【机器学习基础】系列博客为参考周志华老师的《机器学习》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.话题模型
本部分没太理解,仅作记录。
话题模型(topic model)是一族生成式有向图模型,主要用于处理离散型的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用。隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA)是话题模型的典型代表。
我们先来了解一下话题模型中的几个概念:词(word)、文档(document)和话题(topic)。具体来说,“词”是待处理数据的基本离散单元,例如在文本处理任务中,一个词就是一个英文单词或有独立意义的中文词。“文档”是待处理的数据对象,它由一组词组成,这些词在文档中是不计顺序的,例如一篇论文、一个网页都可看作一个文档;这样的表示方式称为“词袋”(bag-of-words)。数据对象只要能用词袋描述,就可使用话题模型。“话题”表示一个概念,具体表示为一系列相关的词,以及它们在该概念下出现的概率。
例如若把图像中的小块看作“词”,则可将图像表示为词袋,于是话题模型也可用于图像数据。
形象地说,如图14.11所示,一个话题就像是一个箱子,里面装着在这个概念下出现概率较高的那些词。不妨假定数据集中一共包含$K$个话题和$T$篇文档,文档中的词来自一个包含$N$个词的词典。我们用$T$个$N$维向量$\mathbf{W}=\{ \mathbf{w}_1,\mathbf{w}_2,…,\mathbf{w}_T \}$表示数据集(即文档集合),$K$个$N$维向量$\mathbf{\beta}_k (k=1,2,…,K)$表示话题,其中$\mathbf{w}_t \in \mathbb{R}^N$的第$n$个分量$w_{t,n}$表示文档$t$中词$n$的词频,$\mathbf{\beta}_k \in \mathbb{R}^N$的第$n$个分量$\beta_{k,n}$表示话题$k$中词$n$的词频。
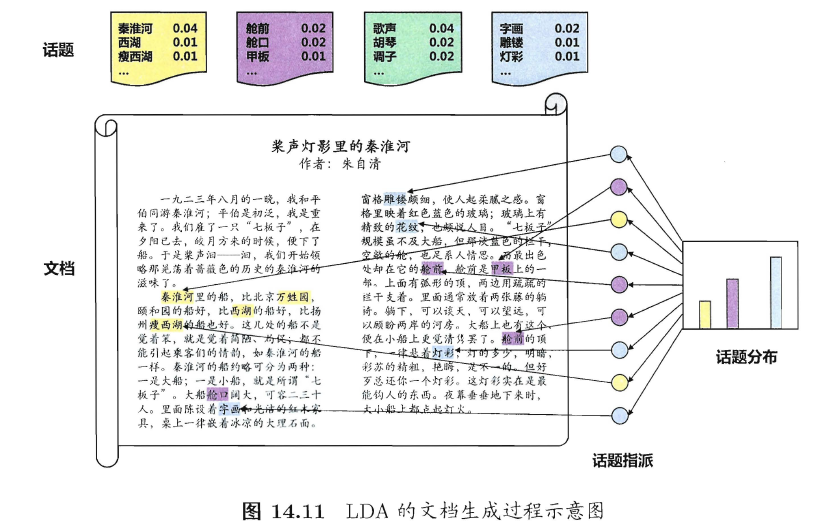
在现实任务中可通过统计文档中出现的词来获得词频向量$\mathbf{w}_i(i=1,2,…,T)$,但通常并不知道这组文档谈论了哪些话题,也不知道每篇文档与哪些话题有关。LDA从生成式模型的角度来看待文档和话题。具体来说,LDA认为每篇文档包含多个话题,不妨用向量$\Theta_t \in \mathbb{R}^K$表示文档$t$中所包含的每个话题的比例,$\Theta_{t,k}$即表示文档$t$中包含话题$k$的比例,进而通过下面的步骤由话题“生成”文档$t$:
通常需对词频做一些处理,例如去除“停用词表”中的词等。
- 根据参数为$\mathbf{\alpha}$的狄利克雷分布(见本文第2.2部分)随机采样一个话题分布$\Theta_t$;
- 按如下步骤生成文档中的$N$个词:
- (a)根据$\Theta_t$进行话题指派,得到文档$t$中词$n$的话题$z_{t,n}$;
- (b)根据指派的话题所对应的词频分布$\beta_k$随机采样生成词。
图14.11演示出根据以上步骤生成文档的过程。显然,这样生成的文档自然地以不同比例包含多个话题(步骤1),文档中的每个词来自一个话题(步骤2b),而这个话题是依据话题比例产生的(步骤2a)。
图14.12描述了LDA的变量关系,其中文档中的词频$w_{t,n}$是唯一的已观测变量,它依赖于对这个词进行的话题指派$z_{t,n}$,以及话题所对应的词频$\beta_k$;同时,话题指派$z_{t,n}$依赖于话题分布$\Theta_t$,$\Theta_t$依赖于狄利克雷分布的参数$\alpha$,而话题词频则依赖于参数$\eta$。
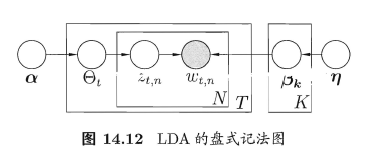
于是,LDA模型对应的概率分布为:
\[p(\mathbf{W,z,\beta,\Theta} \mid \mathbf{\alpha,\eta}) = \prod_{t=1}^T p (\Theta_t \mid \mathbf{\alpha}) \prod _{i=1}^K p(\beta_k \mid \eta) \left( \prod_{n=1}^N P(w_{t,n} \mid z_{t,n},\beta_k) P(z_{t,n} \mid \Theta_t) \right) \tag{1}\]其中$p(\Theta_t \mid \mathbf{\alpha})$和$p(\beta_k \mid \eta)$通常分别设置为以$\alpha$和$\eta$为参数的$K$维和$N$维狄利克雷分布,例如:
\[p(\Theta_t \mid \alpha) = \frac{\Gamma (\sum_k \alpha_k)}{\prod_k \Gamma (\alpha_k)} \prod _k \Theta_{t,k}^{\alpha_k -1} \tag{2}\]其中$\Gamma (\cdot)$是Gamma函数(见本文第2.1部分)。显然,$\alpha$和$\eta$是模型式(1)中待确定的参数。
给定训练数据$\mathbf{W}=\{ w_1,w_2,…,w_T \}$,LDA的模型参数可通过极大似然法估计,即寻找$\alpha$和$\eta$以最大化对数似然:
\[LL(\mathbf{\alpha,\eta})=\sum_{t=1}^T \ln p(\mathbf{w}_t \mid \mathbf{\alpha,\eta}) \tag{3}\]训练文档集对应的词频。
但由于$p(\mathbf{w}_t \mid \mathbf{\alpha,\eta})$不易计算,式(3)难以直接求解,因此实践中常采用变分法来求取近似解。
若模型已知,即参数$\alpha$和$\eta$已确定,则根据词频$w_{t,n}$来推断文档集所对应的话题结构(即推断$\Theta_t$,$\beta_k$和$z_{t,n}$)可通过求解:
\[p(\mathbf{z,\beta,\Theta} \mid \mathbf{W,\alpha,\eta}) = \frac{p(\mathbf{W,z,\beta,\Theta} \mid \mathbf{\alpha,\eta})}{p (\mathbf{W} \mid \mathbf{\alpha,\eta})} \tag{4}\]然而由于分母上的$p (\mathbf{W} \mid \mathbf{\alpha,\eta})$难以获取,式(4)难以直接求解,因此在实践中常采用吉布斯采样或变分法进行近似推断。
2.概率分布
2.1.贝塔分布
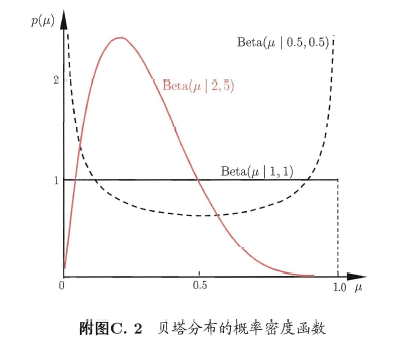
贝塔分布(Beta distribution)是关于连续变量$\mu \in [0,1]$的概率分布,它由两个参数$a>0$和$b>0$确定,其概率密度函数如附图C.2所示。
其中$\Gamma (a)$为Gamma函数:
\[\Gamma (a) = \int_0^{+\infty} t^{a-1}e^{-t}dt\]$B(a,b)$为Beta函数:
\[B(a,b) = \frac{\Gamma (a) \Gamma (b)}{\Gamma (a+b)}\]当$a=b=1$时,贝塔分布退化为均匀分布。
2.2.狄利克雷分布
狄利克雷分布(Dirichlet distribution)是关于一组$d$个连续变量$\mu_i \in [0,1]$的概率分布,$\sum_{i=1}^d \mu_i = 1$。令$\mathbf{\mu} = (\mu_1; \mu_2;…;\mu_d)$,参数$\mathbf{\alpha} = (\alpha_1; \alpha_2;…;\alpha_d)$,$\alpha_i > 0$,$\hat{\alpha} = \sum_{i=1}^d \alpha_i$。
\[p(\mathbf{\mu} \mid \mathbf{\alpha}) = \text{Dir} (\mathbf{\mu} \mid \mathbf{\alpha}) = \frac{\Gamma (\hat{\alpha})}{\Gamma (\alpha_1)...\Gamma (\alpha_i)} \prod _{i=1}^d \mu_i ^{\alpha_i -1}\] \[\mathbb{E} [\mu_i] = \frac{\alpha_i}{ \hat{\alpha}}\] \[\text{var} [\mu_i] = \frac{\alpha_i (\hat{\alpha} - \alpha_i)}{\hat{\alpha}^2 (\hat{\alpha} + 1)}\] \[\text{cov} [\mu_j,\mu_i] = \frac{\alpha_j \alpha_i}{\hat{\alpha}^2 (\hat{\alpha}+1)}\]当$d=2$时,狄利克雷分布退化为贝塔分布。
