【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.什么是Batch Normalization
在【深度学习基础】第十二课:归一化输入一文中,我们提到了归一化输入可以加速学习过程。
根据这个思路,同样的我们也可以将每个隐藏层的输入$a^{[0]},a^{[1]},a^{[2]},…,a^{[l]}$进行同样的归一化处理。这样我们就可以提升每一层的训练效率。
⚠️但是在很多深度学习相关的研究中存在一个争议:是归一化激活函数的输入$z^{[l]}$还是归一化激活函数的输出$a^{[l]}$。在实践中,归一化$z^{[l]}$是更常见的做法,本系列博客也将默认采用这种方式。
以神经网络中某一层$l$为例,我们可以得到激活函数的输入:$z^{(1)},z^{(2)},…,z^{(m)}$(假设有m个样本),其归一化的步骤(即Z变换)和归一化网络输入是一样的:
- $\mu=\frac{1}{m}\sum z^{(i)}$
- $\sigma ^2=\frac{1}{m}\sum (z^{(i)} - \mu)^2$
- $z^{(i)}_{norm}=\frac{z^{(i)}-\mu}{\sqrt{ \sigma^2 + \epsilon}}$(分母加上$\epsilon$防止除0)
将$z^{(i)}$转换成均值为0,方差为1的标准正态分布(前提假设:$z^{(i)}$服从正态分布)。但是有的时候,我们并不希望每个$z^{(i)}$的均值都为0,方差都为1,因为不同的分布可能会更有意义。比如对于sigmoid激活函数来说,我们可能希望$z^{(i)}$的方差更大一些,而不是全部集中在S型曲线中段近似线性的部分:
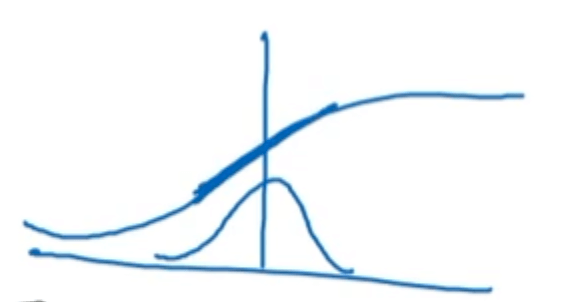
因此,引进两个新的参数$\gamma,\beta$作为调整(此处的$\beta$不同于momentum中的$\beta$):
\[\widetilde{z}^{(i)}=\gamma z^{(i)}_{norm} + \beta\]当$\gamma=\sqrt{ \sigma^2 + \epsilon},\beta=\mu$时,有$\widetilde{z}^{(i)}=z^{(i)}_{norm}$。
可以通过赋予$\gamma$和$\beta$其他的值来构造含其他均值和方差的分布。
然后我们就可以用$\widetilde{z}^{(i)}$代替$z^{(i)}$进行后续的计算。
以上便是Batch Normalization(包含对输入层的归一化)。通常简称为Batch Norm或者BN。
2.Batch Normalization在深层网络中的应用
在第1部分我们介绍了Batch Norm在单个隐藏层中的应用,将其扩展到多层:
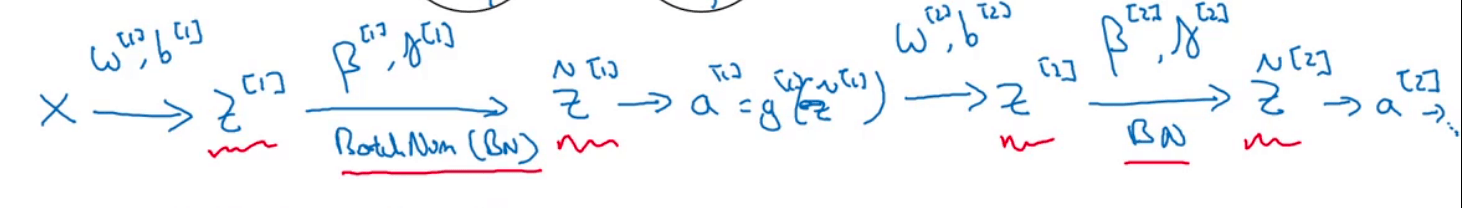
该网络中涉及到的参数为:
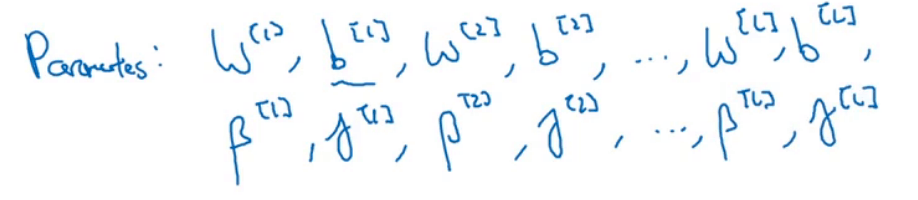
但是因为Batch Norm的存在,使得参数$b$失去了意义。因为$z^{[l]}=w^{[l]}a^{[l-1]}+b^{[l]}$,而Batch Norm中,$z^{[l]}$会减去其均值,此时$b^{[l]}$的作用便被消除了。所以我们可以省略掉参数$b$。$z^{[l]}$的计算简化为:$z^{[l]}=w^{[l]}a^{[l-1]}$。
$\beta,\gamma$的更新和$w,b$一样,我们可以用任何一种优化算法来进行更新,比如:
\[\beta^{[l]} := \beta^{[l]} -\alpha d\beta^{[l]}\]或momentum、RMSprop、Adam等其他优化算法。
⚠️此外,通常情况下,Batch Norm通常和mini-batch一起使用。以第一个mini-batch为例:

其中,$X^{\{1 \}}$为第一个mini-batch的输入。
3.BatchNorm为什么起作用
那么为什么Batch Norm可以提升学习效率呢?
其中一个原因我们已经在【深度学习基础】第十二课:归一化输入一文中解释过了。
另一个原因是Batch Norm可以让同一隐藏层的每次输入都服从均值为0,方差为1(或者是由$\beta,\gamma$决定的其他值)的分布,从而减少了输入的改变,使得其不会过多的受到前几层参数更新的影响。相当于每一层都可以更加独立的进行学习,尽可能的不受其他层参数的影响。这有助于加速整个网络的学习。
此外,Batch Norm还有轻微的正则化效果。因为在和mini-batch一起使用时,计算$z^{[l]}$的均值和方差只是基于总体数据集的一部分,因此会有噪声。因为噪声很小,所以正则化效果并不特别明显。可以和dropout一起使用,起到更好的正则化效果。
4.BatchNorm在测试阶段的应用
在测试阶段,测试样本可能只有一个,这种情况下用一个测试样本的均值和方差进行Batch Norm是没有意义的。
那么在测试阶段,我们怎么获得每个隐藏层$z^{[l]}$的均值和方差呢?
解决办法:在训练阶段计算每一个mini-batch时,同时缓存每一隐藏层的均值和方差,最终分别求其指数加权平均作为测试阶段的均值和方差。
如果测试数据足够多,也可以基于测试数据计算每个隐藏层的均值和方差。但是基于训练阶段得到的均值和方差的指数加权平均是更为常用的方法。
