【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.设置验证集
我们在【深度学习基础】第九课:深层神经网络一文中提到了神经网络的超参数。那么超参数的确定有很多办法,其中设置验证集就是一个非常常用的办法,即把数据集分成训练集、验证集和测试集三部分。利用验证集确定模型的最佳超参数。
1.1.数据集划分比例
对于小数据量(通常指数据量在万级及以下):
- 60%训练集
- 20%验证集
- 20%测试集
对于大数据量(通常指数据量在万级以上,例如百万级),此时验证集和测试集占数据总量的比例会趋向于变得很小:
- 98%训练集
- 1%验证集
- 1%测试集
甚至对于数据量过百万的情况,会有:
- 99.5%训练集
- 0.25%验证集(或0.4%验证集)
- 0.25%测试集(或0.1%测试集)
1.2.数据集划分原则
⚠️要确保验证集和测试集的数据来自同一分布。
2.偏差和方差
偏差和方差的详细讲解请见👉【机器学习基础】第五课:偏差与方差。
一般来说会存在偏差-方差窘境,但是也存在偏差和方差都很高或者都很低的情况。
偏差和方差都很高的情况:
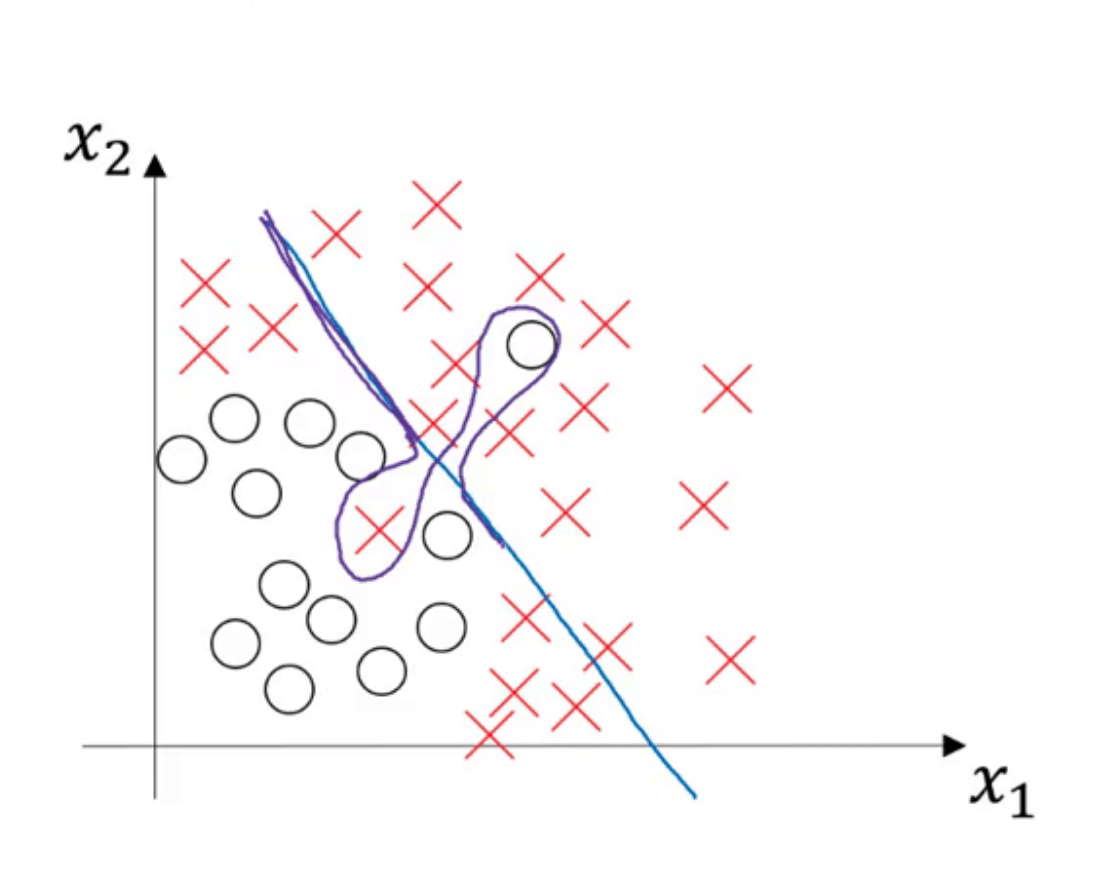
上图中的模型基本是个简单的线性模型,并没有很好的拟合大部分数据,因此有着高偏差;此外,该模型又过度拟合了其中的部分数据,导致其还有着高方差。
对于理想中的完美模型或者趋于完美的模型,有可能出现其偏差和方差都较低的情况。
👉降低偏差的方法:
- 选择更大的网络(比如更多的隐藏层或者隐藏单元)。
- 训练更长的时间(比如增加迭代次数)。
- 选择更先进的优化算法。
👉降低方差的方法:
- 更多的训练数据。
- 正则化。
在训练初期,确定一个合适的网络框架可以有效的同时降低偏差和方差。
在实际应用中,确定我们要解决的是高偏差问题还是高方差问题,对症下药有助于我们选出最有效的解决办法。
在机器学习的初期阶段,偏差-方差窘境经常出现。但是在深度学习和大数据时代,在正则适度的前提下,通常构建一个更大的网络便可以在不影响方差的同时,减少偏差;而采用更多数据通常可以在不过多影响偏差的同时,减少方差。这也是我们在深度学习中,不用特别关注偏差-方差窘境的一个重要原因。
