本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
源码:https://github.com/WongKinYiu/yolor。
个人感觉整篇文章写的有点云里雾里的,有困惑的同学可以直接跳到Appendix部分查看清晰的网络框架图。

如Fig1所示,根据一张图片,人类可以回答多个不同的问题。但对于一个训练好的CNN来说,其通常只能完成一种任务,一般来说,从训练好的CNN中提取的特征往往难以适应其他类型的任务。造成这一问题的原因在于我们仅从神经元中提取特征,而CNN中大量存在的隐性知识(implicit knowledge)并未被利用。而在真实的人脑中,上述隐性知识则可以有效地辅助大脑完成各种任务。
隐性知识是指在潜意识状态下习得的知识。然而,目前尚未有系统的定义来说明隐性学习是如何运作的,以及如何获取隐性知识。在神经网络的一般定义中,从浅层提取的特征通常被称为显性知识(explicit knowledge),而从深层提取的特征被称为隐性知识。在本文中,我们将直接与观察结果相对应的知识称为显性知识;而模型中隐含的、与观察无关的知识,我们称之为隐性知识。
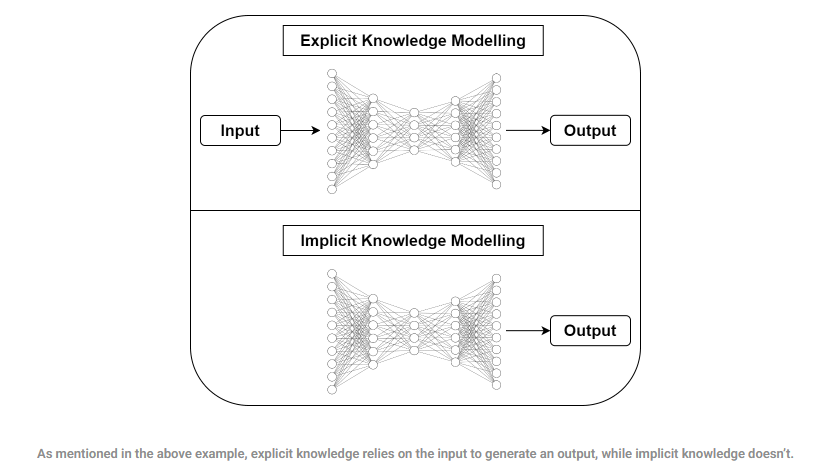
- 显性知识建模:以输入为基础生成输出,依赖于当前输入信息。
- 隐性知识建模:不依赖输入,而是利用模型内部已存的知识结构进行推理。
我们提出了一种统一网络(a unified network),用于整合隐性知识和显性知识,使得所学习到的模型能够包含一种通用表示(a general representation)。而这种通用表示又能够生成适用于多种任务的子表示(sub-representations)。Fig2(c)展示了我们所提出的统一网络架构。
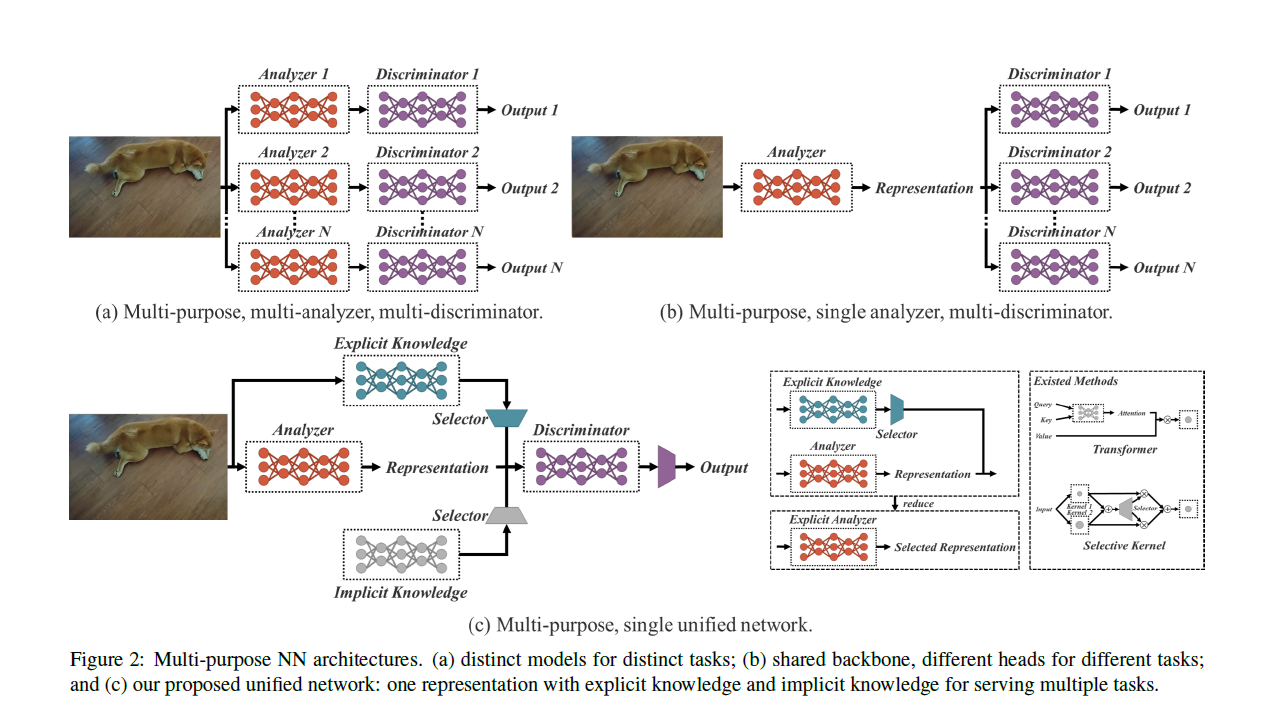
构建上述统一网络的方法是将压缩感知(compressive sensing)与深度学习相结合。本工作的贡献如下:
- 我们提出了一种统一的网络,可以完成多种任务。该网络通过整合隐性知识和显性知识来学习一种通用表示,并能够通过这种通用表示完成多种任务。所提出的网络在仅带来极小额外代价(参数量和计算量少于万分之一)的情况下,有效提升了模型的性能。
- 我们在隐性知识的学习过程中引入了核空间对齐(kernel space alignment)、预测优化(prediction refinement)和多任务学习(multi-task learning),并验证了它们的有效性。
- 我们分别探讨了使用向量(vector)、神经网络(neural network)或矩阵分解(matrix factorization)来建模隐性知识的方法,并同时验证了其有效性。
- 我们验证了所提出的隐性表示学习(implicit representation learned)能够准确对应于某种具体的物理特征,并以可视化的方式进行了展示。我们还确认,如果采用符合目标物理意义的算子(operators),则可以用于融合隐性知识与显性知识,并产生协同增效的效果。
- 结合SOTA的方法,我们所提出的统一网络在目标检测任务上达到了与Scaled-YOLOv4-P7相当的准确率,同时将推理速度提升了88%。
2.Related work
不再详述。
3.How implicit knowledge works?
我们的主要目的是构建一个能够有效训练隐性知识的统一网络,因此我们首先关注的是如何训练隐性知识,并在后续过程中快速推理。由于隐性表示(implicit representation)$z_i$与观察无关,我们可以将其看作一组常量张量$Z=\{z_1,z_2,…, z_k\}$。在本部分,我们将介绍如何将隐性知识作为常量张量(constant tensor)应用于各种任务。
3.1.Manifold space reduction
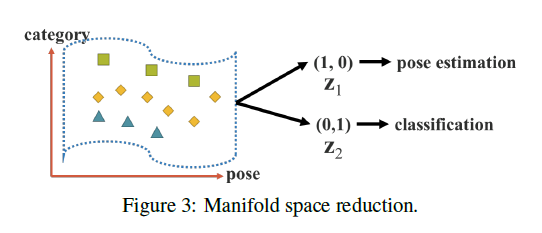
通用表示我们可以理解为就是网络输出的一个张量,每个输入都有自己的通用表示。将一组常量张量(即隐性知识)理解为一种任务,另一组常量张量理解为另一种任务。如Fig3所示,第一组常量张量$Z_1=(1,0)$,表示姿态估计任务,第二组常量张量$Z_2 = (0,1)$,表示分类任务。如果我们把每个输入的通用表示投影到$Z_1,Z_2$所构成的空间中(投影操作就是内积操作),假设数据的标签为分类任务的标签,此时如果数据可以被超平面成功分类,则是最理想的情况。如果数据是姿态估计任务的标签,依然可以被超平面成功分类,那我们就相当于是实现了利用隐性知识,通过一个统一的通用表示来适配多种不同任务的能力。
3.2.Kernel space alignment
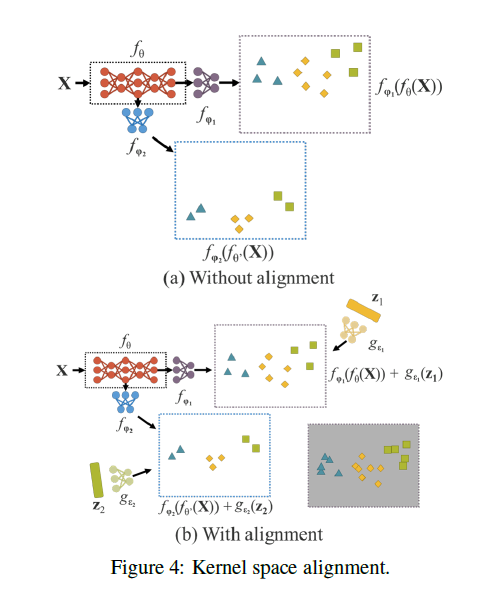
接着第3.1部分,如果我们可以进一步优化投影机制,让最终投影后的数据在不同任务下的空间分布是接近的,那么我们就能用相似的超平面完成对多个任务的成功分类。因此,我们引入核空间对齐。如Fig4(a)所示,$f_{\theta}$可以理解为backbone,$f_{\varphi_1},f_{\varphi_2}$表示用于不同任务的head,其输出的样本空间(即所谓的核空间)分布不一致。在Fig4(b)中,我们利用隐性知识对核空间进行平移、旋转或缩放,从而实现核空间对齐。
3.3.More functions
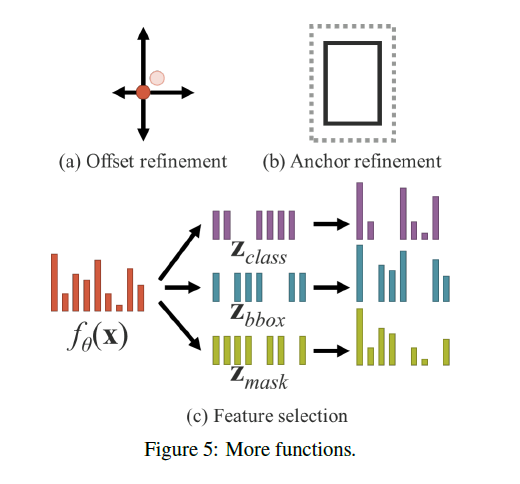
除了可以用于不同任务之外,隐性知识还可以扩展到更多其他功能中。如Fig5所示:
- 在Fig5(a)中,可以将隐性知识加到原始的中心点预测上,对其进行细粒度的位置调整。比如:$\text{refined center} = \text{predicted center} + g(Z_{offset})$。
- 在Fig5(b)中,可以利用乘法,将隐性知识应用于anchor,完成anchor的自适应优化。比如:$\text{refined anchor} = \text{anchor} \times g(Z_{anchor})$。
- 在Fig5(c)中,利用点积和concat,将隐性知识用于多任务特征选择。
4.Implicit knowledge in our unified networks
在本部分,我们将比较传统网络与所提出的统一网络的目标函数,并解释为什么引入隐性知识对训练多任务网络是重要的。同时,我们还将详细阐述所提出方法的具体细节。
4.1.Formulation of implicit knowledge
👉传统网络:
对于传统神经网络的目标函数,可以使用式(1)来表示:
\[y = f_{\theta}(x)+\epsilon \\ \text{minimize} \ \epsilon \tag{1}\]其中,$x$是模型输入,$\theta$是模型参数,$f_{\theta}(x)$表示模型输出,$\epsilon$是误差项,$y$是给定的目标。
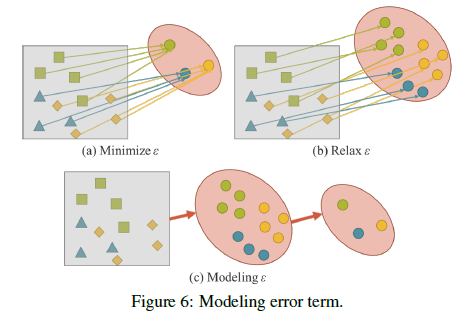
在传统神经网络的训练过程中,我们要最小化误差项$\epsilon$,使得$f_{\theta}(x)$尽可能接近$y$。这意味着,对于有着相同标签的样本,我们希望在$f_{\theta}$输出的子空间中被映射到非常相近的位置,如Fig6(a)所示。这样做的弊端就是模型所学到的解决空间只适用于当前任务$t_i$,而不适用于其他任务$T \backslash t_i$,其中$T=\{ t_1,t_2,…,t_n \}$。
对于一个通用神经网络,我们希望模型学到的表示(representation)可以同时服务于集合$T$中的所有任务。因此,我们需要放宽误差项$\epsilon$,使得可以在同一个流形空间中同时为多个任务找到解,如Fig6(b)所示。然而,这种要求也导致我们无法再使用一些简单的数学方法,比如one-hot向量的最大值或欧氏距离的阈值,来获得单个任务$t_i$的解。为了解决这个问题,我们必须对误差项$\epsilon$进行建模,以便可以为不同的任务找到对应解,如Fig6(c)所示。
👉统一网络:
为了训练我们提出的统一网络,我们使用显性知识和隐性知识来共同建模误差项,并用其引导整个多任务网络的训练过程。目标函数如下:
\[y= f_{\theta}(x)+\epsilon+g_{\phi}(\epsilon_{ex}(x),\epsilon_{im}(z)) \\ \text{minimize} \ \epsilon + g_{\phi}(\epsilon_{ex}(x),\epsilon_{im}(z)) \tag{2}\]其中,$\epsilon_{ex}(x)$表示来自输入的显性误差(explicit error)的建模,$\epsilon_{im}(z)$表示隐性误差(implicit error)的建模。$g_{\phi}$用于组合两种误差信息。
我们也可以将$g_{\phi}$直接融合到$f_{\theta}$中,式(2)就会变成如下式(3)的样子:
\[y=f_{\theta}(x) \star g_{\phi}(z) \tag{3}\]其中,$\star$表示能够将$f_{\theta}(x)$和$g_{\phi}(z)$结合起来的一些可能的操作,比如Fig5中提到的操作。
如果我们将误差项的建模过程扩展到多任务的情形,我们可以得到如下表达式:
\[F(x,\theta,Z,\Phi,Y,\Psi) = 0 \tag{4}\]其中,$Z=\{z_1,z_2,…,z_T\}$表示$T$个不同任务的隐性知识向量。$\Phi$是一组参数,用于从$Z$中生成隐性表示(implicit representation)。$\Psi$用于从显性表示和隐性表示的不同组合中计算最终的输出参数。
对于不同的任务$z \in Z$,我们可以通过如下公式获得预测:
\[d_{\Psi}(f_{\theta}(x),g_{\Phi}(z),y) = 0 \tag{5}\]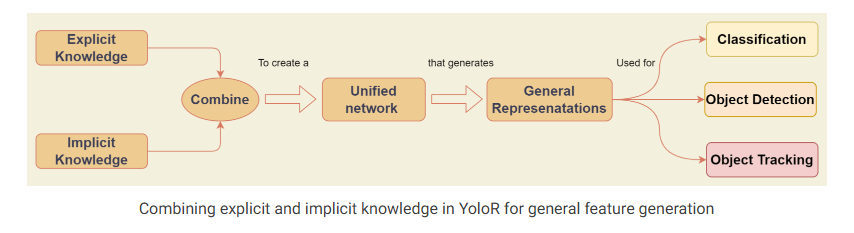
4.2.Modeling implicit knowledge
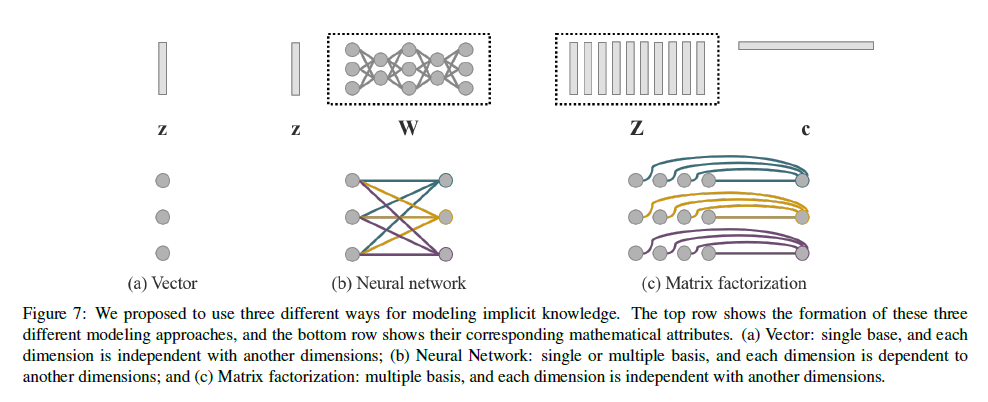
如Fig7所示,我们建议使用如下3种方式对隐性知识进行建模:
方式一:向量/矩阵/张量。
\[z \tag{6}\]使用向量$z$作为隐性知识的先验,并直接作为隐性表示。
方式二:神经网络。
\[Wz \tag{7}\]使用向量$z$作为隐性知识的先验,然后使用权重矩阵$W$执行线性组合或非线性转换,从而得到隐性表示。
方式三:矩阵分解。
\[Z^T c \tag{8}\]使用多个向量作为隐性知识的先验基础,这些隐性先验向量构成矩阵$Z$,系数向量$c$则与之结合,形成最终的隐性表示。
4.3.Training
假设我们的模型在初始时没有任何先验的隐性知识,也就是说,它对显性表示$f_{\theta}(x)$没有任何影响。如果式(3)中的组合操作$\star$属于加法或concat,则初始化隐性先验$z \sim N(0,\sigma)$,如果$\star$属于乘法,则初始化隐性先验$z \sim N(1,\sigma)$。此处,$\sigma$是一个非常小的值,接近于0。对于$z$和$\phi$,它们都会在训练过程中随着反向传播而被更新。
4.4.Inference
由于隐性知识与输入$x$无关,因此无论隐性建模$g_{\phi}$多么复杂,它都可以在推理阶段被简化为一组常量张量。换句话说,隐性信息几乎不会对算法的计算复杂度造成影响。此外,当组合操作属于乘法,且后续层是卷积层时,我们可以用式(9)进行融合。如果组合操作属于加法,前一层是卷积层且没有激活函数时,可使用式(10)进行融合。
\[\begin{align} x_{(l+1)} &= \sigma(W_l(g_{\phi}(z)x_l)+b_l) \\&= \sigma(W'_l(x_l)+b_l), \text{ where } W'_l=W_lg_{\phi}(z) \end{align} \tag{9}\] \[\begin{align} x_{(l+1)} &= W_l(x_l) + b_l + g_{\phi}(z) \\&= W_l (x_l) + b'_l, \text{ where } b'_l = b_l + g_{\phi}(z) \end{align} \tag{10}\]个人理解:隐性知识在训练阶段就训练好了,推理阶段直接用就行,就像人类的经验一样,不再依赖输入。
5.Experiments
实验使用MSCOCO数据集。
5.1.Experimental setup
我们将隐性知识应用在3个方面:
- feature alignment for FPN:FPN的特征对齐。
- prediction refinement:预测结果的refine。
- multi-task learning in a single model:单个模型的多任务学习。其中,多任务包括目标检测、多标签图像分类和特征嵌入。
使用YOLOv4-CSP作为baseline模型,并在Fig8中箭头所指的位置引入隐性知识。所有训练超参数和Scaled-YOLOv4的默认设置保持一致。
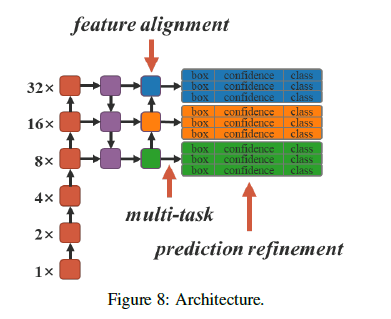
5.2.Feature alignment for FPN

YOLOv4-CSP-fast的详细介绍可见Appendix。
5.3.Prediction refinement for object detection

5.4.Canonical representation for multitask
当我们希望训练一个可以同时用于多任务的模型时,由于损失函数的联合优化(joint optimization)过程必须执行,不同任务之间在训练过程中往往会相互“拉扯”,这会导致最终的整体性能反而不如分别训练多个模型后再集成的方式。为了解决上述问题,我们提出为多任务训练一个标准表示(canonical representation)的思路。具体来说,我们的方法是通过将隐性表示(implicit representation)引入到每个任务分支中,以增强模型的表达能力。其效果列在了表3中。
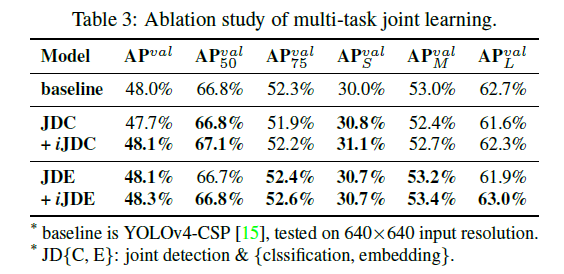
5.5.Implicit modeling with different operators

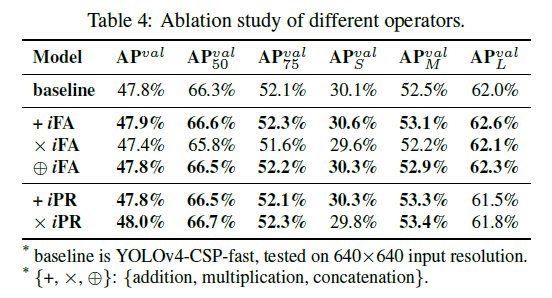
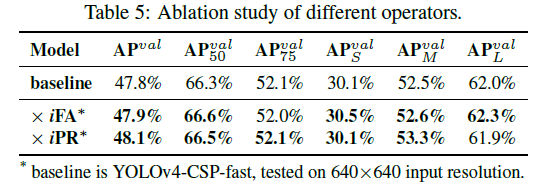
5.6.Modeling implicit knowledge in different ways

5.7.Analysis of implicit models
我们分析了在有无隐性知识的情况下,模型的参数数量、FLOPs以及训练过程,结果见表7和Fig11。从实验数据可以看出,引入隐性知识,我们的参数量和计算量仅增加了不到万分之一,但却能显著提升模型的性能,同时训练过程也能够更快且更准确的收敛。

YOLOv4-P6-light的详细介绍见Appendix。
5.8.Implicit knowledge for object detection
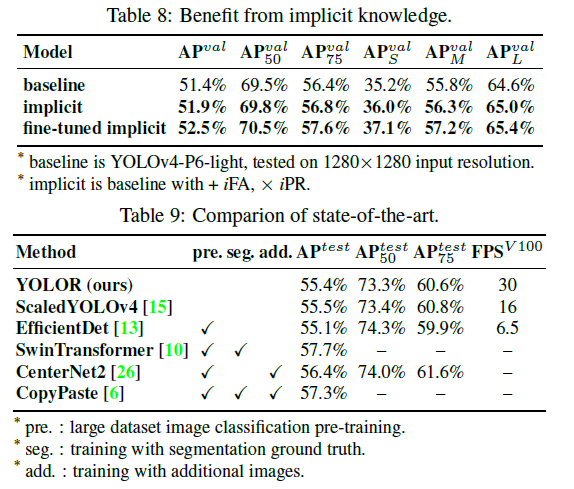
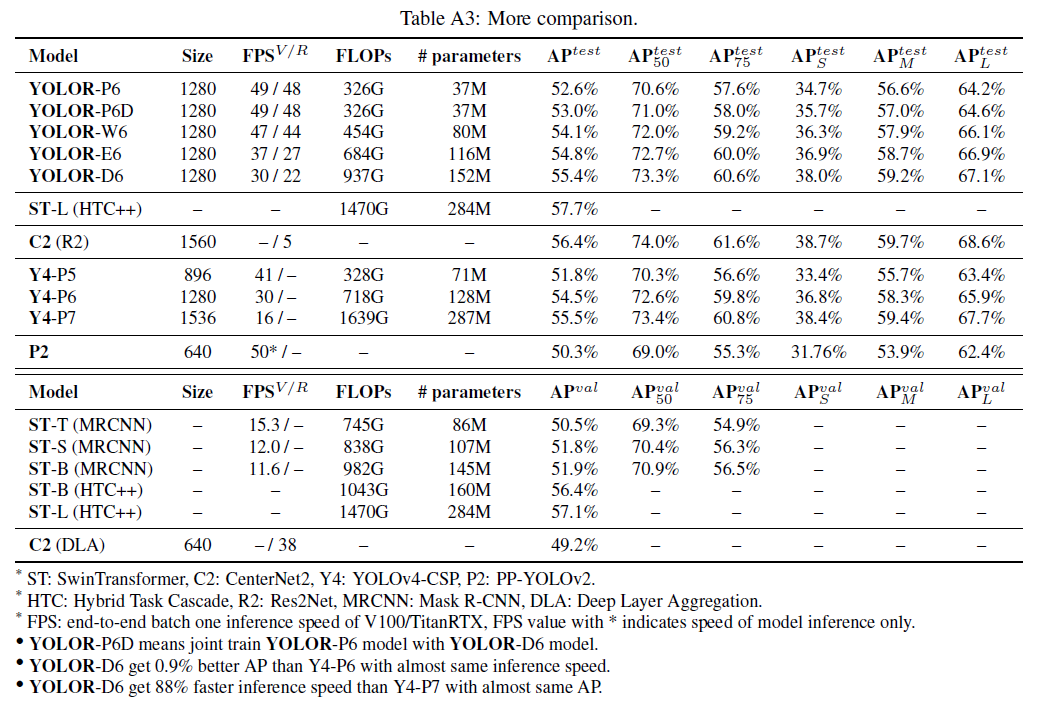
最后,我们将所提出的方法与SOTA的目标检测方法进行了对比,结果见表8。整个训练过程中,我们遵循了scaled-YOLOv4的训练流程,即先从头开始训练300个epoch,然后再fine-tune 150个epoch。值得注意的是,我们提出的方法并没有使用额外的训练数据和标注,仅通过引入隐性知识,就达到了SOTA的效果。
6.Conclusions
未来的工作是将训练扩展到多模态和多任务场景,如Fig12所示。

7.Appendix
用到了4种下采样方式,见Fig.A1:

Fig.A1(a)是离散小波变换。
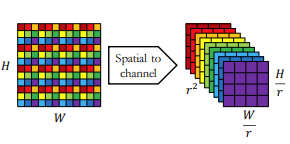
用下面这张图理解Fig.A1(b),即ReOrg:
用Fig.A1中的4种下采样方式构建了不同的stem block,见下:
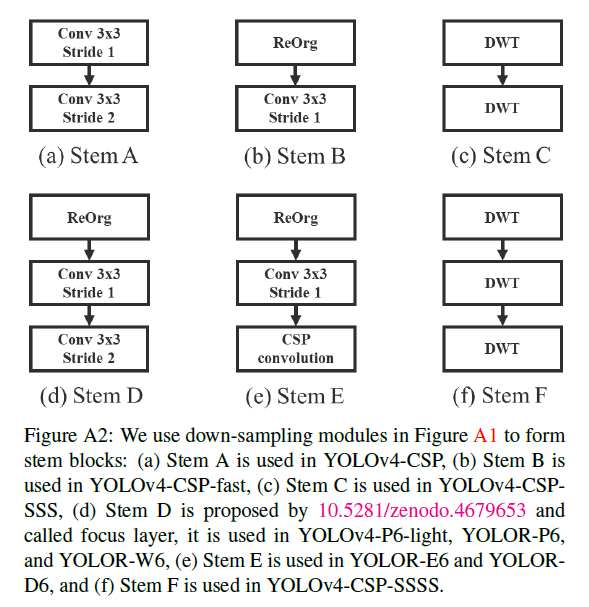
- Stem A用于YOLOv4-CSP。
- Stem B用于YOLOv4-CSP-fast。
- Stem C用于YOLOv4-CSP-SSS。
- Stem D,也称为focus layer,用于YOLOv4-P6-light、YOLOR-P6和YOLOR-W6。
- Stem E用于YOLOR-E6和YOLOR-D6。
- Stem F用于YOLOv4-CSP-SSSS。
本文涉及的模型可以映射为3到4种架构拓扑结构。由于Stem C\D\E包含两个下采样模块,因此使用这些stem block的模型在backbone中没有Stage B1;出于相同的原因,使用Stem F的模型则没有Stage B1和B2。具体如Fig.A3所示。

- YOLOv4-CSP属于拓扑结构1。
- 把YOLOv4-CSP中的Stem A换成Stem B,就得到了YOLOv4-CSP-fast。
- YOLOv4-CSP-SSS属于拓扑结构2,其Stage B2之后的拓扑结构和YOLOv4-CSP一样,width缩放因子和depth缩放因子分别设置为0.5和0.33。此外,还将所有的Mish激活函数换成了SiLU激活函数。
- YOLOv4-CSP-SSSS是在YOLOv4-CSP-SSS的基础上修改的。YOLOv4-CSP-SSSS将YOLOv4-CSP-SSS中的Stem C替换为了Stem F。由于stem block包含三个下采样模块,所以YOLOv4-CSP-SSSS属于拓扑结构4。
-
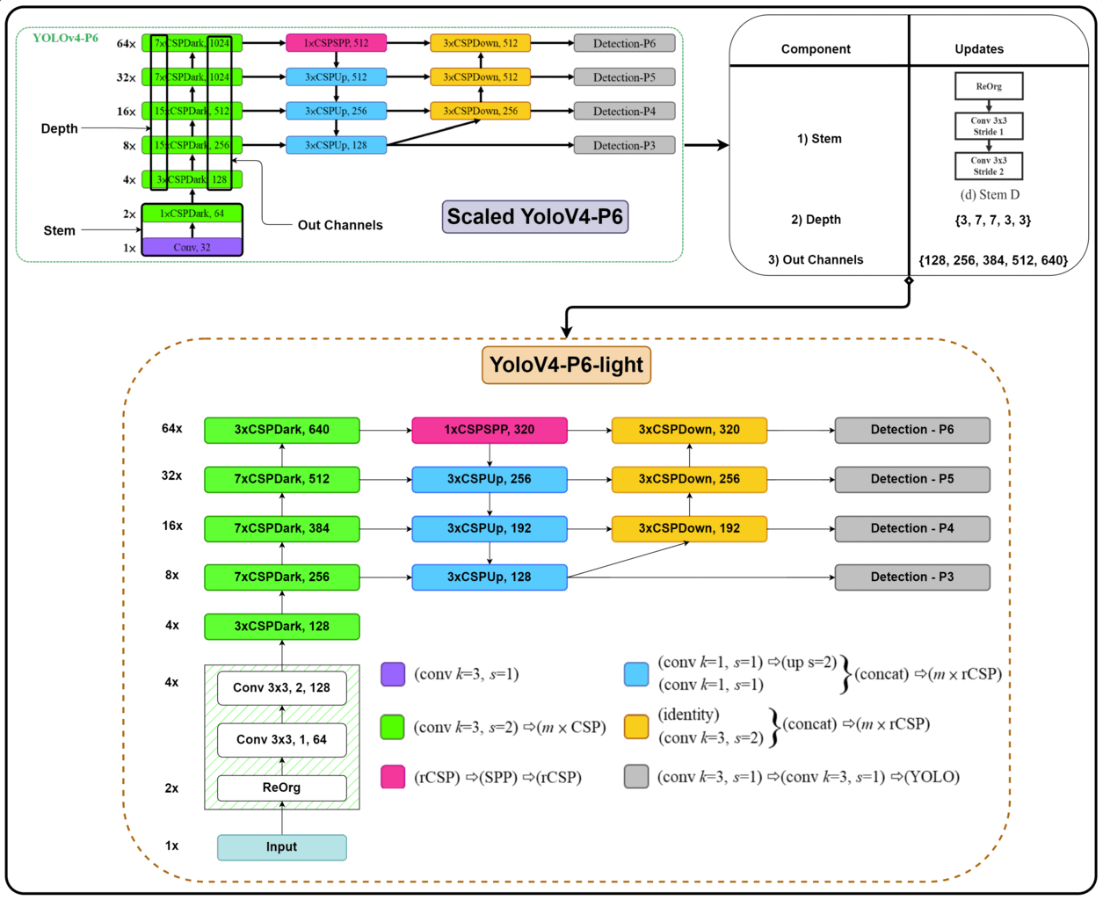
YOLOv4-P6-light属于拓扑结构3,使用Stem D,详细结构见下图:
-
由YOLOv4-P6-light进化得到一系列模型:YOLOR-P6、YOLOR-W6、YOLOR-E6和YOLOR-D6。

其中,YOLOR-P6的详细结构见下:
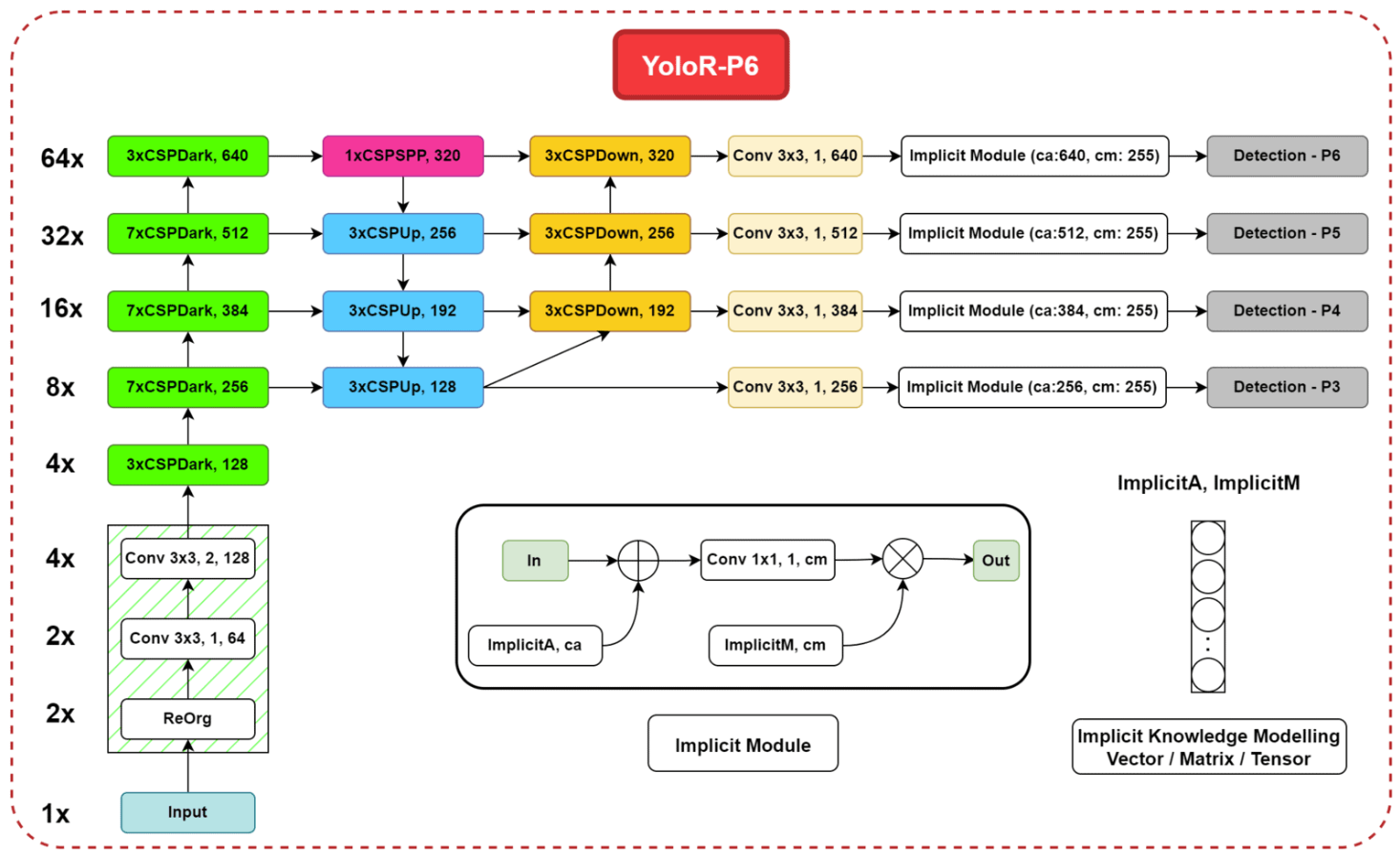
可以看到YOLOR-P6中有4个隐性模块,每个隐性模块中都用到了2个隐性表示:ImplicitA和ImplicitM。ImplicitA通过加法进行融合,ImplicitM通过乘法融合。ImplicitA和ImplicitM在训练阶段被训练完之后,在推理阶段就不再变化了。
8.原文链接
👽You Only Learn One Representation:Unified Network for Multiple Tasks
