本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.简介(Introduction)
开篇先强调了特征的重要性。在过去几十年里,各类视觉识别任务基本都是基于SIFT特征和HOG特征。但是从其在PASCAL VOC目标检测任务中的表现就可以看出,在2010-2012年间,其发展很慢,没有显著的性能提升。
PASCAL VOC(PASCAL:pattern analysis, statistical modelling and computational learning,VOC:visual object classes)挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。官方网址:http://host.robots.ox.ac.uk/pascal/VOC/。
CNN曾经在20世纪90年代非常流行,但是随着SVM的出现,CNN逐渐淡出人们的视野。直到ILSVRC2012中AlexNet取得了分类任务和定位任务第一名的好成绩,才重新燃起了人们对CNN的兴趣。
本文是首篇论文:证明了相比简单的类HOG特征,CNN可以在PASCAL VOC目标检测任务中取得更优异的表现。本文为了验证这个结论,主要聚焦在两个问题:1)使用深度网络定位目标;2)使用少量带标注数据去训练一个大型网络。
不同于图像分类任务,目标检测任务通常需要在一张图片上定位出多个目标的位置。其中一种目标检测的方法是将其看作一个回归问题,作者采用这种方法在VOC2007取得了mAP=58.5%的成绩,相比同期且相同思路的C. Szegedy, A. Toshev, and D. Erhan. Deep neural networks for object detection. In NIPS, 2013.(mAP=30.5%),表现有所提升,但是依旧效果不好。另一种办法就是使用CNN,作者构建的网络共5个卷积层,(POOL5层的神经元)感受野大小为$195 \times 195$,(POOL5层的神经元映射回原图的)步长为$32 \times 32$。
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。
例如,三层$3\times 3$卷积核操作之后的感受野是$7\times 7$:

作者所用模型结构:

先从原始输入图像中提取大约2000个备选区域(region proposals),然后将每个region proposal缩放到同一尺寸进入CNN网络,输出层为线性SVM(有多少个类别,就构建多少个SVM)。因此,作者所使用的模型结构被称为R-CNN:Regions with CNN features。R-CNN在PASCAL VOC 2010的mAP为53.7%,优于另一种同样使用region proposals,但是搭配spatial pyramid和bag-of-visual-words的方法(mAP=35.1%)。在200个类别的ILSVRC2013检测数据集上,R-CNN的mAP=31.4%,优于当时的最佳方法OverFeat(mAP=24.3%,OverFeat使用的方法是基于滑动窗口的CNN)。
检测过程中面临的第二个挑战是带标签数据的缺乏,因为训练一个大型CNN网络需要大量的带标签数据。传统的解决办法是先进行无监督的预训练,然后使用有监督的fine-tune。本文提出了一种新的有效的解决办法:先使用其他相关的大型数据集(ILSVRC)进行有监督的预训练,然后再用自己的小型数据集(PASCAL)在特定区域(domain-specific)进行有监督的fine-tune。这一改进使得本文的检测模型性能提升了8%。作者认为该方法在数据稀少的情况下去训练一个大型CNN网络是非常有效的。
CNN的特征共享也使得R-CNN变得更为高效。此外,bounding-box回归有效降低了mislocalization类型的错误。
R-CNN也可以用于语义分割(semantic segmentation)。通过少量的修改,R-CNN在PASCAL VOC分割任务中,在VOC 2011测试集上取得了相当不错的成绩,平均分割准确率为47.9%。
2.使用R-CNN进行目标检测(Object detection with R-CNN)
R-CNN包含3个模块:1)第一个模块用于生成region proposals,这些proposal会作为下一个模块的输入,即CNN网络的输入。2)第二个模块是一个CNN网络,每一个region proposal进入CNN,都会对应生成一个固定尺寸的特征向量。3)第三个模块为线性SVM分类器,输入为第二个模块生成的特征向量,该分类器会判断此region是否为目标所在位置。
2.1.模块设计(Module design)
Region proposals:
产生region proposal的方法有很多,例如:
- objectness:B. Alexe, T. Deselaers, and V. Ferrari. Measuring the objectness of image windows. TPAMI, 2012.
- selective search:J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013.
- category-independent object proposals:I. Endres and D. Hoiem. Category independent object proposals. In ECCV, 2010.
- constrained parametric min-cuts (CPMC):J. Carreira and C. Sminchisescu. CPMC: Automatic object segmentation using constrained parametric min-cuts. TPAMI, 2012.
- multi-scale combinatorial grouping:P. Arbel´aez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In CVPR, 2014.
- Ciresan:D. Cires¸an, A. Giusti, L. Gambardella, and J. Schmidhuber. Mitosis detection in breast cancer histology images with deep neural networks. In MICCAI, 2013.
R-CNN所用的方法为selective search。
Feature extraction:
CNN部分使用了AlexNet,但是去掉了最后的softmax层(即网络结构变为5CONVs+2FCs),网络的输出为4096维的特征向量。网络的输入为$227 \times 227$大小的RGB图像。
R-CNN需要将不同尺寸的region proposal统一变换为$227 \times 227$大小(作为CNN网络部分的输入)。具体变换方法见Appendix A部分。warp的结果见Fig2。

2.2.检测阶段耗时测试(Test-time detection)
在检测阶段,RCNN使用selective search的fast mode挑选出大约2000个左右的region proposal,这些proposal经过warp之后进入CNN,从CNN得到的特征向量作为训练好的SVM的输入,然后将SVM的输出作为该proposal的得分(得分可以理解为该proposal最有可能属于哪个类别的概率值,这个概率值应该是输出层所有SVM分类器所预测出来的最大值)。最终我们会得到这2000多个region proposal属于各自预测类别的得分,然后针对每个类别,分别应用贪婪的非极大值抑制(greedy non-maximum suppression),即如果该proposal和同属一个类别但得分更高的另一个proposal的IoU大于某一阈值,则该proposal会被舍弃。
Run-time analysis。两大特性使得检测更为高效。1)CNN的共享权重机制;2)CNN输出的特征向量相比其他常规方法,维度要小很多。
计算region proposal的耗时可以分摊到所有类别的头上(在GPU上,一张图需要13秒;在CPU上,一张图需要53秒)。唯一和具体类别有关的计算是特征向量和SVM权重的点积以及NMS。在实际应用中,所有点积都可以批量化成矩阵间的计算。特征矩阵的大小为$2000 \times 4096$(2000为region proposal的数量),SVM权重矩阵大小为$4096 \times N$,其中N是类别的数量。
R-CNN可以被轻易的扩展到100k个类别,在多核CPU上运行也仅需要10秒左右。
2.3.训练(Training)
Supervised pre-training:
作者使用了ILSVRC2012分类任务的数据集进行了CNN网络部分的预训练(该数据集只提供了图像类别标签,无bounding box)。使用的框架为Caffe。作者训练得到的CNN网络的top-1错误率比AlexNet高了2.2%,这是由于训练步骤的简化造成。
Domain-specific fine-tuning:
训练方法为MBGD(论文中写的是SGD,其实指的是MBGD)。输出层的单元数为N+1,N为类别数,1为背景(即将AlexNet的输出层由1000个神经元改为N+1个神经元)。和ground-truth的IoU大于等于0.5的region proposal被认为是正样本,否则为负样本。使用的学习率为0.001(预训练阶段的学习率为0.1)。mini-batch size=128,包含32个正样本(不局限于同一类别)和96个负样本,之所以正负样本的数量不设置为相等,是因为在实际情况中,正样本的数量本来就是远远少于负样本的。
这里的Domain-specific指的是网络的输入为经过warp后的region proposal(warp方法详情请见Appendix A部分)。
个人理解:这部分仅用来在预训练模型的基础上fine-tune CNN部分。在R-CNN中,CNN部分是AlexNet去掉输出层,但是在fine-tune时,会把CNN部分加上一个输出层(例如softmax层,训练完毕后再移除该层,保留训练好的网络参数)。输出层如上段所述,共有N+1个神经元。CNN部分和SVM部分是分开训练的,个人理解是先训练好CNN部分,然后再训练SVM部分,SVM部分的输入是已经训练好的CNN输出的特征向量(但是得注意IoU阈值的不同)。
Object category classifiers:
在训练SVM分类器时,只有IoU=1的样本(即ground-truth)会被认为是正样本,IoU<0.3的样本被认为是负样本(0.3<IoU<1的样本在训练时会被忽略,即不参与训练SVM)。作者认为0.3这个阈值非常重要。在确定该阈值时,作者使用了网格搜索的方法,在验证集上测试了多个阈值$\{0,0.1,…,0.5 \}$。当阈值设为0.5时,mAP下降5%;当阈值设为0时,mAP下降4%。
针对每个类别,分别优化各自的SVM分类模型。但是因为训练集过大,无法全部放到内存中,作者使用了hard negative mining的方法以使得模型快速收敛。
R-CNN所用的hard negative mining方法的主要思路:
- 对于R-CNN的应用场景来说,正样本数量远远小于负样本数量。在第一次训练时,通常控制训练集中正负样本的比例为1:3,即负样本只选取其中一个子集(随机选取即可)。
- 将训练好的模型用于检测剩余的负样本,把检测错误的负样本加入到训练集中。
- 重新训练模型。如果模型性能收敛或达到预期值则停止训练;否则回到第2步。
作者关于hard negative mining引用了两篇文献:
- P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010.
- K. Sung and T. Poggio. Example-based learning for viewbased human face detection. Technical Report A.I. Memo No. 1521, Massachussets Institute of Technology, 1994.
在Appendix B中,作者说明了为什么训练CNN和SVM时判定正负样本用的IoU阈值不同。并且进一步讨论了训练SVM时没有简单直接的使用fine-tuned CNN的softmax层输出的原因。
2.4.在PASCAL VOC 2010-12上的表现(Results on PASCAL VOC 2010-12)
使用VOC2012的训练集(train)fine-tune CNN部分,使用VOC2012的训练验证集(trainval)优化SVM分类器。作者最终提交了两个版本,一个带bounding-box回归(bounding-box regression),一个不带。
Table1列出了R-CNN与四个优秀的baseline方法在VOC2010数据集上的性能对比。显然,R-CNN BB(R-CNN with bounding-box regression)取得了最好的性能,mAP=53.7%。此外,在VOC2011/12的测试集上,R-CNN BB也取得了类似的性能,mAP=53.3%。

2.5.在ILSVRC2013上的表现(Results on ILSVRC2013 detection)
作者也在ILSVRC2013检测任务(共200个类别)的数据集上进行了测试,共提交了两个版本:一个带BB(即Bounding Box Regression),一个不带BB。

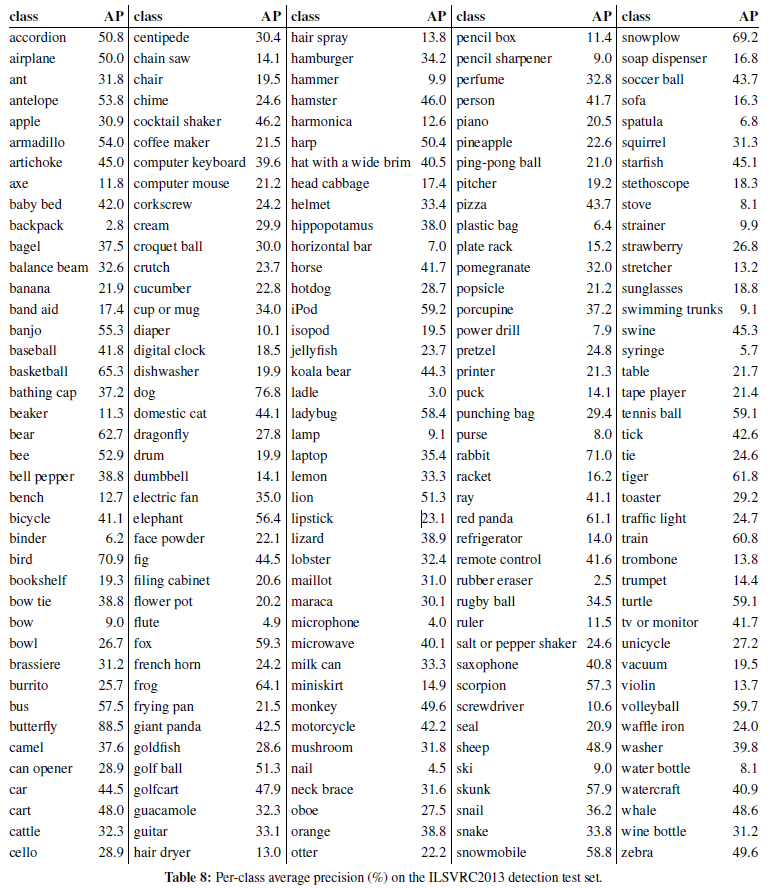
Fig3展示了R-CNN和其他算法(在ILSVRC2013检测任务中表现优异的算法)的对比结果。R-CNN的mAP=31.4%,明显优于其他算法。R-CNN在每个类别上的AP值见下表(Table8)。Fig3中的许多算法都应用了CNN,这说明CNN使用方式的不同会造成结果的极大差异。
在第4部分,作者给出了R-CNN在ILSVRC2013检测数据集上的实现细节。
3.可视化、消融和误差模式(Visualization, ablation, and modes of error)
3.1.可视化学到的特征(Visualizing learned features)
作者并没有使用ZFNet提供的网络可视化方法。而是使用了一种简单的非参数化的方法,直接展示网络学到的东西。
与ZFNet提供的可视化方法类似,作者所用的方法也是先选定一个神经元,计算大量region proposal(大约一千万个)在通过该神经元时计算得到的激活值,根据这些激活值的高低进行NMS,然后显示高得分(即激活值高)的区域。
作者可视化了CNN网络部分的POOL5层。该层的输出大小为$6 \times 6 \times 256 = 9216$。POOL5层中的每一个神经元映射回原图($227\times 227$)的感受野大小为$195 \times 195$(不考虑边界影响),接近全局视图。
Fig4的每一行代表POOL5中的某一神经元(共展示了6个神经元的结果),针对每个神经元,共展示了激活值最大的16个region proposal。白色框为该神经元对应的感受野,左上角的白色数字为激活值(经过了归一化处理,归一化方式为除以该神经元所在通道的所有神经元的最大激活值)。从Fig4可以很明显的看出,第一行所代表的神经元主要学到了人物信息,第二行学到了点阵信息,第四行学到了数字信息,第六行学到了反光物体信息。更多可视化结果见Appendix D。

3.2.消融研究(Ablation studies)
ablation study 就是为了研究模型中所提出的一些结构是否有效而设计的实验。如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。也就是控制变量法。
Performance layer-by-layer, without fine-tuning.
为了找出CNN中哪一层对检测性能才是至关重要的,作者针对CNN网络部分的最后三层(POOL5、FC6、FC7)进行了消融研究。首先考虑去掉fine-tune步骤可能会出现什么结果。

其结果可见表2的第一到第三行(这三行的结果均去掉了fine-tune步骤)。第一行指的是CNN网络部分去掉FC6和FC7;第二行指的是CNN网络部分仅去掉FC7;第三行则保留CNN网络的全部后三层。基于PASCAL得到的该测试结果。所有的CNN网络参数都在ILSVRC2012上预训练过。可以看出在去掉fine-tune步骤的前提下,FC7层并没有什么作用,这就意味着CNN网络部分29%的参数(即FC7层的参数占比,FC7层共有参数:$4096 \times 4096= 16777216 \approx 16.8M$)是可以被移除的。令人惊讶的是第一行的结果,网络参数只占原来的6%,却取得了相当不错的性能。由此看来,CNN的强大能力主要是来自卷积层,而不是全连接层。
Performance layer-by-layer, with fine-tuning.
接下来考虑加入fine-tune(简写为FT)步骤的情况,结果见表2的4-6行(每一行的解读和前三行类似,唯一的不同就是加入了FT步骤)。使用VOC2007的训练验证集(trainval)进行FT。可以看出FT使得mAP上升了8%(去掉FT的最高mAP为46.2%,添加FT的最高mAP为54.2%,相差8%)。FC6(46.2% $\rightarrow$ 53.1%)和FC7(44.7% $\rightarrow$ 54.2)的提升明显优于POOL5(44.2% $\rightarrow$ 47.3%),这说明在预训练阶段,卷积层从ImageNet数据集中学得的特征通用性很强(因为前面的卷积层学到的大多都是边缘信息,纹理信息等局部特征,所以通用性很强),而后面的全连接层学到的特征更有针对性(学到的特征更为全面,整体性更强),应用的数据集不同会有很大的不同,通用性很弱。
Comparison to recent feature learning methods.
与另外三种优秀算法的比较见表2的8-10行。可以看出,表2中任何的R-CNN模型的性能都优于DPM baseline。
3.3.网络结构(Network architectures)
本文的大部分结果所用的网络结构都来自AlexNet。并且作者发现网络结构的选择对R-CNN的检测性能有着很大的影响。表3列出了将AlexNet替换为VGG16在VOC2007数据集上进行测试的结果。

表3的第一行为网络部分使用AlexNet,第二行在此基础上又添加了bounding box回归。第三行和第四行的网络部分为VGG16,第四行又额外添加了bounding box回归。
作者测试用的O-Net(OxfordNet,即VGG16)使用了公开的预训练好的网络权重参数。然后使用了和T-Net(TorontoNet,即AlexNet)一样的fine-tune策略。唯一的不同在于,因为显存的原因,O-Net使用的minibatch size=24。从表3中可以看出,R-CNN O-Net的性能明显优于R-CNN T-Net。但是,O-Net前向传播的时间(可理解为预测耗时)为T-Net的7倍。
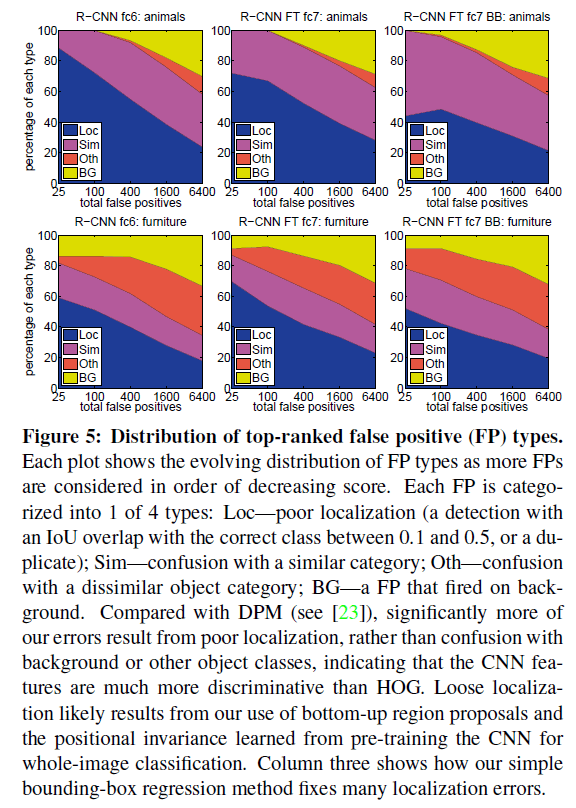
3.4.检测错误分析(Detection error analysis)
作者使用了D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. In ECCV. 2012.一文中的错误分析工具进行错误分析。此举为了揭示作者所用方法的错误模式,fine-tune是如何优化这些错误的以及和DPM相比,作者所用方法错误类型的异同。分析结果见Fig5和Fig6。

3.5.Bounding-box回归(Bounding-box regression)
详见Appendix C。表1、表2和Fig5都显示BB可以有效的提升模型性能。
3.6.定性结果(Qualitative results)
在ILSVRC2013上的定性检测结果见Fig8和Fig9。图片是从$val_2$数据集(mAP=31.0%)中随机选取的,展示了准确率大于0.5的结果。更多的定性结果见Fig10和Fig11(也是准确率大于0.5的结果才展示出来)。




Fig8-Fig11中bounding-box的左上角为预测类别和准确度(precision value)。
4.ILSVRC2013检测任务数据集(The ILSVRC2013 detection dataset)
第2.5部分展示了R-CNN在ILSVRC2013检测数据集上的结果。本部分将进一步说明。
4.1.数据集概览(Dataset overview)
ILSVRC2013检测数据集分为三部分(括号内为数据量):训练集(395,918)、验证集(20,121)和测试集(40,152)。验证集和测试集服从同一图像分布。这些图像在复杂程度上与PASCAL VOC数据集类似。验证集和测试集是带有bounding-box标记(包含类别标签)的。相反的,训练集则和ILSVRC2013分类任务的图像分布保持一致。这些图像更为多变。因为数据量庞大的原因,训练集的图像并没有被详细标注。也就是说训练集的图像中,有些目标被标注出来了,而有些则没被标注。除此之外,每一个类别都有一组负样本集,即不包含该类别目标的图像集。本文未使用这些负样本集。更多有关ILSVRC的图像收集以及标注的信息请见以下两篇论文:
- J. Deng, O. Russakovsky, J. Krause, M. Bernstein, A. C.Berg, and L. Fei-Fei. Scalable multi-label annotation. In CHI, 2014.
- H. Su, J. Deng, and L. Fei-Fei. Crowdsourcing annotations for visual object detection. In AAAI Technical Report, 4th Human Computation Workshop, 2012.
这几个数据集为训练R-CNN提供了多种选择。因为标注不全的缘故,训练集不能用于hard negative mining(hard negative mining见第2.3部分)。那我们的负样本该来自哪里呢?并且,验证集以及测试集的数据分布和训练集也不一样,那我们还应该使用训练集进行训练吗?如果用,我们该怎么用呢?作者并没有对这么多的可能性一一进行评估,只是根据以往经验,选择了一个理应不错的方法。
我们的策略是以验证集为主,并使用一些训练集中的正样本作为辅助。验证集即被用于训练,也被用于验证,我们将验证集分为$val_1$和$val_2$。但是在验证集中,有一些类别的样本很少(最少的只有31个样本,一半的类别的样本数都少于110个),所以很有必要对其做下平衡处理。那是怎么进行平衡处理的呢?首先需要有一个指标,用于衡量数据集的不平衡程度。作者所用的指标称为“relative imbalance”,计算方法见下:
\[\frac{\mid a -b \mid}{a+b}\]$a,b$为数据集中任意两个类别的数量。很显然,两个类别的数量差距越大,其“relative imbalance”越接近1;两个类别的数量差距越小,其“relative imbalance”越接近0。将验证集分为$val_1$和$val_2$有很多种分法,我们的目标就是找到一种分法使得$val_1$的最大“relative imbalance”和$val_2$的最大“relative imbalance”之和最小(求和为个人猜测,具体以作者公开的代码为准)。我们通过聚类的方法来产生多种不同的分法。作者在文中也提到后续会公开这部分的代码。
4.2.备选区域(Region proposals)
Region proposals的产生方法和之前一样,也是selective search。采用”fast mode”,应用于$val_1,val_2$和测试集中每一幅图像(不包括训练集中的图像)。但是此处需要一个小的修改,就是selective search产生的region数量依赖于图像的分辨率。ILSVRC中图像的分辨率从几个像素到百万级像素不等,图像分辨率差异非常大。因此在执行selective search之前,先对图像进行resize处理,将图像的width统一resize到500个像素。在验证集,平均一张图像可产生2403个region proposal,recall可达91.6%(与GT的IoU阈值设为0.5)。recall明显低于其在PASCAL上的值(98%),说明region proposal阶段还有很大的完善空间。
4.3.训练数据(Training data)
训练数据的构成:$val_1$中通过selective search产生的所有region proposal+$val_1$中所有的GT+训练集中每个类别选取N个GT(如果有的类别GT数量不足N个,则全部选取)。我们将该数据集称为$val_1+train_N$。在第4.5部分的消融研究中,我们也展示了$val_2$搭配$N\in \{0,500,1000 \}$的mAP。训练数据用于三个步骤:1)CNN fine-tuning;2)SVM的训练;3)bounding-box回归模型的训练。对于CNN fine-tuning,使用和之前一样的训练方法,迭代了50k次。使用Caffe框架,在单个NVIDIA Tesla K20显卡上跑了13个小时。对于SVM的训练,$val_1+train_N$中的所有GT被用作正样本。在执行hard negative mining时,只使用了从$val_1$中随机选取的5000张图像(大约是$val_1$的一半),相比使用$val_1$中所有的图像,虽然mAP略有下降(下降了0.5%),但是训练SVM的时间缩短了近一半。没有从训练集中选取负样本,因为其标注不完全。未使用额外的已标注好的负样本集。bounding-box回归模型基于$val_1$进行训练。
4.4.验证和评估(Validation and evaluation)
模型中所有的超参数(例如SVM C hyperparameters,warp时所用的padding值,NMS阈值,bounding-box回归模型的超参数等)和在PASCAL数据集上所用的保持一致。虽然这些超参数对于ILSVRC数据集可能不是最优的,但是我们的目的在于:在不使用额外数据集fine tune的情况下,使用R-CNN在ILSVRC上产生一个初步的结果。作者向ILSVRC2013提交了两个结果。一个结果使用了bounding-box回归,另一个没有使用。对于这两个提交,SVM的训练使用了全部的验证集,即$val+train_{1k}$,bounding-box回归模型的训练仅使用了整个验证集。对于CNN fine tuning,基于的数据集是$val_1 + train_{1k}$。
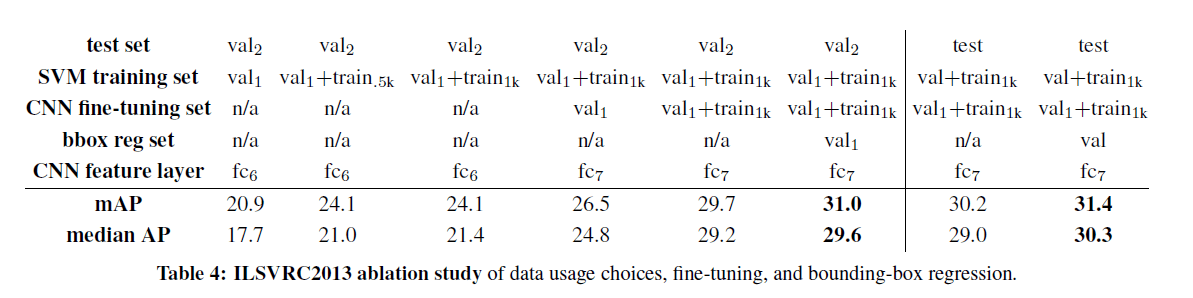
4.5.消融研究(Ablation study)
消融研究的结果见表4。首先,使用测试集或使用$val_2$进行测试,得到的最好结果相差不大(31.0% vs. 31.4%)。说明在$val_2$上的测试结果可以很好的代表其在测试集上的测试结果。
4.6.与OverFeat的关系(Relationship to OverFeat)
OverFeat可以看成是R-CNN的特例。但是OverFeat的检测速度比R-CNN快9倍,OverFeat平均检测一幅图像仅需2秒。快的原因主要是因为OverFeat使用了滑动窗口机制。加速R-CNN也是有可能的,这将是未来的工作之一。
5.语义分割(Semantic segmentation)
区域分类(region classification)是语义分割的一项标准技术,所以我们可以很容易的将R-CNN应用到PASCAL VOC的分割任务中。
6.结论(Conclusion)
最近几年,目标检测陷入停滞。本文提出了一种简单且易扩展的目标检测算法,将PASCAL VOC 2012的最好结果提升了30%。
7.Appendix
7.A.Object proposal transformations
R-CNN所用的CNN网络的输入大下为$227 \times 227$,但是region proposal的大小却是不固定的。因此需要将不同尺寸的region统一为$227 \times 227$。作者评估了两种转换方法。
第一种方法为:tightest square with context。将每个object proposal按照长边扩展为正方形(扩展部分用context填充),然后将其等比例缩放到$227 \times 227$大小作为CNN的输入(见Fig7的B列)。这种方法还有一种变体:tightest square without context,唯一的不同是填充的内容,该变体不用context进行填充,可以选择使用某一常数进行填充,例如Fig7的C列。第二种方法为:warp。直接各向异性的将每个object proposal缩放到CNN所需要的尺寸,见Fig7的D列。Fig7的A列为目标区域在原始图像中的真实大小。

此外,作者还考虑到了context的影响。对原始的object proposal进行扩展(基于原始图像),即padding,padding的值为p(即扩展的圈数)。Fig7中每个例子的第一行,p=0,即没有padding;第二行,p=16。如果proposal的范围延伸到了图像外面,则会用图像像素值的平均进行填充(在进入CNN之前会被减去)。实验表明,warp+padding(p=16)的方法是最优的。
7.B.Positive vs. negative examples and softmax
最初作者并没有设置fine-tune这一步,只是对CNN进行了预训练,然后训练SVM(在此阶段,确定了训练SVM最佳的正负样本定义)。后来加入了fine-tune这一步,并且在fine-tune CNN时使用了和训练SVM时一致的正负样本定义,但是结果并不理想,其性能比最终版本(使用了不同的正负样本定义)差了很多。
作者假设正负样本的定义并不重要,之所以将fine-tune CNN时的IoU阈值设为0.5,是因为如果不这样做,只将IoU=1的视为正样本,那么训练网络的正样本会大大减少,这样很容易造成过拟合。为了扩充正样本的数量,才把IoU的阈值设为了0.5。
那么为什么不直接用CNN网络输出最后的结果呢(加个softmax层)?这是因为fine-tune CNN网络时,正样本的定义是$IoU\geqslant 0.5$,并不是标准的ground-truth,这种不严格的正样本定义使得训练出来的CNN网络性能并不好。于是在后面加了个SVM,并只使用ground-truth作为正样本。
但是作者认为去掉SVM层而不影响性能也是有可能的,只是得对CNN网络进行进一步的微调。如果这个能实现的话,那将会大大简化R-CNN的结构并提升其训练速度。
7.C.Bounding-box regression
首先我们定义:
\[\{ (P^i,G^i) \}_{i=1,...,N}\]N为样本数。其中,
\[P^i = (P^i_x, P^i_y, P^i_w, P^i_h)\] \[G=(G_x,G_y,G_w,G_h)\]此处省略了上标i。$P^i$为region proposal的bounding box,$(x,y)$为bounding box的中心点坐标,w和h分别为bounding box的宽和高。而$G^i$为对应的ground truth。
$P^i$可以理解为维度为$m \times 4$的矩阵,m为归属于第i类的样本个数,4为x,y,w,h。
使用4个变换函数$d_x(P),d_y(P),d_w(P),d_h(P)$,通过下面四个公式计算预测的ground truth $\hat G$:
\[\hat{G} _x = P_w d_x(P) + P_x \tag{1}\] \[\hat{G} _y = P_h d_y(P) + P_y \tag{2}\] \[\hat{G} _w = P_w exp( d_w(P) ) \tag{3}\] \[\hat{G} _h = P_h exp( d_h(P) ) \tag{4}\]$\hat G$其实就是$P$通过平移缩放得到的。
平移我们可以表示为:
\[\hat G_x = P_x + \delta x\] \[\hat G_y = P_y + \delta y\]缩放我们可以表示为:
\[\hat G_w = P_w \cdot \delta w\] \[\hat G_h = P_h \cdot \delta h\]论文中对$\delta x,\delta y,\delta w,\delta h$定义如下:
\[\delta x = P_w d_x (P)\] \[\delta y = P_h d_y (P)\] \[\delta w = exp ( d_w (P) )\] \[\delta h = exp ( d_h (P) )\]带入即可得到式1~式4。
式1~式4中的$d_* (P)$($*$为$x,y,h,w$中的一个)为一个线性模型,自变量为CNN网络中POOL5层的输出,表示为$\phi_5(P)$。则$d_* (P)=w_* ^T \phi_5 (P)$。参数$w_*$的学习方法为岭回归(即改良的最小二乘估计,其实就是多加了个正则化项):
\[w_* = \arg \min \limits_{\hat{w}_*} \sum^N_{i} (t^i_* - \hat{w}_*^T\phi_5(P^i))^2 + \lambda \parallel \hat{w}_* \parallel ^2 \tag{5}\]其中,$t_*$的定义见下:
\[t_x = (G_x - P_x)/P_w \tag{6}\] \[t_y = (G_y - P_y)/P_h \tag{7}\] \[t_w = \log (G_w / P_w) \tag{8}\] \[t_h = \log (G_h / P_h) \tag{9}\]基于验证集,作者设$\lambda = 1000$。此外还需要关注的就是训练样本对$(P,G)$的挑选。如果P离G很远,依然通过回归用P预测G显然是不合理的。因此,我们只挑选和G的IoU大于0.6(基于验证集设置的该阈值)的P,如果P和多个G的IoU均大于0.6,则挑选最大IoU的G作为该P的ground truth。针对每一个类别,我们都训练一个bounding box回归模型。
在测试阶段,我们可以通过SVM预测每个proposal的所属类别,然后将该proposal丢进对应类别的bounding box回归模型中,得到预测的$\hat G$。这个过程也可以多次迭代,即将$\hat G$继续丢进该模型中,得到新的$\hat G$。但是作者发现迭代多次并不能提升结果,因此作者只执行了一次bounding box回归。
7.D.Additional feature visualizations
Fig12展示了POOL5层中20个神经元的可视化结果。针对每个神经元,展示了激活值最大的24个region proposal。Fig12中每个神经元可视化结果的上方都标注了该神经元的位置:$(y,x,channel)$。

8.原文链接
👽Rich feature hierarchies for accurate object detection and semantic segmentation
