【机器学习基础】系列博客为参考周志华老师的《机器学习》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.近似推断
精确推断方法通常需要很大的计算开销,因此在现实应用中近似推断方法更为常用。近似推断方法大致可分为两大类:第一类是采样(sampling),通过使用随机化方法完成近似;第二类是使用确定性近似完成近似推断,典型代表为变分推断(variational inference)。
本章内容没太理解,仅作记录。
2.MCMC采样
在很多任务中,我们关心某些概率分布并非因为对这些概率分布本身感兴趣,而是要基于它们计算某些期望,并且还可能进一步基于这些期望做出决策。例如对图14.7(a)的贝叶斯网,进行推断的目的可能是为了计算变量$x_5$的期望。若直接计算或逼近这个期望比推断概率分布更容易,则直接操作无疑将使推断问题的求解更为高效。
采样法正是基于这个思路。具体来说,假定我们的目标是计算函数$f(x)$在概率密度函数$p(x)$下的期望:
\[\mathbb{E}_p [f] = \int f(x) p(x) dx \tag{1}\]若$x$是离散变量,则把积分换做求和即可。
则可根据$p(x)$抽取一组样本$\{ x_1,x_2,…,x_N \}$,然后计算$f(x)$在这些样本上的均值:
\[\hat{f} = \frac{1}{N} \sum_{i=1}^N f(x_i) \tag{2}\]以此来近似目标期望$\mathbb{E}[f]$。若样本$\{ x_1,x_2,…,x_N \}$独立,基于大数定律,这种通过大量采样的办法就能获得较高的近似精度。问题的关键是如何采样。对概率图模型来说,就是如何高效地基于图模型所描述的概率分布来获取样本。
概率图模型中最常用的采样技术是马尔可夫链蒙特卡罗(Markov Chain Monte Carlo,简称MCMC)方法。给定连续变量$x \in X$的概率密度函数$p(x)$,$x$在区间$A$中的概率可计算为:
\[P(A) = \int _A p(x) dx \tag{3}\]若有函数$f:X\to \mathbb{R}$,则可计算$f(x)$的期望:
\[p(f) = \mathbb{E}_p [f(X)] = \int _x f(x) p(x) dx \tag{4}\]若$x$不是单变量而是一个高维多元变量$\mathbf{x}$,且服从一个非常复杂的分布,则对式(4)求积分通常很困难。为此,MCMC先构造出服从$p$分布的独立同分布随机变量$\mathbf{x}_1,\mathbf{x}_2,…,\mathbf{x}_N$,再得到式(4)的无偏估计:
\[\tilde{p}(f) = \frac{1}{N} \sum_{i=1}^N f(\mathbf{x}_i) \tag{5}\]然而,若概率密度函数$p(\mathbf{x})$很复杂,则构造服从$p$分布的独立同分布样本也很困难。MCMC方法的关键就在于通过构造“平稳分布为$p$的马尔可夫链”来产生样本:若马尔可夫链运行时间足够长(即收敛到平稳状态),则此时产出的样本$\mathbf{x}$近似服从于分布$p$。如何判断马尔可夫链到达平稳状态呢?假定平稳马尔可夫链$T$的状态转移概率(即从状态$\mathbf{x}$转移到状态$\mathbf{x}’$的概率)为$T(\mathbf{x}’ \mid \mathbf{x})$,$t$时刻状态的分布为$p(\mathbf{x}^t)$,则若在某个时刻马尔可夫链满足平稳条件:
\[p(\mathbf{x}^t)T(\mathbf{x}^{t-1} \mid \mathbf{x}^t) = p(\mathbf{x}^{t-1}) T (\mathbf{x}^t \mid \mathbf{x}^{t-1}) \tag{6}\]则$p(x)$是该马尔可夫链的平稳分布,且马尔可夫链在满足该条件时已收敛到平稳状态。
也就是说,MCMC方法先设法构造一条马尔可夫链,使其收敛至平稳分布恰为待估计参数的后验分布,然后通过这条马尔可夫链来产生符合后验分布的样本,并基于这些样本来进行估计。这里马尔可夫链转移概率的构造至关重要,不同的构造方法将产生不同的MCMC算法。
Metropolis-Hastings(简称MH)算法是MCMC的重要代表。它基于“拒绝采样”(reject sampling)来逼近平稳分布$p$。如图14.9所示,算法每次根据上一轮采样结果$\mathbf{x}^{t-1}$来采样获得候选状态样本$\mathbf{x}^{*}$,但这个候选样本会以一定的概率被“拒绝”掉。假定从状态$\mathbf{x}^{t-1}$到状态$\mathbf{x}^{*}$的转移概率为$Q(\mathbf{x}^{*} \mid \mathbf{x}^{t-1}) A (\mathbf{x}^{*} \mid \mathbf{x}^{t-1})$,其中$Q(\mathbf{x}^{*} \mid \mathbf{x}^{t-1})$是用户给定的先验概率,$A(\mathbf{x}^{*} \mid \mathbf{x}^{t-1})$是$\mathbf{x}^{*}$被接受的概率。若$\mathbf{x}^{*}$最终收敛到平稳状态,则根据式(6)有:
\[p(\mathbf{x}^{t-1})Q(\mathbf{x}^* \mid \mathbf{x}^{t-1}) A (\mathbf{x}^* \mid \mathbf{x}^{t-1})= p(\mathbf{x}^*)Q(\mathbf{x}^{t-1} \mid \mathbf{x}^*) A (\mathbf{x}^{t-1} \mid \mathbf{x}^*) \tag{7}\]
重复足够多次以达到平稳分布。
实践中常会丢弃前面若干个样本,因为达到平稳分布后产生的才是希望得到的样本。
于是,为了达到平稳状态,只需将接受率设置为:
\[A(\mathbf{x}^* \mid \mathbf{x}^{t-1}) = \min \left( 1,\frac{p(\mathbf{x}^*)Q(\mathbf{x}^{t-1} \mid \mathbf{x}^*)}{p(\mathbf{x}^{t-1})Q(\mathbf{x}^* \mid \mathbf{x}^{t-1})} \right) \tag{8}\]吉布斯采样(Gibbs sampling)有时被视为MH算法的特例,它也使用马尔可夫链获取样本,而该马尔可夫链的平稳分布也是采样的目标分布$p(\mathbf{x})$。具体来说,假定$\mathbf{x} = \{ x_1,x_2,…,x_N \}$,目标分布为$p(\mathbf{x})$,在初始化$\mathbf{x}$的取值后,通过循环执行以下步骤来完成采样:
- 随机或以某个次序选取某变量$x_i$;
- 根据$\mathbf{x}$中除$x_i$外的变量的现有取值,计算条件概率$p(x_i \mid \mathbf{x}_{\bar{i}})$,其中$\mathbf{x}_{\bar{i}} = \{ x_1,x_2,…,x_{i-1},x_{i+1},…,x_N \}$;
- 根据$p(x_i \mid \mathbf{x}_{\bar{i}})$对变量$x_i$采样,用采样值代替原值。
3.变分推断
变分推断通过使用已知简单分布来逼近需推断的复杂分布,并通过限制近似分布的类型,从而得到一种局部最优、但具有确定解的近似后验分布。
在学习变分推断之前,我们先介绍概率图模型一种简洁的表示方法——盘式记法(plate notation)。图14.10给出了一个简单的例子。图14.10(a)表示$N$个变量$\{ x_1,x_2,…,x_N \}$均依赖于其他变量$\mathbf{z}$。在图14.10(b)中,相互独立的、由相同机制生成的多个变量被放在一个方框(盘)内,并在方框中标出类似变量重复出现的个数$N$;方框可以嵌套。通常用阴影标注出已知的、能观察到的变量,如图14.10中的变量$x$。在很多学习任务中,对属性变量使用盘式记法将使得图表示非常简洁。
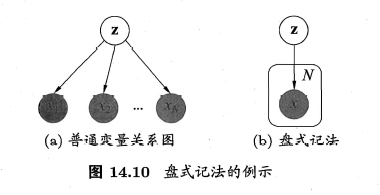
在图14.10(b)中,所有能观察到的变量$x$的联合分布的概率密度函数是:
\[p(\mathbf{x} \mid \Theta) = \prod _{i=1}^N \sum_{\mathbf{z}} p(x_i,\mathbf{z} \mid \Theta) \tag{9}\]变分推断使用的近似分布需具有良好的数值性质,通常是基于连续型变量的概率密度函数来刻画的。
所对应的对数似然函数为:
\[\ln p(\mathbf{x} \mid \Theta) = \sum_{i=1}^N \ln \left\{ \sum_{\mathbf{z}} p (x_i,\mathbf{z} \mid \Theta) \right\} \tag{10}\]其中$\mathbf{x} = \{ x_1,x_2,…,x_N \}$,$\Theta$是$\mathbf{x}$与$\mathbf{z}$服从的分布参数。
一般来说,图14.10所对应的推断和学习任务主要是由观察到的变量$\mathbf{x}$来估计隐变量$\mathbf{z}$和分布参数变量$\Theta$,即求解$p(\mathbf{z} \mid \mathbf{x},\Theta)$和$\Theta$。
概率模型的参数估计通常以最大化对数似然函数为手段。对式(10)可使用EM算法:在E步,根据$t$时刻的参数$\Theta ^t$对$p(\mathbf{z} \mid \mathbf{x},\Theta ^t)$进行推断,并计算联合似然函数$p(\mathbf{x},\mathbf{z} \mid \Theta)$;在M步,基于E步的结果进行最大化寻优,即对关于变量$\Theta$的函数$\mathcal{Q}(\Theta;\Theta^t)$进行最大化从而求取:
\[\begin{align} \Theta ^{t+1} &= \underset{\Theta}{\text{arg max}} \mathcal{Q}(\Theta;\Theta^t) \\&= \underset{\Theta}{\text{arg max}} \sum_{\mathbf{z}} p(\mathbf{z} \mid \mathbf{x},\Theta^t) \ln p(\mathbf{x},\mathbf{z}\mid \Theta) \end{align} \tag{11}\]式(11)中的$\mathcal{Q}(\Theta;\Theta^t)$实际上是对数联合似然函数$\ln p(\mathbf{x},\mathbf{z} \mid \Theta)$在分布$p(\mathbf{z} \mid \mathbf{x},\Theta^t)$下的期望,当分布$p(\mathbf{z} \mid \mathbf{x},\Theta^t)$与变量$\mathbf{z}$的真实后验分布相等时,$\mathcal{Q}(\Theta;\Theta^t)$近似于对数似然函数。于是,EM算法最终可获得稳定的参数$\Theta$,而隐变量$\mathbf{z}$的分布也能通过该参数获得。
需注意的是,$p(\mathbf{z}\mid \mathbf{x},\Theta^t)$未必是隐变量$\mathbf{z}$服从的真实分布,而只是一个近似分布。若将这个近似分布用$q(\mathbf{z})$表示,则不难验证:
\[\ln p(\mathbf{x}) = \mathcal{L}(q) + KL(q \parallel p) \tag{12}\]其中,
\[\mathcal{L}(q) = \int q(\mathbf{z}) \ln \left\{ \frac{p(\mathbf{x},\mathbf{z})}{q(\mathbf{z})} \right\} d\mathbf{z} \tag{13}\] \[KL(q \parallel p) = - \int q(\mathbf{z}) \ln \frac{p(\mathbf{z}\mid \mathbf{x})}{q(\mathbf{z})} d \mathbf{z} \tag{14}\]然而在现实任务中,E步对$p(\mathbf{z}\mid \mathbf{x},\Theta^t)$的推断很可能因$\mathbf{z}$模型复杂而难以进行,此时可借助变分推断。通常假设$\mathbf{z}$服从分布:
\[q(\mathbf{z}) = \prod_{i=1}^M q_i (\mathbf{z}_i) \tag{15}\]即假设复杂的多变量$\mathbf{z}$可拆解为一系列相互独立的多变量$\mathbf{z}_i$。更重要的是,可以令$q_i$分布相对简单或有很好的结构,例如假设$q_i$为指数族(exponential family)分布,此时有:
\[\begin{align} \mathcal{L}(q) &= \int \prod_i q_i \left\{ \ln p(\mathbf{x,z}) - \sum_i \ln q_i \right\} d \mathbf{z} \\&= \int q_j \left\{ \int \ln p(\mathbf{x,z}) \prod_{i \neq j} q_i d\mathbf{z}_i \right\} d\mathbf{z}_j - \int q_j \ln q_j \ln q_j d \mathbf{z}_j + \text{const} \\&= \int q_j \ln \tilde{p} (\mathbf{x},\mathbf{z}_j) d \mathbf{z}_j - \int q_j \ln q_j d \mathbf{z}_j + \text{const} \end{align} \tag{16}\]为简化表述,这里将$q_i(\mathbf{z}_i)$简写为$q_i$。
$\text{const}$是一个常数。
其中:
\[\ln \tilde{p} (\mathbf{x},\mathbf{z}_j) = \mathbb{E}_{i\neq j} [ \ln p(\mathbf{x,z}) ] + \text{const} \tag{17}\] \[\mathbb{E}_{i \neq j} [ \ln p(\mathbf{x,z}) ] = \int \ln p(\mathbf{x,z}) \prod _{i \neq j} q_i d \mathbf{z}_i \tag{18}\]我们关心的是$q_j$,因此可固定$q_{i \neq j}$再对$\mathcal{L}(q)$进行最大化,可发现式(16)等于$-KL(q_j \parallel \tilde{p} (\mathbf{x},\mathbf{z}_j))$,即当$q_j = \tilde{p}(\mathbf{x},\mathbf{z}_j)$时$\mathcal{L}(q)$最大。于是可知变量子集$\mathbf{z}_j$所服从的最优分布$q_j^{*}$应满足:
\[\ln q_j^* (\mathbf{z}_j) = \mathbb{E}_{i \neq j} [\ln p(\mathbf{x,z})] + \text{const} \tag{19}\]即:
\[q_j^* (\mathbf{z}_j) = \frac{\exp (\mathbb{E}_{i\neq j}[\ln p(\mathbf{x,z})])}{\int \exp (\mathbb{E}_{i \neq j} [\ln p(\mathbf{x,z})] ) d \mathbf{z}_j} \tag{20}\]换言之,在式(15)这个假设下,变量子集$\mathbf{z}_j$最接近真实情形的分布由式(20)给出。
显然,基于式(15)的假设,通过恰当地分割独立变量子集$\mathbf{z}_j$并选择$q_i$服从的分布,$\mathbb{E}_{i \neq j} [ \ln p(\mathbf{x,z}) ]$往往有闭式解,这使得基于式(20)能高效地对隐变量$\mathbf{z}$进行推断。事实上,由式(18)可看出,对变量$\mathbf{z}_j$分布$q_j^{*}$进行估计时融合了$\mathbf{z}_j$之外的其他$\mathbf{z}_{i \neq j}$的信息,这是通过联合似然函数$\ln p(\mathbf{x,z})$在$\mathbf{z}_j$之外的隐变量分布上求期望得到的,因此亦称“平均场”(mean field)方法。
mean指期望,field则是指分布。
在实践中使用变分法时,最重要的是考虑如何对隐变量进行拆解,以及假设各变量子集服从何种分布,在此基础上套用式(20)的结论再结合EM算法即可进行概率图模型的推断和参数估计。显然,若隐变量的拆解或变量子集的分布假设不当,将会导致变分法效率低、效果差。
