本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
卷积神经网络不仅推动了图像分类任务的发展,也促进了定位任务的发展,例如bounding box。
可以很自然的想到定位任务的下一步应该是语义分割(semantic segmentation),其实就是每一个像素点都有一个所属的类别标签。但是之前的方法或多或少都有一些缺点,而本文提出的方法可以解决这些缺点。
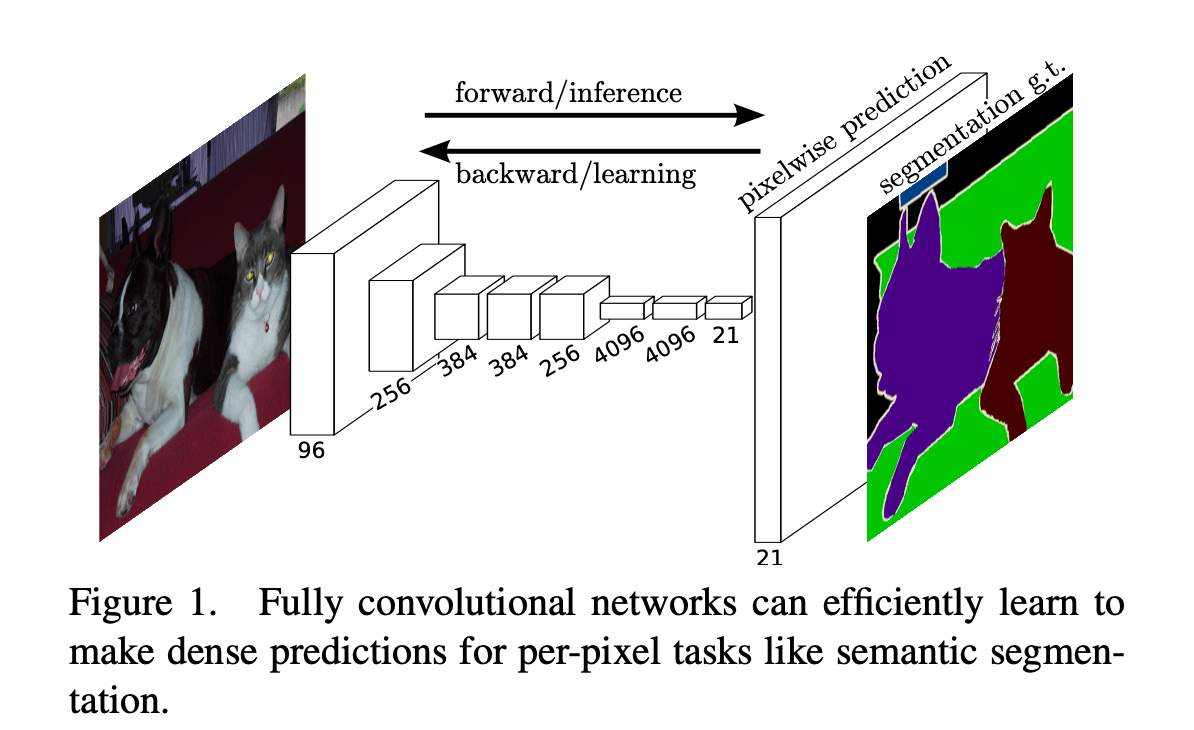
在本文中,我们提出FCN(fully convolutional network),是一种端到端、像素到像素的语义分割方法,超过了现有的顶尖算法。我们是第一个训练端到端的FCN:1)像素级别的预测;2)有监督的预训练。现有网络的全卷积版本可以预测任意大小输入的dense output。网络的训练和推理都是通过密集(dense)的前向计算和后向传播一次完成的。在网络中,上采样层(upsampling layers)通过subsampled pooling实现像素级别的预测和学习。
dense prediction:预测出图像中每个像素点的所属类别。
我们的方法是有效的,不会有其他方法的复杂性。基于patchwise的预测是其他很多方法所应用的,但是相比FCN,其缺乏效率。此外,我们的方法不使用预处理和后处理复杂度。我们将最近表现优异的分类模型转化成FCN(使其得到dense prediction)并进行fine-tuning。相比之下,转化前的网络使用small convnets,并且没有进行有监督的预训练。
pixelwise:像素级别。
patchwise:patch级别。
imagewise:图像级别。
语义分割面临着semantics和location之间的冲突:全局信息决定着是什么,而局部信息决定着在哪里。在非线性的局部到全局的金字塔中,深层特征的层级结构决定着semantics和location。在本文的第4.2部分,我们定义了一个skip architecture来利用刚提到的特征谱(feature spectrum),它结合了深层且粗糙的语义信息和浅层且精细的外在信息。
在下一部分,我们回顾了一些深度分类网络,FCN,近期进行语义分割的一些卷积网络。随后的部分我们会介绍FCN设计和dense prediction之间的权衡取舍(tradeoffs),以及我们所用架构中的上采样和多层结合策略。最后,我们测试了在PASCAL VOC 2011-2、NYUDv2和SIFT Flow上的最优结果。
2.Related work
我们的方法借鉴了在图像分类和迁移学习方面的成功经验。迁移学习在识别任务、检测任务、实例分割(instance segmentation)、语义分割方面都有应用。我们重新构建并fine-tune了这些分类网络,使其可以直接dense prediction,进行语义分割。
👉Fully convolutional networks
据我们所知,将卷积网络输入扩展到任意大小的想法最早出现在论文“O. Matan, C. J. Burges, Y. LeCun, and J. S. Denker. Multi-digit recognition using a space displacement neural network. In NIPS, pages 488–495. Citeseer, 1991.”中,他们将LeNet扩展到识别数字串。由于他们的网络仅限于一维输入,所以他们使用Viterbi decoding来获得输出。论文“R. Wolf and J. C. Platt. Postal address block location using a convolutional locator network. Advances in Neural Information Processing Systems, pages 745–745, 1994.”将卷积网络的输出扩展到二维。
全卷积计算(Fully convolutional computation)也在当今得到了利用。全卷积推理(fully convolutional inference)在滑动窗口检测、语义分割和图像恢复等领域都有应用。全卷积训练(Fully convolutional training)很少见。
论文“K.He, X.Zhang, S.Ren,and J.Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.”通过移除分类网络中的非卷积部分,制作了一个特征提取器。他们通过结合proposals和spatial pyramid pooling来产生用于分类的局部(localized)且固定长度(fixed-length)的特征。这个方法虽然快速有效,但是这种混合模型无法进行端到端的学习。
👉Dense prediction with convnets
近期有一些方法将卷积网络用于dense prediction。这些方法的共通点有:
- capacity和receptive fields受限的小型模型。
- patchwise级别的训练。
- 都采用了一些后处理的方法,例如superpixel projection, random field regularization, filtering或者local classification。
- 输入移位和dense输出的隔行交错输出。
- 多尺度金字塔处理。
- 饱和双曲正切非线性。
- 集成。
模型的capacity指的是模型能拟合复杂函数的能力,代表着模型的学习能力。如果学习能力过强,而数据过于简单,则容易出现过拟合现象。
虽然我们的方法并没有应用这些机制。但是我们从FCN的角度研究了patchwise training(见第3.4部分)和“shift-and-stitch” dense output(见第3.5部分)。我们还在第3.3部分讨论了上采样(upsampling)。
不同于现有的方法,我们采用并扩展了深度分类框架,使用图像分类作为有监督的预训练,并全卷积地进行fune-tune,使从whole image inputs到whole image ground thruths的学习变得简单有效。
也有些方法通过对bounding box和region proposal进行采样来fine-tune R-CNN,使其可应用于检测、语义分割、实例分割等任务。这些方法都不是端到端的。但它们依然在PASCAL VOC和NYUDv2中取得了SOTA(state-of-the-art)的分割结果,所以我们在第5部分直接用端到端的FCN和这些方法做了比较。
NYUDv2(NYU Depth Dataset V2)数据集由微软Kinect的RGB和Depth摄像机记录的各种室内场景的视频序列组成。它的特点:
- 1449张标注的RGB图片和深度图。
- 来自3个城市,464个场景。
- 407024张没有标注的图片。

我们跨层融合特征以定义非线性局部到全局的表示,并对其进行端到端的调整。
3.Fully convolutional networks
卷积网络中每一层的数据都是三维的:$h\times w \times d$,其中,$h$和$w$为空间维度,$d$为通道维度。第一层为输入图像,此时,$h\times w$为输入图像的大小,$d$为输入(彩色)图像的通道数。
卷积网络基于平移不变性(translation invariance)建立。网络的基本组件(卷积、pooling、激活函数)作用在输入的局部区域上,并且仅依赖于相对空间坐标。使$\mathbf{x}_{ij}$为某一层$(i,j)$处的数据向量(向量大小为$d\times 1$),$\mathbf{y}_{ij}$为下一层的值(即$(i,j)$位置对应的输出),$\mathbf{y}_{ij}$的计算见下:
\[\mathbf{y}_{ij}=f_{ks} ( \{ \mathbf{x}_{si+\delta i , sj+\delta j} \} _ {0 \leqslant \delta i , \delta j \leqslant k})\]其中,$k$为kernel的大小,$s$为步长或下采样因子(subsampling factor)。$f_{ks}$可以是:用于卷积或average pooling的矩阵乘法;max pooling的空间最大值;elementwise非线性的激活函数等。
平移不变性(Translation Invariance):在图像分类任务中,不变性意味着,当所需要识别的目标出现在图像的不同位置时,模型对其识别所得到的标签应该相同。即当输出进行变换后,还能得到相同的输出。
平移相等性(Translation Equivariance):指在目标检测任务中,如果输入的图像中,对应的目标发生了平移,那么最终检测出的候选框也应发生相应的变化。即对输入进行变换后,输出也会发生相应的变换。
kernel的大小和步长遵循以下转换规则:
\[f_{ks} \circ g_{k's'} = (f \circ g) _{k' + (k-1)s',ss'}\]$f \circ g$表示$f$与$g$的合成函数或复合函数。例如:$(g\circ f) (x) = g(f(x))$。
举个例子解释下上式,比如$f$为$3 \times 3$的kernel,步长为1;$g$也一样。此时有$f_{31} \circ g_{31} = (f \circ g) _{51}$,即连续两个$3\times 3$的kernel(步长均为1),相当于一个$5\times 5$的kernel(步长也为1)。
如果一个网络只通过这种方式计算非线性filter,则我们称这种网络为deep filter或fully convolutional nerwork(FCN)。FCN可以很自然的处理各种大小的输入,并生成相应空间维度的输出(可能涉及重采样)。
FCN使用实值损失函数(a real-valued loss function)。损失函数可定义为最后一层空间维度的和:
\[\ell (\mathbf{x};\theta) = \sum_{ij} \ell ' (\mathbf{x}_{ij};\theta)\]其梯度将是其每个空间分量梯度的总和。因此在整幅图像上,基于$\ell$的随机梯度下降计算和基于$\ell ‘$的随机梯度下降结果是一样的,将最后一层的所有感受野(receptive field)作为一个minibatch。
当感受野重叠区域很大时,前馈计算和反向传播会比逐块(patch-by-patch)单独计算时更有效。
点击此处帮助理解上一段话。
接下来我们会介绍如何将分类网络转化成FCN,使其可以输出coarse output maps。对于像素级别的预测,我们需要将coarse outputs映射回像素。为了达到此目的,我们将在第3.2部分介绍快速扫描。在第3.3部分介绍反卷积层(deconvolution layers)用于上采样。第3.4部分,我们考虑通过patch级别的采样(patchwise sampling)进行训练。并且在第4.3部分,证明了我们所使用的全图训练方法(whole image training)更为快速,且同样有效。
3.1.Adapting classifiers for dense prediction
典型的识别网络,例如LeNet、AlexNet以及后续更深的网络框架,其输入大小都是固定的,然后产生非空间型的输出(即输出是一个类别而不是一个map)。并且这些网络全连接层的大小都是固定的,丢弃了空间坐标。但是这些全连接层也可以被视为卷积层。这样网络就可以接受任意大小的输入并输出分类图(classification maps)了。转换示意图见Fig2。
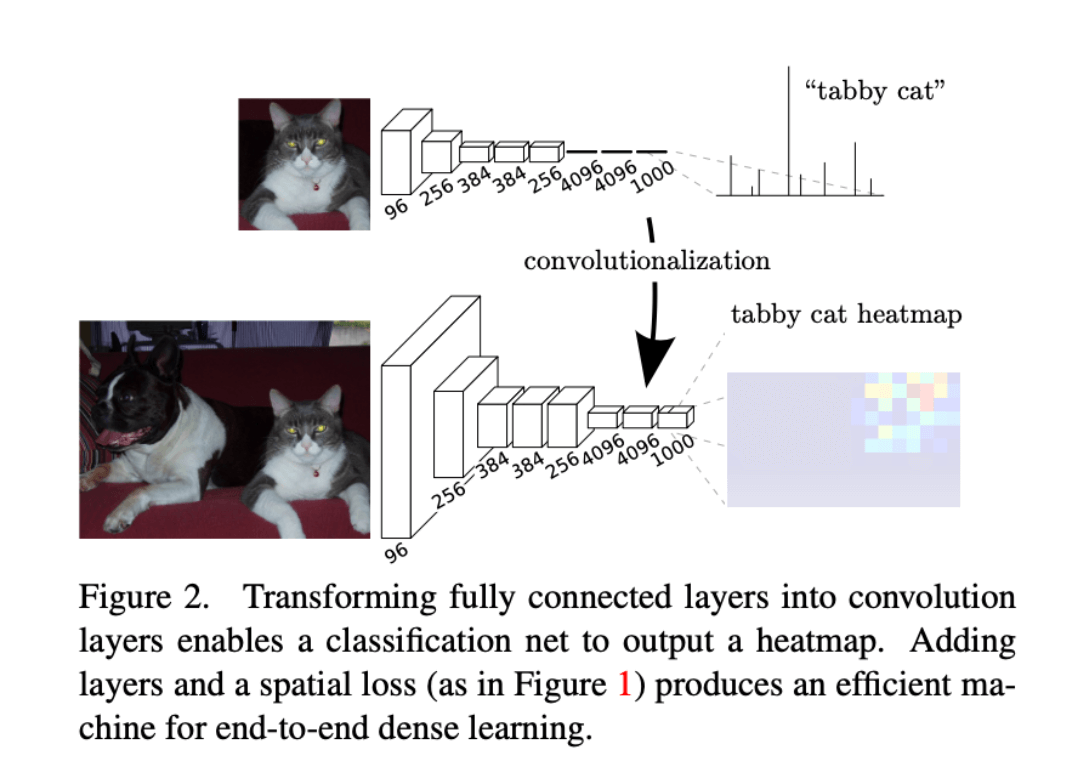
Fig2展示了如何将全连接层转换成卷积层使其可以输出heatmap。添加层和spatial loss(如Fig1所示)可以为端到端的dense learning提供有效的机制。
此外,结果输出的map相当于是原始输入图像不同patch的评估,并且这些patch重叠区域的计算是共享的。例如,AlexNet推理一幅$227\times 227$大小的图像需要1.2ms,而FCN只需22ms就能从$500\times 500$的图像中输出$10\times 10$的grid,速度快了将近5倍。
grid中的每个点在输入层面的感受野都是$227 \times 227$,所以FCN相当于用了22ms预测了$10\times 10=100$幅$227 \times 227$patch的类别,而AlexNet预测100幅$227 \times 227$图像需要$1.2\times 100=120$ms,所以说快了将近5倍。
由于每个输出单元(output cell,对应输入图像的每个像素点)都有GT,所以前向和反向传播都很直截了当。AlexNet在单张图像上反向传播一次的时间是2.4ms,对应的FCN(输出$10 \times 10$的map)反向传播一次的时间是37ms,这导致了与前向传播类似的速度提升。
虽然我们将分类网络重新解释为了FCN,但因为下采样(比如pooling)的关系,网络的输出维度小于原始图像的维度。这使得这些分类网络的FCN版本的输出变得粗糙(即输出维度不能和原始图像中的每个像素点做到一一对应,无法进行语义分割)。实际上最终生成的map比原始图像缩小s倍,s为下采样时stride的乘积(即累积下采样步长)。
这一部分主要介绍了如何将分类网络转换成FCN(即把FC层转换成卷积层),但此时得到的输出map是粗糙的,和原始图像无法一一对应。
3.2.Shift-and-stitch is filter rarefaction
通过拼接(stitch)输入的移位(shift)版本的输出,可以从coarse output中获得dense prediction。假设下采样因子为$f$(即通过多次下采样得到的output map的size是input size的$\frac{1}{f}$),平移(shift)输入图像,偏移量为$(x,y)$,$x$表示输入图像向右移动的像素个数(下图的例子中$x$为向左移动的像素个数,例子和原文中的方向相反,不影响理解,下同),$y$表示输入图像向下移动的像素个数(下图的例子中$y$为向上移动的像素个数),其中有$0 \leqslant x,y < f$。因此我们共可以得到$f^2$个input,自然也可以得到$f^2$个output,将所有output拼接(stitch)在一起得到和input size一样的dense prediction。拼接方法为:output map中的每个点都在原始图像上对应一个patch(即对应的感受野),则该点的预测结果便可视为对应的感受野的中心像素点的预测类别。
举个例子,假设网络只有一层$2\times 2$的max pooling,且stride=2,所以有$f=2$,output map中每个点对应的感受野大小为$2\times 2$,将右下角的位置视为感受野的中心:
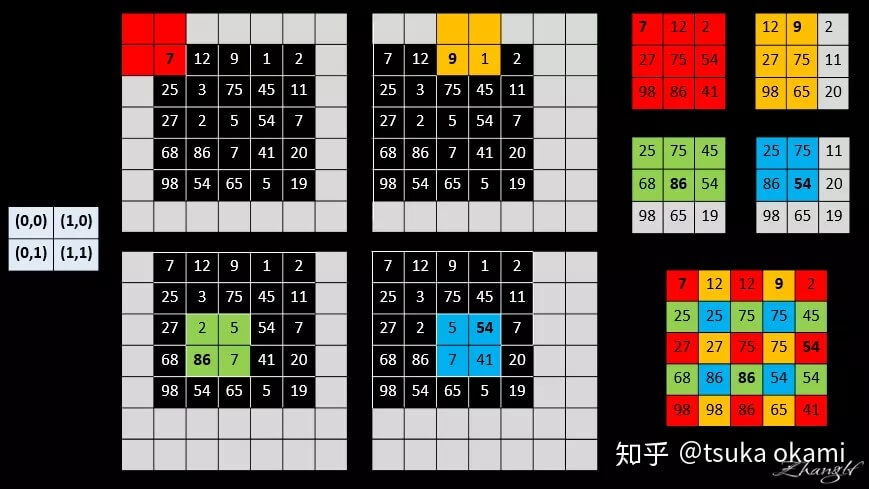
这个其实有点类似滑动窗口的思想,只不过是不修改输出的维度(如果是分类模型,则输出就是$1\times C$,$C$为类别数),变为移动input,使input的每个像素点轮流作为感受野的中心。
shift-and-stitch这个方法会使计算成本增加$f^2$倍,但是有一个trick(即filter rarefaction)可以更有效的得到一样的结果。还是用上面的例子,如果把max pooling的stride设为1可以得到一样的结果。这个原理也很好理解,因为每次移动input一个像素就相当于input不动,移动filter一步。但是上述例子是假设网络只有一个max pooling层,而实际情况是网络通常由多个卷积层、pooling层组成,如果还是仅仅把下采样层的stride改为1无法得到相同的结果。解决这一问题的办法是扩展原来的filter。考虑某一下采样层,其stride=s,后接一个卷积层,卷积核权重为$f_{ij}$,记input大小为$w\times h$,想得到dense prediction有两种方式:
- shift and stitch。过程为:shift input,得到$s^2$个inputs,然后分别经过subsampling layer得到$s^2$个outputs,这些outputs又分别通过后续的conv层,得到$s^2$个outputs,最后stitch这$s^2$个outputs得到最终大小为$w\times h$的output。
-
filter rarefaction。将下采样层的stride改为1,同时将后接卷积层的filter按如下方式dilate:
\[f'_{ij} = \begin{cases} f_{i/s,j/s}, & \text{if s divides both i and j;} \\ 0, & \text{otherwise,} \end{cases}\]
如果按照方式1继续下一层的卷积:
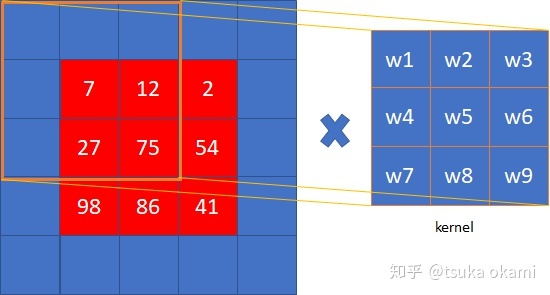
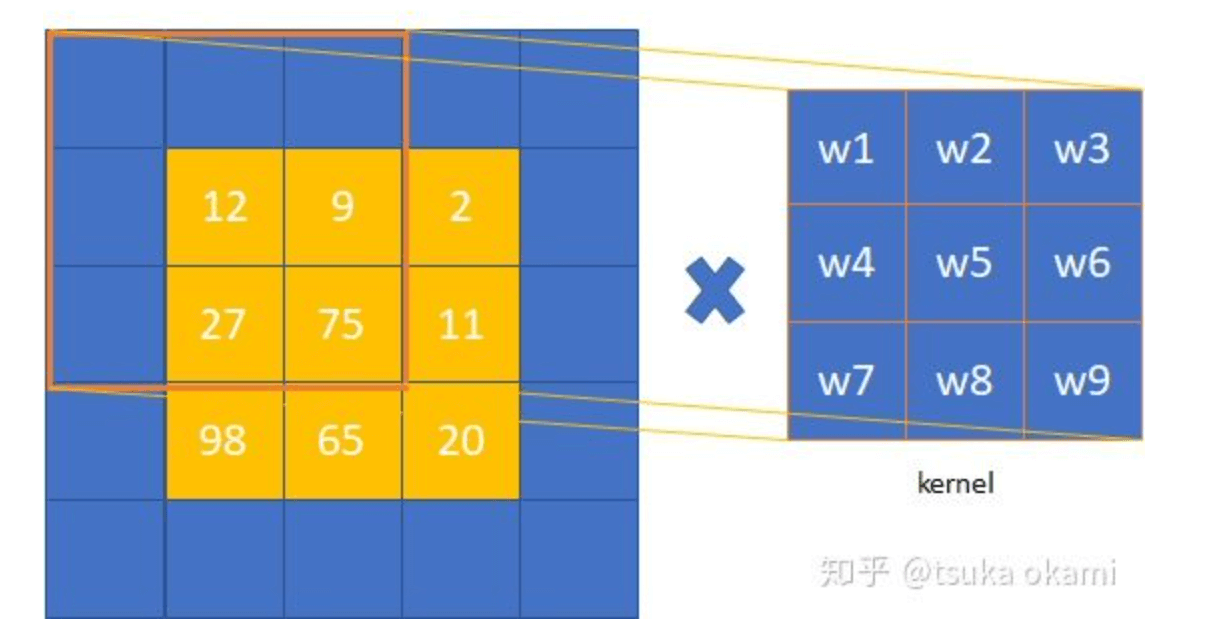
如果按照方式2继续下一层的卷积:
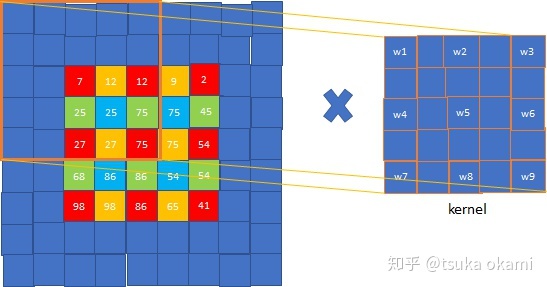
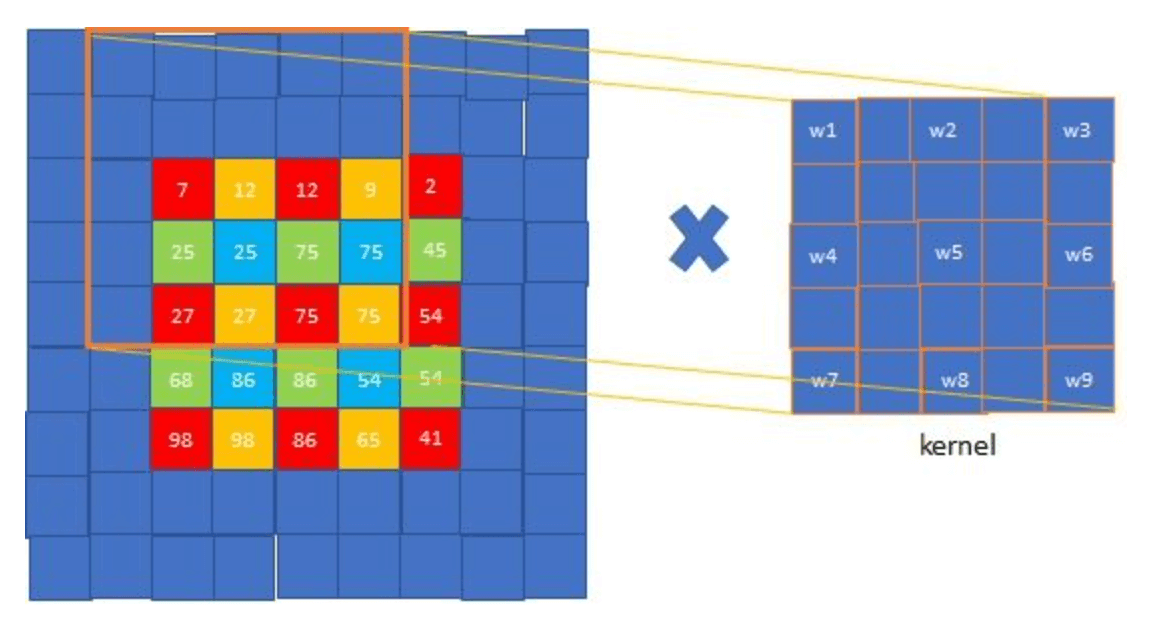
可以看到,两种策略得到的结果是一样的。
在方式2中,如果只是把后接卷积层的stride改为1,则无法得到和方式1一样的结果。尽管维度可以保持一致。
减少网络中的下采样是一种tradeoff的方法:虽然filter可以获得更详细的信息,但是感受野变小了,计算时间也更长。同样,shift-and-stitch也是一种tradeoff的方法:虽然可以在不减小感受野的前提下获得dense prediction,但是filter却无法获得更详细的信息。
虽然我们对shift-and-stitch进行了一些实验,但是我们并没有在我们的模型中使用它。我们发现上采样(upsampling)是一种更为有效的方法。我们将在下一节介绍上采样。
3.3.Upsampling is backwards strided convolution
另一种从coarse outputs到dense outputs的方法是插值(interpolation)。
反卷积(backwards convolution或deconvolution)是一种自然的上采样方式。通过插值+卷积的方式实现,有两种实现方式:
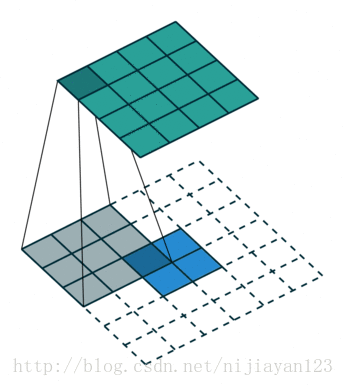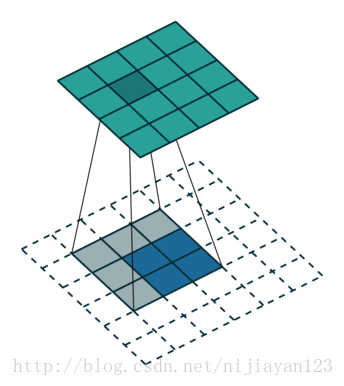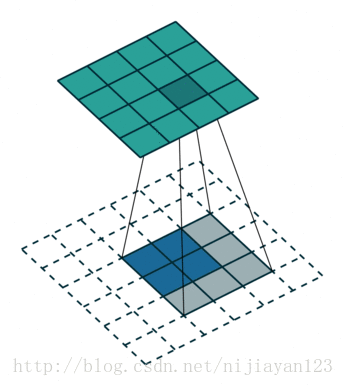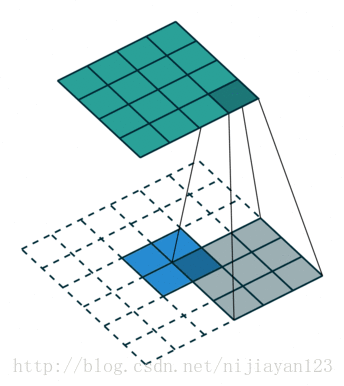
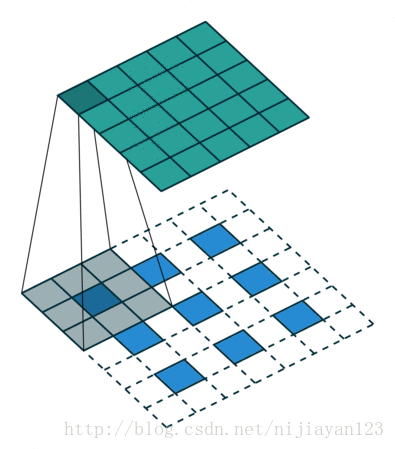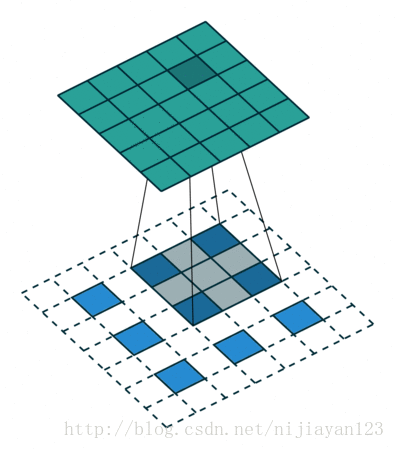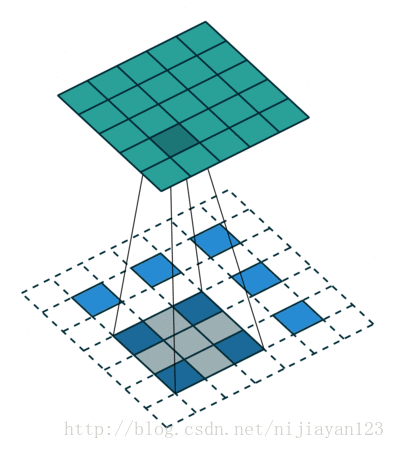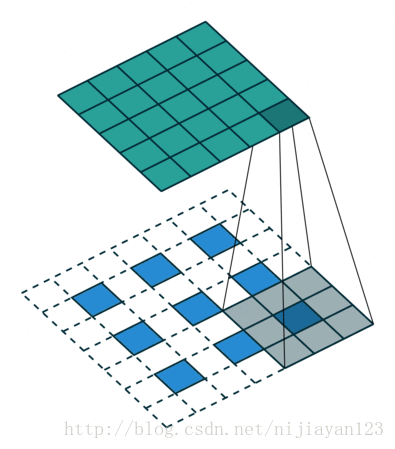
在网络上查阅资料时,也有人说ZFNet中的反卷积方法才是标准的。
反卷积所用的filter不需要固定,是可以被学习的,即通过梯度下降法进行参数更新。
我们通过实验发现上采样是一种更为快速和有效获得dense prediction的方法。我们最佳的分割框架就使用了这种方法(详见第4.2部分)。
3.4.Patchwise training is loss sampling
patchwise的训练和全卷积训练都可以产生任意的分布,其计算效率取决于重叠部分和minibatch的大小。
在第4.3部分,我们尝试了采样训练(training with sampling),但是发现这样并不能使dense prediction更快收敛。全图训练(whole image training)更有效。
4.Segmentation Architecture
我们将ILSVRC中的分类模型转换成FCN,通过上采样和pixelwise loss使其进行dense prediction。我们通过fine-tune训练分割模型。并且,我们在层之间增加skip,以融合粗糙语义信息和局部外观信息。
我们的训练和验证都基于PASCAL VOC 2011分割挑战(所用的数据集)。训练时忽略了难以定义GT的像素(比如过于模糊)。
4.1.From classifier to dense FCN
我们考虑了AlexNet(使用Caffe提供的版本)、VGG16(使用Caffe提供的版本)和GoogLeNet(目前没有GoogLeNet的官方公开版本,所以这里我们使用自己实现的版本,在ILSVRC上获得了68.5%的top-1准确率和88.4%的top-5准确率)。在这个任务下,我们发现VGG16和VGG19有着一样的表现。对于GoogLeNet,我们只使用了最后的loss layer,并通过去掉最后的average pooling layer提升了模型性能。对于每个分类网络模型,最后的分类层都被丢弃,并将FC层转换成卷积层。测试结果见表1:

在表1中,我们将这三个分类模型都扩展为FCN。基于PASCAL VOC 2011验证集,我们比较了三种FCN模型的平均IoU(即mean IU)以及推理时间(取20次实验的均值,输入为$500\times 500$大小,使用的显卡为NVIDIA Tesla K40c)。我们还列出了一些其他的细节:参数层的数量、感受野的大小(rf size)以及最大步长。这些结果是基于固定学习率得到的最优结果。
结合Fig3,明白了这里说的最大步长(max stride)指的是通过5次上采样,每次步长为2,所以是$2^5=32$。
fine-tune由分类模型转换得到的分割模型。即使是最差的模型,也达到了SOTA方法大约75%的性能。FCN-VGG16在验证集上的平均IoU达到了56.0(SOTA),在测试集上为52.6。使用额外的数据进行训练将FCN-VGG16的mean IU提升至59.4,FCN-AlexNet的mean IU提升至48.0。尽管VGG16和GoogLeNet在分类任务中有着相近的表现,但是在分割任务中,二者表现却相差甚远。
4.2.Combining what and where
除了基于原有的分类模型进行改造,我们也提出了一个新的用于分割的FCN模型,见Fig3:
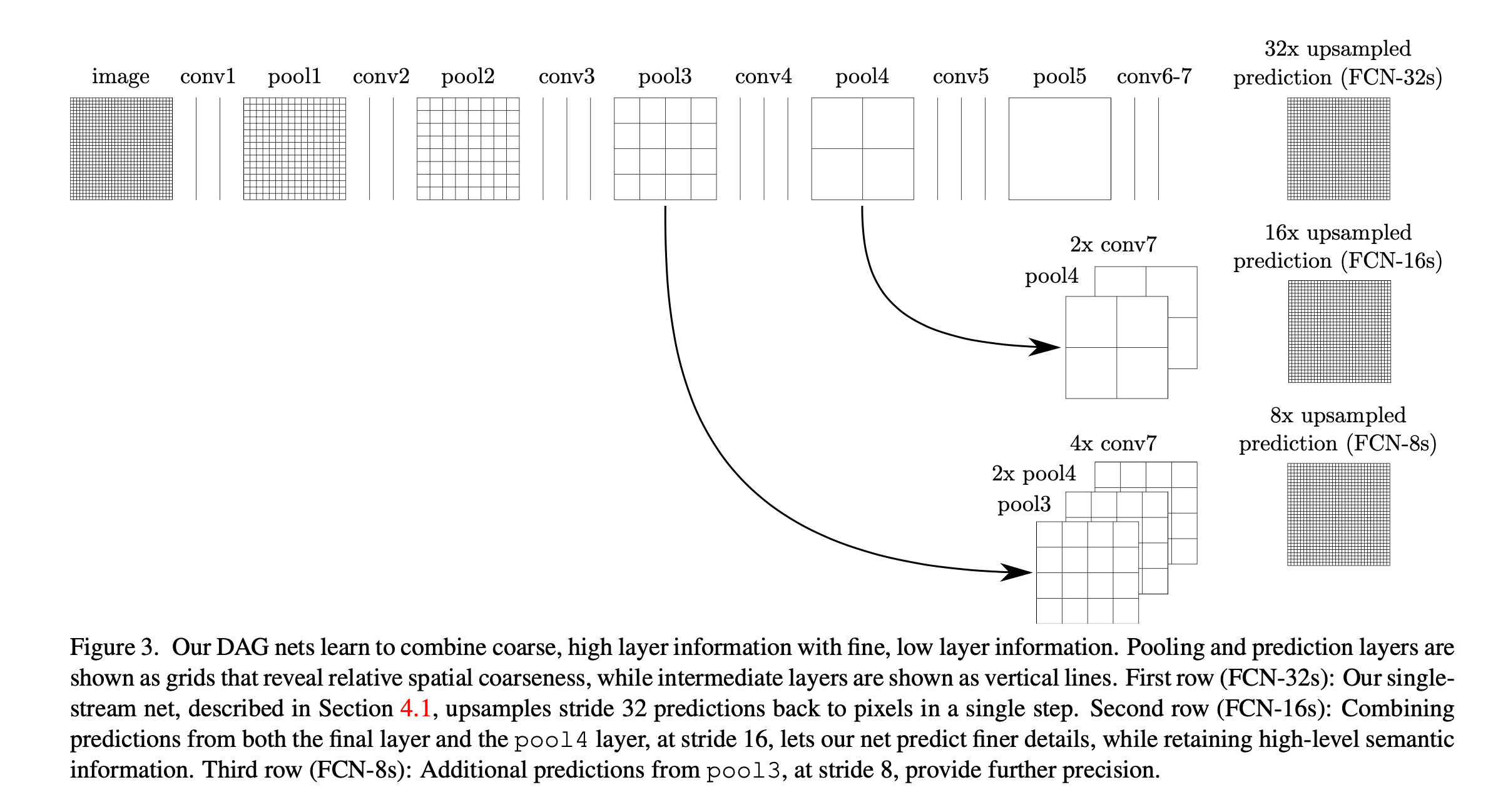
Fig3也很好理解,第一行为普通的FCN结构,通过32倍上采样(即5次上采样),称为FCN-32s(第4.1部分的模型基本都属于FCN-32s)。为了能让浅层精细的信息和深层粗糙的信息结合起来,作者添加了skip。Fig3的第二行将conv7上采样一次(即2x)后和pool4相结合(可以理解为拼接在一起,二者维度是一样的),然后上采样4次(即16x),这种结构称为FCN-16s。类似的,Fig3的第三行,conv7上采样2次+pool4上采样1次+pool3拼接在一起,然后上采样3次(即8x),这样的结构称为FCN-8s。3种结构的结果见Fig4:
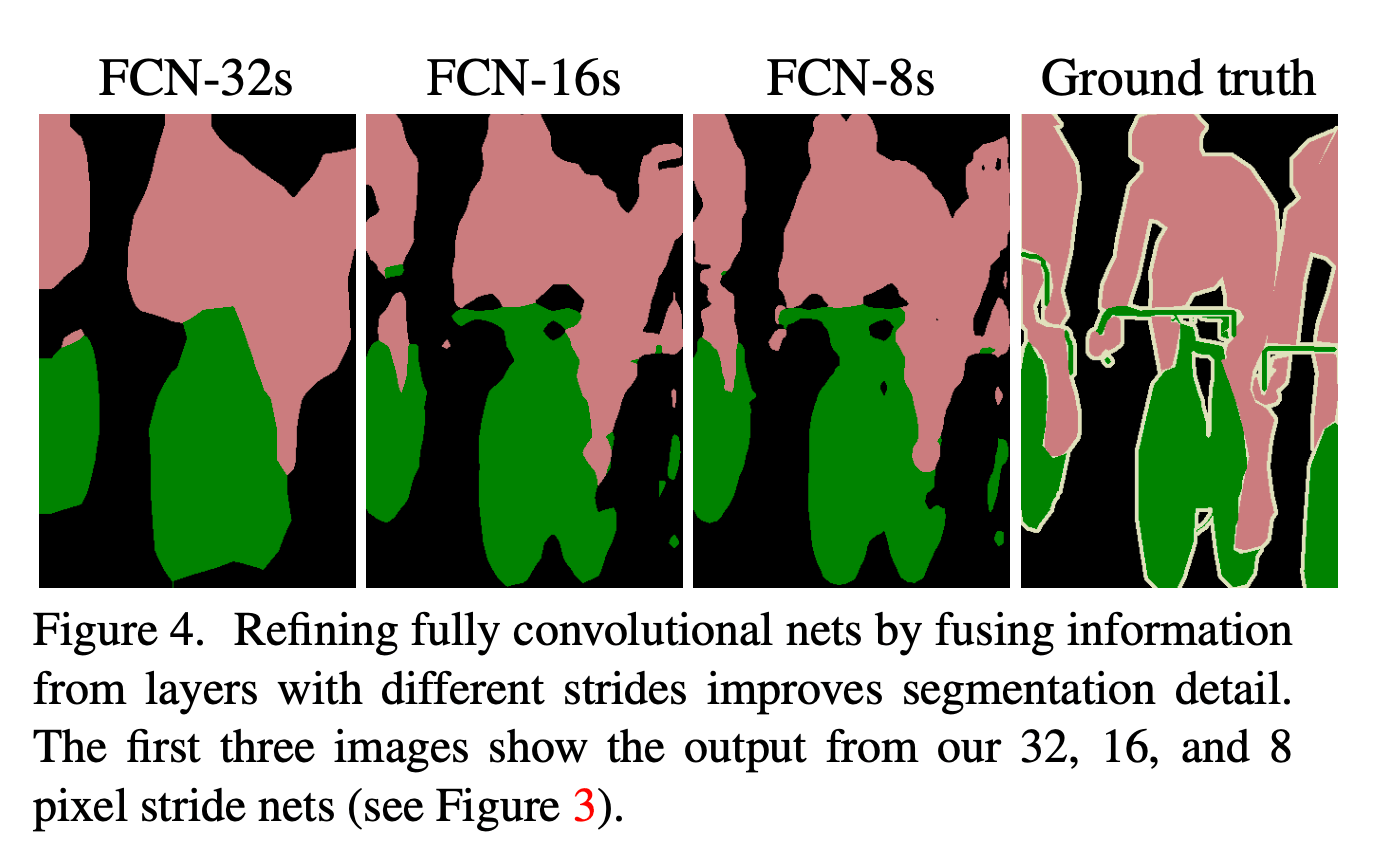
FCN-32s的分割效果最差。FCN-16s稍微好一点,FCN-8s效果最优。
使用FCN-32s的参数初始化FCN-16s,FCN-16s新增的参数用0初始化。
skip结构的加入将FCN-16s在验证集上的mean IU提升至62.4,FCN-8s在验证集上的mean IU提升至62.7。
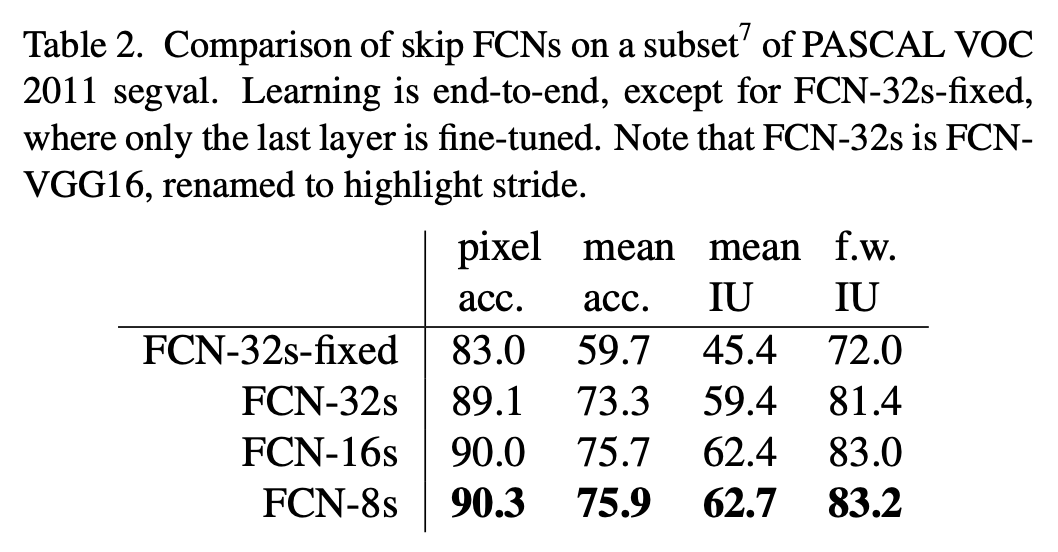
表2中,FCN-32s-fixed指的是只有最后一层被fine-tune,FCN-32s基于VGG16。
👉Refinement by other means
降低pooling层的步长是得到更精细预测结果最直接的方法。但是我们基于VGG16的模型并不适合这种办法,如果我们把pool5的步长改为1,就需要FC6使用$14\times 14$大小的kernel,这样做除了增加计算成本之外,我们很难学习一个这么大的卷积核。我们尝试重新构建pool5之前的层以使得FC6可以使用更小的卷积核,但是这样做效果并不好,一个可能的解释是上层的ILSVRC初始化很重要。
另一个获得更精细结果的方法是使用shift-and-stitch(见第3.2部分)。但在有限的实验中,我们发现这种方法的提升成本比分层融合(layer fusion,即本节介绍的拼接不同层的方法)要差。
4.3.Experimental framework
👉Optimization:训练使用MBGD+momentum,minibatch size=20。学习率是固定的,FCN-AlexNet的学习率为$10^{-3}$,FCN-VGG16的学习率为$10^{-4}$,FCN-GoogLeNet的学习率为$5^{-5}$。momentum=0.9,weight decay=$5^{-4}$或$2^{-4}$。我们使用0初始化class scoring layer,因为随机初始化既不能加快收敛也不能获得更好的性能。原始分类网络的dropout被保留。
👉Fine-tuning:我们fine-tune了所有层。从表2可以看到,只fine-tune最后一层只能获得fine-tune所有层70%的性能。考虑到训练原始分类网络所需要的时间,training from scratch显然是不可行的。在单块GPU上,通过fine-tune得到FCN-32s花了三天时间。然后又各花了一天时间升级得到FCN-16s和FCN-8s。
👉More Training Data:PASCAL VOC 2011分割训练集有1112张带标签图像。此外,又使用了“B. Hariharan, P. Arbelaez, L. Bourdev, S. Maji, and J. Malik. Semantic contours from inverse detectors. In International Conference on Computer Vision (ICCV), 2011.”提供的8498张带标签的PASCAL训练图像。更多的训练数据使得FCN-VGG16的mean IU提升了3.4,达到了59.4。
👉Patch Sampling:如Fig5所示,全图训练和patch sampling的效果差不多(见Fig5左),但是全图训练的收敛速度更快(见Fig5右)。
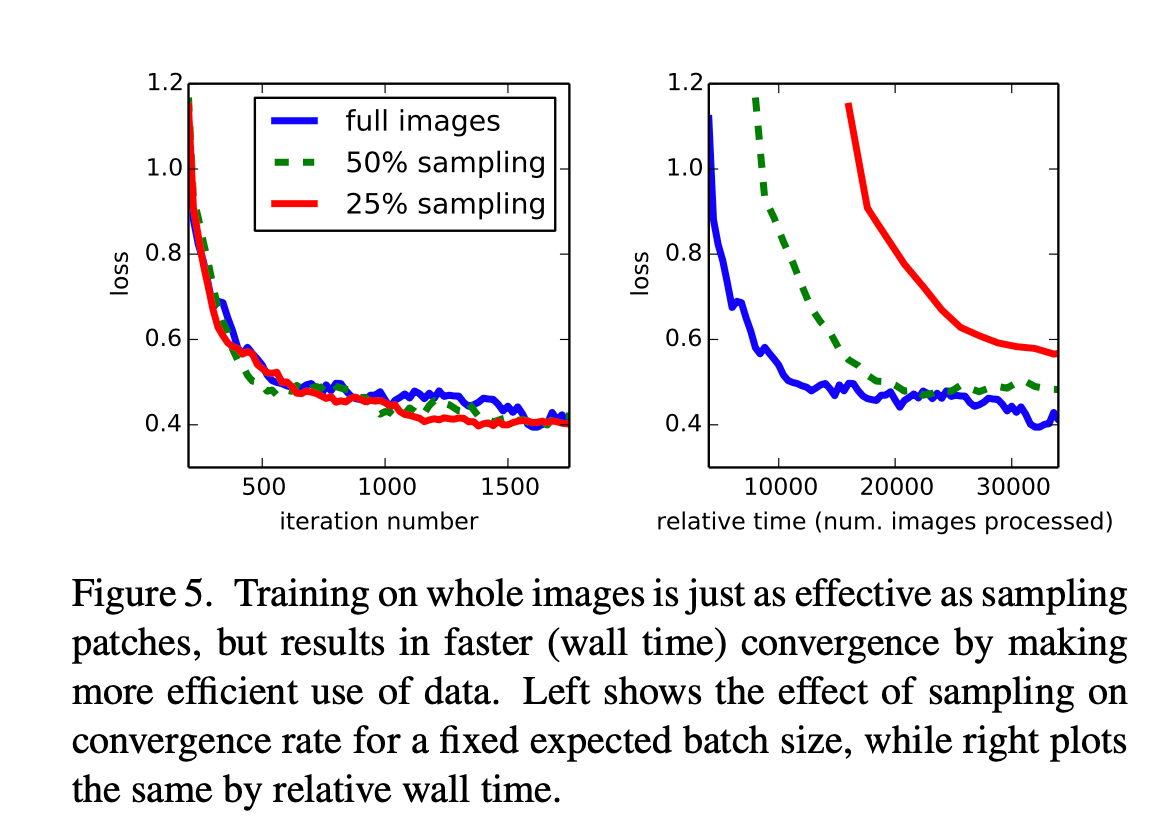
👉Class Balancing:全卷积训练可以通过加权或采样的方法来进行类别平衡。虽然我们的类别很不平衡(大约3/4都是背景),但是我们发现类别平衡不是必要的。
👉Dense Prediction:通过反卷积得到和输入维度一样的输出。
👉Augmentation:我们尝试通过镜像和抖动来扩展训练数据集,但是发现并没有带来性能的提升。
👉Implementation:所有模型的训练和测试都使用Caffe,并基于单个NVIDIA Tesla K40c GPU。我们的模型以及代码都是开源的,地址:https://github.com/shelhamer/fcn.berkeleyvision.org。
5.Results
我们在语义分割和场景解析任务(基于PASCAL VOC,NYUDv2,SIFT Flow数据集)中测试了FCN。
👉Metrics:模型评估使用以下常用指标($n_{ij}$表示类别$i$被预测为类别$j$的像素点个数,$t_i = \sum_j n_{ij}$表示真实类别为$i$的像素点的个数,$n_{cl}$表示类别个数):
-
pixel accuracy:
\[\sum_{i} n_{ii} / \sum_i t_i\] -
mean accuraccy:
\[(1/n_{cl}) \sum_i n_{ii} / t_i\] -
mean IU:
\[(1/n_{cl}) \sum_i n_{ii} / (t_i +\sum_j n_{ji} - n_{ii})\] -
frequency weighted IU:
\[(\sum_k t_k)^{-1} \sum_i t_i n_{ii} / (t_i +\sum_j n_{ji} - n_{ii})\]
👉PASCAL VOC:FCN-8s在PASCAL VOC 2011和2012测试集上的表现见表3。并和之前SOTA的方法:SDS、R-CNN进行比较。FCN-8s取得了最高的mean IU,并且推理速度也快了很多。

在Fig6中,基于PASCAL数据集,我们展示了我们的最优模型FCN-8s和之前SOTA的方法SDS的结果对比。

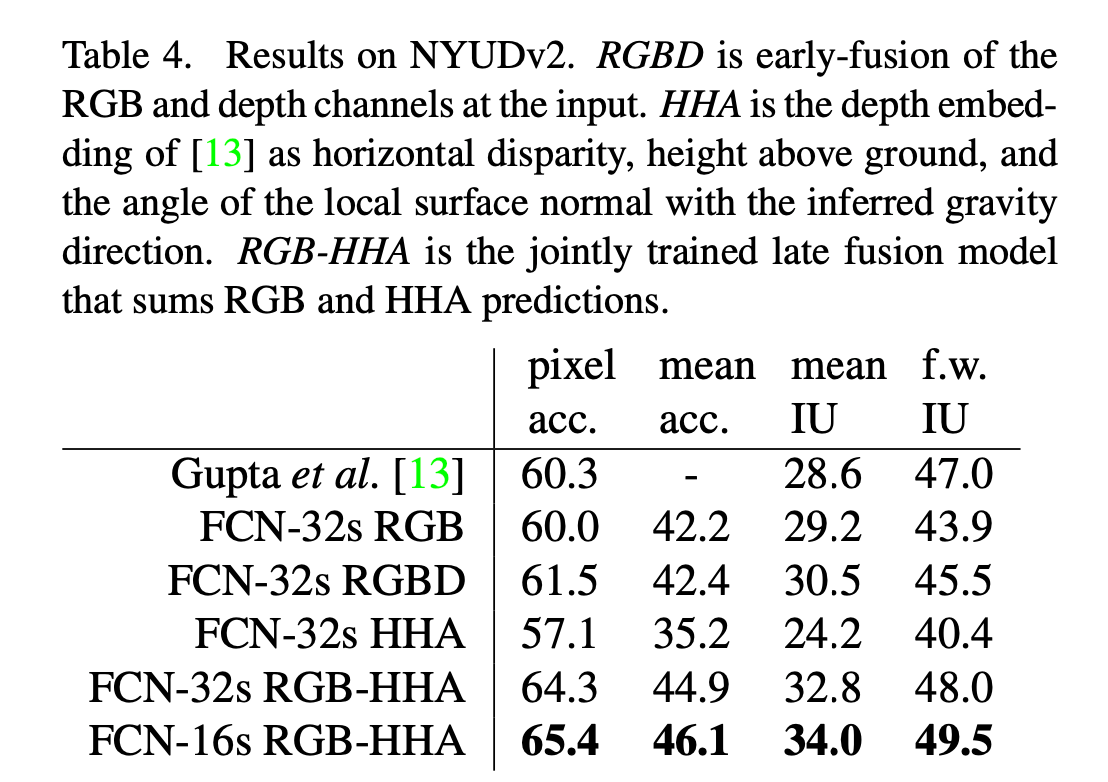
👉NYUDv2:我们的测试结果基于标准的数据集:795张训练图像和654张测试图像。测试结果见表4。加入深度信息后,结果稍微变好了一点(FCN-32s RGB vs. FCN-32s RGBD)。我们也尝试了以HHA作为输入。最终,FCN-16s RGB-HHA取得了最好的结果。
HHA:
- H:horizontal disparity,水平视差。
- H:height above ground,离地高度。
- A:the angle of the local surface normal with the inferred gravity direction,局部表面法线与推断重力方向的角度。
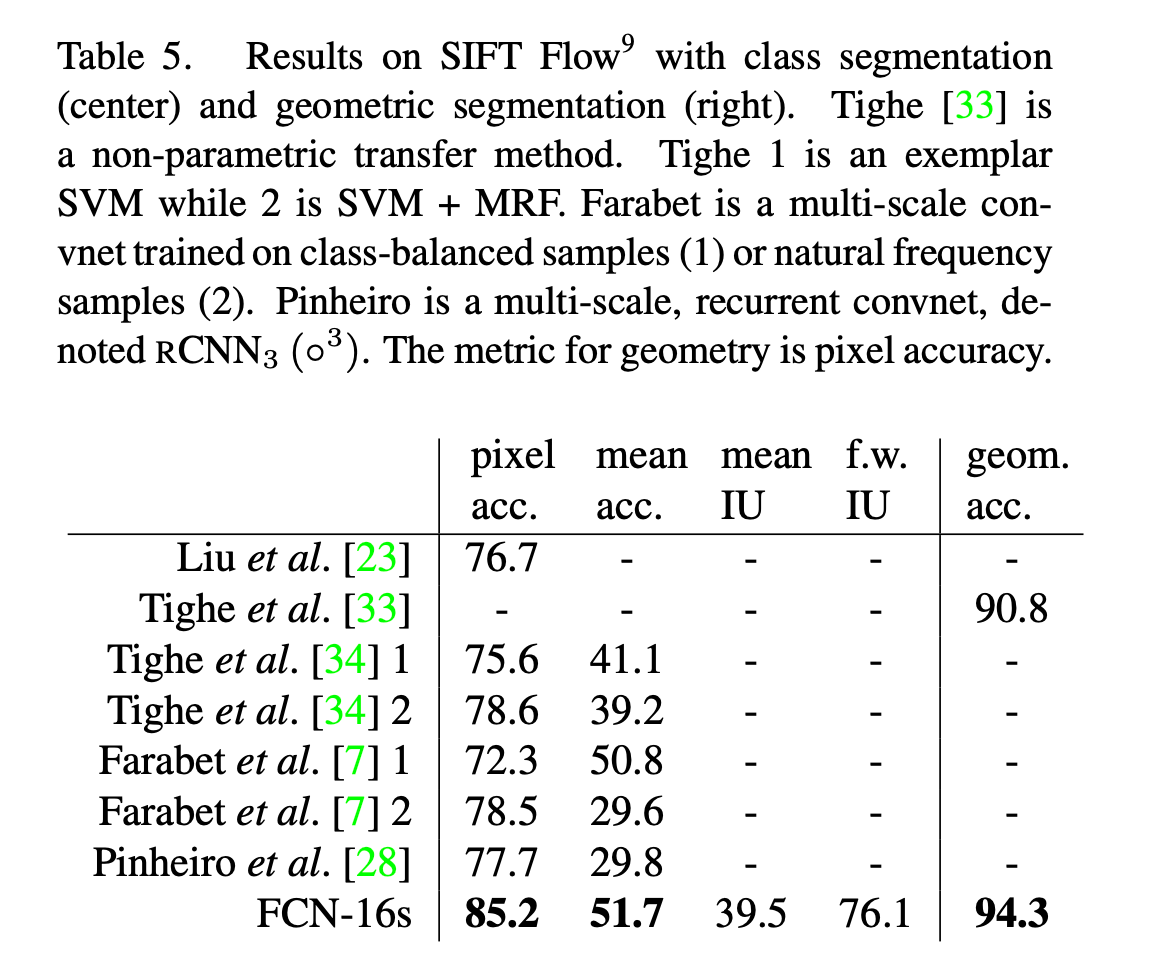
👉SIFT Flow:该数据集包含有2688张带像素标签的图像,共有33个语义类别(例如桥、山、太阳等)和3个几何类别(水平、垂直和天空)。FCN可以学习并预测两种类型标签的联合表示。结果见表5。数据集划分为2488张训练图像和200张测试图像。FCN-16s在两种标签任务中都是表现最优的。
6.Conclusion
FCN是一类丰富的模型,分类网络就是其中的一个特例。将分类网络扩展到语义分割,并通过multi-resolution layer combinations来改善网络结构,达到SOTA,并且简化和加快了学习和推理速度。
7.原文链接
👽Fully Convolutional Networks for Semantic Segmentation
