本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
我们提出的ResNeXt融合了VGG、ResNets和Inception模型(Inception-v1,Inception-v2/v3,Inception-v4)的思想,见Fig1所示。Fig1中,左右block的复杂度几乎一样。用名词“基数”(cardinality)来表示分支路径的数量。
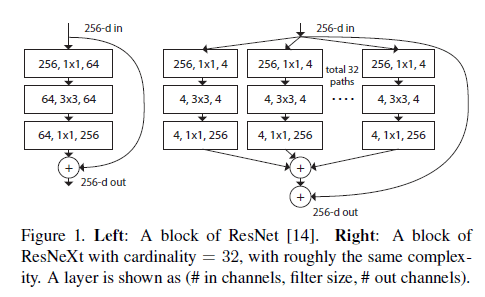
在ImageNet分类数据集上,ResNeXt的表现超过了ResNet-101/152、ResNet-200、Inception-v3和Inception-ResNet-v2。101层的ResNeXt相比ResNet-200精度更高,并且复杂度只有ResNet-200的50%。此外,ResNeXt的设计比所有Inception模型都要简单。ResNeXt在ILSVRC 2016分类任务中取得了第二名的成绩。我们还在ImageNet-5K和COCO目标检测数据集上进行了测试,ResNeXt的表现也都优于ResNet。
2.Related Work
不再赘述。
3.Method
3.1.Template
3.2.Revisiting Simple Neurons
最简单的神经元计算可以视为:
\[\sum_{i=1}^D w_i x_i \tag{1}\]用图表示为:
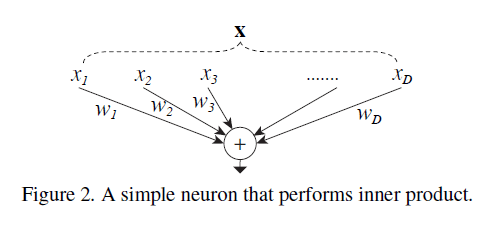
其也可以视为和Inception模块一样,分为三部分:splitting、transforming和aggregating。
- Splitting:将向量$\mathbf{x}$分割成低维度的$x_i$。
- Transforming:低维度的表征被转化,即$w_i x_i$。
- Aggregating:将转化结果聚合起来,即$\sum_{i=1}^D$。
3.3.Aggregated Transformations
通过3.2部分的分析,我们可以考虑将聚合转化结果这一步扩展为一个更通用的函数,这个函数本身也可以是一个网络。Network-in-Network是将网络沿着深度方向进行扩展,而我们的”Network-in-Neuron”则是沿着另一个新的维度进行扩展。
我们将聚合转化结果表示为:
\[\mathcal{F}(\mathbf{x}) = \sum_{i=1}^C \mathcal{T}_i (\mathbf{x}) \tag{2}\]其中,$\mathcal{T}_i(\mathbf{x})$可以是任意函数。
在式(2)中,$C$(即Cardinality)表示有多少个转化需要被聚合,类似于式(1)中的$D$,但不同之处在于$C$可以是任意数量。我们通过实验证明了基数(即$C$)在提升网络性能方面比宽度和深度更有效。
宽度(width)指的是一层内通道的数量。
在本文中,我们考虑用一种简单的方法来设计转化函数:所有的$\mathcal{T}_i$都是相同的拓扑结构,即Fig1右所示结构。
在式(2)的基础上加上残差连接:
\[\mathbf{y} = \mathbf{x} + \sum_{i=1}^C \mathcal{T}_i (\mathbf{x}) \tag{3}\]Fig1右,即Fig3(a)还有另外两种等效模式:Fig3(b)和Fig3(c)。
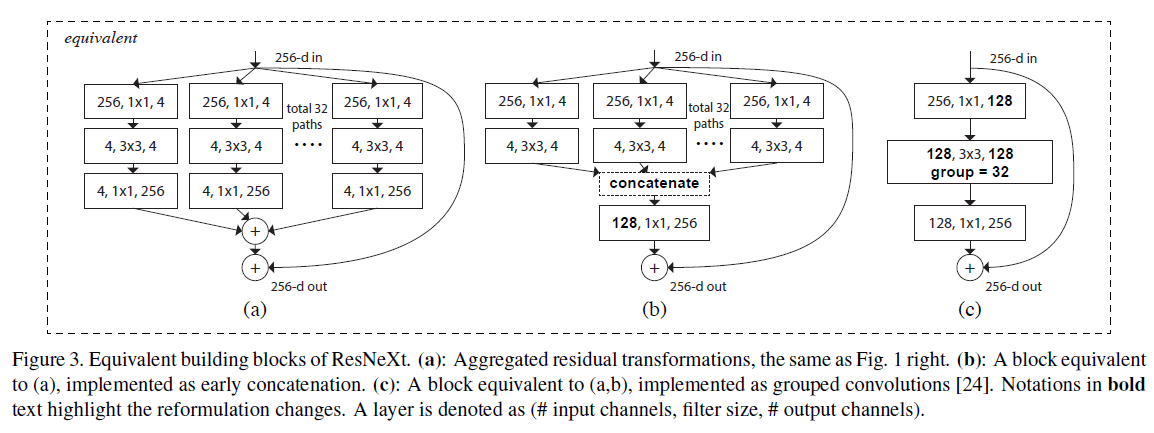
Fig3(c)中使用的分组卷积(grouped convolution)指的是AlexNet在多块GPU上并行计算的方式。
此外,需要注意的是,只有当block的深度大于等于3时,这种转化才是有意义的。Fig4是block深度为2的例子。

3.4.Model Capacity
在同等的模型容量(相同的模型复杂度和参数数量)下,我们的模型有着更高的准确性。
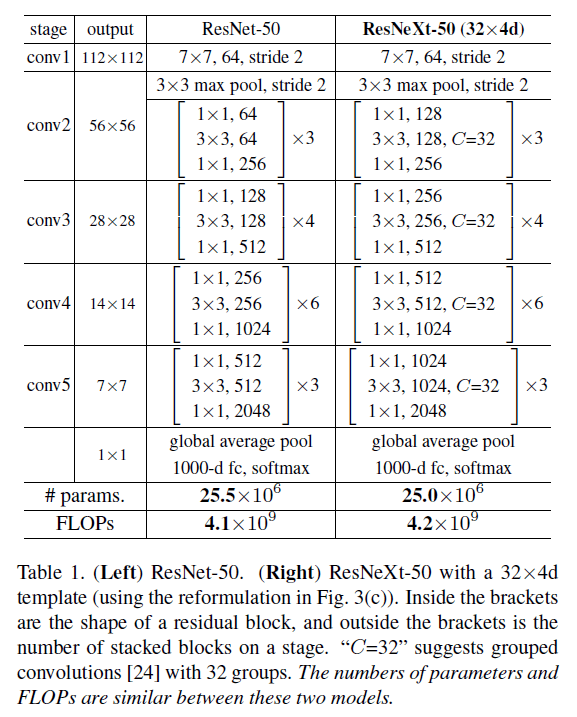
为了保证模型复杂度不变,基数和网络宽度的对应变化可见表2。

在Fig1左的block中,参数量约为$256 \cdot 64 + 3 \cdot 3 \cdot 64 \cdot 64 + 64 \cdot 256 \approx 70k$。在Fig1右的block中,参数量为:
\[C \cdot ( 256 \cdot d + 3 \cdot 3 \cdot d \cdot d + d\cdot 256 ) \tag{4}\]当$C=32,d=4$时,式(4)的结果约为70k。
4.Implementation details
ResNeXt的实现遵循ResNet和fb.resnet.torch。我们的模型通过Fig3(c)的形式来实现。在卷积之后使用了BN(如果是按Fig3(a)的形式实现,BN应该放在聚合转化之后,添加到shortcut之前)。BN之后是ReLU激活函数。Fig3的三种等效模式可以得到完全一样的结果,但Fig3(c)的实现更为简洁和高效。
5.Experiments
5.1.Experiments on ImageNet1K
我们在1000个类别的ImageNet分类任务上进行了消融实验。我们遵循ResNet构建了50层和101层的残差网络,并把其中的block替换成了我们提出的block。
👉Cardinality vs. Width.
如表2所示,在保证相同复杂度的情况下,对基数$C$和bottleneck width $d$进行了评估。结果见表3和Fig5。

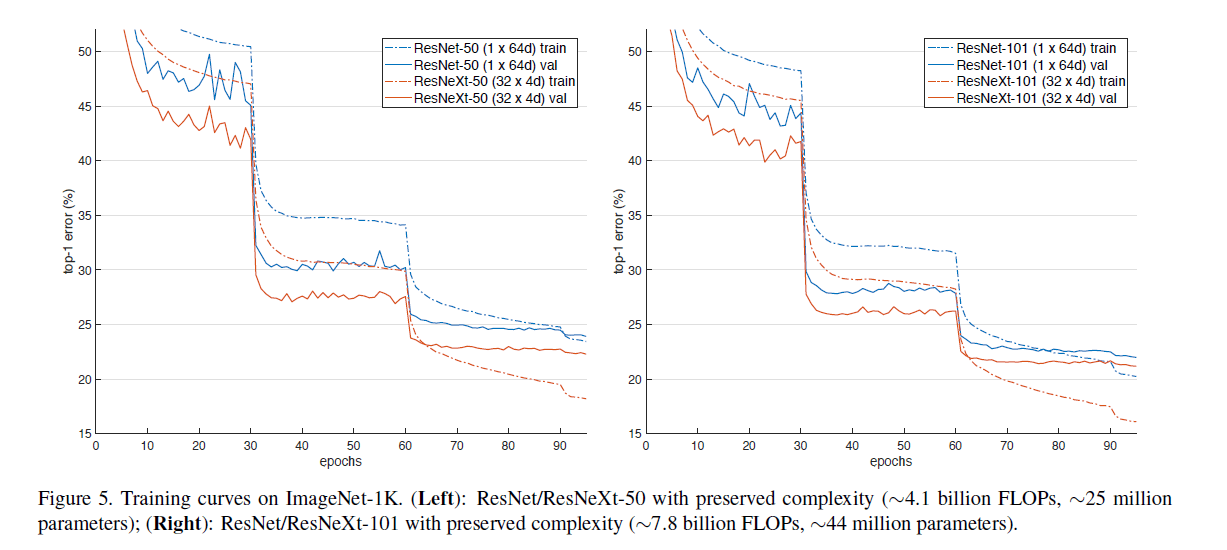
从表3中可以看出,随着$d$的减小,模型性能在不断上升。但我们认为$d$最小为4就可以了,再小就没意义了。
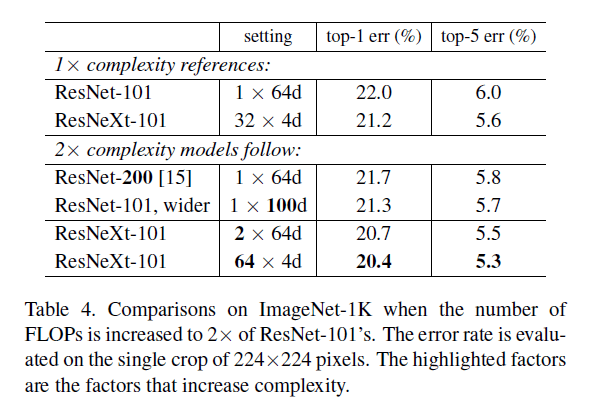
👉Increasing Cardinality vs. Deeper/Wider.
- Going deeper:使用ResNet-200。
- Going wider:增加bottleneck width。
- Increasing cardinality:把$C$翻倍。
上述策略都会把原始模型的FLOPs翻倍。比较结果见表4。
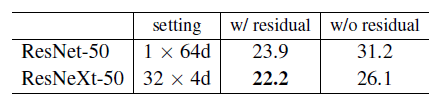
👉Residual connections.
是否使用残差连接的测试见下:
👉Performance.
我们直接使用了Torch内置的分组卷积实现,没有进行任何的优化。但其实现对并行化非常不友好。在8块M40 NVIDIA GPU上,表3中的$32 \times 4d$ ResNeXt-101处理一个patch需要0.95秒(batch size=256,输入图像大小为$224 \times 224$),而同等FLOPs的ResNet-101 baseline处理一个batch仅需要0.7秒。
👉Comparisons with state-of-the-art results.
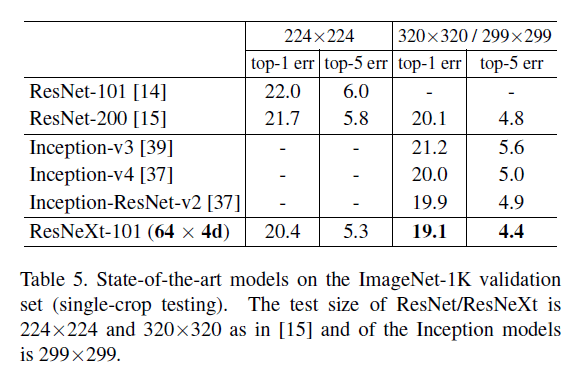
我们注意到很多模型(包括我们的模型)在使用了multi-scale或multi-crop testing后,在该数据集上的性能趋于饱和。
5.2.Experiments on ImageNet5K
鉴于在ImageNet-1K上的性能已经饱和了(饱和的原因不是模型本身,而是数据集的复杂性),因此在更大的ImageNet-5K数据集上进行了测试。
我们所用的5K数据集是ImageNet-22K的一个子集。这5000个类别包含ImageNet-1K中的1000个类别。这个5K数据集共有680万张图像,约为1K数据集的5倍。因为没有官方的训练集/验证集划分,所以我们在ImageNet-1K的验证集上进行评估。基于5K数据集的模型都是从头开始训练的。测试结果见表6和Fig6。
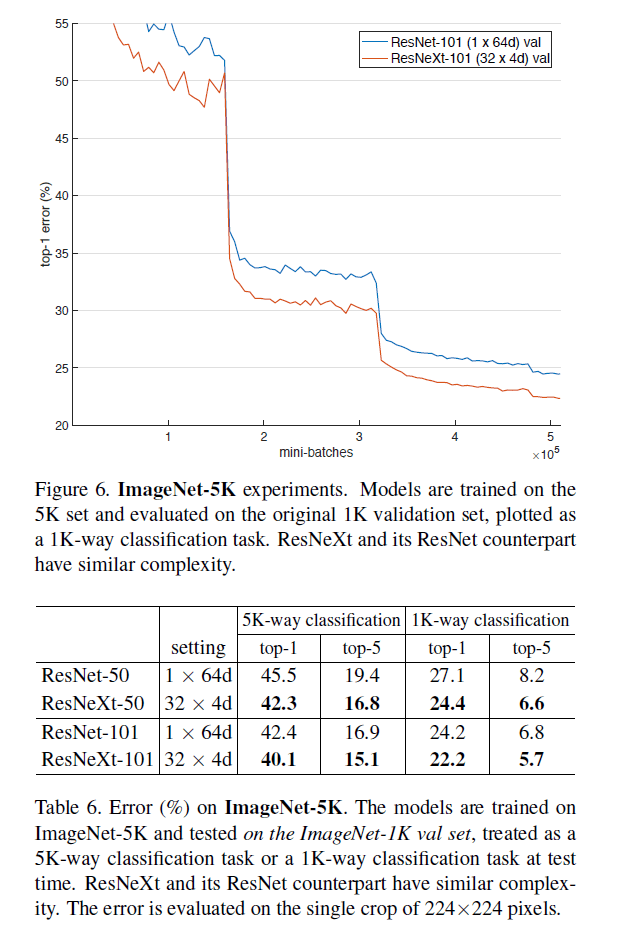
5K-way classification就是预测所有的5K个类别,但其余4K个类别都视为预测错误。1K-way classification就是只预测这1K个类别。
5.3.Experiments on CIFAR
我们在CIFAR-10和CIFAR-100上也进行了测试。我们使用这里的框架并把block替换成我们的block:
\[\begin{bmatrix} 1 \times 1,64 \\ 3 \times 3,64 \\ 1 \times 1, 256 \end{bmatrix}\]我们的网络开头是一个$3\times 3$卷积层,然后是3个阶段,每个阶段有3个残差块,最后是一个平均池化和一个全连接分类器(一共有29层)。使用了和这里一样的平移和翻转的数据扩展方式。更多实现细节见附件。
基于上述baseline模型,我们比较了两种增加复杂度的情况:(i)增加基数,固定width不变;(ii)增加bottleneck的width,固定基数为1。结果见Fig7。
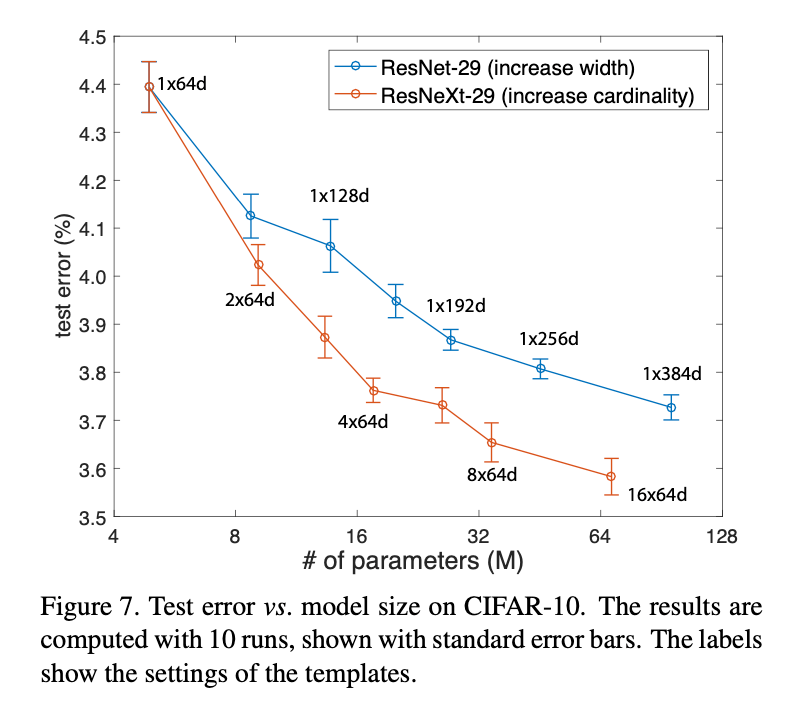
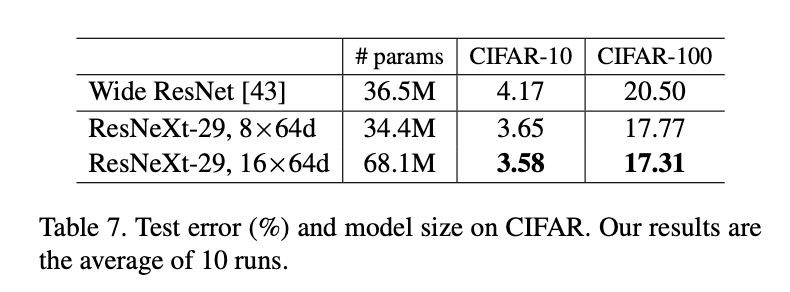
从Fig7可以看出,增加基数比增加width更有效。和Wide ResNet的比较见表7,我们较大的模型取得了SOTA的结果。
Wide ResNet:S. Zagoruyko and N. Komodakis. Wide residual networks. In BMVC, 2016.。
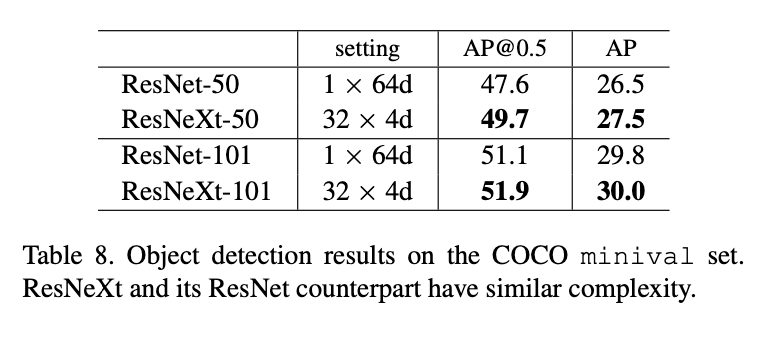
5.4.Experiments on COCO object detection
我们在80k训练集+35k验证子集上进行了训练,在5k的minival上进行了评估。我们采用基础的Faster R-CNN,并按照这里的做法把ResNet或ResNeXt嵌入进去。模型在ImageNet-1K上进行了预训练,并在目标数据集上进行了fine-tune。更多实现细节见附录。
结果见表8。在同等模型复杂度的情况下,我们的模型效果更好。
此外,Mask R-CNN也采用了ResNeXt,并在COCO实例分割和目标检测任务上都取得了SOTA的结果。
6.Appendix
6.A.Implementation Details: CIFAR
在50k训练集上训练模型,在10k测试集上进行评估。通过zero-padding将原始图像扩充到$40 \times 40$大小,然后再随机裁剪出$32 \times 32$大小的图像或者其翻转图像作为输入。没有使用其他的数据扩展方式。第一个$3 \times 3$卷积层有64个卷积核。一共有3个阶段,每个阶段都有3个残差块,3个阶段输出的feature map大小分别为32、16和8。网络结束是一个全局平均池化层和一个全连接层。当阶段变化时(即下采样时),width增加2倍。训练在8块GPU上进行,batch size=128,weight decay=0.0005,momentum=0.9。初始学习率为0.1,训练了300个epoch,在第150和第225个epoch时降低学习率。
6.B.Implementation Details: Object Detection
我们使用Faster R-CNN。为了简化,RPN和Fast R-CNN之间不共享特征(参见:Sharing Features for RPN and Fast R-CNN)。在RPN训练阶段,我们使用了8块GPU,每个GPU的batch内有2张图像,每张图像有256个anchor。RPN的训练,前120k个mini-batch的学习率为0.02,后60k个mini-batch的学习率为0.002。在Fast R-CNN训练阶段,我们同样也使用了8块GPU,每个GPU内一个mini-batch有1张图像和64个region。Fast R-CNN的训练,前120k个mini-batch的学习率为0.005,后60k个mini-batch的学习率为0.0005,weight decay=0.0001,momentum=0.9。
7.原文链接
👽Aggregated Residual Transformations for Deep Neural Networks
