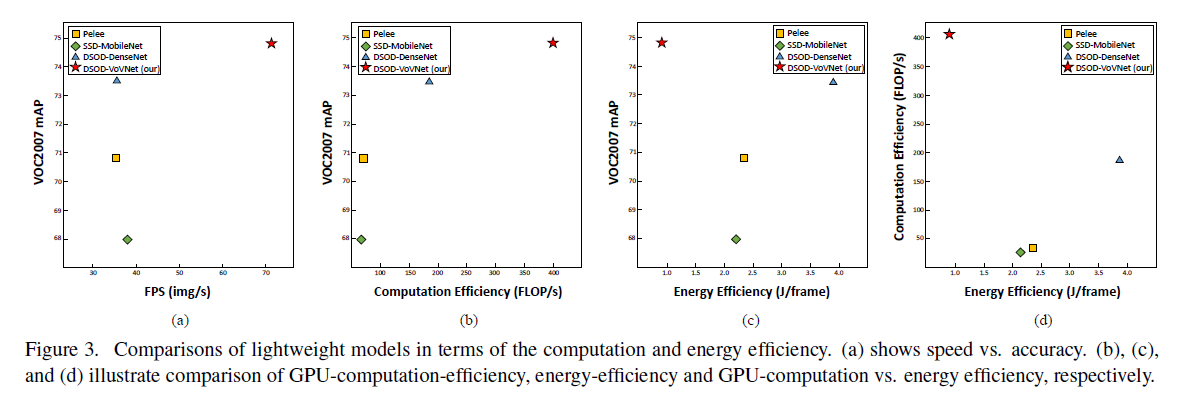
见Fig3(a)和Fig3(b)。
👉Energy Efficiency.
见表2、Fig3(c)和Fig3(d)。
4.3.RefineDet
为了公平比较,我们直接将VoVNet-39/57插入到RefineDet中,并采用相同的超参数和训练策略。具体来说,我们将RefineDet320训练了400k次迭代,batch size为32,初始学习率为0.001,并在第280k和第360k次迭代时分别将学习率乘以0.1。

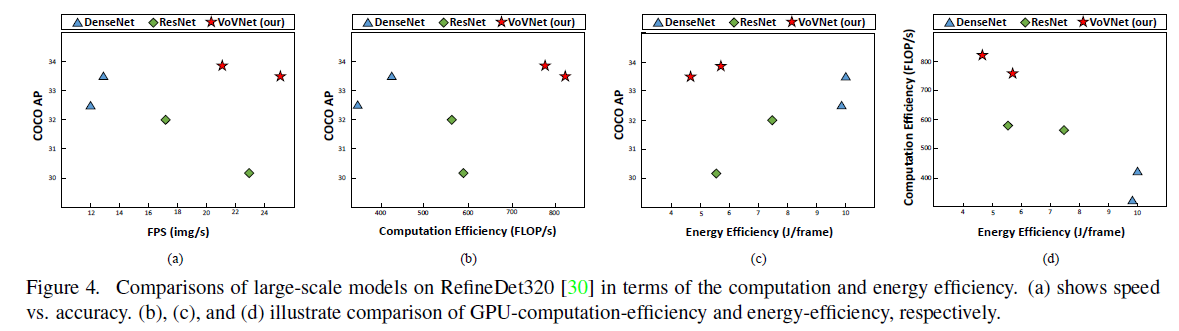
从表4可以看到,VoVNet和DenseNet在小目标和中等目标上的效果要优于ResNet,这说明concat这种聚合特征的方式有利于小目标检测。此外,VoVNet在小目标和中等目标上的效果比DenseNet还要好,进一步说明了OSA模块生成的特征更有利于小目标检测。
4.4.Mask R-CNN from scratch

5.Conclusion
不再赘述。
6.Appendix A: Experiments on RefineDet512
为了在更大输入尺寸上进行测试,我们使用和RefineDet512(backnone为ResNet101)相同的超参数和训练策略,在COCO数据集上训练了基于VoVNet-39/57的RefineDet512。具体来说,batch size为20,初始学习率为$10^{-3}$,使用初始学习率训练400k次迭代,然后将学习率降为$10^{-4}$再训练80k次迭代,再然后将学习率降为$10^{-5}$再训练60k次迭代。需要注意的是,在4块32GB的NVIDIA V100 GPU上,基于DenseNet-201/161的RefineDet512由于过高的MAC而无法完成训练。


在表7中,如果将batch size增加到32,在训练时,将初始学习率设为$10^{-3}$,一共训练400k次迭代,在第280k次和第360k次迭代时将学习率乘以0.1。需要注意的是,当batch size为32时,基于ResNet101的RefineDet512由于过高的MAC而无法完成训练。
7.Appendix B: Qualitative comparisons

在Fig5中,只有置信度高于0.6的bbox被绘制。
8.原文链接
👽An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
