本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Apriori算法
Apriori算法的优点是简单,缺点是:
- 每一步产生的候选项集过多。
- 每一步计算项集的支持度时,都遍历了全部记录。
因此数据量很大的时候,Apriori算法的效率会很低。
2.FP Growth Tree
当数据量较大时,我们可以选择效率更高的Frequent Pattern Growth Tree算法来寻找频繁项集。假设有如下记录:
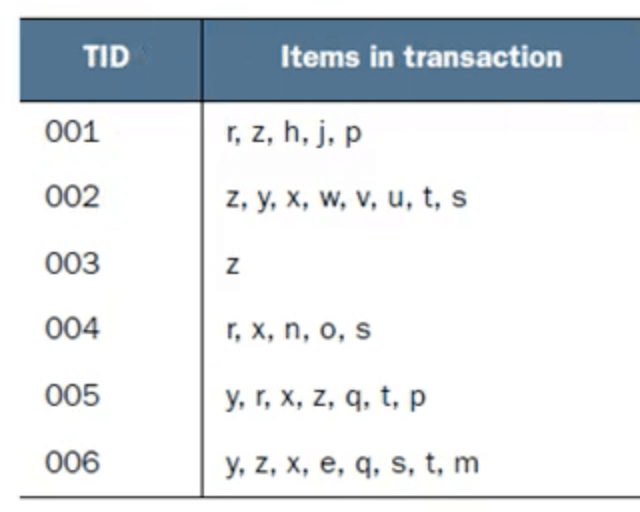
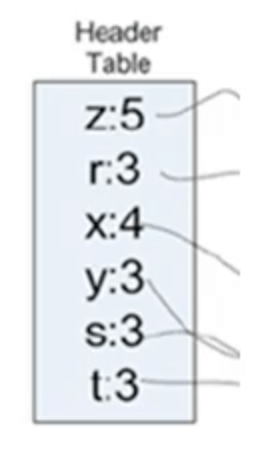
假设我们将支持度的阈值设为出现频次至少3次,统计得到如下商品的频次超过了3次:
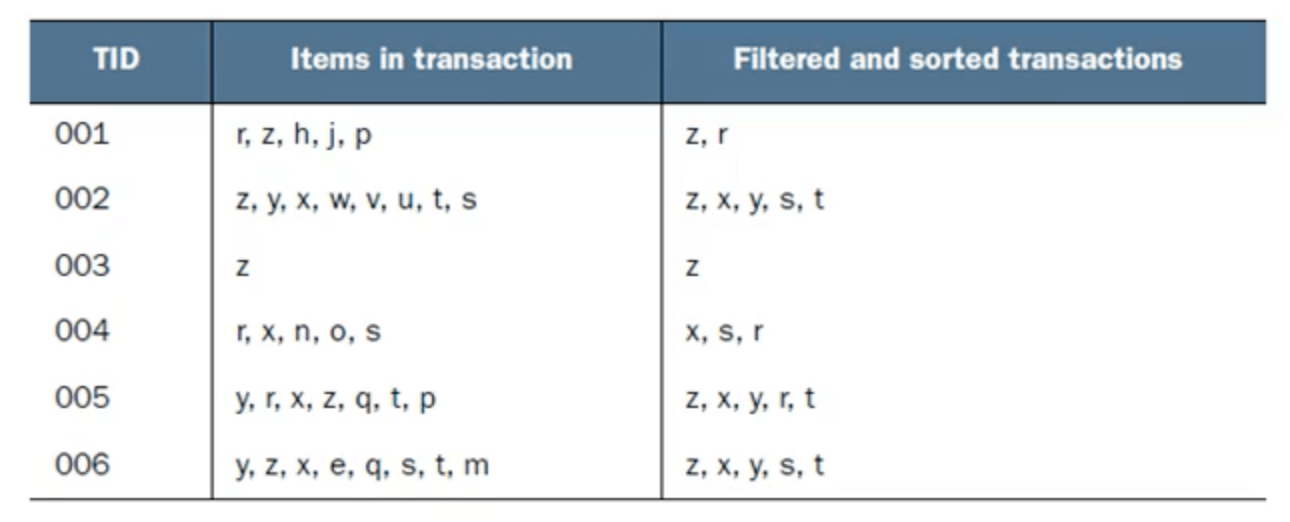
去除掉每条记录中频次不满3次的商品,并将剩下的商品按照频次高低排序:
然后将每条过滤后的记录依次加到树里:
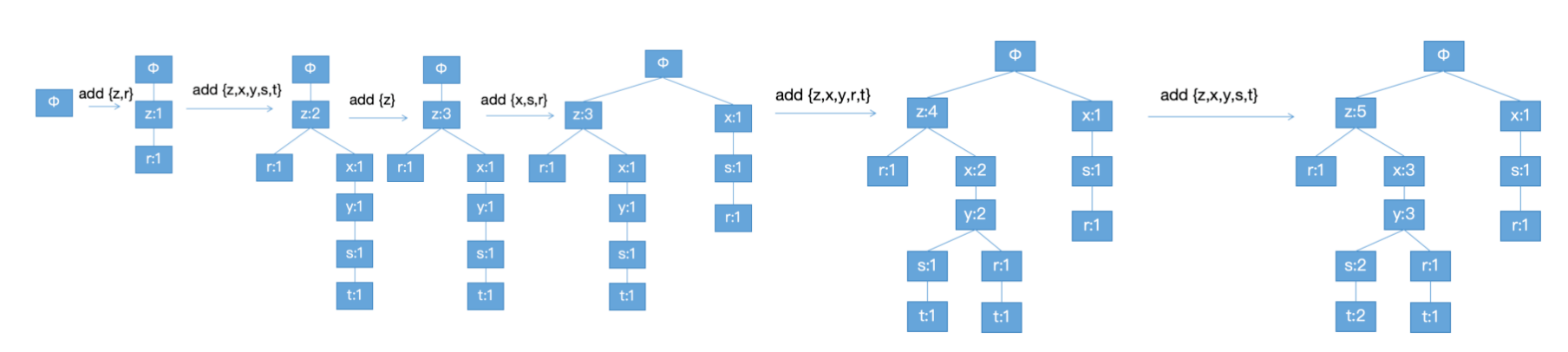
然后统计每件商品到树根所能形成的各种商品组合的频次:

我们以r为例,考虑树的不同分支,在r之前出现过{z}、{z,x,y}、{x,s}等3种情况。其中z,r一起出现的频次为1,所以把{z}标记为1;z,x,y,r一起出现的频次也是1,所以把{z,x,y}也标记为1;x,s,r一起出现的频次也是1,把{x,s}也标记为1。
如果我们要选出支持度最少为3频次的最大频繁项集,便可从上表中轻松得到是{x,y,z}。
3.使用Python执行FP-Growth算法
我们使用pymining来调用FP-Growth算法。首先安装pymining:
1
pip install pymining
核心代码(完整示例代码见:Demo47):
1
2
3
from pymining import itemmining
fp_input = itemmining.get_fptree(transactions)
report = itemmining.fpgrowth(fp_input, min_support=30, pruning=True)
