本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
经典的网络结构VGG由卷积、ReLU、pooling堆叠而成,结构非常简单,但在图像识别领域取得了巨大成功。随着Inception(Inception-v1、BN-Inception、Inception-v2/v3、Inception-v4/ResNet)、ResNet、DenseNet的出现,研究方向逐渐转为复杂的网络架构设计,使得模型变得越来越复杂。
尽管这些复杂的网络架构的确能带来更高的精度,但它们也有明显的缺点:
- 多分支设计(比如ResNet和Inception)使得模型难以实现和定制,同时减慢推理速度并降低内存利用率。
- 某些组件(比如depthwise卷积和channel shuffle)增加了MAC,并且缺乏对各种设备的良好支持。
由于影响推理速度的因素很多,FLOPs并不能精确反映实际速度。虽然一些新模型的FLOPs比传统模型(如VGG、ResNet)更低,但它们并不一定运行得更快。因此,VGG和原始版本的ResNet在学术界和工业界的实际应用中仍被大量使用。
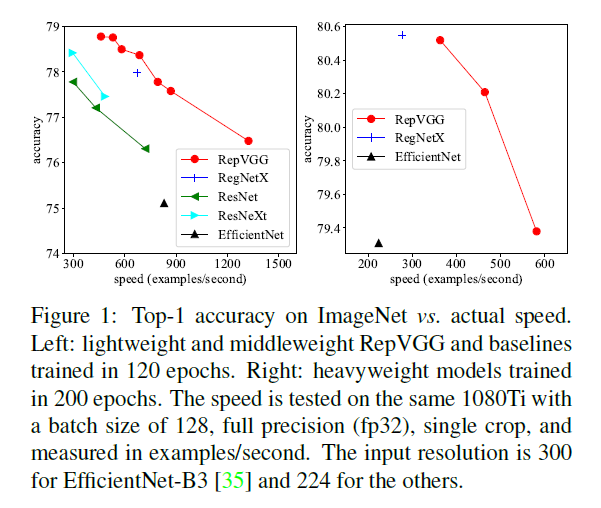
在本文中,我们提出了RepVGG:一种VGG风格的架构,其性能优于许多复杂的模型(见Fig1)。RepVGG具有以下优势:
- VGG风格,结构简单,没有任何分支,每一层仅接收前一层的输出,并将结果传递给下一层。
- 模型主体仅使用$3\times 3$卷积和ReLU。
- 其具体架构完全是人工设计的,不需要自动搜索或复杂设计。
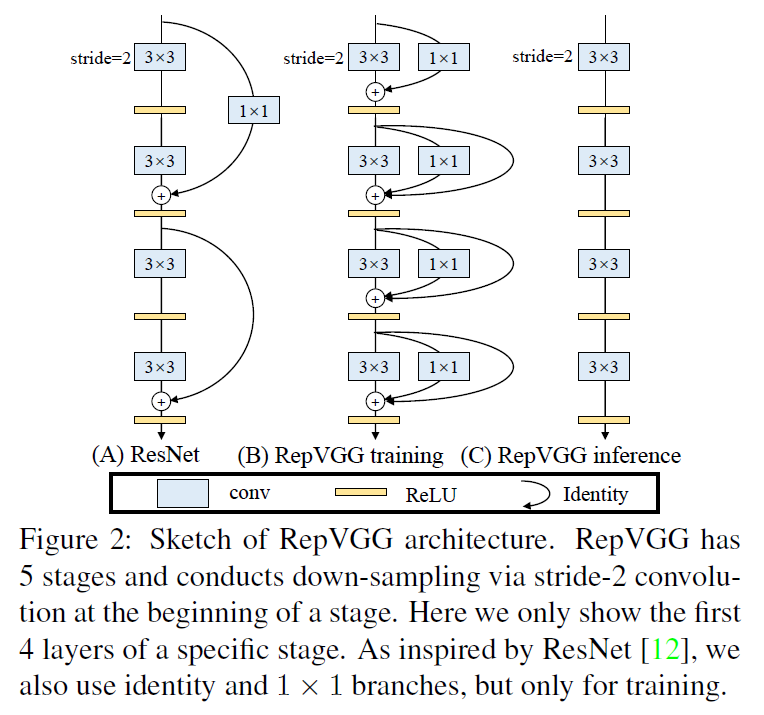
如Fig2所示,我们在训练阶段为RepVGG引入了恒等映射(identity)和$1\times 1$分支,其灵感来自ResNet,但方式有所不同,这些分支可以在训练完成后通过结构重参数化去掉。具体操作是,在训练完成后,我们利用代数变换,将identity分支视为退化的$1\times 1$卷积,而$1\times 1$卷积又可以视为退化的$3\times 3$卷积,从而把原始$3\times 3$卷积、identity分支、$1\times 1$分支以及BN层的参数合并为一个等价的$3\times 3$卷积。最终得到的模型就是一个由$3\times 3$卷积堆叠而成的简单结构,可直接用于推理与部署。
值得注意的是,推理阶段的RepVGG仅包含一种运算算子:$3\times 3$卷积+ReLU。这使得RepVGG在GPU等通用计算设备上非常高效。
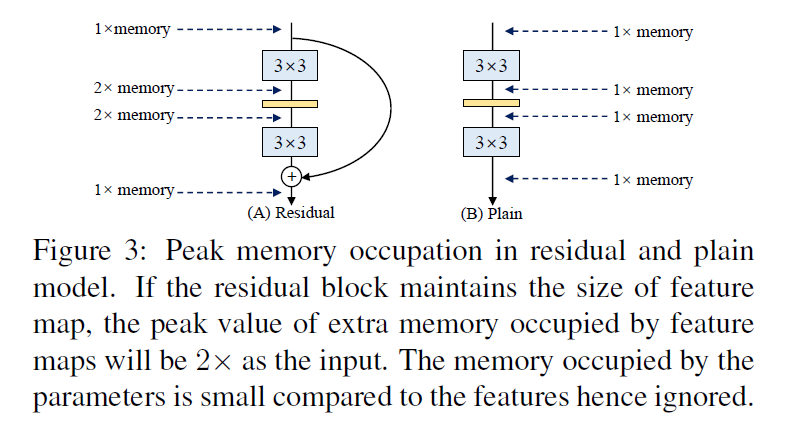
如Fig3所示,在ResNet中,峰值情况下,memory中要同时存储两个分支的信息,所以峰值内存大约是输入的2倍,而对于RepVGG来说,其只有一个路径,所以峰值内存一般是输入的1倍。
2.Related Work
不再赘述。
3.Building RepVGG via Structural Re-param
3.1.Simple is Fast, Memory-economical, Flexible
使用plain卷积网络至少有3个原因:快、节省内存(见Fig3)、灵活。
3.2.Training-time Multi-branch Architecture
但是plain卷积网络有个致命缺陷:性能不足。因此参照ResNet,在训练阶段我们引入了多分支:$y = x+g(x)+f(x)$,其中,$x$来自identity分支,$g(x)$来自$1\times 1$卷积分支,$f(x)$来自$3\times 3$卷积分支。我们将若干个这样的block堆叠起来,构建训练时的模型。
3.3.Re-param for Plain Inference-time Model
本部分介绍如何将训练好的多分支block转换为一个单一的$3\times 3$卷积层,从而用于推理阶段。需要注意的是,我们在每个分支的卷积之后都应用了BN,在BN之后才进行的相加操作,具体如Fig4所示。
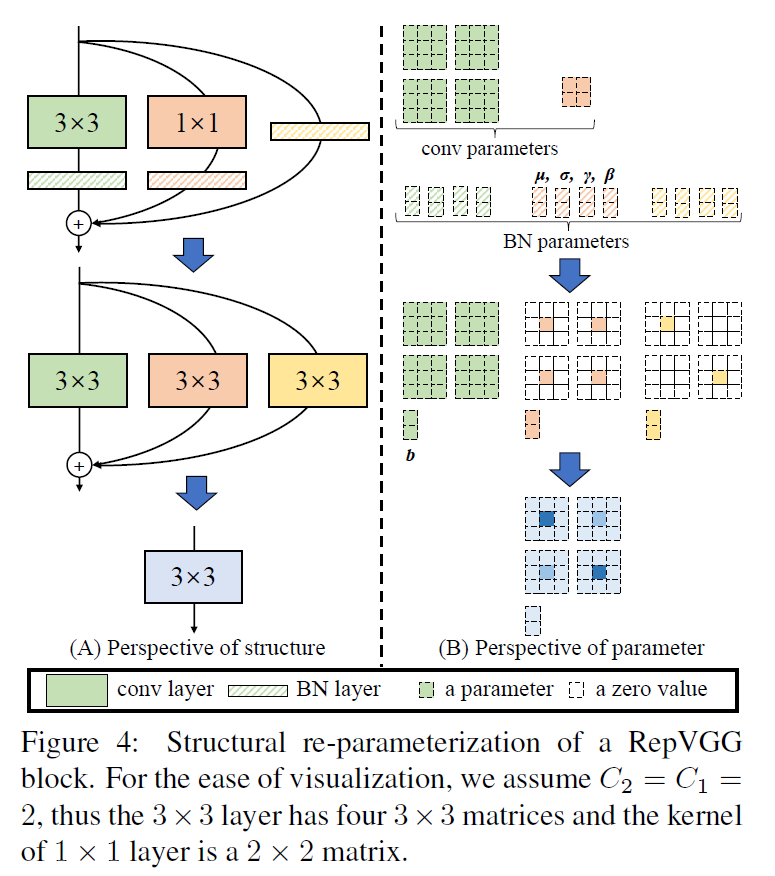
用$W^{(3)} \in \mathbb{R}^{C_2 \times C_1 \times 3 \times 3}$表示$3\times 3$卷积核,其中$C_1$表示输入通道数,$C_2$表示输出通道数。类似的,我们用$W^{(1)}\in \mathbb{R}^{C_2 \times C_1}$表示$1\times 1$卷积核。$3 \times 3$卷积之后的BN所用到的参数用$\mu^{(3)},\sigma^{(3)},\gamma^{(3)},\beta^{(3)}$表示,$1\times 1$卷积之后的BN所用到的参数用$\mu^{(1)},\sigma^{(1)},\gamma^{(1)},\beta^{(1)}$表示,identity分支的BN所用到的参数用$\mu^{(0)},\sigma^{(0)},\gamma^{(0)},\beta^{(0)}$表示。block的输入表示为$M^{(1)}\in \mathbb{R}^{N \times C_1 \times H_1 \times W_1}$,block的输出表示为$M^{(2)}\in \mathbb{R}^{N \times C_2 \times H_2 \times W_2}$,用*表示卷积操作。如果有$C_1= C_2, H_1 = H_2, W_1=W_2$,则block的输出可用下式计算:
此外,如果我们不使用identity分支,则只需把式(1)中的第3项去掉就行。在推理阶段,BN的计算可表示为:
\[\text{bn} (M,\mu,\sigma,\gamma,\beta)_{:,i,:,:} = (M_{:,i,:,:}-\mu_i)\frac{\gamma_i}{\sigma_i}+\beta_i, \ \forall 1 \leqslant i \leqslant C_2 \tag{2}\]我们可以将每个BN和其前置的卷积合并为一个卷积和一个偏置项。即将参数$\{ W,\mu,\sigma,\gamma,\beta \}$转换为$\{ W’,b’ \}$,转换公式见下:
\[W'_{i,:,:,:} = \frac{\gamma_i}{\sigma_i} W_{i,:,:,:}, \quad b'_i = -\frac{\mu_i \gamma_i}{\sigma_i}+\beta_i , \ \forall 1 \leqslant i \leqslant C_2 \tag{3}\]BN层和卷积层融合之后的计算为:
\[\text{bn} (M * W, \mu, \sigma, \gamma, \beta)_{:,i,:,:} = (M * W')_{:,i,:,:} + b_i' \tag{4}\]这种变换对identity分支也适用,因为identity操作可以视为一个$1\times 1$卷积,卷积核是单位矩阵。通过这种变换,第一个分支变成了1个$3\times 3$卷积和1个偏置向量,第二个分支变成了1个$1\times 1$卷积和1个偏置向量,第三个分支变成了1个$1\times 1$卷积和1个偏置向量。接下来我们把这三个分支合并成一个卷积和一个偏置向量,合并策略如Fig4(B)所示,3个分支的偏置向量可以直接相加得到一个偏置向量,2个$1\times 1$卷积可以用0 padding到$3\times 3$大小,然后将3个$3\times 3$卷积相加得到一个$3\times 3$卷积。这样,3个分支就被合并成了一个单一的$3\times 3$卷积层。需要注意的是,这种等价转换要求$3\times 3$卷积和$1\times 1$卷积的步长相同,此外,$1\times 1$卷积的padding要比$3\times 3$少1,比如,$3\times 3$卷积通常设置padding=1,此时$1\times 1$卷积应设置padding=0。
3.4.Architectural Specification
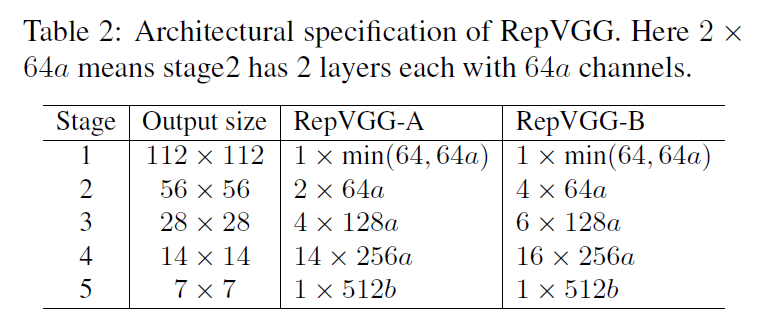
RepVGG是一种VGG风格的架构,采用plain的拓扑结构,大量使用$3\times 3$卷积,但和VGG不同的是,我们并没有使用max pooling,因为我们希望网络架构主体只有一种类型的操作。我们将大量的$3\times 3$卷积层分为5个阶段,其中每个阶段中的第一层步长为2。对于图像分类任务,我们可以在全连接层后接一个global average pooling作为head。对于其他类型的任务,可以将特定的head接在任意一层的后面。
每个阶段内层的数量遵循三个简单的原则:1)第一个阶段要处理很大的分辨率,这会很耗时,所以第一个阶段只包含一层,以保证低延迟;2)最后一个阶段应该有更多的通道数,所以我们仅用一层来保存参数;3)仿照ResNet,我们在倒数第二个阶段中设置了最多的层数。
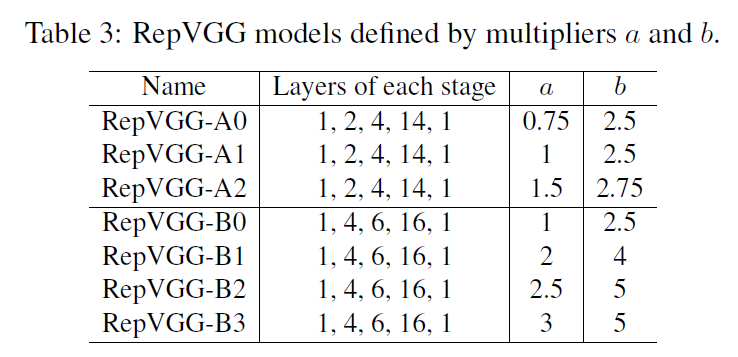
在表2中,我们展示了RepVGG-A和RepVGG-B的结构。通道缩放因子$b$通常设置的要比因子$a$大,因为我们希望最后一层可以获得更丰富的特征用于分类或其他下游任务。
我们可以使用分组卷积来进一步降低参数量和计算成本。除去第一层,我们只对奇数层使用分组卷积。分组数$g$通常全局设置为1,2或4。
4.Experiments
4.1.RepVGG for ImageNet Classification
构建了一系列不同规模的RepVGG模型:
对于轻量级和中量级的模型,训练只使用了简单的数据扩展,包括随机裁剪和左右翻转。使用了8块GPU,全局batch size设置为256,初始学习率设置为0.1,学习率衰减策略使用cosine annealing,momentum=0.9,weight decay=$10^{-4}$。对于重量级模型,包括RegNetX-12GF、EfficientNet-B3和RepVGG-B3,使用5个epoch用于warmup,学习率衰减策略使用cosine annealing,还使用了label smoothing、MixUp、随机裁剪和翻转。
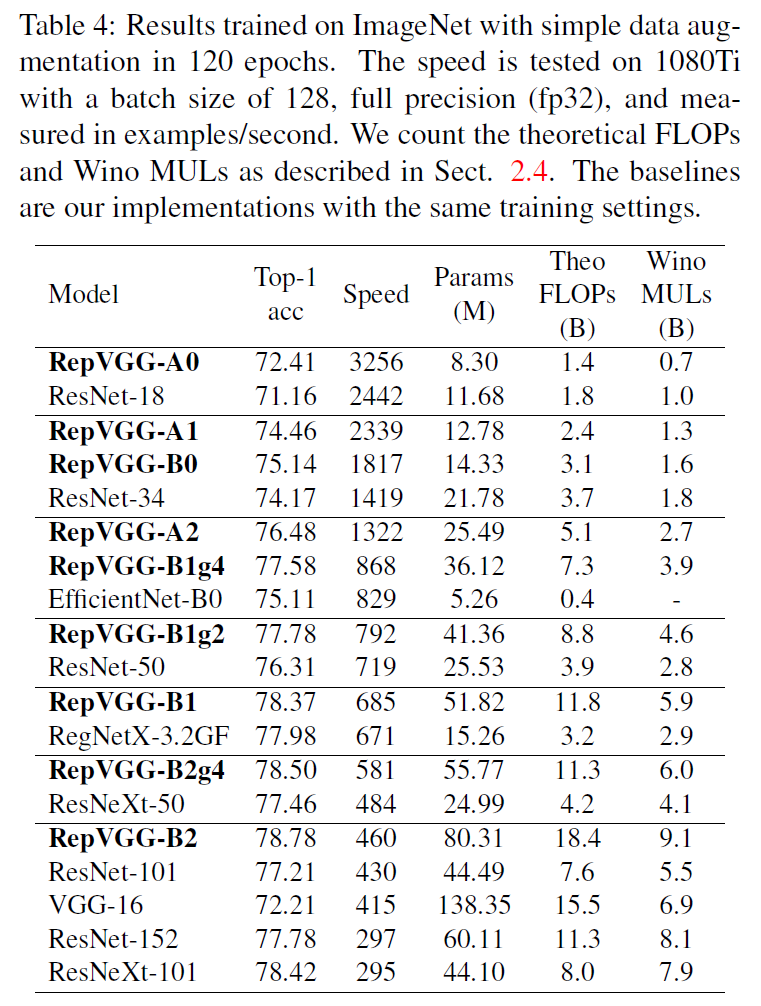
其中,后缀”g2/g4”表示使用了分组卷积,”g2”表示分组数$g=2$,”g4”表示分组数$g=4$。
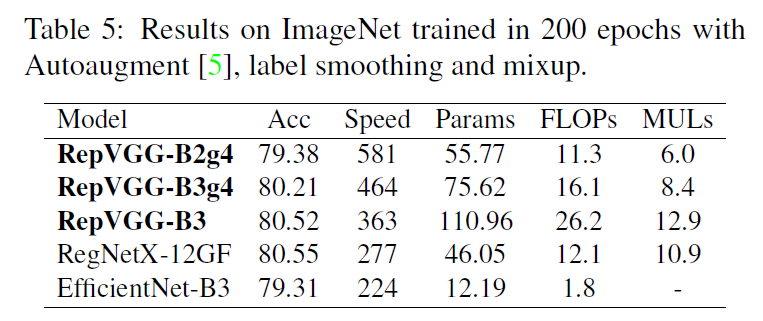
4.2.Structural Re-parameterization is the Key
RepVGG block有3个分支,在表6中,第一行是移除identity分支和$1\times 1$分支的测试结果,第二行是仅移除$1\times 1$分支的测试结果,第三行是仅移除identity分支的测试结果,第四行是保留所有3个分支的测试结果。

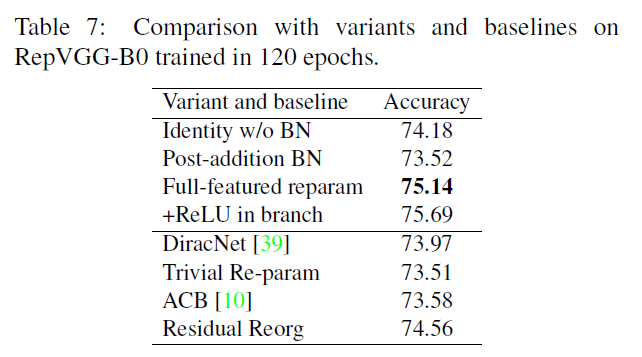
在表7中列出了不同RepVGG-B0变体的性能比较:
- Identity w/o BN:移除identity的BN。
- Post-addition BN:移除三个分支的BN层,然后在三个分支相加操作的后面加一个BN层。
- +ReLU in branches:在原始的RepVGG结构中,训练阶段在分支相加操作之后才会ReLU,现在在每个分支内的BN层之后都加上ReLU操作,以此来看下更多的非线性操作是否可以提高性能。
- DiracNet:一种经过重参数化的卷积,可以把identity操作融入到卷积中去。
- Trivial Re-param:一种更为简单的重参数化卷积,直接将identity核加到$3\times 3$核上,可视为一种退化版本的DiracNet。
- Asymmetric Conv Block (ACB):可视为另一种结构化的重参数方法。
- Residual Reorg:仿照ResNet(每个block内有两层),我们对RepVGG-B0的结构进行了重构。对于第1个和第5个阶段,只有一个$3\times 3$卷积层;对于第2、3、4个阶段,每两层添加一个残差连接,所以对于第2、3、4个阶段,分别会有2、3、8个残差块。
表7中的”Full-featured reparam”表示baseline,即原始的RepVGG-B0。
4.3.Semantic Segmentation
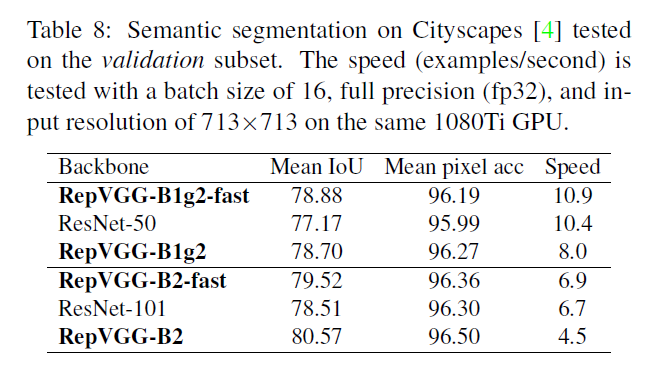
我们在Cityscapes数据集中,验证了经过ImageNet预训练的RepVGG在语义分割任务上的泛化性能。我们使用PSPNet框架,学习率衰减策略使用poly learning rate policy:
\[lr=lr_{init} \times \left( 1 - \frac{iter}{max\_iter} \right)^{power}\]PSPNet见论文:Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 6230–6239. IEEE Computer Society, 2017.。
其中,$lr_{init}$为初始学习率,这里设置为0.01。iter和max_iter指的是全局迭代次数,即batch数,iter表示已经运行的batch数,max_iter表示最大batch数,通常等于epoch数量乘上每个epoch内的batch数量。power这里设置为0.9。
weight decay设置为$10^{-4}$,使用8块GPU,全局batch size设置为16,共训练40个epoch。为了公平比较,我们仅仅是把ResNet-50和ResNet-101的backbone分别替换为RepVGG-B1g2和RepVGG-B2,其他设置均保持一致。在官方的PSPNet-50/101中,其在ResNet-50/101的最后两个阶段使用了空洞卷积,为了遵循这一设计,RepVGG-B1g2和RepVGG-B2的最后两个阶段的所有$3\times 3$卷积层也都使用了空洞卷积。但是,当前的$3\times 3$空洞卷积实现并不充分(虽然和常规的$3\times 3$卷积的FLOPs一样),其会导致推理变慢。为了便于比较,我们构建了另外两个PSPNets(标记为fast),其仅在最后5层使用空洞卷积(即stage4的最后4层和stage5的一层),这样的话,PSPNets能比其对应的以ResNet-50/101为backbone的模型运行的稍微快一些。
4.4.Limitations
RepVGG是一个快速、简单且实用的CNN架构,其设计目标是在GPU和专用硬件上实现最高的运行速度,而并不是刻意减少参数数量。RepVGG在参数利用率上优于ResNet,但在低功耗设备上,逊色于MobileNets和ShuffleNets等专为移动端设计的模型。
5.Conclusion
不再赘述。
