本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.相关知识
2.代码实现
我们依旧以MNIST数据集为例。首先,载入必要的库:
1
2
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
读入MNIST数据集:
1
mnist = input_data.read_data_sets("../Demo3/MNIST_data/", one_hot=True)
定义一些变量:
1
2
3
4
5
6
n_inputs = 28 # 输入层神经元个数,每个神经元代表图像的一行,一行为28个像素
max_time = 28 # 一个图像一共有28行
lstm_size = 100
n_classes = 10 # 10个分类:0~9
batch_size = 50 # 每批次50个样本
n_batch = mnist.train.num_examples // batch_size # batch个数
定义输入和输出,并初始化权值和偏置项:
1
2
3
4
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
weights = tf.Variable(tf.truncated_normal([lstm_size, n_classes], stddev=0.1)) # 初始化权值
biases = tf.Variable(tf.constant(0.1, shape=[n_classes])) # 初始化偏置项
定义RNN网络:
1
2
3
4
5
6
7
8
9
# 定义RNN网络
def RNN(X, weights, biases):
inputs = tf.reshape(X, [-1, max_time, n_inputs])
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(lstm_size)
# final_state[0]是cell state
# final_state[1]是hidden state
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, inputs, dtype=tf.float32)
results = tf.nn.softmax(tf.matmul(final_state[1], weights) + biases)
return results
定义交叉熵损失函数并运行网络:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 计算RNN的返回结果
prediction = RNN(x, weights, biases)
# 损失函数
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y))
# 使用AdamOptimizer进行优化
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1)) # argmax返回一维张量中最大的值所在的位置
# 求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 把correct_prediction变为float32类型
# 初始化
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(6):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print("Iter " + str(epoch) + ", Testing Accuracy= " + str(acc))
得到最终预测结果,模型准确率见下:

3.tf.nn.rnn_cell.BasicLSTMCell
该API用于构建LSTM单元(cell),参数见下:
1
2
3
4
5
6
7
8
9
def __init__(self,
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None,
**kwargs)
部分参数解释:
👉num_units:

如上图所示,每个cell中的每一个小黄框都代表着一个前馈网络层。参数num_units就是这个层的隐藏神经元个数。其中第1,2,4个小黄框的激活函数是sigmoid,第3个小黄框的激活函数是tanh。
该API返回的是一个lstm cell,即上图中的一个A。
👉forget_bias:forget gate加上的偏置项。
👉state_is_tuple:默认为True。
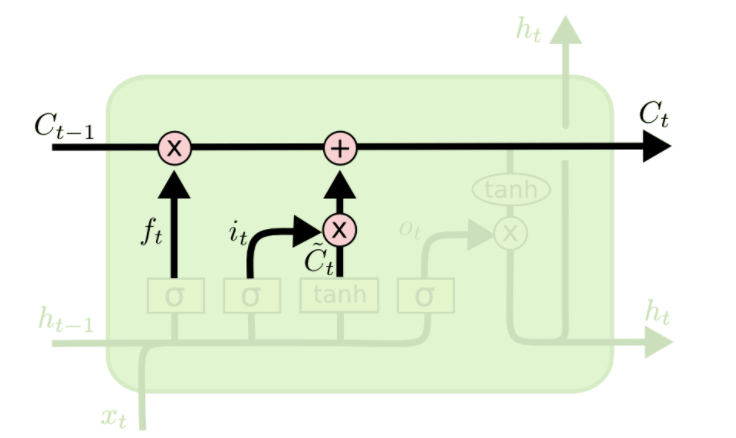

state_is_tuple=True返回的是一个表示state的tuple:(c=array([[]]), h=array([[]])。其中$c$代表cell输出的$C_t$,$h$代表cell输出的$h_t$。
👉activation:内部状态的激活函数。默认为tanh。
👉reuse:布尔类型。表示是否在现有范围内重用变量。
👉name:为string类型,代表层的名称。具有相同名称的层将共享权重,但为了避免错误,在这种情况下需要reuse=True。
👉dtype:该层默认的数据类型。
4.tf.nn.dynamic_rnn
该API用于使用cell构建RNN,参数见下:
1
2
3
4
5
6
7
8
9
def dynamic_rnn(cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None)
部分参数解释:
👉cell:RNN的基本单元,可以是LSTM或者GRU。
👉inputs:输入的训练或测试数据。如果time_major=False,inputs的格式为[batch_size,max_time,embed_size],其中batch_size是输入的这批数据的数量,max_time就是这批数据中序列的最长长度,embed_size表示嵌入的词向量的维度。如果time_major=True,inputs的格式为[max_time,batch_size,embed_size]。
👉sequence_length:一个可选参数,是一个list。如果你要输入三句话且这三句话的长度分别是5,10,25,那么sequence_length=[5,10,25]。
👉initial_state:可选参数,RNN的初始state。
👉dtype:可选参数,为initial_state和outputs的数据类型。
👉parallel_iterations:并行运行的迭代次数,默认为32。个人理解指的是下图中四个并行的小黄框所代表的网络的迭代次数:
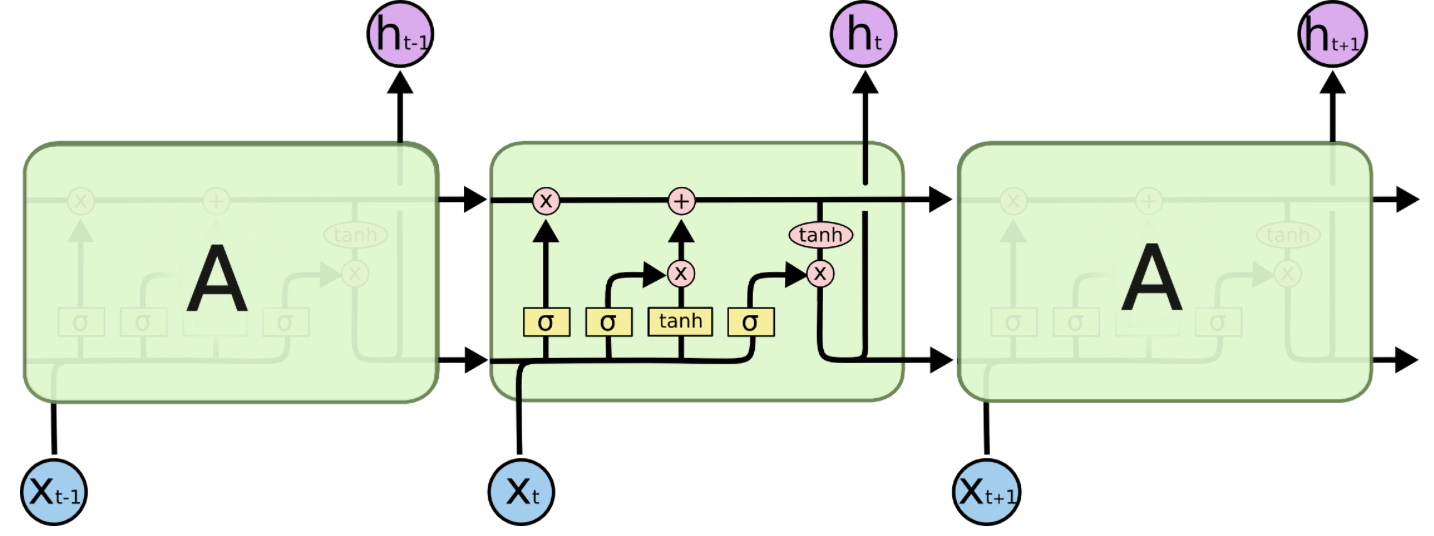
👉swap_memory:Transparently swap the tensors produced in forward inference but needed for back prop from GPU to CPU. This allows training RNNs which would typically not fit on a single GPU, with very minimal (or no) performance penalty.
👉time_major:布尔类型。决定输入、输出的格式,详情见inputs参数解释(输出格式和输入保持一致)。
👉scope:VariableScope for the created subgraph; defaults to “rnn”.
tf.nn.dynamic_rnn的返回值是一个tuple:(outputs,states)。outputs是RNN最后一层的输出,states储存的是最后一个cell输出的states。一般情况下states的形状(例如当cell为GRU单元时)为[batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size],其中2也对应着LSTM中的cell state(即$c^{<t>}$)和hidden state(即$a^{<t>}$)。
举个例子说明一下,假设我们的LSTM网络只有一层,包含两个cell(即max_time=2):

并且设输入的维度为[batch_size=3,max_time=2,embed_size=4],num_units=5。则outputs的维度应该是[batch_size=3,max_time=2,num_units=5](即$a^{<1>},a^{<2>}$),states的维度应该是[2,batch_size=3,num_units=5](即$c^{<2>},a^{<2>}$)。巧合的是,因为网络只有一层,所以在这个例子中有outputs[3,2,:]=states[2,3,:]。
