本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
我们针对YOLO框架(YOLOv1,YOLOv2、YOLO9000)只是做了一些小的改动和优化,形成了YOLOv3。
2.The Deal
2.1.Bounding Box Prediction
在YOLO9000中,我们使用聚类的方法产生anchor box。每个bounding box预测出4个坐标:$t_x,t_y,t_w,t_h$。假设cell的左上角相对于整幅图像的左上角的offset为$(c_x,c_y)$,anchor box的宽和高为$p_w,p_h$,那么预测结果为:
\[b_x = \sigma (t_x) + c_x\] \[b_y = \sigma (t_y) + c_y\] \[b_w = p_w e^{t_w}\] \[b_h = p_h e^{t_h}\]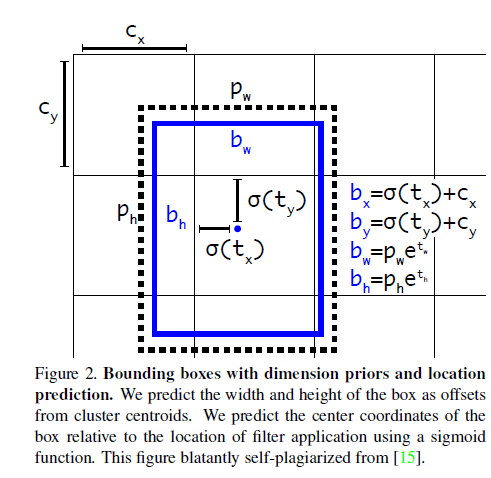
训练使用均方误差(sum of squared error loss)。
YOLOv3使用逻辑回归为每个bounding box都预测一个objectness score。不像Faster R-CNN,对于每个ground truth object,我们只分配一个bounding box prior。没有被分配到ground truth object的bounding box prior不会参与coordinate和class的loss计算,只保留objectness部分(的loss)。
2.2.Class Prediction
bounding box的类别标签可能有多个(比如某一object既属于woman,也属于person),对于这种multilabel classification任务,softmax函数就不是很合适。因此我们使用多个独立的逻辑回归二分类器。在训练时,对于类别的预测,使用binary cross-entropy loss。
这一策略也使得我们可以将算法移植到更复杂的Open Images Dataset。
2.3.Predictions Across Scales
对于聚类产生anchor,在YOLOv2中,是不是也有这种可能:对于整幅图像来说,整个数据集聚类得到k种anchor box的大小,如果是针对每个grid cell,好像没这个必要。

我们使用了3种不同scale的feature map来预测box(见上图)。对于每种scale的feature map,每个grid cell都负责预测3个box,所以输出的tensor维度为:$N \times N \times [ 3 * (4+1+80) ]$,4为bounding box的offset,1为objectness prediction,80为COCO数据集的类别数。
我们依然使用k-means生成anchor box。对于COCO数据集,一共使用了9种anchor box:$(10\times 13),(16 \times 30),(33\times 23),(30\times 61),(62\times 45),(59 \times 119),(116 \times 90),(156\times 198),(373\times 326)$。这9种anchor box我们随机均匀分配给3个scale的feature map,即每个scale的feature map分到3种anchor box。
2.4.Feature Extractor
我们使用一个新的网络用于特征提取,这个新的网络基于YOLOv2中的Darknet-19,我们添加了残差连接,我们将这个网络称之为Darknet-53:
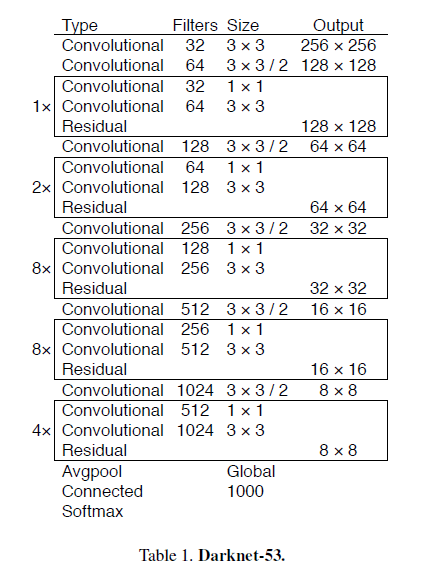
Darknet-53比Darknet-19性能更好,比ResNet-101、ResNet-152效率更高,其在ImageNet上的测试结果见下:

每个网络的参数配置都一样,图像大小均为$256 \times 256$,统计single crop准确率。run time在Titan X上进行测试。Darknet-53和SOTA分类器的性能相当,但是计算成本更低,速度更快。Darknet-53性能比ResNet-101要高,并且速度是ResNet-101的1.5倍快。Darknet-53和ResNet-152的性能相近,但是速度却是ResNet-152的2倍快。
Darknet-53每秒执行的浮点数计算(floating point operations)是最多的,说明Darknet-53对GPU的利用更为充分。ResNet因为层数太多,所以效率不高。
2.5.Training
我们在full image上进行训练,没有使用hard negative mining。使用multi-scale training和多种数据扩展方式、BatchNorm等一些标准操作。
3.How We Do
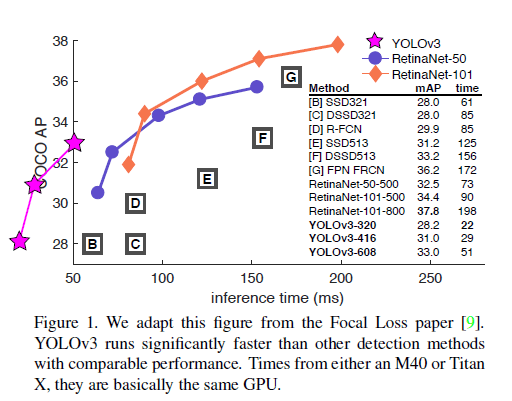
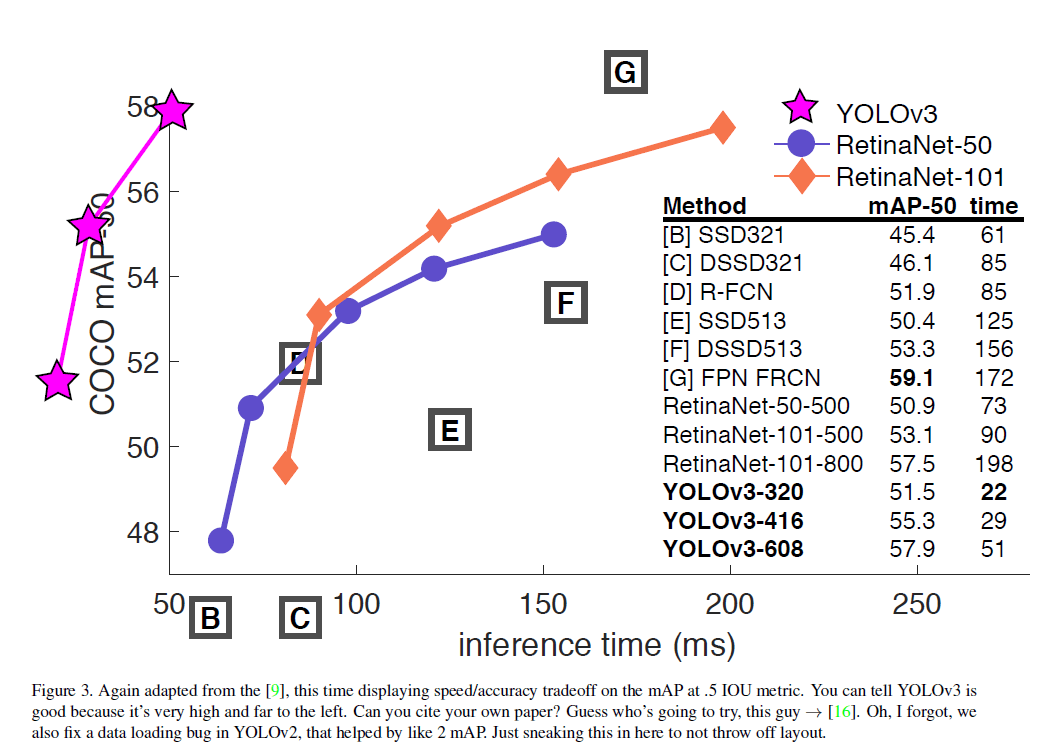
YOLOv3的结果相当好,见表3。使用了COCO中各种奇怪的AP指标作为评价标准,YOLOv3和SSD变体的性能相近,但速度快了3倍。但YOLOv3的性能远落后于RetinaNet。
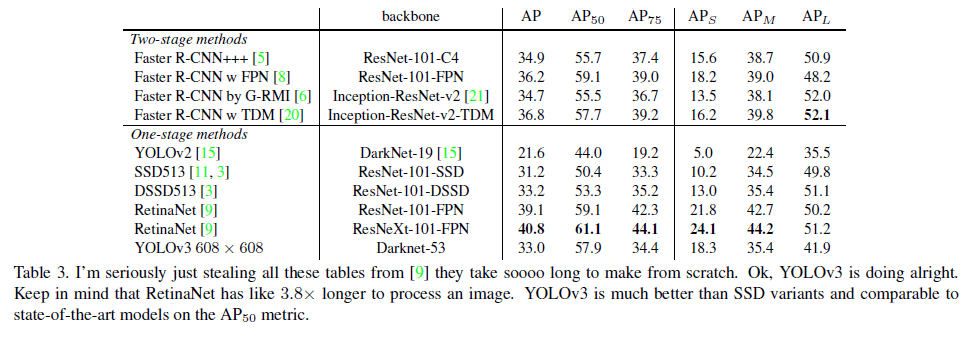
但是如果我们看一些老的常用的AP指标,例如$AP_{50}$(即IoU阈值为0.5时的mAP),YOLOv3的性能还是非常不错的,其和RetinaNet性能相当,且远优于SSD变体。但是当IoU的阈值变大时,例如$AP_{75}$,YOLOv3的性能会出现大幅的下滑。
之前的YOLO版本对小目标的检测并不好,但是YOLOv3对这一缺点进行了改进。$AP_S,AP_M,AP_L$分别代表对小型目标、中型目标、大型目标的检测结果。从表3中可以看到,YOLOv3在小目标检测上的结果还算可以,但是其检测精度依然远低于对中型目标和大型目标的检测精度。
4.Things We Tried That Didn’t Work
我们列出了尝试过却没有起作用的方法。
Anchor box x,y offset predictions.
使用$x,y$的offset(个人理解就是$t_x,t_y$),通过一个线性函数来预测bounding box的宽和高(最终使用的不是线性函数,而是一个指数函数)。我们发现使用线性函数预测bounding box的宽和高会降低模型的稳定性,效果并不好。
Linear x,y predictions instead of logistic.
在YOLOv2中,我们使用了逻辑回归来预测$t_x,t_y,t_w,t_h$,以限制其范围在0~1之间。我们尝试换成普通的线性模型,结果导致mAP大幅下降。
Focal loss.
我们尝试使用focal loss,导致mAP下降了2个百分点。
Dual IOU thresholds and truth assignment.
Faster R-CNN在训练过程中使用了两个IoU阈值:IoU>0.7为正样本,IoU在[0.3,0.7]之间会被忽略,IoU<0.3为负样本。我们也尝试了相似的策略,但结果并不好。
5.What This All Means
YOLOv3速度快,精度高。

6.原文链接
👽YOLOv3:An Incremental Improvement
