【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.$1\times 1$的卷积
$1\times 1$的卷积(也称“network in network”)操作和我们之前介绍的卷积操作是完全一样的,只不过卷积核的维度为$1\times 1$而已。例如:
![]()
2.Inception网络
在构建卷积层时,我们需要决定filter的大小究竟是$3\times 3$、$5\times 5$或者其他大小,并且还需要确定要不要添加池化层。而Inception网络的作用就是代替我们做这个决定。虽然网络结构因此变得更加复杂,但网络表现却非常好。
先来看下Inception模块的实现原理:
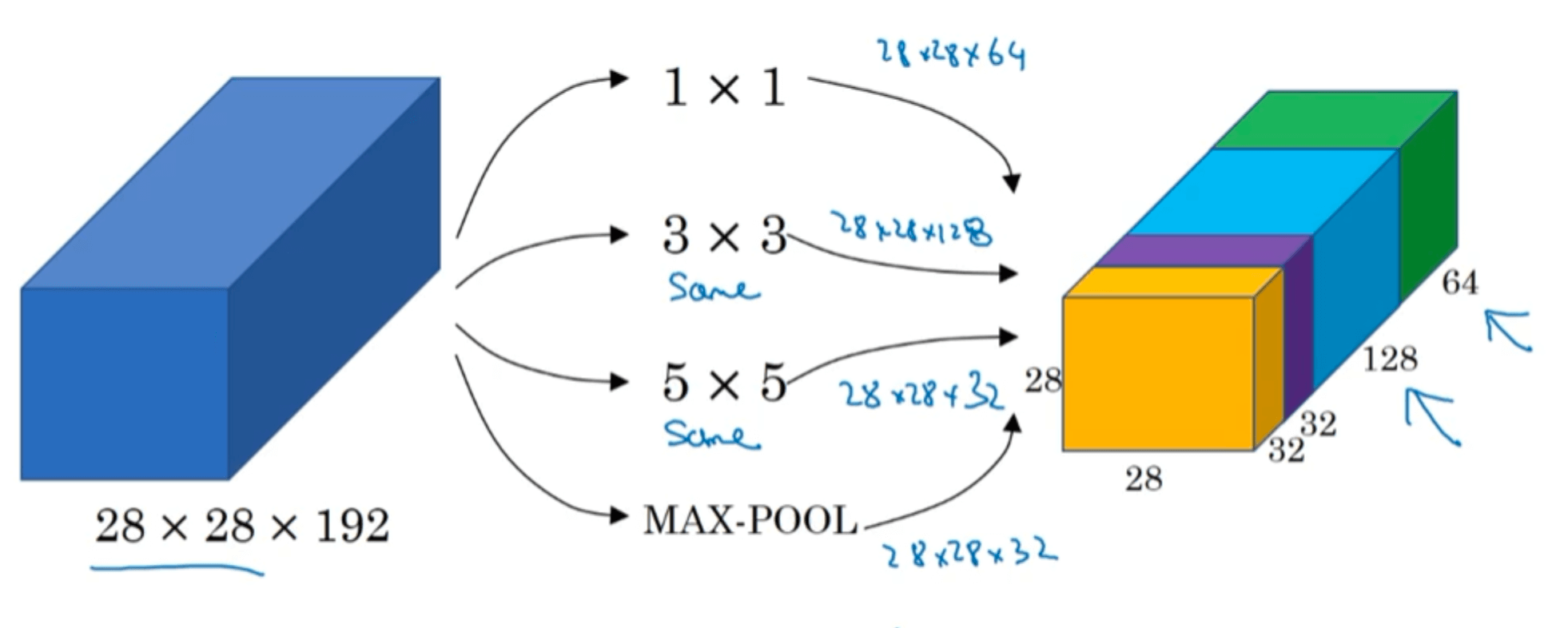
其中卷积操作的padding方式均为SAME。这里的MAX-POOL为了保持维度的一致,也使用了padding。本例的Inception模块中,输入为$28\times 28 \times 192$,输出为$28\times 28 \times 256$。模块使用哪种卷积核(或者几种卷积核的组合)或者是否需要池化,均由网络自行确定这些参数,即让网络自己学习它需要什么样的参数。
接下来我们来考虑一下计算成本的问题,以$5 \times 5$的卷积核为例:
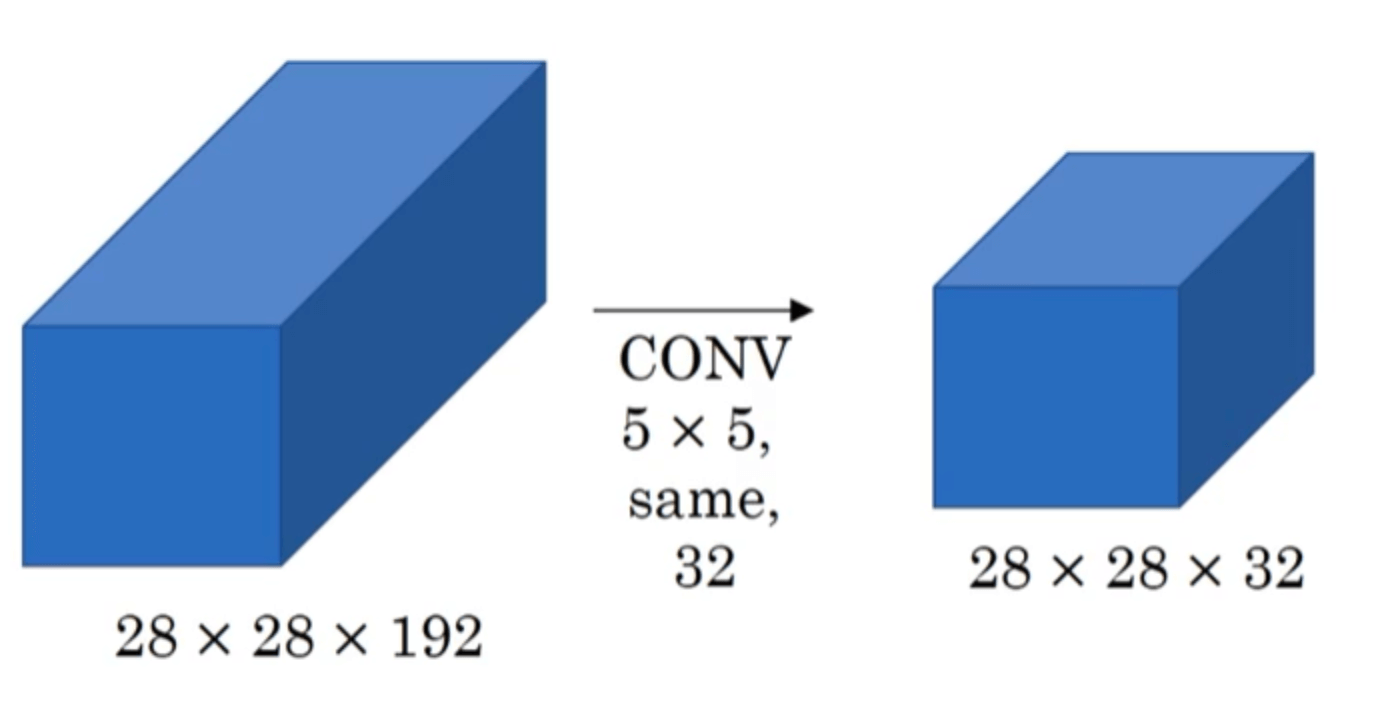
我们共进行了($5\times 5 \times 192 \times 28 \times 28 \times 32 =$)120,422,400次乘法。用计算机执行1.2亿次乘法运算的成本是相当高的。因此,引入$1\times 1$卷积来降低计算成本:
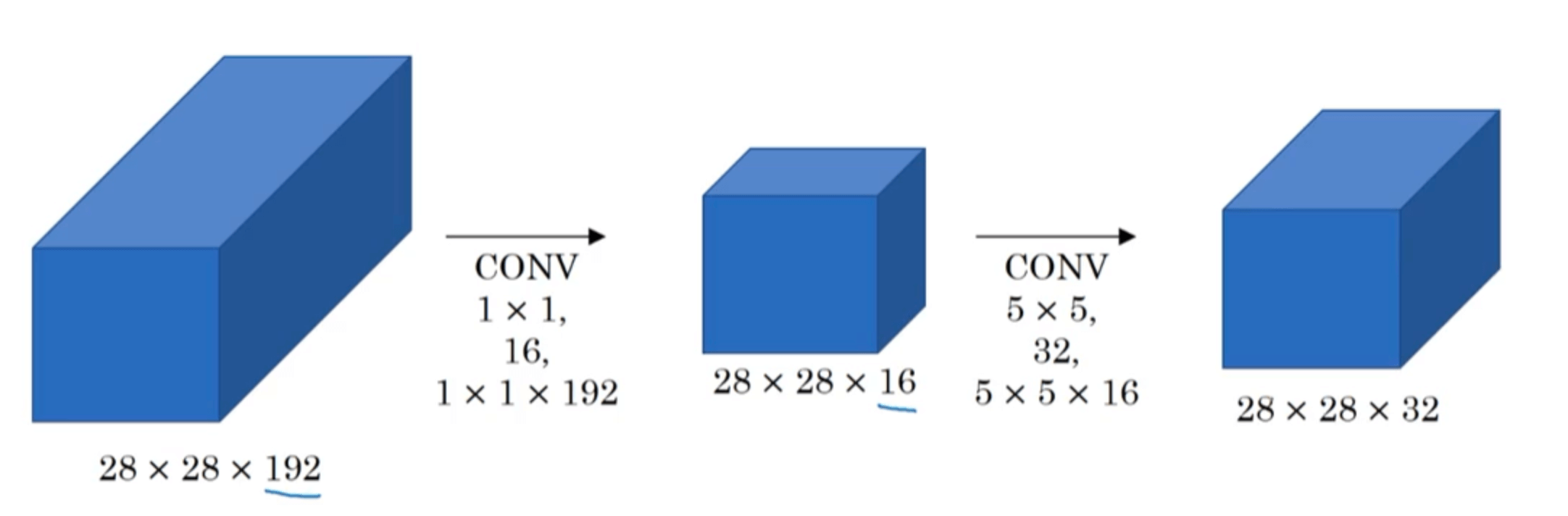
保持输入和输出维度不变,在中间添加$1\times 1$卷积进行过渡(有时被称为“bottleneck layer”)。经过如此改进之后,我们共进行了($1\times 1 \times 192 \times 28 \times 28 \times 16 + 5 \times 5 \times 16 \times 28 \times 28 \times 32=$)12,443,648次乘法。与之前相比,计算成本仅为之前的十分之一(加法运算的次数和乘法运算的次数近似,在此不再赘述)。并且事实证明,只要合理构建bottleneck layer,既可以显著降低运算成本,同时又不会降低网络性能。
据此,我们对Inception模块进行完善,如下:
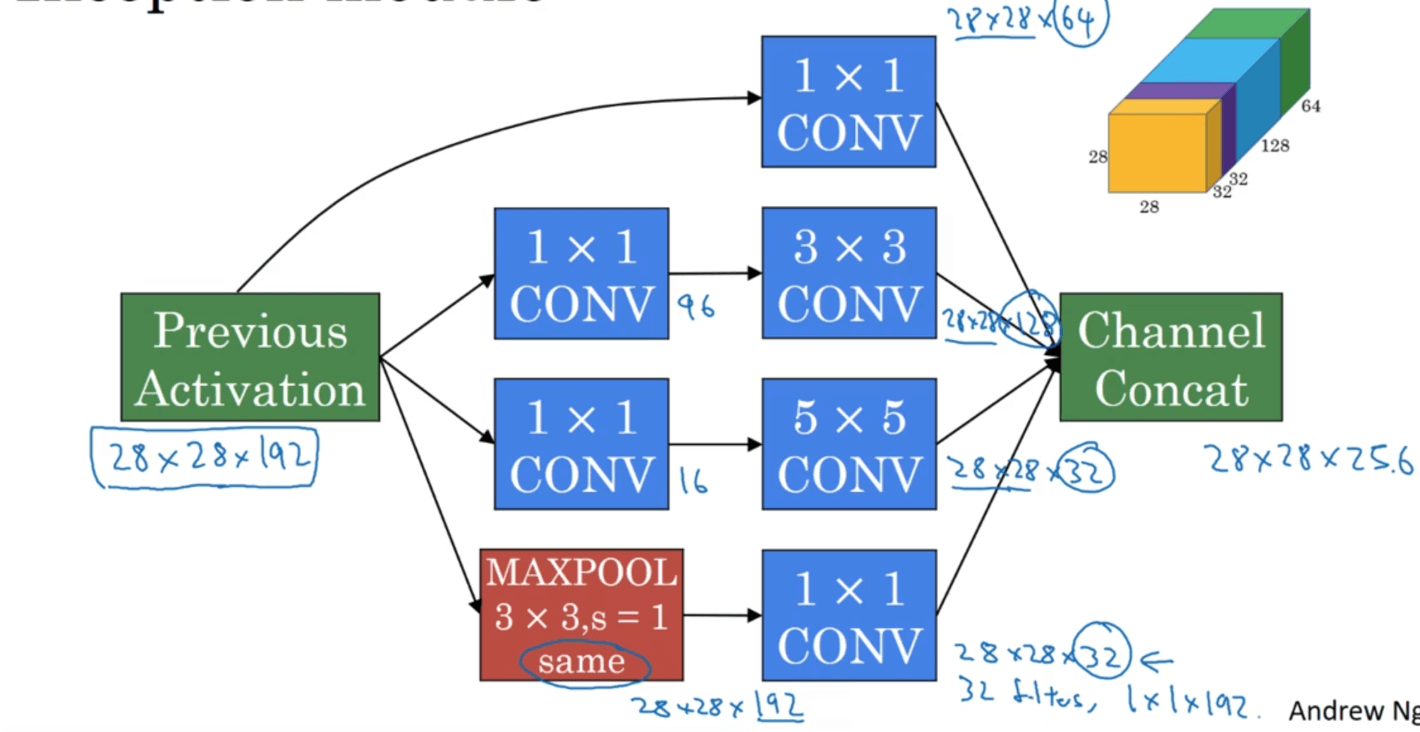
这里在MAX-POOL之后也添加了$1\times 1$卷积,是为了调整输出的深度(即通道数)。
而Inception网络就是将这些模块都组合到一起,例如:
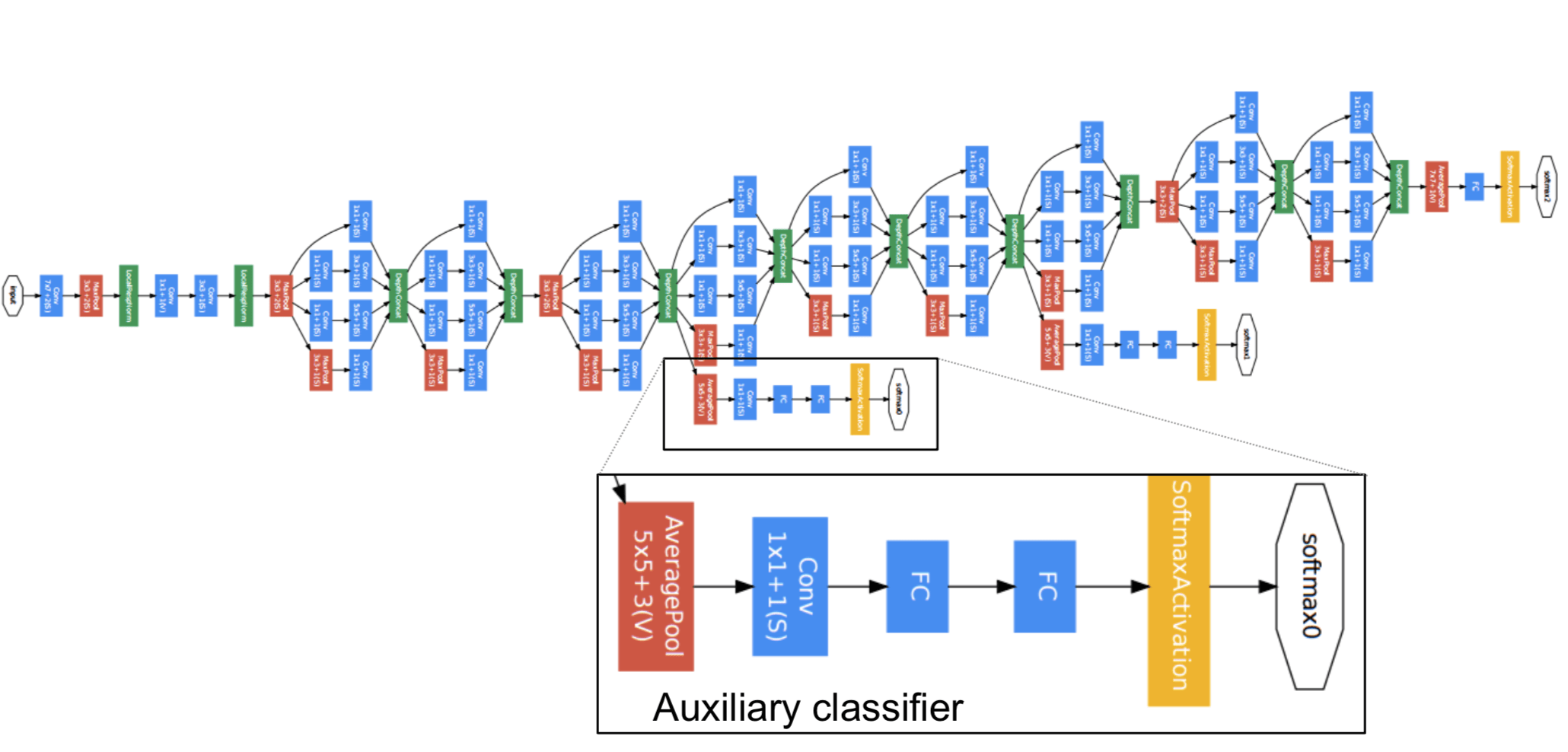
这里还有一个另外的细节就是还会有一些分支(Auxiliary Layer)。这些分支的作用就是通过隐藏层来做出预测。这么做的好处是,能提高网络中层的辨识能力,通过 Auxiliary Layer 提取中低层特征,防止梯度消失,提供正则化。
这个特殊的Inception网络也被称为GoogLeNet。该网络由google提出,这个名字是为了向LeNet网络致敬。
