本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
我们提出的用于实例分割的方法叫做Mask R-CNN,其通过在Faster R-CNN上新添加一个与类别分支和bounding box回归分支平行的一个mask分支,用于在每个RoI上预测分割mask,见Fig1。mask分支是应用在每个RoI上的一个小型FCN,通过pixel-to-pixel的方式预测分割mask。此外,mask分支只增加了很小的计算开销。
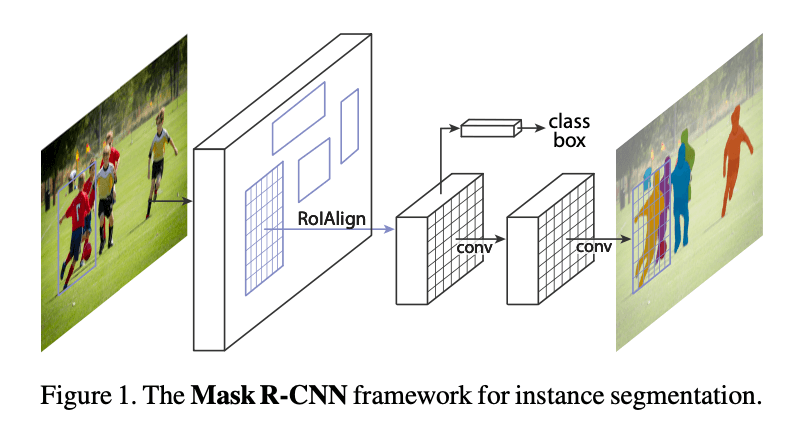
正确构建mask分支对于获得良好结果至关重要。因为Faster R-CNN设计的初衷并没有考虑输入和输出在pixel-to-pixel级别上的对齐问题,所以我们提出了RoIAlign用于获取精确的空间位置。尽管RoIAlign只是一个微小的改变,但其有着巨大的影响:其将mask精度提高了10%-50%。其次,我们发现将mask预测和类别预测解耦是非常重要的。
在COCO实例分割任务上,Mask R-CNN超过了以前所有的SOTA模型。此外,Mask R-CNN也擅长COCO目标检测任务。我们的模型可以在GPU上以每帧200ms的速度运行,使用8块GPU在COCO数据集上训练需要一到两天的时间。此外,我们还在COCO关键点检测任务上展示了我们框架的通用性。

2.Related Work
不再详述。
3.Mask R-CNN
Faster R-CNN对每个候选目标有两个输出:一个类别标签和一个bounding box offset,在此基础上,我们添加了第三个分支,用于输出目标mask。
👉Faster R-CNN:
参见:Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks。
👉Mask R-CNN:
Mask R-CNN同样也是two-stage,第一个stage也是RPN。在第二个stage,平行于预测类别和box offset的分支,Mask R-CNN对每个RoI多输出了一个二值mask。而许多主流的算法,分类需要取决于mask的预测结果。
在训练阶段,对每个RoI,我们定义了一个多任务loss:$L = L_{cls} + L_{box} + L_{mask}$。其中,$L_{cls}$和$L_{box}$的定义和Fast R-CNN中一样。mask分支对每个RoI输出的维度为$Km^2$,即$K$个分辨率为$m \times m$的二值mask,$K$表示类别数。$L_{mask}$是像素级别的交叉熵损失函数。假设RoI的真实类别是$k$,那么$L_{mask}$就只定义为$k$类别的mask(其他类别的输出对loss不起作用)。
我们解耦了mask预测和类别预测(在两个不同的分支),这有助于获得良好的实例分割结果。
👉Mask Representation:
我们使用FCN从每个RoI预测一个$m \times m$的mask。
👉RoIAlign:
在Fast R-CNN中,针对每个RoI,使用RoIPool将RoI提取为一个小的feature map(比如$7\times 7$)。RoIPool通常是将RoI细分为多个spatial bin(比如分成$7 \times 7$个bin),然后对每个bin进行特征值的聚合(比如通过max pooling的方式聚合)。这种量化导致了RoI和提取到的特征之间没有对齐。虽然这对分类来说可能影响不大,但它对预测mask有很大的负面影响。
为了解决这个问题,我们提出了RoIAlign层,见Fig3。

Fig3中,虚线网格表示feature map,实线表示RoI(本例中为$2 \times 2$个bin),每个bin内有4个采样点,每个采样点的值可以通过双线性插值从feature map上的附近网格点计算得到,然后再对这些采样点进行聚合(使用最大值或平均值)。这样就避免了量化。我们注意到,只要不进行量化,最终结果对采样点的位置和数量并不敏感。
👉Network Architecture:
将Mask R-CNN主要分为两部分:(i)backbone,用于在整个图像上提取特征;(ii)head,对每个RoI进行类别预测、bounding box回归以及mask预测。
backbone的命名方式为network-depth-features,比如原始的Faster R-CNN的backbone为ResNet-50-C4,C4表示backbone提取到的特征来自ResNet-50的第四个stage。我们测试了ResNet和ResNeXt。此外,我们还尝试了使用ResNet-FPN作为backbone,在精度和速度方面都得到了大幅提高。

head的结构见Fig4。Fig4左的backbone是ResNet C4,Fig4右的backbone是FPN(已经包含”res5”)。数字表示的是空间分辨率和通道数。箭头表示卷积层、反卷积层或FC层。输出层的卷积核大小为$1\times 1$,其余卷积层的卷积核大小都为$3 \times 3$,反卷积层的核大小为$2 \times 2$(步长为2),在隐藏层中我们使用ReLU函数。Fig4左的”res5”表示ResNet的第5个stage。Fig4右的”x4”表示连续4个卷积层。
3.1.Implementation Details
我们对超参数的设置遵循Fast R-CNN和Faster R-CNN。尽管这些超参数在原论文中都是为目标检测任务设置的,但我们发现其对实例分割任务也是有效的。
👉Training:
和Fast R-CNN一样,如果RoI和GT的IoU超过0.5,则视为正样本,否则为负样本。$L_{mask}$只定义在正样本RoI上。
输入图像被resize到短边为800个像素。每块GPU的每个mini-batch内有2张图像,每张图像有$N$个RoI,RoI正负样本的比例为$1:3$。当backbone为C4时,$N=64$;当backbone为FPN时,$N=512$。我们在8块GPU(相当于mini-batch size=16)上训练了160k次迭代,初始学习率为0.02,在第120k次迭代时,学习率缩小10倍。weight decay=0.0001,momentum=0.9。当使用ResNeXt时,每块GPU训练1张图像,迭代次数不变,初始学习率为0.01。
和FPN中一样,RPN anchor有5种尺度和3种长宽比。为了方便进行消融实验,RPN是单独训练的,不和Mask R-CNN共享特征。但其backbone都是一样的,是可以共享特征的。
👉Inference:
在推理阶段,C4 backbone的proposal数量为300;FPN backbone的proposal数量为1000。bounding box分支在这些proposal上运行,并使用了NMS。mask分支只运行在得分最高的100个box上。尽管这与训练中使用的并行计算不同,但它加快了推理速度并提高了精度(因为使用了更少、更准确的RoI)。对于每个RoI,mask分支都可以预测出$K$个mask,但我们只使用第$k$个类别的mask,$k$是类别分支预测得到的类别。mask分支输出的$m \times m$大小的mask会被resize到RoI大小,并在0.5的阈值下进行二值化。
因为我们在前100个box上计算了mask,所以计算开销相比Faster R-CNN提高了约20%。
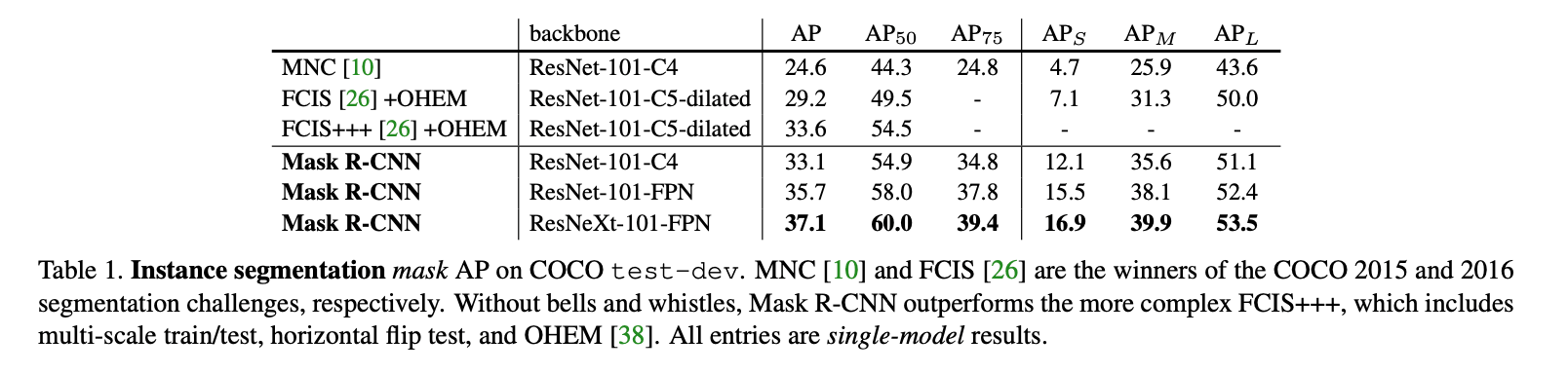
4.Experiments: Instance Segmentation
我们将Mask R-CNN和现有的SOTA方法进行了彻底的比较,并在COCO数据集上进行了消融实验。我们在80k训练图像+trainval35k的并集上进行了训练,在minival上进行了消融实验,在test-dev上汇报了结果。
4.1.Main Results
Mask R-CNN的结果可视化见Fig2和Fig5。

和FCIS+++的结果对比见Fig6。

4.2.Ablation Experiments
消融实验的结果见表2:

👉Architecture:
Mask R-CNN使用不同backbone的结果见表2a。
👉Multinomial vs. Independent Masks:
是否将类别预测和mask预测解耦的结果对比见表2b。
👉Class-Specific vs. Class-Agnostic Masks:
我们默认是预测class-specific masks,即一个类别对应一个$m \times m$的mask。如果Mask R-CNN预测class-agnostic masks,即只预测得到一个$m \times m$的mask(与类别无关),在backbone为ResNet-50-C4的情况下,class-agnostic masks的AP为29.7,稍差于class-specific masks的30.3。
👉RoIAlign:
对RoIAlign的评估见表2c,backbone为ResNet-50-C4,步长为16。RoIAlign对max/average pool是敏感的,后续我们都使用average。
当backbone为ResNet-50-C5,步长为32个像素时,对RoIAlign的评估见表2d。我们使用Fig4右的head。
👉Mask Branch:
mask分支使用全连接MLP和FCN的对比见表2e。
4.3.Bounding Box Detection Results
目标检测任务上的对比结果见表3。
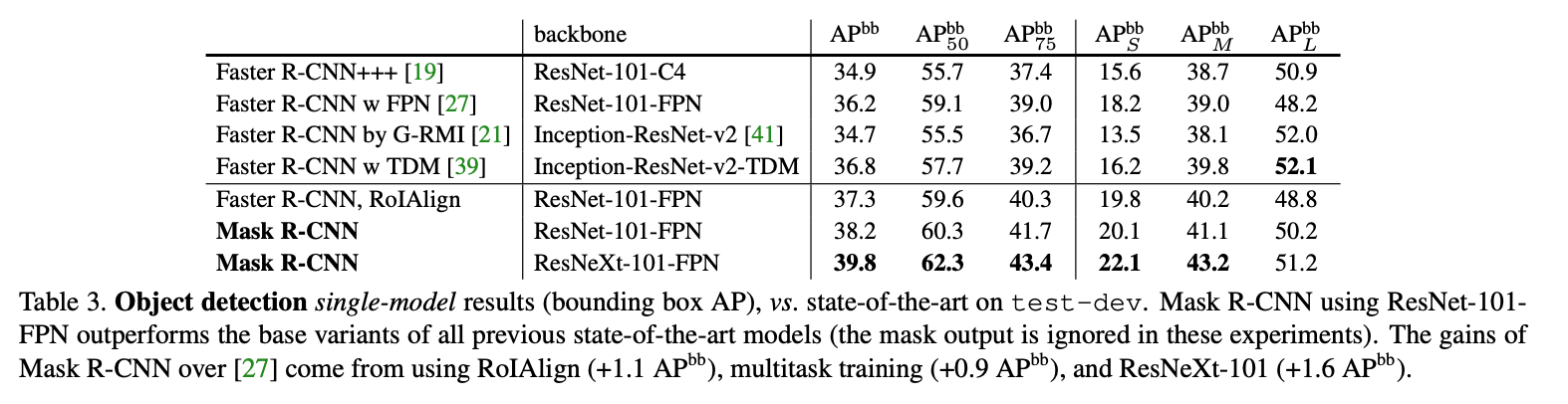
完整的Mask R-CNN模型被训练,但在推理阶段只使用了类别和box输出(mask输出被忽视)。为了进一步的比较,我们训练了一个没有mask分支的Mask R-CNN,见表3中的”Faster R-CNN, RoIAlign”。
4.4.Timing
👉Inference:
我们训练了一个ResNet-101-FPN模型,其在RPN和Mask R-CNN之间共享特征,遵循Faster R-CNN的4步训练法。在Nvidia Tesla M40 GPU上处理一张图像需要195ms(在CPU上还需要15ms用于将输出resize到原始分辨率),可以达到不共享特征时的AP。如果backbone是ResNet-101-C4,则需要400ms。
尽管Mask R-CNN速度很快,但我们并没有针对速度进行优化。
👉Training:
Mask R-CNN训练也很快。backbone为ResNet-50-FPN,在COCO trainval35k上训练了32个小时,用了8块GPU。如果backbone为ResNet-101-FPN,则训练需要44个小时。
5.Mask R-CNN for Human Pose Estimation
我们的框架可以很容易的被扩展到人体姿态估计。Mask R-CNN还是预测$K$个mask,每个mask对应一个关键点。
👉Implementation Details:
输出一个one-hot的$m \times m$大小的二值mask,只有一个像素被标记为前景。使用softmax函数和交叉熵损失。和实例分割模型一样,$K$个关键点也是被独立处理的。
使用ResNet-FPN作为backbone,head的结构类似Fig4右。关键点模型的head包含8个$3 \times 3$ 512-d的卷积层,然后是反卷积层和2倍的双线性上采样,最终的输出分辨率为$56 \times 56$。我们发现关键点的精确定位需要相对较高的输出分辨率。
在COCO trainval35k上训练模型。由于该训练集较小,为了减少过拟合,我们将图像的短边随机resize到$[640,800]$个像素,推理则是在800个像素的尺度上进行的。一共训练了90k次迭代,初始学习率为0.02,在第60k和第80k次迭代时,学习率缩小10倍。bounding box NMS的阈值为0.5。其他细节和第3.1部分一样。
👉Main Results and Ablations:
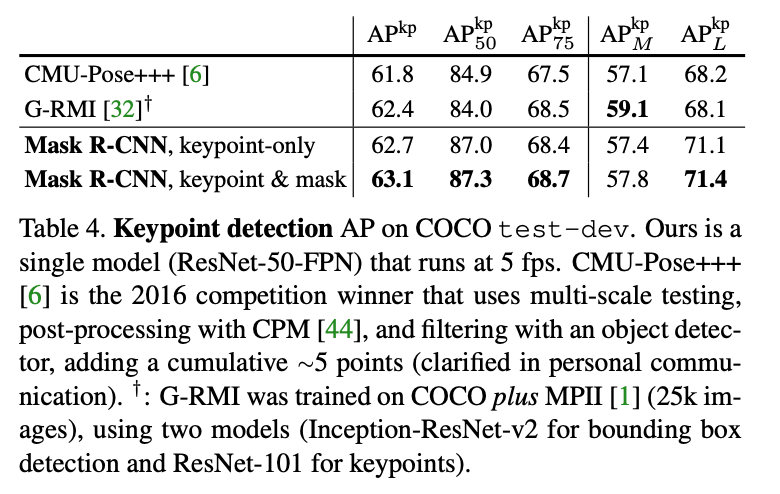
表4中,我们还展示了一个统一的模型,可以以5 fps的速度同时预测bounding box、分割和关键点,并且$AP^{kp}$达到了63.1。更多在minival上多任务学习的消融实验见表5。多任务学习的可视化结果见Fig7。
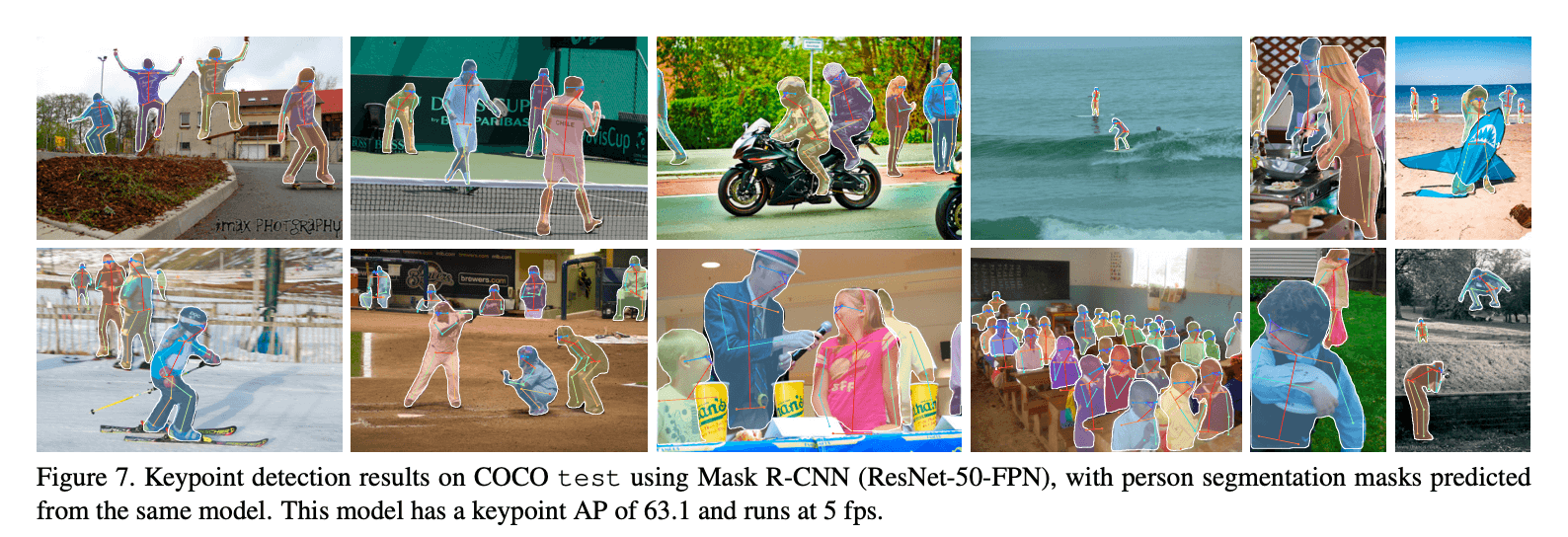
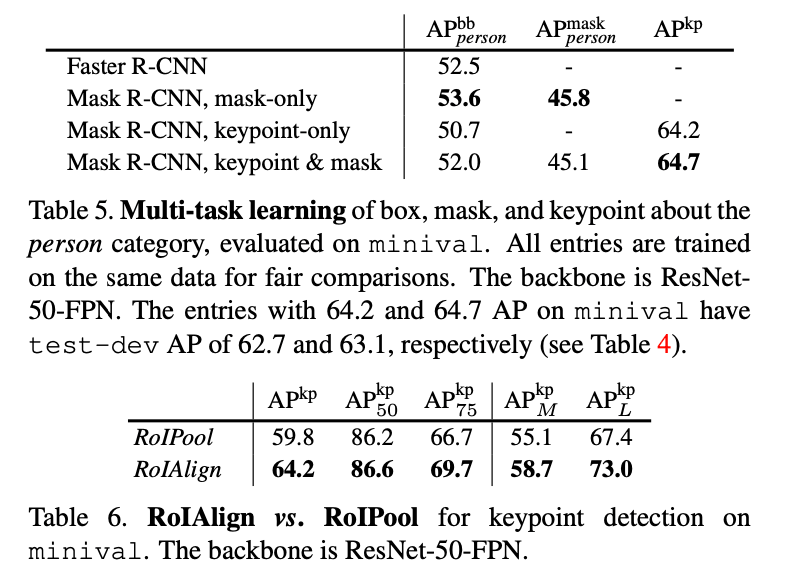
RoIAlign对关键点检测的影响见表6。
6.Appendix A: Experiments on Cityscapes
我们进一步报告了在Cityscapes数据集上的实例分割结果。该数据集标注的很详细(fine data),训练集有2975张图像,验证集有500张图像,测试集有1525张图像。此外,它还有20k张没有实例标注的训练图像(coarse data),我们并没有使用这些无标注的图像。所有图像都是$2048 \times 1024$大小的。实例分割任务包括8个目标类别,每个类别的实例数量见下:
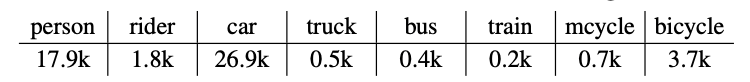
👉Implementation:
Mask R-CNN的backbone使用ResNet-FPN-50。由于数据集太小,使用101层的backbone区别不大。为了减少过拟合,我们将训练图像的短边随机resize到$[800,1024]$;推理在1024的单尺度上进行。一块GPU的mini-batch size为1(8块GPU就是8),模型一共训练了24k次迭代,初始学习率为0.01,在第18k次迭代时,学习率降为0.001。一共训练了4个小时。
👉Results:
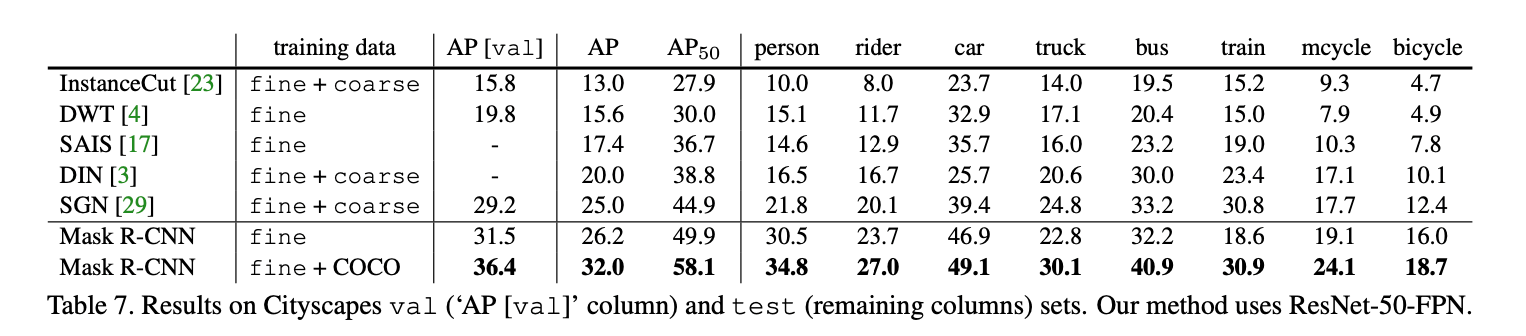
在表7中,我们还汇报了经过COCO预训练后的Mask R-CNN的结果,fine-tune了4k次迭代,在第3k次迭代时学习率下降,在COCO上预训练用了1个小时。

7.Appendix B: Enhanced Results on COCO
本附录介绍一些改进原始结果的技术。
7.1.Instance Segmentation and Object Detection
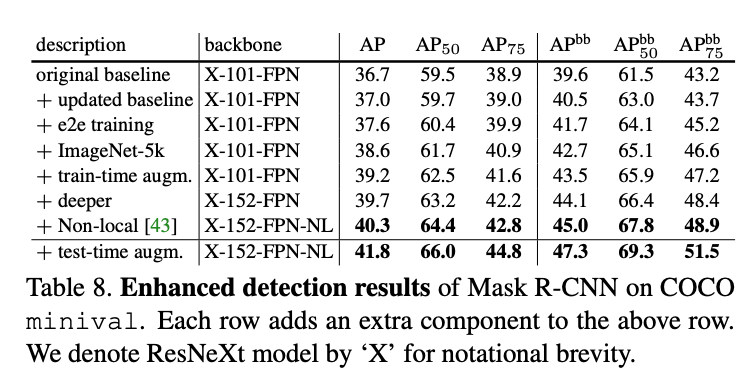
👉Updated baseline:
我们将训练延长到180k次迭代,在第120k和第160k次迭代时学习率缩小10倍。将NMS的阈值从默认的0.3调整为0.5。
👉End-to-end training:
将Faster R-CNN的4步训练法调整为“Approximate joint training”的端到端训练方式。
👉ImageNet-5k pre-training:
在ImageNet-5k上进行了预训练。
👉Train-time augmentation:
对图像进行不同比例的缩放进一步提升了结果。我们将短边随机resize到$[640,800]$区间,并且把迭代次数增加至260k(在第200k和第240k的时候学习率衰减10倍)。
👉Model architecture:
把101层的ResNeXt增加至152层。
👉Non-local:
使用了non-local模型。在不使用test-time augmentation的情况下,在Nvidia Tesla P100 GPU上可以达到3fps的推理速度。
non-local模型:X.Wang, R.Girshick, A.Gupta, and K.He. Non-local neural networks. arXiv:1711.07971, 2017.。
👉Test-time augmentation:
我们将测试图像的短边分别resize到$[400,1200]$(间隔100),并考虑其水平翻转图像,得到的综合预测结果作为最终结果。
7.2.Keypoint Detection
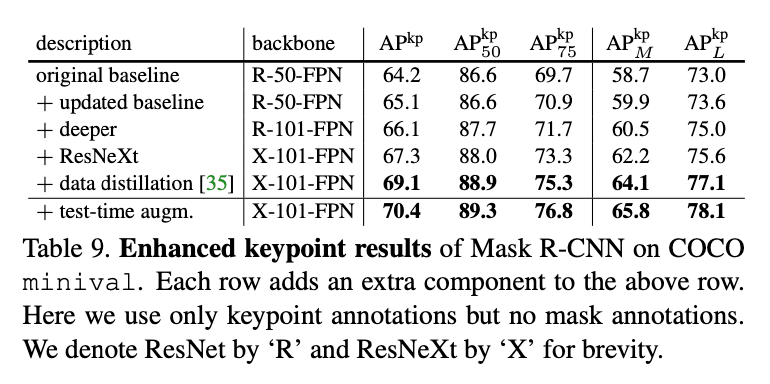
针对updated baseline,我们将迭代次数增加至130k,在第100k和第120k时学习率衰减10倍。
通过data distillation的方法,我们能够利用COCO提供的额外120k张未标记图像。简单来说,data distillation是一种自训练策略(self-training strategy),它使用在标记数据上训练的模型来预测未标记图像的标签/标注,然后用这些新的标签/标注来更新模型。
data distillation:I. Radosavovic, P. Dolla ́r, R. Girshick, G. Gkioxari, and K. He. Data distillation: Towards omni-supervised learning. arXiv:1712.04440, 2017.。
