本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
对于region-based的CNN目标检测模型来说(比如R-CNN),虽然SPPnet和Fast R-CNN已经显著降低了CNN部分的检测时间,但是其均没有考虑生成proposal带来的耗时。
相比Fast R-CNN优化后的CNN部分的检测时间,生成proposal的耗时会高出几个数量级。以Selective Search为例,其在CPU上针对每幅图像需要运行2秒。另一个生成proposal的方法:EdgeBoxes,每幅图像也需要0.2秒,这仍然是个不小的时间支出。
EdgeBoxes原文:C. L. Zitnick and P. Doll´ar, “Edge boxes: Locating object proposals from edges,” in European Conference on Computer Vision (ECCV), 2014.。
但是需要注意的是CNN部分是运行在GPU上的,而proposal的生成是运行在CPU上的,所以直接比较耗时并不公平。但即使把proposal的生成放在GPU上运行,虽然理论上可以提速,但是其和CNN部分仍然是孤立的,并不能共享计算,所以还是有进一步优化的余地。
因此,我们使用一个深度卷积网络来生成proposal,我们称该网络为Region Proposal Networks(RPNs)。RPNs会和CNN部分共享卷积层,这大大降低了生成proposal的耗时(每幅图像仅需10ms)。使用RPNs的原因在于我们发现卷积层的feature map也可以被用来生成proposal。
此外,为了使RPNs可以生成不同尺度和长宽比的proposal,我们提出了anchor box的概念,见Fig1。
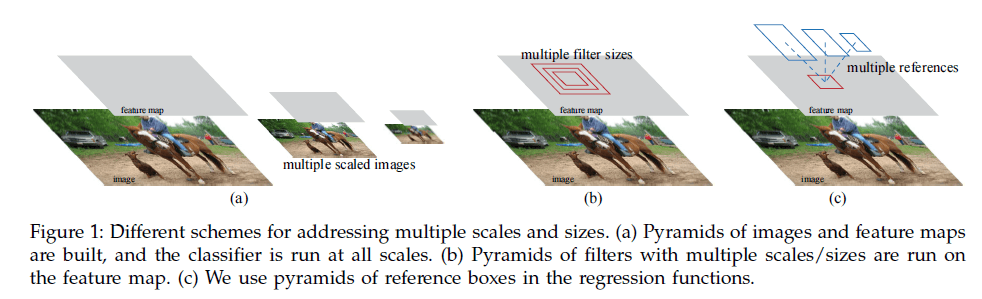
为了将RPNs(即region proposal task)和Fast R-CNN目标检测网络(即object detection task)相结合,我们提出了一种训练机制:交替fine-tune两个task,但是在fine-tune object detection task时,保持proposal不变。我们这种方法收敛很快。
后来作者还发现两个task可以联合训练从而进一步缩短训练时间。
在PASCAL VOC检测任务中,RPNs+Fast R-CNN的性能优于Selective Search+Fast R-CNN。即使CNN部分使用较深VGG Net,我们的方法在GPU上也可以达到5fps(所有步骤都算在内)。此外,我们也在COCO数据集上进行了测试。code是开源的,MATLAB代码地址:https://github.com/shaoqingren/faster_rcnn,Python代码地址:https://github.com/rbgirshick/py-faster-rcnn。
在论文正式发表之前,作者就发出了初稿,所以在论文正式发表时,RPN和Faster R-CNN已经被广泛用于目标检测、实例分割等多个领域。因为我们的方法不但速度快而且准确率高。
2.RELATED WORK
不再详述。
3.FASTER R-CNN
Faster R-CNN包含两个模块。第一个模块是用于生成proposal的深度全卷积网络,第二个模块是使用这些proposal的Fast R-CNN检测模型。如Fig2所示,Faster R-CNN是一个单一的模型(即不再需要把proposal的生成和检测任务分割开来):
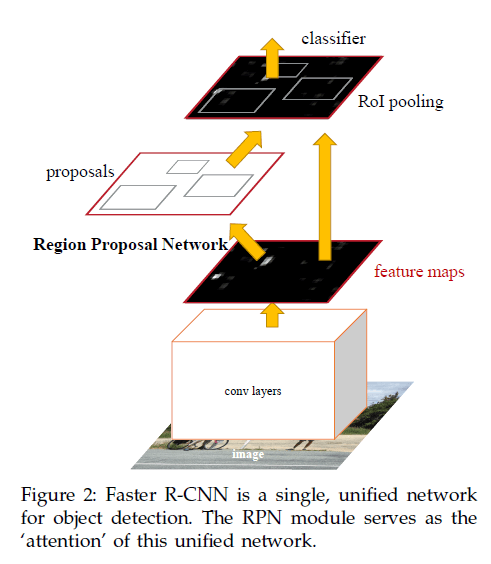
3.1.Region Proposal Networks
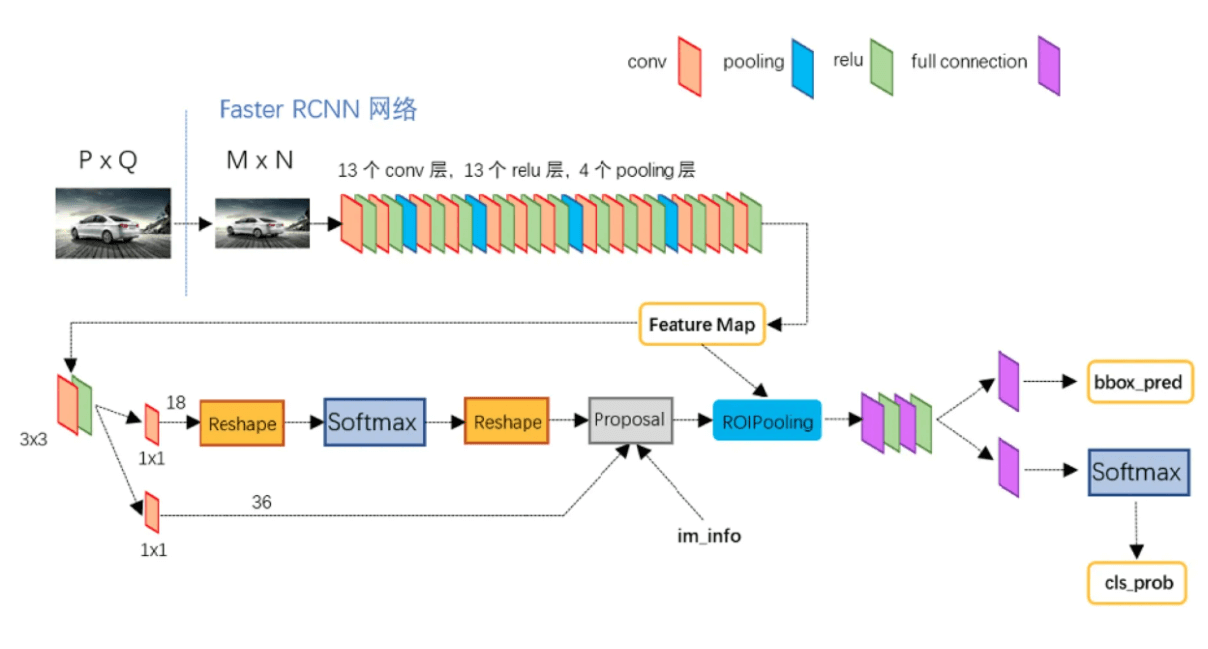
RPN的输入为任意大小的图像(或feature map),输出为一系列矩形object proposal,并且每个proposal都有一个评分(用于评价属于前景还是背景)。本文中,我们使用FCN作为RPN。因为我们最终目的是让RPN和Fast R-CNN目标检测网络可以共享计算,因此我们让其共享卷积层,如果是基于ZFNet,则可以共享5个卷积层;如果是基于VGG16,则可以共享13个卷积层。
我们利用滑动窗口的原理,以最后一个共享卷积层的feature map(假设大小为$f \times f$)为输入,在上面滑动一个$n\times n$大小的窗口,每个$n\times n$大小的窗口都得到一个低维的特征向量(对于ZFNet,得到一个256-d的特征向量;对于VGG16,得到一个512-d的特征向量,激活函数使用ReLU函数),又因为我们使用FCN作为RPN,所以对于ZFNet,我们可以得到一个$f \times f \times 256$的feature map;对于VGG16,我们可以得到一个$f\times f \times 512$的feature map。对于每一个256-d(或512-d)的特征向量,我们将其喂入两个并行的FC层(two sibling fully-connected layers):一个用于box回归(reg),一个用于对box进行二分类(cls,前景或背景)。本文中,我们使用$n=3$(对于ZFNet,其感受野为$171^2$;对于VGG16,其感受野为$228^2$)。单个滑动窗口的解释见Fig3左。
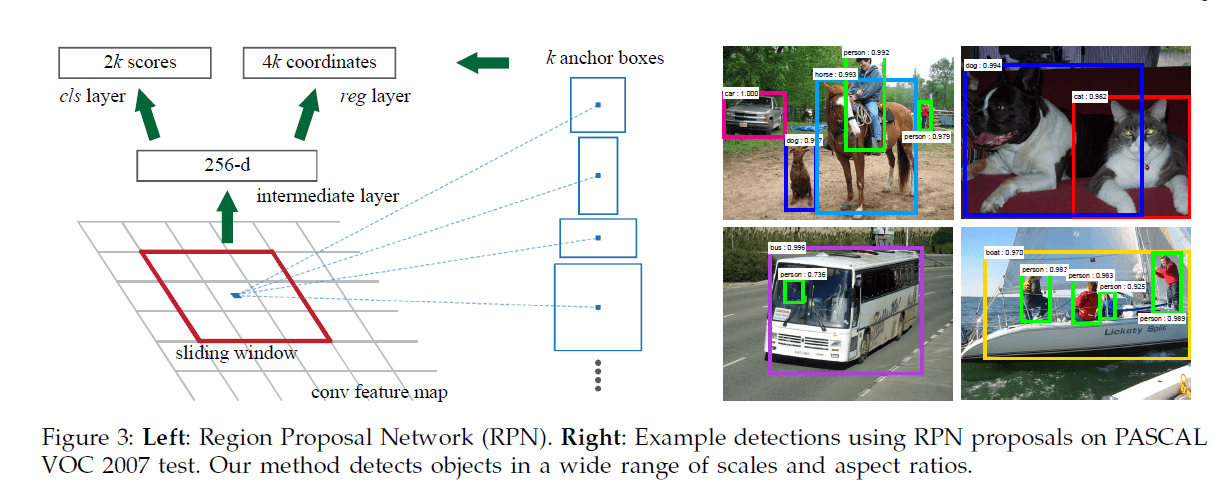
个人理解:作者的做法其实很简单,就是在最后一个共享卷积层后再接一个卷积层,卷积核大小为$3\times 3$,卷积核数量为256(ZFNet)或512(VGG16),padding方式为SAME,激活函数为ReLU,然后再接两个并行的$1\times 1$卷积层,其实就是全连接层。
个人理解:cls layer可以是并行的k个2分类输出;reg layer可以是并行的k个4个神经元的输出。
3.1.1.Anchors
针对每个滑动窗口,我们以窗口的中心为锚点设置k个不同面积(scale)和长宽比(aspect ratio)的anchor(每个anchor映射回原始图像都是一个region proposal),所以RPN的reg层有4k个输出(每个anchor都有4个偏移量),cls层有2k个输出(每个anchor都有分别属于前景或背景的概率)。在本文中,我们使用了3个不同面积搭配3种不同长宽比的anchor(即k=9),如Fig3所示。假设最后一个共享卷积层得到的feature map的大小为$W \times H$,那么一共可得到$WHk$个anchor。
👉Translation-Invariant Anchors
anchor机制具有平移不变性。平移不变性使得我们模型的size更小(即更少的参数数量),这同时也降低了过拟合的风险。
👉Multi-Scale Anchors as Regression References
作者和其他相关方法进行了比较,提出anchor机制是基于a pyramid of anchors,更加的cost-efficient。此外,multi-scale anchors使得我们使用single-scale image作为输入即可。
3.1.2.Loss Function
在训练RPNs时,将每个anchor分为前景(正样本)或背景(负样本)。正样本的划分遵循以下两个规则:1)和GT的IoU最大的anchor标记为正样本;2)和GT的IoU大于0.7的anchor被标记为正样本。在规则2的基础上又添加了规则1是因为有些情况下,对于某一GT box,没有任何一个anchor与之的IoU大于0.7。一个GT box可能会对应多个anchor。与GT的IoU低于0.3的anchor视为负样本。
我们将单张图像的loss function定义如下:
\[L( \{ p_i \},\{ t_i \})=\frac{1}{N_{cls}} \sum_i L_{cls} (p_i,p^*_i)+\lambda \frac{1}{N_{reg}} \sum_i p^*_i L_{reg} (t_i,t^*_i) \tag{1}\]$i$表示在一个mini-batch中第$i$个anchor的索引,$p_i$为第$i$个anchor属于前景的概率。$p_i^*$是GT,当第$i$个anchor为正样本时,$p_i^*=1$;为负样本时,$p_i^*=0$。$t_i$(预测值)和$t_i^*$(GT)为四个值的向量,定义和R-CNN一致:
\[\begin{split} t_x = (x-x_a)/w_a, \quad t_y=(y-y_a)/h_a, \\ t_w=\log(w/w_a), \quad t_h=\log(h/h_a), \\ t^*_x=(x^*-x_a)/w_a, \quad t^*_y=(y^*-y_a)/h_a, \\ t^*_w=\log(w^*/w_a), \quad t^*_h=\log(h^*/h_a), \end{split} \tag{2}\]式(2)中,$x,y,w,h$为预测得到的box的中心点坐标以及其宽和高,$x_a,y_a,w_a,h_a$为anchor box的中心点以及宽高,$x^*,y^*,w^*,h^*$为GT box的中心点以及宽高。
回到式(1),$L_{cls}$和$L_{reg}$的计算和Fast R-CNN一样。在我们自己的代码中,设$N_{cls}=\text{mini-batch size}$(即$N_{cls}=256$)。$N_{reg}$为最后一个共享feature map的大小,即锚点的个数:$N_{reg}=W*H$,我们的代码中该值约为2400。我们设$\lambda=10$,这样的话,$cls$项和$reg$项的权重差不多。我们后续实验表明结果对$\lambda$的取值并不敏感(见表9)。并且我们还发现normalization(即$N_{cls}$和$N_{reg}$)不是必要的,可以被简化。
在SPPnet和Fast R-CNN中,所有region proposal在经过spatial pyramid pooling layer后的bounding box回归计算使用的同一组权重。而我们的方法针对每一种类型的anchor都训练了一个单独的回归器,即共训练了$k$个不同的回归器,每个回归器只负责一种scale和aspect ratio的anchor。
3.1.3.Training RPNs
通过后向传播和mini-batch梯度下降法训练RPNs。一个mini-batch内只包含一张图象以及其对应的多个anchor正样本和负样本。因为负样本的数量过多,因此一张图我们只随机选择256个anchor,其中128个为正样本,128个为负样本。如果正样本的数量不足128个,则剩余的均用负样本。
使用高斯分布(均值为0,标准差为0.01)初始化RPNs中新添加的层,其余层(比如共享卷积层)则使用经ImageNet预训练过的权值进行初始化。如果公共卷积部分是基于ZFNet,则fine-tune ZFNet的所有层,如果是基于VGGNet,则只fine-tune conv3_1及以后的层(和Fast R-CNN一样的策略)。在PASCAL VOC数据集上,前60k个mini-batch使用0.001的学习率,后20k个mini-batch使用0.0001的学习率。momentum=0.9,weight decay=0.0005。使用Caffe框架。
3.2.Sharing Features for RPN and Fast R-CNN
检测网络部分我们使用Fast R-CNN,如Fig2所示。RPN和Fast R-CNN的训练是各自独立的。但它俩又存在共享卷积层,所以我们探讨了三种方式来训练这些共享卷积层:
👉(i)Alternating training.
先训练RPN,然后用其产生的proposal来训练Fast R-CNN。被Fast R-CNN fine-tune过的网络权值可以用来对RPN进行初始化,然后再次训练RPN,整个过程就这样一直迭代。这也是本文所有实验所用的方法。
👉(ii)Approximate joint training.
这个方法在训练时将RPN和Fast R-CNN视为一个整体。在每次MBGD的迭代中,先用RPN生成proposal,然后用这些proposal去训练Fast R-CNN。loss为RPN loss和Fast R-CNN loss的结合。在我们的实验中,这个方法的结果接近Alternating training,并且相比Alternating training,其训练时间减少了25%-50%。在我们released Python code里用的是这种方法。
👉(iii)Non-approximate joint training.
Faster R-CNN并没有使用这种方法,不再赘述。
👉4-Step Alternating Training.
在本文中,我们使用4步训练法:
- 按照第3.1.3部分训练RPN。使用ImageNet-pre-trained的模型来初始化RPN。
- 使用第1步生成的proposal,开始单独训练Fast R-CNN。同样的,也使用ImageNet-pre-trained的模型来初始化Fast R-CNN。此时,RPN和Fast R-CNN还未开始共享卷积层。
- 使用Fast R-CNN初始化RPN,然后固定需要共享的卷积层,fine-tune只属于RPN的层。此时,RPN和Fast R-CNN就开始了共享卷积层。
- 最后,依旧固定共享的卷积层,fine-tune只属于Fast R-CNN的层。
个人理解:RPN和Fast R-CNN在训练时各自使用各自的loss function。
虽然这个交替训练的过程可以迭代多次,但是我们发现多次迭代并没有显著的提升模型性能。
3.3.Implementation Details
我们都是在single scale上训练和测试的RPN和Fast R-CNN。我们将图像的短边re-scale到$s=600$个像素。虽然多尺度特征提取(multi-scale feature extraction),比如image pyramid,可能能提升准确率,但是不能对速度和准确率做一个很好的trade-off。ZFNet和VGGNet最后一个卷积层的一步都相当于是在re-scale后图像上的16个像素,也就是PASCAL原始图像(大小约为$500 \times 375$)上的大约10个像素。尽管步长如此之大,但结果还是很不错,虽然更小的步长可能会进一步的提高准确率。
对于anchor,我们使用了三种scale(即box面积):$128^2,256^2,512^2$;三种长宽比:$1:1,1:2,2:1$。这些超参数并不是根据某些数据集精心设计的。我们没有使用多尺度,这节省了大量时间。Fig3(右)展示了使用不同scale和长宽比的效果。表1展示了基于ZFNet,每个anchor学到的proposal的平均大小。并且,如果只有物体的中间部分是可见的,算法仍然可以粗略推断出物体的范围。
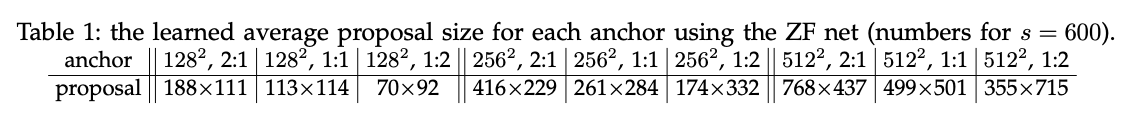
在训练阶段,对于超过图像边界的anchor,我们会选择忽视。对于一张$1000 \times 600$的图像,大约会有20000个($\approx 60 \times 40 \times 9$)anchor。忽略掉超过图像边界的anchor后,在训练时每张图像大概还剩6000个anchor。如果不忽略这些跨越图像边界的anchor,会引入难以纠正的误差并导致训练不会收敛。在测试阶段,我们仍然对整幅图像应用全卷积RPN。在测试阶段生成的跨越图像边界的anchor,我们会将其裁剪至图像边界。
RPN产生的一些proposal重合度很高。我们根据cls分数进行NMS,IoU的阈值设为0.7,这样的话每幅图像差不多能剩2000个左右的proposal。NMS不但大量减少了proposal的数量,并且还没有损害最终的检测准确率。在NMS之后,我们选择排名前$N$的proposal进行检测(个人理解:按照cls分数进行排名)。在训练阶段,我们使用2000个由RPN生成的proposal来训练Fast R-CNN,在测试阶段,我们评估了使用不同数量的proposal。
4.EXPERIMENTS
4.1.Experiments on PASCAL VOC
我们在PASCAL VOC 2007 detection benchmark上评估了我们的方法。这个数据集包含五千张trainval图像,五千张测试图像,超过20个类别。同时我们也在PASCAL VOC 2012 benchmark上评估了一些模型。对于经过ImageNet预训练的网络,我们使用ZF net的“fast version”:5个卷积层+3个全连接层;以及VGG16(www.robots.ox.ac.uk/∼vgg/research/very deep/):13个卷积层+3个全连接层。我们使用的评估指标为mAP。
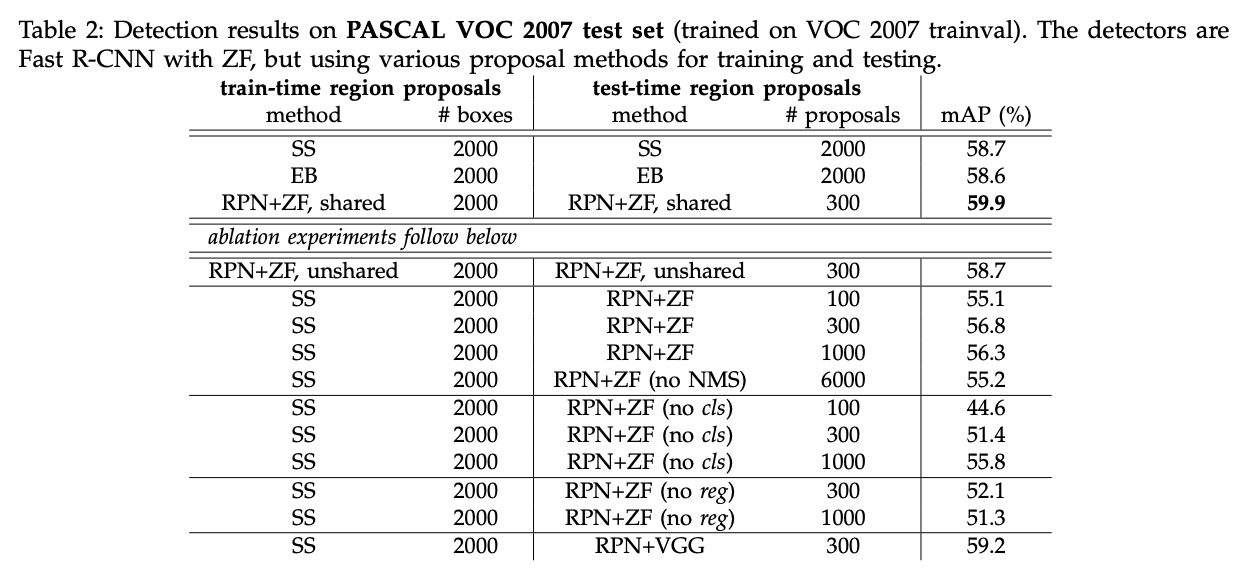
表2(顶部)展示了训练和测试时使用各种生成proposal方法的结果。这几个结果都是基于ZFNet。“RPN+ZF,shared”在测试阶段每幅图像最多使用了300个proposal,其实在NMS之后,RPN生成的proposal可能都不足300个,所以平均下来,每幅图像使用的proposal数量比300还要少。“RPN+ZF,shared”的mAP最高,并且速度也更快。更少的proposal也降低了region-wise的全连接层的cost(见表5)。
个人理解:region-wise指的是对每个proposal都需要进行计算,是以region为单位的。
👉Ablation Experiments on RPN.
我们针对RPN做了一些消融研究。首先,我们实验了共享卷积层。通过只执行4步训练法的前2步来取消共享卷积层。取消共享卷积层的结果见表2中的“RPN+ZF,unshared”。因此,共享卷积层的使用提升了模型性能。
接下来我们分析了RPN对训练Fast R-CNN的影响。为了这个目的,我们使用由SS生成的2000个proposal来训练Fast R-CNN。在测试阶段,我们固定detector,尝试使用不同数量的proposal。在这一系列的消融实验中,RPN和detector不共享特征。
SS+300个RPN proposal得到了最高的mAP,为56.8%。mAP的降低是因为训练和测试阶段的proposal方法不一样。该结果作为以下比较的baseline。
令人惊讶的是,SS+100个RPN proposal也取得了不错的结果(mAP=55.1%),这说明RPN生成的前100个proposal还是比较准确的。另外一个极端的现象是,SS+6000个RPN proposal(without NMS)也得到了差不多的结果(mAP=55.2%),说明NMS的应用并不会对模型性能产生损害。
接下来,我们通过在测试阶段分别关闭RPN的cls或reg输出来研究它们的作用。当在测试阶段移除cls layer时(此时就无法根据cls分数使用NMS以及对proposal进行排名),我们随机抽选$N$个proposal。当$N=1000$时,mAP变化不大(mAP=55.8%),但是当$N=100$时,mAP下降的比较严重(mAP=44.6%)。这进一步印证了通过cls分数得到的排名靠前的proposal的准确性。
另一方面,如果在测试阶段移除reg layer时,mAP下降到52.1%。这说明box回归有利于产生高质量的proposal。虽然anchor有不同的scale和长宽比,但是还是不够精确(仍需要reg layer进行纠正)。
此外,我们还评估了使用更强大的网络对RPN的影响。我们使用VGG16训练RPN,但是detector仍然使用SS+ZF。mAP从56.8%(RPN+ZF)提升到59.2%(RPN+VGG)。这说明RPN+VGG产生的proposal质量要优于RPN+ZF。因为方案“RPN+ZF,unshared”和方案“SS”取得了一样的结果mAP=58.7%,所以我们推测方案“RPN+VGG”可以取得比方案SS更好的结果(方案应用于训练和测试阶段)。我们用接下来的实验来印证我们的这一推测。
👉Performance of VGG-16.
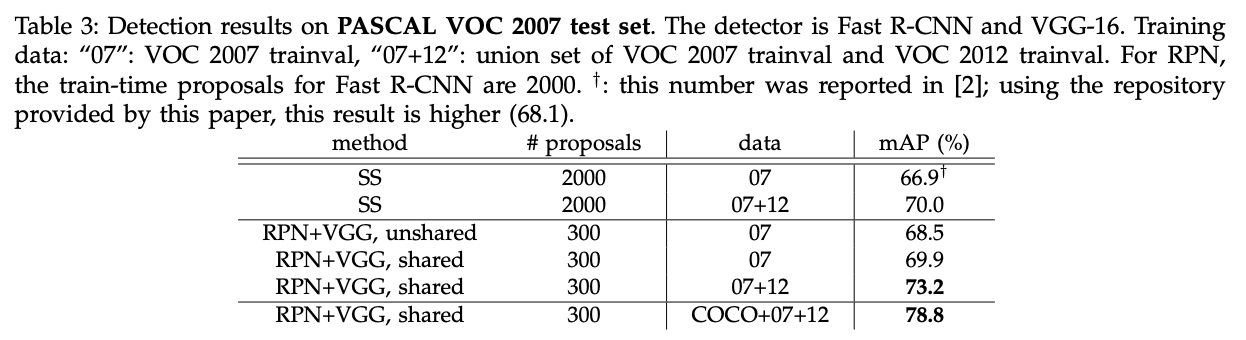
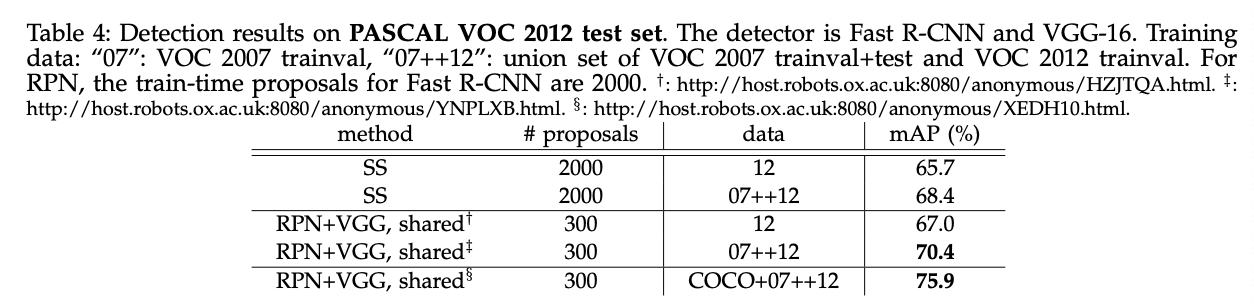
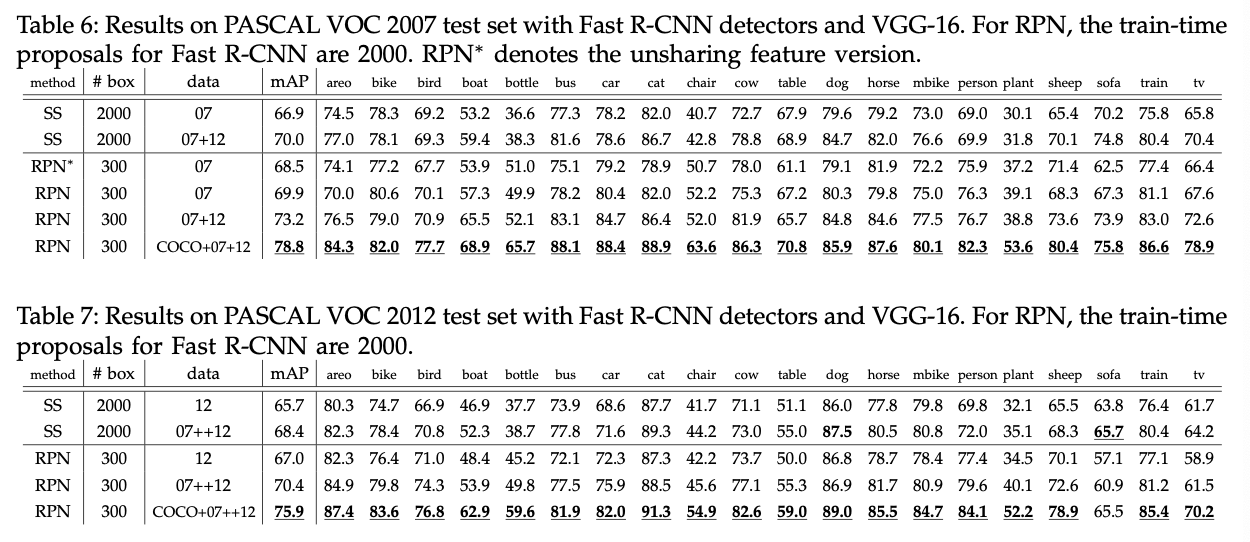
表3展示了VGG应用于生成proposal和detector的结果。“RPN+VGG,unshared”的结果略优于SS(68.5% vs. 66.9%)。如上所述,这是因为RPN+VGG生成的proposal的质量要优于SS。不同于SS,RPN能从网络中获得更好的收益。如果添加共享机制,mAP提升到69.9%。进一步的,我们在PASCAL VOC 2007 trainval和2012 trainval的联合数据集上训练了RPN和detection network,mAP达到了73.2%。Fig5展示了在PASCAL VOC 2007上的一些结果。在PASCAL VOC 2012测试集上(见表4),我们的方法达到了70.4%的mAP。表6和表7展示了一些详细的数值。


在表5中,我们总结了整个目标检测模型的运行时间。SS通常需要1-2秒来产生proposal(平均约1.5秒),基于VGG的Fast R-CNN需要320ms(146ms+174ms)来对SS产生的2000个proposal进行预测(如果对FC层使用SVD,则需要223ms)。而我们的方法,产生proposal+检测总共才198ms。因为有共享的卷积层,所以RPN只需要10ms来计算额外的层。我们的region-wise时间也比较短,因为我们使用了更少的proposal。如果使用ZF,我们的方法可以达到17fps。
👉Sensitivities to Hyper-parameters.
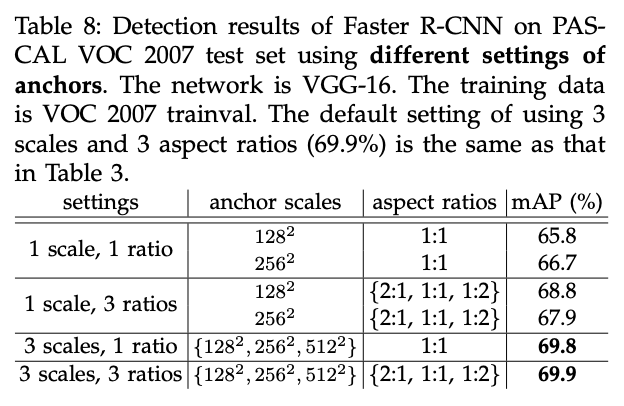
在表8中,我们探讨了不同配置的anchor。默认设置为3种scale搭配3种长宽比,mAP为69.9%。如果只使用1种scale搭配1种长宽比,则mAP下降3-4%。如果使用“1 scale,3 ratios”或“3 scales,1 ratio”,mAP会高很多,说明不同尺度的anchor是很有用的。“3 scales,1 ratio”取得了和“3 scales,3 ratios”差不多的mAP,看起来维度ratio并不那么重要。但是在实际应用中,我们还是使用了“3 scales,3 ratios”。

在表9中,我们评估了公式(1)中不同的$\lambda$值。当$\lambda$在两个数量级之间(1~100)波动时,我们的结果只受到了轻微影响(约1%)。说明我们的结果对$\lambda$的取值并不是特别的敏感。
👉Analysis of Recall-to-IoU.
接下来,我们分析了和GT有着不同IoU的proposal的recall。需要注意的是Recall-to-IoU指标和最终的检测准确率关系不大。我们使用这个指标不是为了评估proposal,而是为了判断proposal方法。
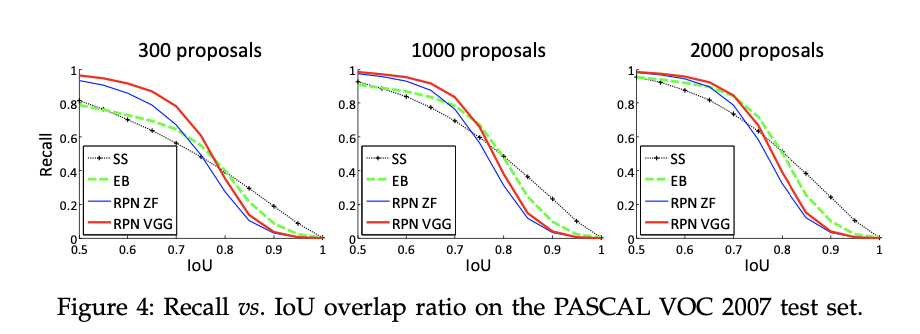
在Fig4中,我们展示了300、1000、2000个proposal的结果。我们对SS和EB进行了比较,都是选取了置信度排名前$N$的proposal。Fig4显示,当proposal的数量从2000降到300时,RPN方法表现良好。这也解释了为什么RPN使用300个proposal就可以取得很好的结果。正如我们之前分析的,这主要归功于RPN的cls项。当proposal的数量较少时,SS和EB的recall下降的比RPN更快。
👉One-Stage Detection vs. Two-Stage Proposal + Detection.

OverFeat属于one-stage,我们的方法属于是two-stage cascade。二者的比较结果见表10。我们的方法相比OverFeat,mAP提升了4.8%,达到了58.7%。并且,因为One-Stage使用了更多的proposal,所以速度也没Two-Stage快。
4.2.Experiments on MS COCO
我们也在Microsoft COCO目标检测数据集上进行了实验。该数据集包含80个目标类别。训练集有80k张图像,验证集有40k张图像,测试集(test-dev set)有20k张图像。评价指标使用mAP@[0.5:0.05:0.95](COCO数据集的标准指标,可简写为mAP@[.5,.95])和mAP@0.5(PASCAL VOC所用的指标)。
个人理解:通常我们将和GT的IoU超过0.5的bounding box视为预测正确,否则视为预测错误,此时计算的mAP记为mAP@0.5。而mAP@[0.5:0.05:0.95]指的是计算IoU阈值分别为[0.5,0.55,0.6,0.65,…,0.9,0.95](即0.5为最小值,0.05为步长,0.95为最大值)时的mAP的均值。
针对这个数据集,我们的模型并没有做太多的改变。我们在8块GPU上进行训练。RPN step和Fast R-CNN step(即4步训练法的第1步和第2步)都是先用0.003的学习率训练240k次迭代,然后用0.0003的学习率再训练80k次迭代。anchor方面,我们使用了3种ratios和4种scales(添加了$64^2$),以便更好的应对数据集中的小目标。此外,在我们训练Fast R-CNN时,我们将和GT的IoU在$[0,0.5)$区间的定义为负样本(SPP net和Fast R-CNN原文使用的区间为$[0.1,0.5)$)。
剩余的细节和PASCAL VOC中的一样。在测试阶段,我们仍旧使用300个proposal以及single-scale($s=600$)。在COCO数据集上,每张图像的检测耗时大约也为200ms。
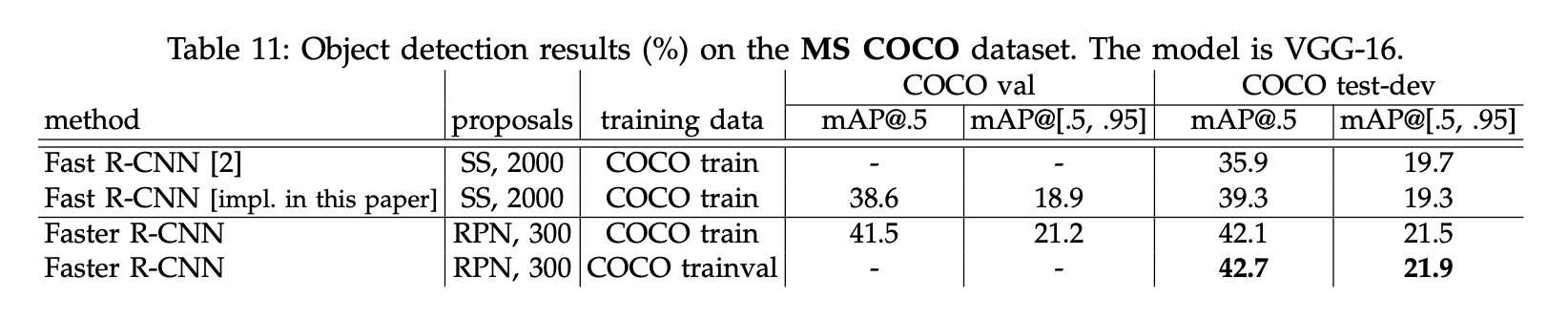
结果见表11。我们微调后的Fast R-CNN比原版的mAP@.5更高(39.3% vs. 35.9%)。我们分析提升的原因在于两点:1)负样本定义的修改;2)mini-batch size的修改。二者的mAP@[.5,.95]也差不多(19.3% vs. 19.7%)。
接下来我们评估了Faster R-CNN。使用COCO训练集进行训练,Faster R-CNN在COCO test-dev数据集上的mAP@0.5为42.1%,mAP@[.5,.95]为21.5%。相比Fast R-CNN,mAP@0.5提升了2.8%,mAP@[.5,.95]提升了2.2%(见表11)。这说明了RPN的优越性。如果使用COCO trainval数据集训练Faster R-CNN,则其在COCO test-dev数据集上的mAP@0.5为42.7%,mAP@[.5,.95]为21.9%。Fig6展示了在MS COCO test-dev数据集上的部分结果。

👉Faster R-CNN in ILSVRC & COCO 2015 competitions
如果将VGG16替换为ResNet-101,Faster R-CNN在COCO val数据集上的mAP从41.5%/21.2%提升至48.4%/27.2%。
4.3.From MS COCO to PASCAL VOC
大规模数据对于改进深层神经网络至关重要。接下来,我们研究了使用MS COCO数据集来提升模型在PASCAL VOC数据集上的表现。
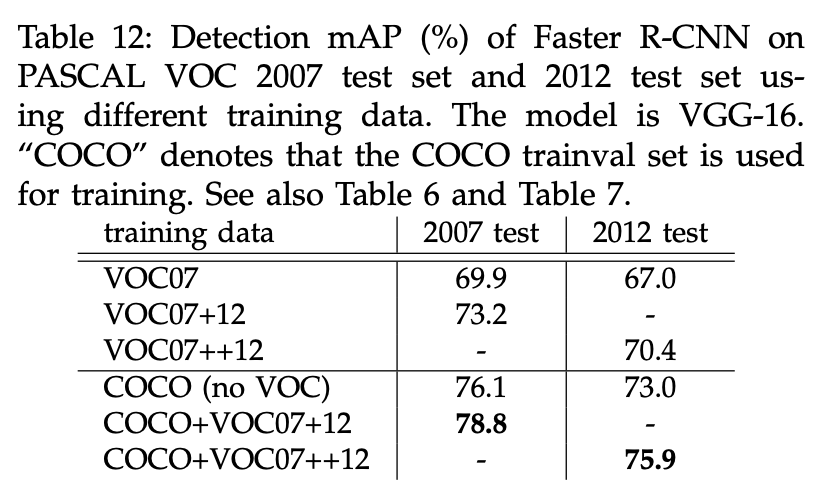
我们直接拿在COCO数据集上训练好的模型来检测PASCAL VOC数据集,不做任何fine-tune,其检测结果作为baseline。baseline在VOC07上的mAP为76.1%(见表12)。这甚至比专门在VOC07+12数据集上训练的模型的效果还要好(73.2% vs. 76.1%)。
接下来我们使用VOC数据集fine-tune了仅在COCO数据集上训练好的模型。在训练4步法(见第3.2部分)的第2步,使用经过COCO预训练的模型来初始化Fast R-CNN。在PASCAL VOC 2007测试集上的mAP为78.8%。COCO数据集的加入使得mAP提升了5.6%(73.2% vs. 78.8%)。从表6中可以看出,经过COCO+VOC训练的模型,在PASCAL VOC 2007的各个类别上得到的AP都是最高的。类似的结果也可以在PASCAL VOC 2012测试集上得到(见表12和表7)。并且得到这些优秀的结果,我们的模型的测试速度仍旧保持在每幅图像200ms左右。
5.CONCLUSION
我们证明了RPN是一种有效且准确的生成proposal的方法。通过与检测网络共享卷积层使得RPN的计算几乎没有成本。我们的方法基本可以满足实时性。
6.原文链接
👽Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
