本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.介绍(Introduction)
GoogLeNet的参数数量比AlexNet少12倍,但精度比AlexNet更高。此外,GoogLeNet并没有只关注于提高准确率,还考虑了算法效率,在预测阶段将其计算成本控制在1.5亿次加乘运算之内。本文提出了一种有效的深度神经网络结构用于计算机视觉,取名为Inception。GoogLeNet就使用了Inception模块并作为我们提交给ILSVRC2014的结果,其在分类和检测任务中的表现都优于其他先进算法。GoogLeNet这个名字也是为了致敬LeNet。
2.相关工作(Related Work)
LeNet5提出了一种标准化的CNN结构:多个卷积层+全连接层。后续的图像分类算法也大多效仿这种结构,并且取得了不错的成绩。对于像ImageNet这种大型数据集,最近的趋势是增加层的数量和大小,并使用dropout解决过拟合的问题。
尽管max-pooling的使用会丢失一些空间信息,但是AlexNet依旧在定位、目标检测以及人体pose识别等领域取得了不错的成绩。此外,GoogLeNet使用了大量的$1 \times 1$卷积(Network-in-Network),这样做的目的有两个:1)降低计算量,从而打破网络规模的限制;2)在加深且加宽网络的同时,不会造成严重的性能下降。
目前目标检测领域内最为优秀的算法之一是R-CNN。R-CNN将目标检测问题分成2个部分(即通常所说的two-stage approach):1)使用浅层特征确定一些候选区域;2)在这些候选区域内运行CNN。GoogLeNet在检测任务中也使用了类似的结构,但是其对每一部分都进行了优化。
3.动机和高层设计考虑(Motivation and High Level Considerations)
提升深度神经网络模型性能最简单直接的办法就是增加网络的大小。这个大小包含两层意思:1)增加网络的深度,即层数;2)增加网络的宽度,即每层的神经元数。但是这种简单的办法却有两个主要的缺点。
第一个缺点:更大的网络意味着更多的参数,这使得训练很容易过拟合,尤其当数据量有限的时候。因此,数据集会是一个主要的瓶颈。并且,构建一个高质量的训练集非常棘手且成本高昂,尤其在一些情况下还需要专业人员的参与,例如对下图中两个狗的品种进行标注:

第二个缺点:网络大小的增加会显著提升其对计算资源的占用。并且如果计算资源没有被充分利用(例如大量的权重趋于零),也会造成资源的浪费。在实际问题中,计算资源通常是有限的,有效合理的利用计算资源比盲目增加网络大小更为重要,虽然增加网络大小的目的是为了提升模型性能。
同时解决这两个问题的一个基本办法就是将全连接改为稀疏连接,甚至在卷积层也这么做。这种处理办法除了是在模仿生物系统外,文章Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.也证实了这种办法的有效性。Arora等人的文章通过对layer的激活值进行相关性统计分析,将高相关性输出的神经元进行聚类。这也符合著名的Hebbian原则,而Inception结构也正是基于该原则。
与反向传播算法一样,Hebbian原则也是一种参数更新的方式。该学习规则:将一个神经元的输入与输出信息进行对比,对该神经元的输入权重参数进行更新。该学习规则使每个神经元独自作战。一个神经元的参数更新,仅仅与它自己的输入与输出数据有关,不考虑整个网络的全局情况。
Hebbian学习规则通常使用双极性激活函数,即激活函数的取值范围是[-1,1]。当输入与输出同号(+或-)时,加大权重,否则,降低权重。
双极性激活函数:
因此,Hebbian学习规则通常用当前神经元的输入与输出的乘积更新自己的权重。
\[\Delta w_{ij}=\eta o_j x_i\]其中,$o_j$是第$j$个神经元的输出,$x_i$是神经元的第$i$个输入。$w_{ij}$是神经元$j$与第$i$个输入数据$x_i$之间的权重。
以单个神经元的单个输入为例:
假设共有3个样本,分别为:$x_1=(1,-2,1.5,0);x_2=(1,-0.5,-2,-1.5);x_3=(0,1,-1,1.5)$。初始权重为$w(0)=(1,-1,0,0.5)$。设$\eta=1,T=1$。则Hebbian的学习过程为:
- 输入第一个样本,输出$f(w(0)^T x_1 - T)=f(3)=1$。根据输出更新权值$\Delta w=\eta o_j x_i=1\cdot 1 \cdot x_1=(1,-2,1.5,0)$。更新后的权值$w(1)=w(0)+\Delta w=(1,-1,0,0.5)+(1,-2,1.5,0)=(2,-3,1.5,0.5)$。
- 输入第二个样本,输出$f(w(1)^T x_2 - T)=f(-0.25)=-1$。根据输出更新权值$\Delta w=\eta o_j x_2=(-1,0.5,2,1.5)$。更新后的权值$w(2)=w(1)+\Delta w=(2,-3,1.5,0.5)+(-1,0.5,2,1.5)=(1,-2.5,3.5,2)$。
- 输入第三个样本,输出$f(w(2)^T x_3 - T)=f(-3)=-1$。根据输出更新权值$\Delta w=\eta o_j x_3=(0,-1,1,-1.5)$。更新后的权值$w(3)=w(2)+\Delta w=(1,-2.5,3.5,2)+ (0,-1,1,-1.5)=(1,-3.5,4.5,0.5)$。
4.结构细节(Architectural Details)

关于结构细节,我之前有一篇博客已经介绍过了,在此不再赘述,请戳链接:【深度学习基础】第三十一课:Inception网络。
为了解决naïve version计算量过大的问题,提出了Fig2(b)的版本,在naïve version的基础上添加了$1\times 1$卷积,这不仅大大降低了计算量,并且$1\times 1$的卷积中也使用ReLU激活函数。
通常情况下,在深层使用Inception模块而浅层保留传统的CNN模式是比较好的,但这也是作者的经验之谈,不一定适用于所有情况。
Inception模块对计算资源的优化利用使得我们可以增加每层的神经元数以及层数,并且不必担心因此会带来计算量的暴增。此外,作者发现他们的网络比相同性能但不使用Inception模块的网络要快2-3倍。
5.GoogLeNet
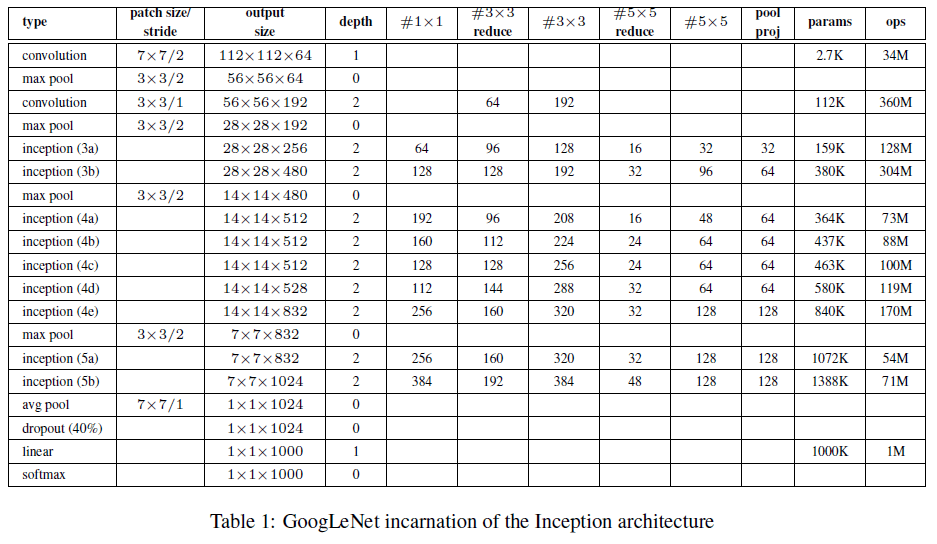
作者省略了网络的细节,因为他们的实验表明:对于特定的某一结构,参数的影响相对而言是很微小的。
所有的卷积层(包括Inception模块内部)的激活函数均为ReLU。网络输入为$224\times 224$大小的RGB彩色图像(输入做了去均值化)。“#$3\times 3$ reduce”和“#$5\times 5$ reduce”表示在$3\times 3$和$5\times 5$卷积之前使用的$1\times 1$卷积。
Table1可以搭配Figure3一起来看:
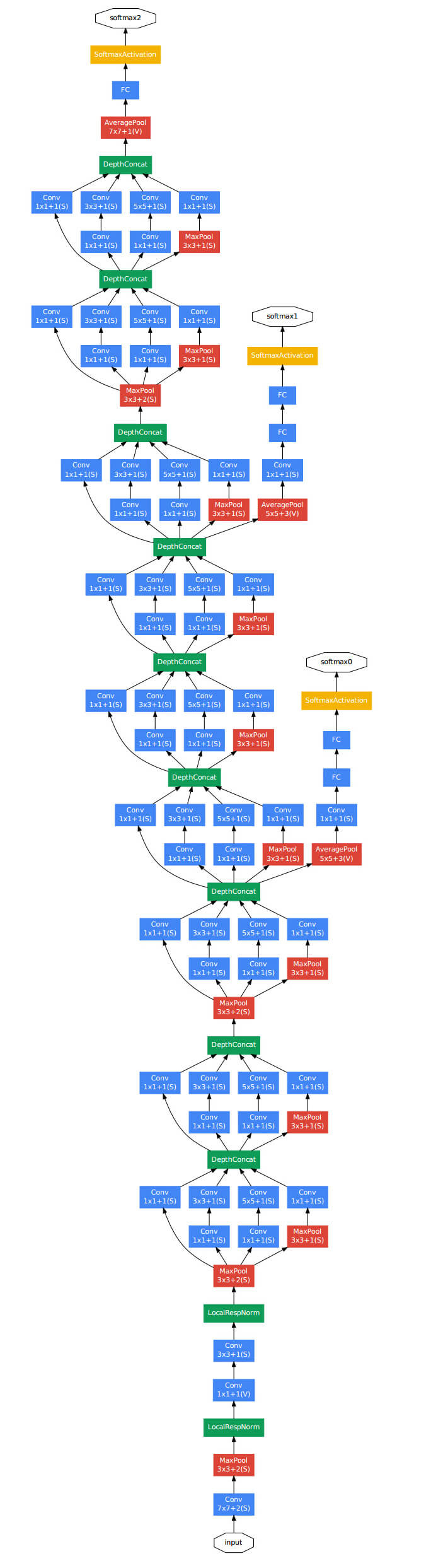
Table1中,“depth”一列指的是层数,例如inception(3a)包含了两层,该列加起来一共是22层(不计pooling层,如果计上pooling层,则一共为27层)。5~10列是filter的数量,以inception(3a)为例(64+128+32+32=256):
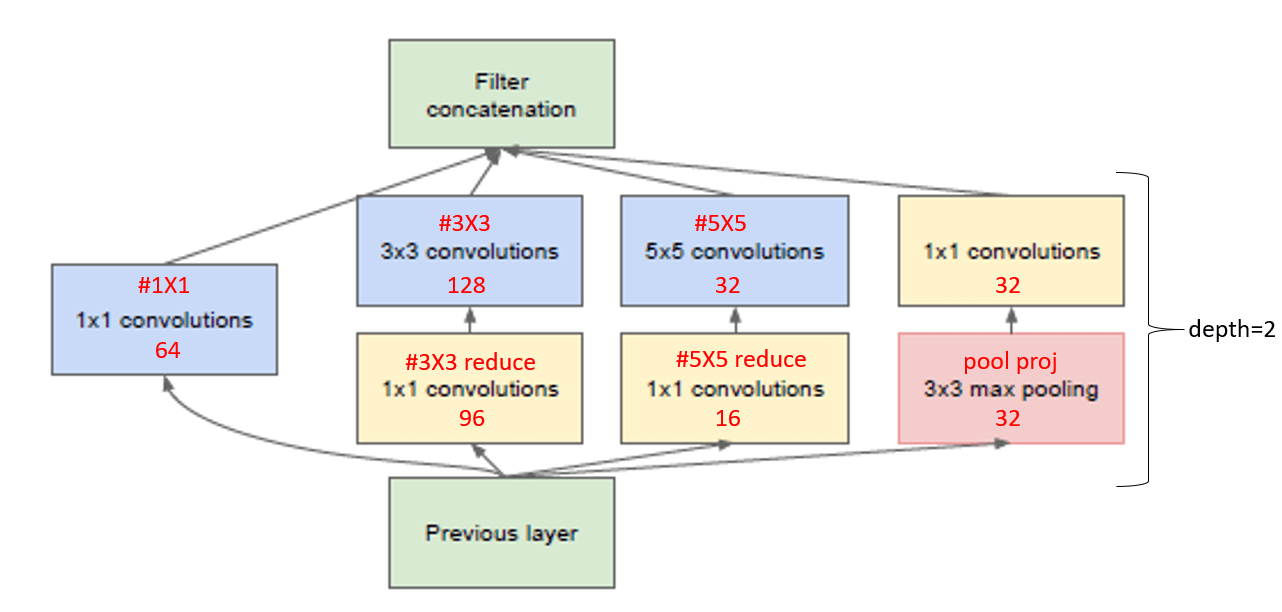
“params”列是参数数量,”ops”列是计算量。
可根据输出维度,自行推测padding的值。Fig3中也标识了stride和padding的方式,例如$7\times 7+2(S)$指的是filter大小为$7\times 7$,步长为2,padding方式为SAME((V)表示padding方式为VALID)。此外,从Fig3的网络结构中可以看出,GoogLeNet使用了LRN(LocalRespNorm)。
GoogLeNet在softmax层之前使用了average pooling(这一做法将top1正确率提升了0.6%),这一处理方式借鉴自NIN,不同的是GoogLeNet在average pooling和softmax层之间还添加了额外的线性层(即FC层)。这一小的改动并没有对模型性能有什么影响,只是为了使用其他数据集训练时方便fine-tune。
一方面为了避免梯度消失/梯度爆炸问题,另一方面有时中间层的特征也非常具有辨识度,因此GoogLeNet在inception(4a)和inception(4d)后添加了辅助分类器(auxiliary classifiers):


在训练阶段,辅助分类器的loss会被加到总loss内,但其权重只有0.3。在预测阶段,辅助分类器会被舍弃掉。
辅助分类器的构建细节:
- average pooling所用的filter大小为$5\times 5$,步长为3。inception(4a)中该pooling层输出大小为$4\times 4 \times 512$,inception(4d)中该pooling层输出大小为$4\times 4\times 528$。
- $1\times 1$的卷积层中filter共有128个,并且使用ReLU激活函数。
- FC层有1024个神经元,也使用ReLU激活函数。
- (最后一个FC层)使用了dropout,drop的概率为70%。
- softmax层和主分类器一样,也设有1000个类别,即包含1000个神经元。
6.训练方法(Training Methodology)
Google开发了一个叫做DistBelief的软件框架来训练超大规模的深度网络,该框架还提出了一种异步的随机梯度下降法(asynchronous stochastic gradient descent):Downpour SGD。GoogLeNet便是使用DistBelief框架进行训练的,其中momentum=0.9。此外,在训练过程中,每8个epoch学习率降低4%。在预测阶段,使用Polyak averaging的方法得到最终的模型。
DistBelief原文:Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao,Marc’aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, Quoc V. Le, and Andrew Y.Ng. Large scale distributed deep networks. In P. Bartlett, F.c.n. Pereira, C.j.c. Burges, L. Bottou,and K.q. Weinberger, editors, Advances in Neural Information Processing Systems 25,pages 1232–1240. 2012.
Polyak averaging原文:B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging. SIAMJ. Control Optim., 30(4):838–855, July 1992.
7.ILSVRC 2014 Classification Challenge Setup and Results
ILSVRC2014分类任务共有1000个类别。训练集120万图像,验证集5万图像,测试集10万图像。每张图像只能属于一个类别。
GoogLeNet的训练没有使用外部数据(即只使用比赛提供的训练集进行训练)。作者在测试阶段使用了以下技巧用于提升模型性能:
- 作者训练了7个版本的GoogLeNet(其中包含一个wider的版本),联合这7个模型的结果作为最终的预测结果。这些模型采用相同的初始化方式和学习率。不同之处在于采样方式和图像输入的随机顺序。
- 在测试阶段,GoogLeNet作者将图像的短边resize到256,288,320,352四个不同的尺寸。对于每个尺寸的图像,选择左中右三个区域(如果是肖像图,则选择上中下三个区域)。在每个区域内,裁剪6张$224 \times 224$大小的图像,并且对其进行镜像翻转。这6张裁剪图像的获得方式:四个角,中心,直接将该区域resize到$224 \times 224$大小。因此,每张原始图像可扩展成144张($4 \times 3 \times 6 \times 2=144$)图像。
- 取上述144张图像的平均结果作为该原始图像在该版本下的预测结果。最后再平均7个版本的预测结果得到最终预测结果。
作者最终提交给ILSVRC2014分类任务的模型,其在验证集和测试集上的top-5错误率为6.67%,排名第一。
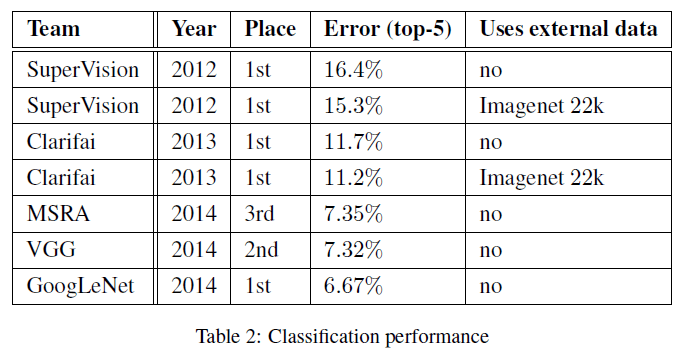
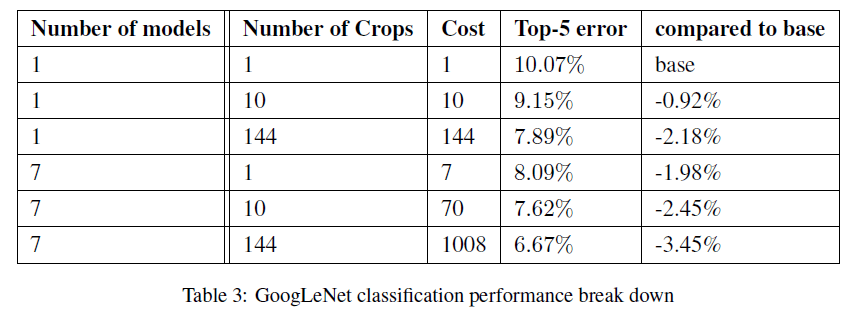
作者还测试了不同数量的模型搭配不同数量的扩展测试图像的错误率(验证集):
8.ILSVRC 2014 Detection Challenge Setup and Results
ILSVRC检测任务是使用bounding box圈出目标的位置。一共有200个不同的目标。检测出的bounding box如果和groundtruth重合率超过50%则认为预测正确。不同于分类任务,一张图像只属于一个类别,在检测任务中,一张图像可以没有目标或者同时存在多个目标,并且目标的大小也不确定,可能很大,也可能很小。使用mAP(mean average precision)作为评价指标。
mAP的计算:
mAP用于评价目标检测与分类的效果。AP是指一个类别的平均精度,它表示模型在某一个类别上的效果。mAP是所有类别AP的平均值,表示模型在所有类别上的整体效果。
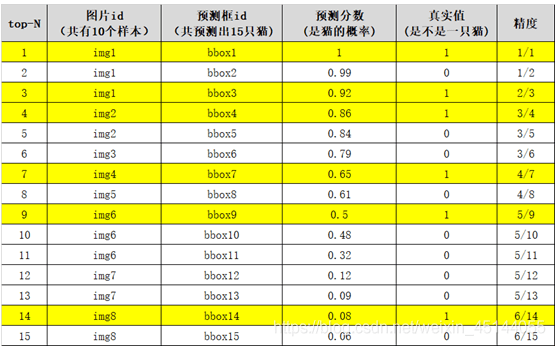
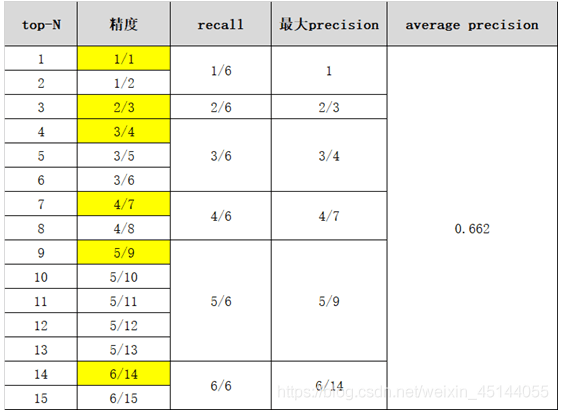
mAP的计算过程有点类似于绘制P-R曲线。以图像分类任务中的类别“猫”为例,假设测试集共有8个样本,共预测出15只猫,按bounding box的概率从高到底排序如下:
根据绘制P-R曲线的规则,我们可以得到15个混淆矩阵,也就是说可以计算出15个precision和recall:
0.662就是该类别的AP(average precision)值。mAP就是所有类别AP值的平均。
GoogLeNet的检测策略类似于R-CNN,但是限于时间,GoogLeNet并没有使用R-CNN中的bounding box regression。GoogLeNet在检测任务中使用了6个网络的组合,其表现见下:
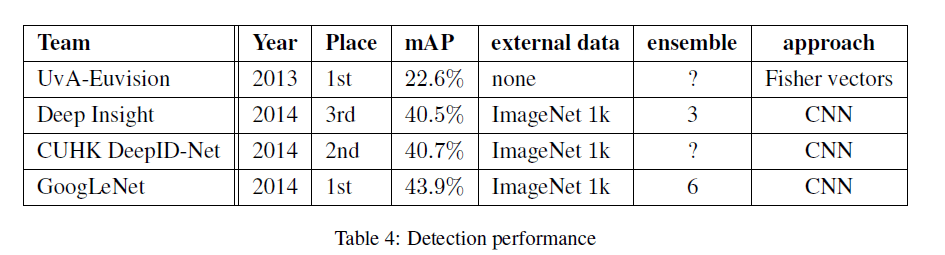
从表4中可以看出,ILSVRC2014检测任务的前三名均使用了CNN,并且都使用了额外的数据进行训练,此外,也都集成了多个模型进行最终结果的预测。
作者也比较了单个模型的性能,统计结果见表5:
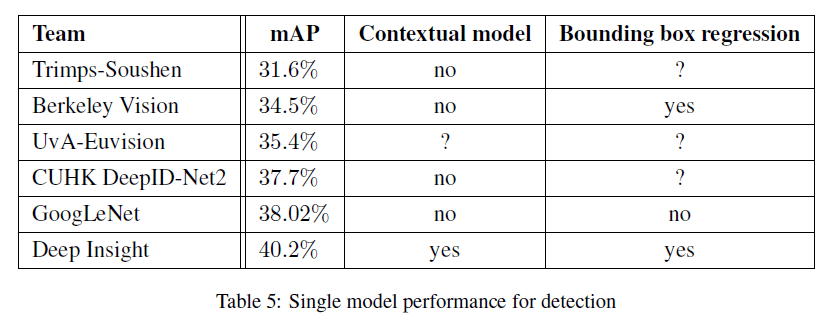
在仅使用一个模型的情况下,Deep Insight取得了最好的成绩,但是相比其集成3个模型的最终结果(40.2% vs. 40.5%),仅有0.3%的提升。但是GoogLeNet在集成多个模型之后(38.02% vs. 43.9%),结果有着显著的提升。
9.结论(Conclusions)
Inception模块这种稀疏的框架是可行且有效的。
10.原文链接
👽Going deeper with convolutions
