【机器学习基础】系列博客为参考周志华老师的《机器学习》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.前言
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。
决策树剪枝的基本策略有“预剪枝(prepruning)”和“后剪枝(postpruning)”。
👉预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
👉后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
接下来,我们通过验证集来判断决策树性能的变化从而进行剪枝,采用信息增益准则来进行划分属性选择。
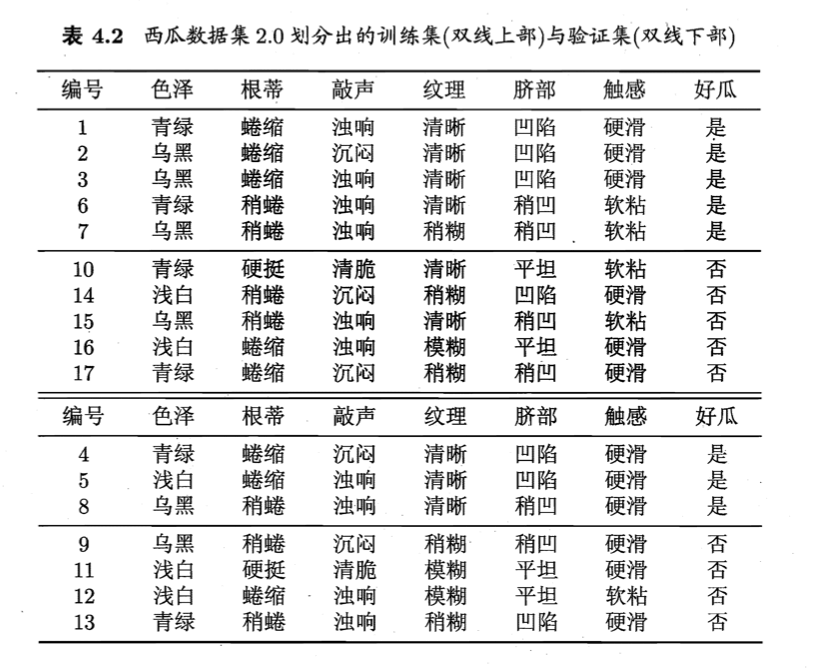
训练集和验证集见下:
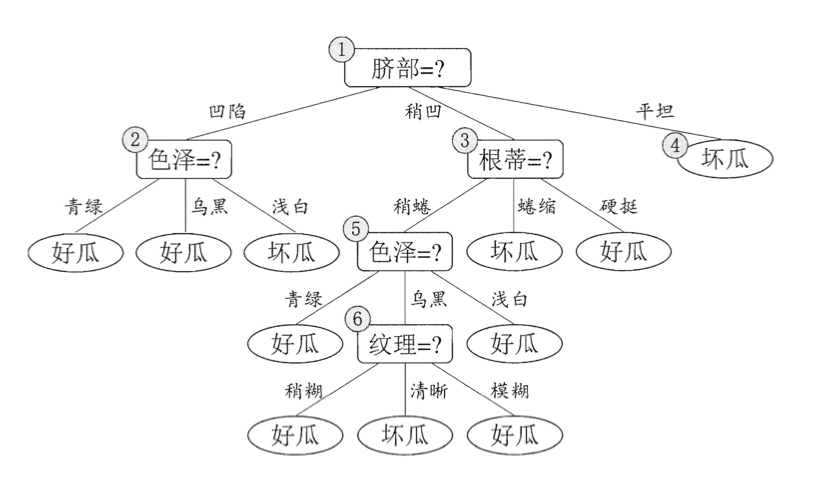
可生成如下决策树(未剪枝):
2.预剪枝
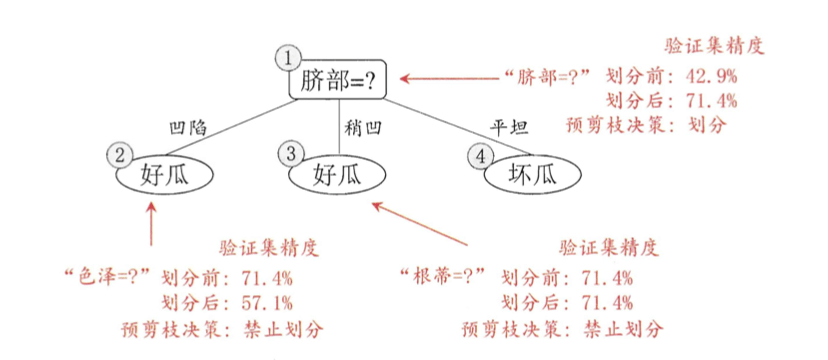
- 首先我们不按照任何属性划分训练集。训练集中正类和负类都是5例,那么可任选其中一类作为预测类别,假设我们选择正类,即所有测试数据均被预测为正类。那么此时验证集的预测正确率为$\frac{3}{7}=42.9\%$。
- 根据信息增益准则,我们选择“脐部”为根结点划分数据集。上图中结点2,3,4分别包含编号为{1,2,3,14}、{6,7,15,17}、{10,16}的训练样例,因此这3个结点分别被标记为“好瓜”、“好瓜”、“坏瓜”。此时,验证集的预测正确概率为$\frac{5}{7}=71.4\%>42.9\%$,因此不需要剪枝,可以用属性“脐部”进行划分。
- 然后,决策树算法应该对结点2进行划分,基于信息增益准则将挑选出划分属性“色泽”。然而,在使用“色泽”划分后,验证集的准确率为57.1%<71.4%。因此,预剪枝策略将禁止结点2被划分。
- 同理,对结点3,最优划分属性为“根蒂”,划分后验证集准确率仍为71.4%。这个划分不能提升验证集精度,于是,预剪枝策略禁止结点3被划分。
- 对于结点4,其所含训练样例全部属于同一类,不再进行划分。
最终,预剪枝后生成如上图所示的仅有一层划分的决策树,亦称“决策树桩”(decision stump)。其验证集精度为71.4%。
预剪枝的优点:
- 降低了过拟合的风险。
- 减少了决策树的训练时间开销和测试时间开销。
预剪枝的缺点:
- 有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分却有可能导致性能显著提高。因此预剪枝会有欠拟合的风险。
3.后剪枝
后剪枝先从训练集生成一棵完整决策树,见第1部分的决策树。该决策树的验证集精度为42.9%。
- 后剪枝首先考虑结点6,若将其领衔的分支剪除,则相当于把6替换为叶结点。替换后的叶结点包含编号为{7,15}的训练样本,于是,该叶结点的类别标记为“好瓜”,此时决策树的验证集精度提高至57.1%。于是,后剪枝策略决定剪枝。
- 然后考察结点5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为{6,7,15}的训练样例,叶结点类别标记为“好瓜”,此时决策树验证集精度仍为57.1%。于是可以不进行剪枝。(⚠️此种情形下验证集精度虽无提高,但根据奥卡姆剃刀准则,剪枝后的模型更好,因此,实际的决策树算法在此种情形下通常要进行剪枝。)
- 同理,对于结点2,剪枝后验证集精度提升至71.4%。于是,执行剪枝。
- 结点3和结点1剪枝后均不能提升验证集精度,于是不执行剪枝。
后剪枝得到的决策树:

其验证集精度为71.4%。
后剪枝的优点:
- 欠拟合风险很小。
- 泛化性能往往优于预剪枝决策树。
后剪枝的缺点:
- 后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
