本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
代码和预训练模型:https://github.com/liuzhuang13/DenseNet。
CNN已经成为了目标检测领域主要的机器学习方法。最初的LeNet5只有5层,到VGG发展为19层,直到Highway Networks和ResNets才突破100层。
随着CNN变得越来越深,出现了一个新的问题:当输入或者梯度在穿过许多层后,其有可能会消失。许多研究都致力于解决这一问题,它们大多采用一个共同的思路:通过short path将前面的层和后面的层连接起来。
而我们提出的新框架,为了确保网络中各层之间信息流最大化,直接将所有层(大小一致)相互连接。为了保持前馈的特性,每个层可以从前面所有层获得额外的输入,并将自己的feature map传递给后面所有层。整体框架见Fig1。与ResNets相比,我们不是通过求和来组合特征,而是通过concat的方式来组合特征。因此,$l^{th}$会有$l$个输入,来自之前所有的卷积block。并且它自己的feature map也会传递给后续所有的$L- l$层。这就导致了一个$L$层的网络会有$\frac{L(L+1)}{2}$次连接,而不是像传统框架那样只有$L$次连接。鉴于其密集连接的模式,我们将我们的方法称为Dense Convolutional Network (DenseNet)。
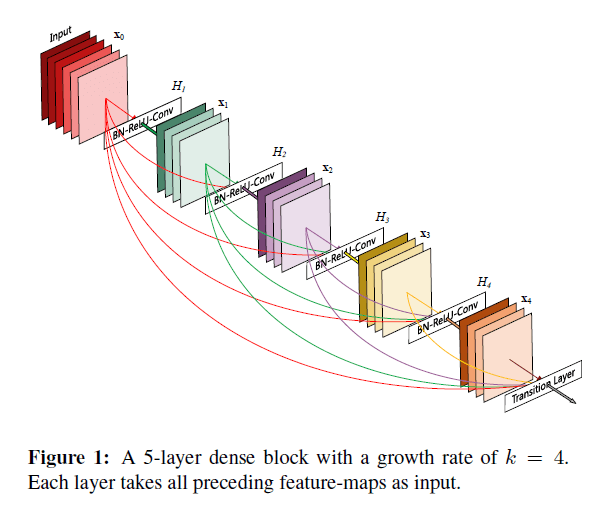
以Fig1为例,一共有$L=5$层,第一层有5次连接,第二层有4次连接,剩余的以此类推,第5层只有1次连接,所以总连接数就是$5+4+3+2+1$。因此如果是$L$层,那么总连接数就是$1+2+3+…+L=\frac{(1+L)L}{2}$。
这种密集连接的模式相比传统CNN网络框架,其参数量更少。除此之外,DenseNet的另一大优势是改善了整个网络的信息流和梯度流,使其更加易于训练。并且,密集连接还有一定的正则化效果,减少了过拟合的现象。
我们在4个benchmark datasets(CIFAR-10、CIFAR-100、SVHN、ImageNet)上评估了DenseNet。我们在大多数任务上都得到了SOTA的结果。
2.Related Work
不再详述。
3.DenseNets
输入为单张图像$x_0$。网络一共有$L$层,每一层$l$都执行一个非线性变换$H_l(\cdot)$。$H_l(\cdot)$可以是BatchNorm、ReLU函数、Pooling操作、卷积操作或者其组合。把第$l^{th}$层的输出记为$x_l$。
对于传统的CNN网络有$x_l = H_l (x_{l-1})$。而ResNets添加了skip-connection:
\[x_l = H_l (x_{l-1}) + x_{l-1} \tag{1}\]ResNets的优点之一就是利于梯度的传播。但其通过求和来组合特征的方式可能会阻碍网络中的信息流。
👉Dense connectivity.
为了改善层之间的信息流,我们引入了密集连接。也就是说,第$l^{th}$层会接收之前所有层的feature map作为输入:
\[x_l = H_l([x_0,x_1,…,x_{l-1}]) \tag{2}\]其中$[x_0,x_1,…,x_{l-1}]$表示将第$0,…,l-1$层输出的feature map concat在一起。
👉Composite function.
我们将$H_l(\cdot)$定义为3个连续的操作:先是BatchNorm,然后是ReLU,最后是一个$3 \times 3$的卷积。
👉Pooling layers.
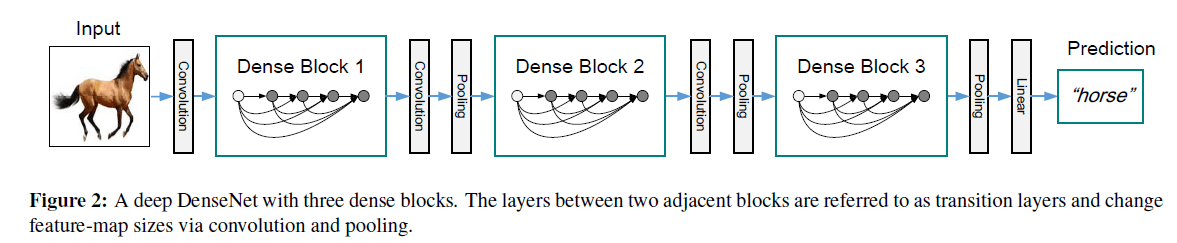
如果feature map的尺寸改变了,之前的concat策略就无法再使用了。但是下采样feature map又是CNN中一个很重要的部分。为了解决这一问题,我们划分了多个dense block,见Fig2。block之间的连接部分称为transition layers,用于执行卷积和pooling操作。我们实验所用的transition layers包括一个BatchNorm层,一个$1\times 1$卷积层,最后是一个$2\times 2$ average pooling层。
👉Growth rate.
如果每个$H_l$都可以生成$k$个feature map,那么第$l^{th}$层的输入将会有$k_0 + k \times (l-1)$个feature map,其中,$k_0$为网络输入层的通道数。DenseNet和现有网络框架的一个重要区别就是,DenseNet可以有非常窄(即通道数很少)的层,比如$k=12$。我们将超参数$k$称为网络的growth rate。我们会在第4部分证明,相对较小的growth rate就可以取得SOTA的成绩。
👉Bottleneck layers.
尽管每一层可以输出$k$个feature map,但通常每层会有更多的输入。如论文1和论文2中提到的那样,可以在每个$3 \times 3$卷积之前引入$1 \times 1$卷积作为bottleneck layer,来降低输入feature map的数量,从而提高计算效率。我们发现这种设计对DenseNet特别有效,我们把添加了bottleneck layer的模型记为DenseNet-B,其$H_l$定义为$\text{BN}-\text{ReLU}-\text{Conv}(1 \times 1)-\text{BN}-\text{ReLU}-\text{Conv}(3 \times 3)$。在我们的实验中,我们让每个$1\times 1$卷积产生$4k$个feature map。
👉Compression.
为了让模型变得紧凑,我们可以减少transition layers的feature map数量。如果一个dense block包含m个feature map,我们就让transition layer输出$\lfloor \theta m \rfloor$个feature map,其中$0 < \theta \leqslant 1$,$\theta$为压缩系数。当$\theta=1$时,则transition layer输出的feature map数量保持不变。我们将$\theta < 1$的DenseNet模型称为DenseNet-C,我们在实验中使用$\theta = 0.5$。如果即使用了bottleneck,又有$\theta < 1$,我们将这样的模型称为DenseNet-BC。
👉Implementation Details.
在除了ImageNet之外的所有数据集上,我们所用的模型都包含有3个dense block,且每个block有相同数量的层。在进入第一个dense block之前,先对输入图像进行一次卷积,输出为16通道的feature map(或者对于DenseNet-BC来说,输出通道数为growth rate的2倍)。卷积层的卷积核大小为$3 \times 3$,进行了zero-padding以保证feature map的大小不变。在两个dense block之间的transition layer包含一个$1 \times 1$卷积和一个$2\times 2$的average pooling。最后一个dense block后面是一个全局的average pooling,然后是一个softmax分类器。3个dense block的feature map的大小分别为$32 \times 32$、$16 \times 16$、$8 \times 8$。对于basic的DenseNet,我们测试了以下模型配置:$\{ L=40,k=12 \}$、$\{ L=100,k=12 \}$、$\{ L=100,k=24\}$。对于DenseNet-BC,我们评估了$\{ L=100,k=12 \}$、$\{ L=250,k=24 \}$、$\{ L=190,k=40 \}$。
在ImageNet的实验中,输入图像大小为$224 \times 224$,我们使用了有4个dense block的DenseNet-BC。初始卷积层有$2k$个$7 \times 7$的卷积,步长为2;其他所有层输出的feature map的数量都是$k$。在ImageNet上使用的网络配置见表1。

4.Experiments
我们在多个benchmark数据集上测试了DenseNet,并主要和ResNet及其变体进行了比较。
4.1.Datasets
👉CIFAR.
两个CIFAR数据集中都是$32 \times 32$大小的彩色图像。CIFAR-10(C10)有10个类别,CIFAR-100(C100)有100个类别。训练集有50,000张图像,测试集有10,000张图像,我们从训练集中分出去了5,000张图像作为验证集。我们采用了在这两个数据集上被广泛使用的数据扩展策略:mirroring和shifting。我们用“+“表示使用了这种数据扩展策略,比如C10+。至于预处理,我们使用通道均值和标准差进行了归一化。对于最终运行,我们使用了所有的50,000张训练图像,并在测试集上进行了评估。
👉SVHN.
Street View House Numbers(SVHN)数据集中也都是$32 \times 32$大小的彩色图像。训练集有73,257张图像,测试集有26,032张图像,另外还有531,131张图像可用于额外训练。和多数研究一样,我们也没有使用任何的数据扩展,并从训练集分出去6,000张图像用作验证集。在训练阶段,我们选择最小验证误差的模型用于评估其在测试集上的表现。我们将像素值归一化到$[0,1]$。
👉ImageNet.
ILSVRC 2012分类数据集包含1.2M张图像用于训练,50,000张用于验证,共有1,000个类别。我们使用了数据扩展,并在测试阶段使用了single-crop或10-crop(大小都为$224 \times 224$)。我们在验证集上汇报了分类错误率。
4.2.Training
所有的训练都使用stochastic gradient descent(SGD)。在CIFAR数据集上,batch size=64,训练了300个epoch;在SVHN数据集上,batch size=64,训练了40个epoch。初始学习率为0.1,在训练总epoch数的50%和75%处分别将学习率除以10。在ImageNet数据集上,batch size=256,训练了90个epoch。初始学习率为0.1,在第30和第60个epoch处将学习率除以10。需要注意的是,DenseNet的原始实现内存占用较高。想要降低GPU内存消耗,请参考论文:G. Pleiss, D. Chen, G. Huang, T. Li, L. van der Maaten, and K. Q. Weinberger. Memory-efficient implementation of densenets. arXiv preprint arXiv:1707.06990, 2017.。
我们使用weight decay=$10^{-4}$和Nesterov momentum=0.9(没有衰减)。使用论文”K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.”中的权重初始化方法。对于没有使用数据扩展的3个数据集,即C10、C100和SVHN,除了第一个卷积层,后续所有卷积层后面都接一个dropout layer,且dropout rate为0.2。对于每个任务和模型配置,只评估一次测试结果。
Nesterov momentum:I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the importance of initialization and momentum in deep learning. In ICML, 2013.。
dropout layer:N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. JMLR, 2014.。
4.3.Classification Results on CIFAR and SVHN
在CIFAR和SVHN的结果见表2。
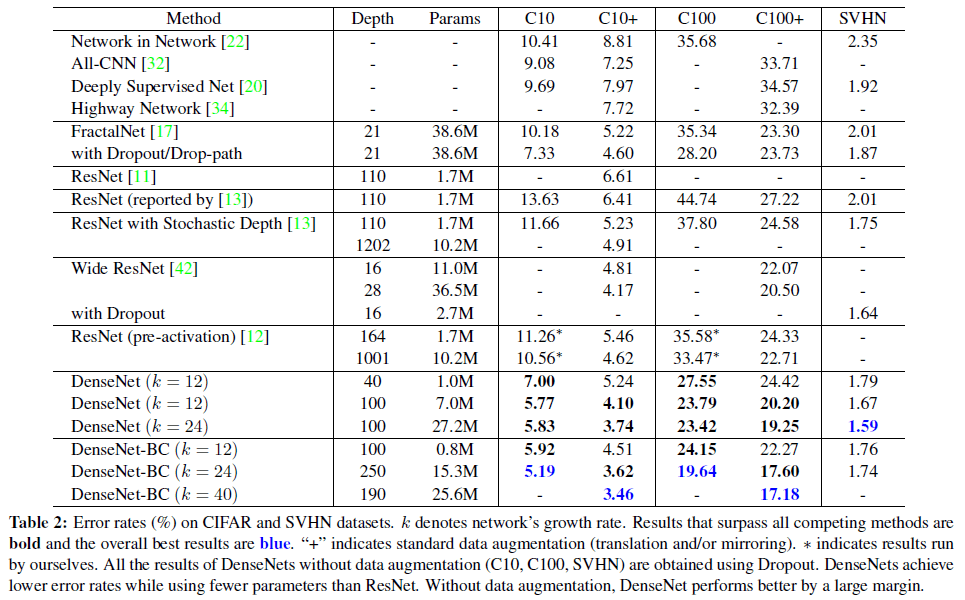
表2是在CIFAR和SVHN数据集上的错误率。$k$表示网络的growth rate。优于现有方法的结果用黑色粗体表示,最优结果用蓝色字体表示。“+“表示有标准的数据扩展(translation和/或mirroring)。*表示是我们自己运行的结果。相比ResNet,DenseNet的参数量更少,错误率也更低。如果都不使用数据扩展,DenseNet对性能的提升会更加明显。
👉Accuracy.
对表格信息的解读,不再赘述。这里需要注意的是,在SVHN数据集上,$L=250$的DenseNet-BC没有对$L=100,k=24$的DenseNet的性能进行进一步的提升,这可能是因为SVHN任务相对简单,过深的模型导致了过拟合。
👉Capacity.
在不考虑compression和bottleneck layers的情况下,DenseNet的总体趋势是随着$L$和$k$的增加,性能越来越好。我们将此归因于model capacity的增加。
👉Parameter Efficiency.
DenseNet比其他方法(尤其是ResNet)能更有效的利用参数。和1001层pre-activation的ResNet相比,$L=100,k=12$的DenseNet-BC少了90%的参数量,但是却达到了差不多的性能(在C10+上,4.51% vs. 4.62%;在C100+上,22.27% vs. 22.71%)。Fig4右图显示了这两个网络在C10+上的训练loss和测试错误率。
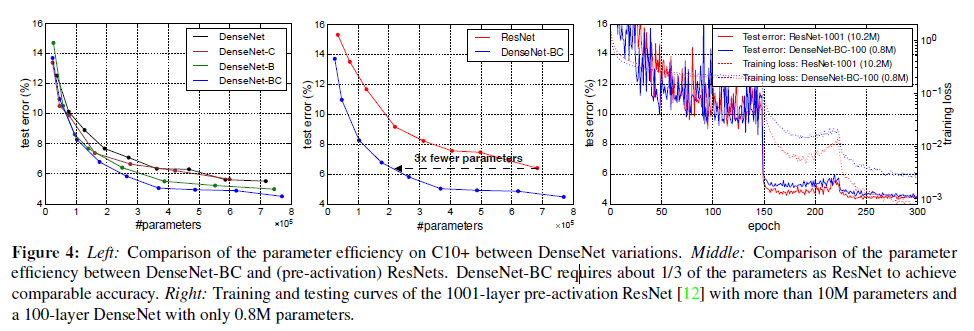
Fig4,左图是DenseNet不同变体在C10+上参数量和test error的关系对比。中间这张图是DenseNet-BC和(pre-activation)ResNets在参数量和test error上的关系对比。在相同test error下,DenseNet-BC的参数量比ResNet少了3倍。右图中,1001层pre-activation的ResNet参数量超过10M,100层的DenseNet参数量仅有0.8M。
👉Overfitting.
参数量少带来的一个优势就是DenseNet不太容易过拟合。
4.4.Classification Results on ImageNet
我们将不同深度和growth rates的DenseNet-BC和SOTA的ResNet框架进行了对比。为了公平的对比,我们消除了不同的前处理和优化设置等差异。
DenseNet在ImageNet上的结果见表3。
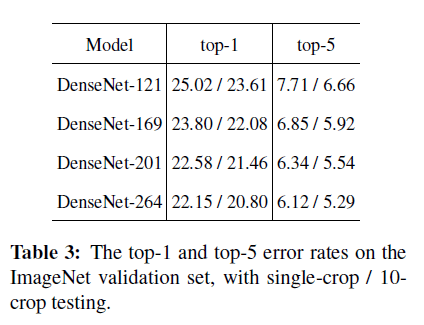
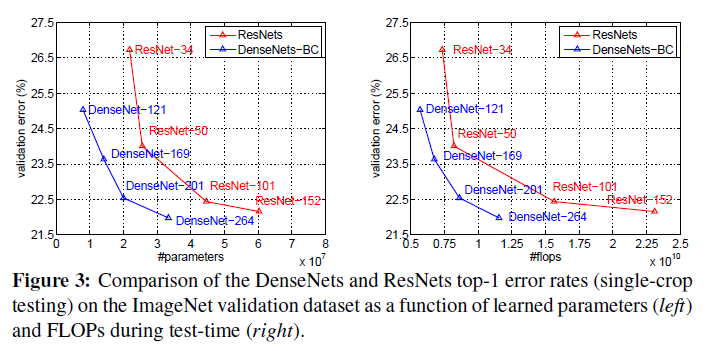
DenseNets和ResNets的对比结果见Fig3。
5.Discussion
表面看来,DenseNets和ResNets非常相似:只是把求和改成了concat操作。但就是这微小的修改导致了两种网络框架在本质上的不同。
👉Model compactness.
相比ResNets,DenseNets更加紧凑,参数效率更高,详见Fig3和Fig4。
👉Implicit Deep Supervision.
作者认为DenseNet表现好的一个可能原因是”deep supervision”,即各层之间连接更加紧密,会受到损失函数更多额外的监督。这种深层监督的好处已经在deeply-supervised nets(DSN)中得到了证实。
👉Stochastic vs. deterministic connection.
和论文”G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger. Deep networks with stochastic depth. In ECCV, 2016.”中的方法进行了比较(和DenseNet的作者都是同一个人:Gao Huang)。
👉Feature Reuse.
在设计上,DenseNet允许层访问先前所有的feature map(有时会通过transition layers)。我们进行了一个实验来调查训练好的网络是否利用了这一特性。我们在C10+上训练了一个$L=40,k=12$的DenseNet。对于block内的每个卷积层$l$,我们都计算了前面层$s$对其的权重。Fig5展示了3个dense block的heat map。
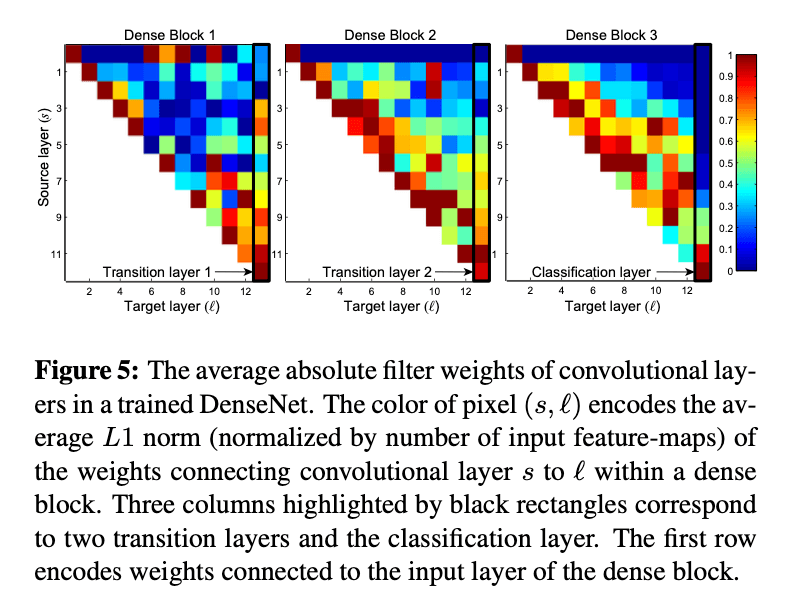
先前层$s$对卷积层$l$的权重就是对应filter中的权重值的绝对值平均(average L1 norm,并用输入feature map的数量进行归一化)。Fig5中$(s,l)$方块的颜色就代表着$s$对$l$的权重,颜色越红,权重越高。Fig5中,用黑框框住的三列分别对应着2个transition layers和1个classification layer。第一行是对输入层的权重可视化显示。
6.Conclusion
我们提出了一种新的卷积网络框架:Dense Convolutional Network(DenseNet)。其引入了具有相同feature map大小的任意两层之间的直接连接。DenseNet可以轻松的扩展到数百层,且不会存在优化困难。在我们的实验中,随着参数量的增加,DenseNet的精度持续改进,没有出现性能下降或过拟合。在多个数据集上都取得了SOTA的结果。并且,DenseNet所需的参数量更少,计算成本更低。此外,我们相信通过更详细的调整超参数和学习率可以进一步提高DenseNet的准确性。
