本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.距离变换
1.1.原理介绍
距离变换于1966年被学者首次提出,目前已被广泛应用于图像分析、计算机视觉、模式识别等领域,人们利用它来实现目标细化、骨架提取、形状插值及匹配、粘连物体的分离等。距离变换是针对二值图像的一种变换,是计算并标识空间点(对目标点)距离的过程,它最终把二值图像变换为灰度图像(其中每个栅格的灰度值等于它到最近目标点的距离)。在二维空间中,一幅二值图像可以认为仅仅包含目标和背景两种像素,目标的像素值为1,背景的像素值为0。距离变换的结果不是另一幅二值图像,而是一幅灰度级图像,即距离图像,图像中每个像素的灰度值为该像素与距其最近的背景像素间的距离。
1.2.cv::distanceTransform
cv::distanceTransform用于计算二值图像中,每个像素点到最近的0像素点的距离。显然,0像素点的距离为0。
当maskSize=DIST_MASK_PRECISE且distanceType=DIST_L2时,算法引自论文:Pedro Felzenszwalb and Daniel Huttenlocher. Distance transforms of sampled functions. Technical report, Cornell University, 2004.。其他情况,算法引自论文:Gunilla Borgefors. Distance transformations in digital images. Computer vision, graphics, and image processing, 34(3):344–371, 1986.。
1
2
3
4
5
6
7
void distanceTransform(
InputArray src,
OutputArray dst,
int distanceType,
int maskSize,
int dstType=CV_32F
);
参数详解:
InputArray src:输入图像,必须为8bit单通道的二值图像。OutputArray dst:输出距离图像(即像素值代表距离)。8bit整型或32bit浮点型单通道图像。和输入图像的大小一致。-
int distanceType:距离的计算方式。有以下几种:1 2 3 4 5 6 7 8 9 10
enum DistanceTypes { DIST_USER = -1, //!< User defined distance DIST_L1 = 1, //!< distance = |x1-x2| + |y1-y2| DIST_L2 = 2, //!< the simple euclidean distance DIST_C = 3, //!< distance = max(|x1-x2|,|y1-y2|) DIST_L12 = 4, //!< L1-L2 metric: distance = 2(sqrt(1+x*x/2) - 1)) DIST_FAIR = 5, //!< distance = c^2(|x|/c-log(1+|x|/c)), c = 1.3998 DIST_WELSCH = 6, //!< distance = c^2/2(1-exp(-(x/c)^2)), c = 2.9846 DIST_HUBER = 7 //!< distance = |x|<c ? x^2/2 : c(|x|-c/2), c=1.345 };
-
int maskSize:掩码矩阵的大小。1 2 3 4 5
enum DistanceTransformMasks { DIST_MASK_3 = 3, //!< mask=3 DIST_MASK_5 = 5, //!< mask=5 DIST_MASK_PRECISE = 0 //!< };
int dstType:输出图像的类型,可以是CV_8U或CV_32F。注意:只有使用DIST_L1时,输出图像的类型才能是CV_8U。
⚠️当该函数使用DIST_L1或DIST_C时,只能搭配DIST_MASK_3,因为使用$3\times 3$和使用$5 \times 5$,甚至使用更大的mask,得到的结果是一样的。
另一种重载形式:
1
2
3
4
5
6
7
8
void distanceTransform(
InputArray src,
OutputArray dst,
OutputArray labels,
int distanceType,
int maskSize,
int labelType = DIST_LABEL_CCOMP
);
有两个新的参数:
OutputArray labels:输出的Voronoi图。大小和src一样,类型为CV_32SC1。-
int labelType:DIST_LABEL_CCOMP将相连的0像素(或非0像素)标记为同一label。DIST_LABEL_PIXEL将每个0像素(或非0像素)分配自己的label。1 2 3 4 5 6 7
enum DistanceTransformLabelTypes { /** each connected component of zeros in src (as well as all the non-zero pixels closest to the connected component) will be assigned the same label */ DIST_LABEL_CCOMP = 0, /** each zero pixel (and all the non-zero pixels closest to it) gets its own label. */ DIST_LABEL_PIXEL = 1 };
⚠️该重载函数不支持DIST_MASK_PRECISE。并且当使用DIST_L1或DIST_C时,也只能搭配DIST_MASK_3。
👉Voronoi图:分割为多个cell,每个cell内都只有一个site,且这个cell内任意一点到这个site的距离都小于其到其他site的距离。cell的划分是通过将每个site与其他所有site都做连线的垂直平分线完成的(即只保留距离该site最近的垂直平分线部分)。
![]()
如上图所示,基于不同的距离计算方式,我们可以得到不同的Voronoi图。
2.分水岭算法
2.1.算法简介
👉Geodesic Distance:
在图论中,Geodesic Distance就是图中两节点的最短路径的距离,这与平时在几何空间中通常用到的Euclidean Distance(欧氏距离),即两点之间的最短距离有所区别。
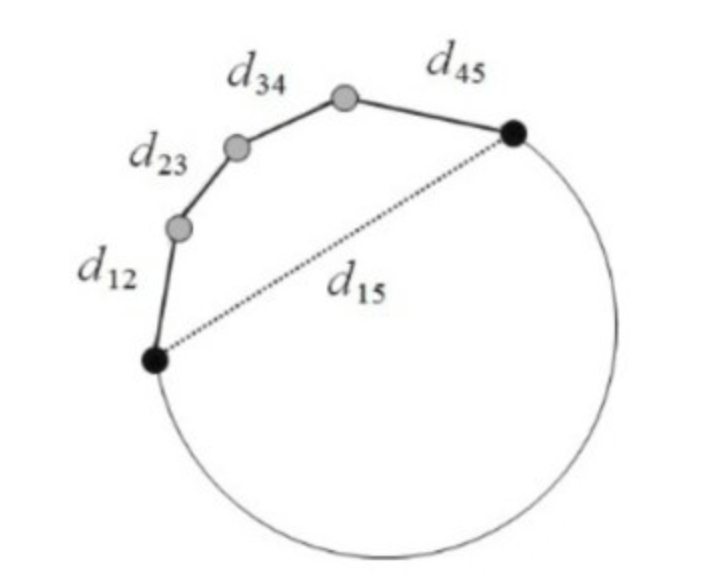
在上图中,两个黑点的欧式距离是用虚线表示的$d_{15}$,而Geodesic Distance作为实际路径的最短距离,其距离应为沿途实线段距离之和的最小值,即$d_{12}+d_{23}+d_{34}+d_{45}$。在三维曲面空间中,两点间的Geodesic Distance就是两点间沿着三维曲面的表面走的最短路径。
👉分水岭算法:
图像的灰度空间很像地球表面的整个地理结构,每个像素的灰度值代表高度。其中灰度值较大的像素连成的线可以看做山脊,也就是分水岭。其中的水就是用于二值化的gray threshold level,二值化阈值可以理解为水平面,比水平面低的区域会被淹没,刚开始用水填充每个孤立的山谷(局部最小值)。
当水平面上升到一定高度时,水就会溢出当前山谷,可以通过在分水岭上修大坝,从而避免两个山谷的水汇集,这样图像就被分成两个像素集,一个是被水淹没的山谷像素集,一个是分水岭线像素集。最终这些大坝形成的线就对整个图像进行了分区,实现对图像的分割。
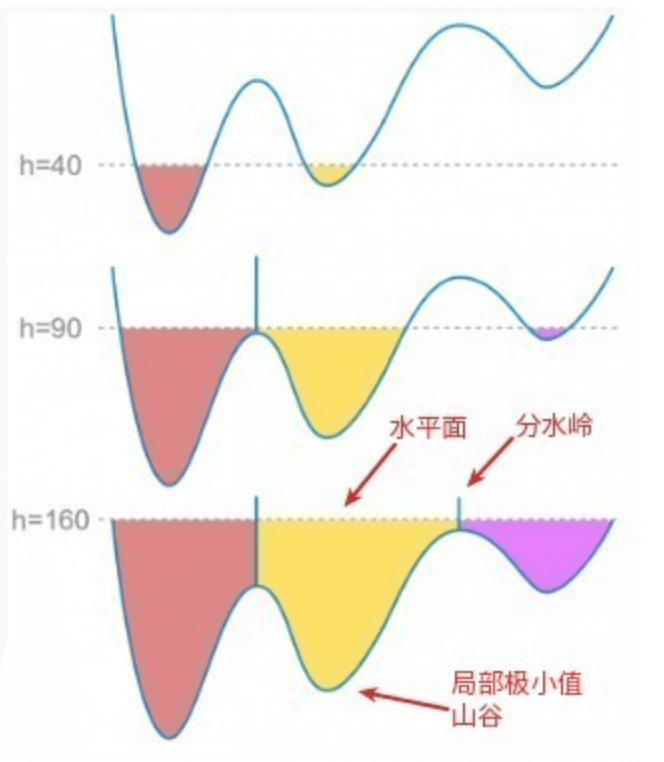
在该算法中,空间上相邻并且灰度值相近的像素被划分为一个区域。
分水岭算法的整个过程:
- 把梯度图像中的所有像素按照灰度值进行分类,并设定一个Geodesic Distance阈值。
- 找到灰度值最小的像素点(默认标记为灰度值最低点),让阈值从最小值开始增长,这些点为起始点。
- 水平面在增长的过程中,会碰到周围的邻域像素,测量这些像素到起始点(灰度值最低点)的Geodesic Distance,如果小于设定阈值,则将这些像素淹没,否则在这些像素上设置大坝,这样就对这些邻域像素进行了分类。
- 随着水平面越来越高,会设置更多更高的大坝,直到灰度值的最大值,所有区域都在分水岭线上相遇,这些大坝就对整个图像像素进行了分区。
用上述算法流程对图像进行分水岭运算,由于噪声点或其它因素的干扰,可能会得到密密麻麻的小区域,即图像被分得太细(over-segmented,过度分割),这因为图像中有非常多的局部极小值点,每个点都会自成一个小区域。
其中的解决方法:
- 对图像进行高斯平滑操作,抹除很多小的最小值,这些小分区就会合并。
- 不从最小值开始增长,可以将相对较高的灰度值像素作为起始点(需要用户手动标记),从标记处开始进行淹没,则很多小区域都会被合并为一个区域,这被称为基于图像标记(mark)的分水岭算法。这也是
cv::watershed所使用的方法。
2.2.cv::watershed
该算法引自论文:Meyer, F.Color Image Segmentation, ICIP92,1992.。
1
2
3
4
void watershed(
InputArray image,
InputOutputArray markers
);
参数详解:
InputArray image:输入8bit3通道图像。InputOutputArray markers:既用来输入也用来输出,为32bit单通道marker map。和输入图像image的大小一样。输入的marker map用来给不同区域贴上不同的标签:用大于1的整数表示我们确定为前景的区域;用1表示我们确定为背景的区域;用0表示我们无法确定的区域。输出的marker map为分水岭算法的结果,边界像素被标记为-1。
3.图像分割步骤
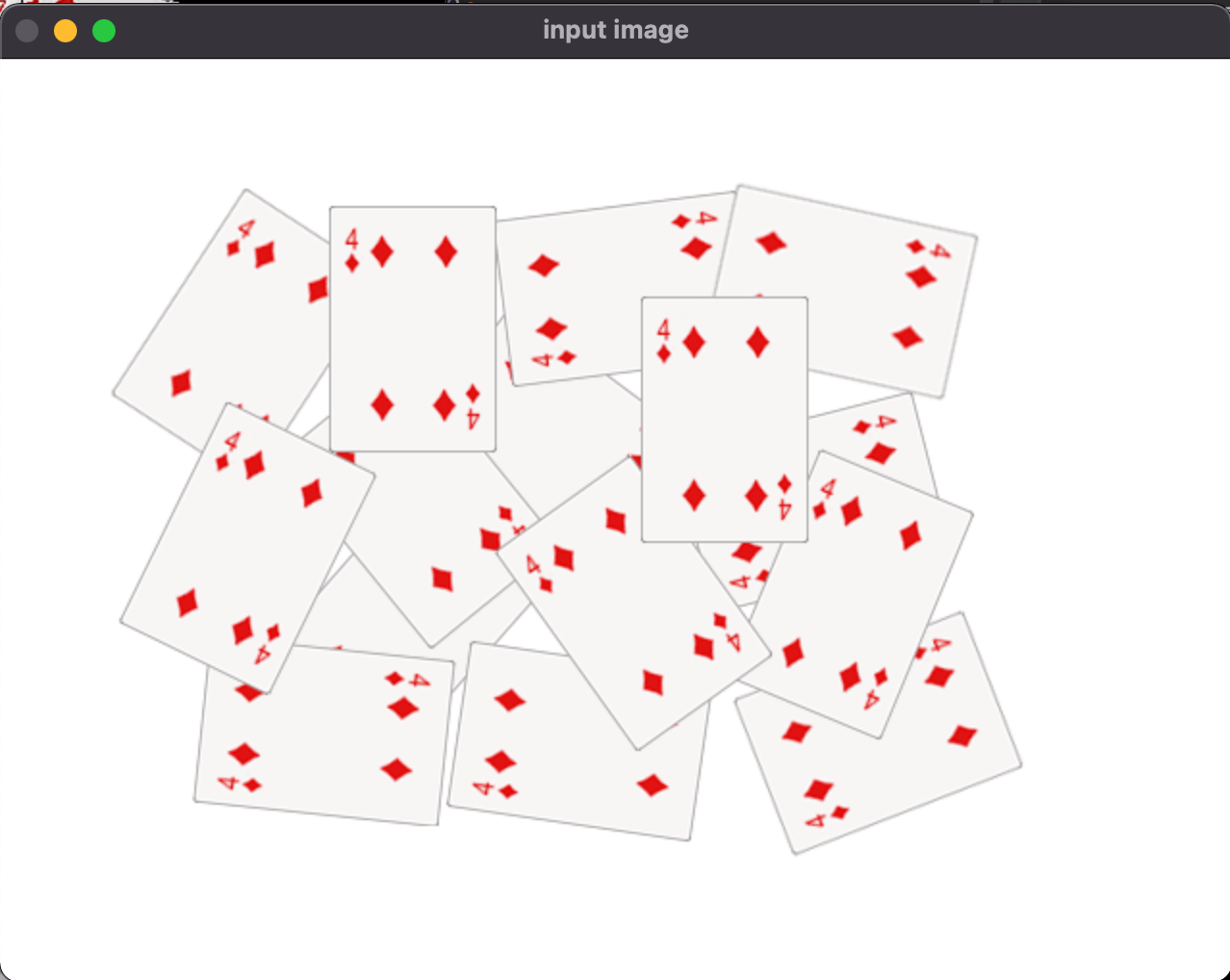
👉1.读入原始图像:
👉2.将背景置为黑色:

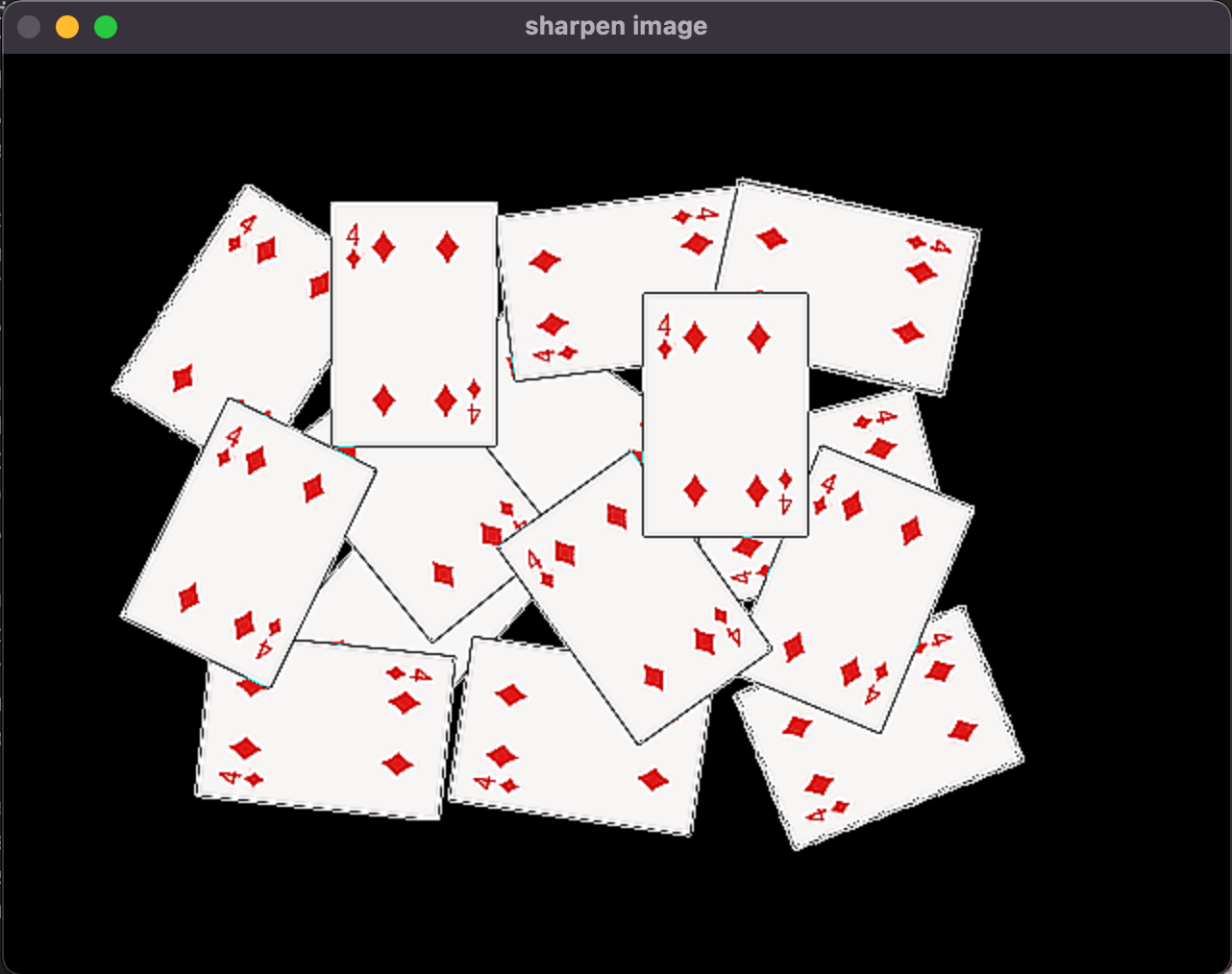
👉3.使用Laplace算子锐化图像:
👉4.图像二值化:

👉5.距离变换并归一化:

👉6.对第5步得到的结果进一步进行二值化(假设阈值设为0.4),然后进行膨胀操作(这些处理都是为了准备cv::watershed所要用的markers):

👉7.使用cv::findContours和cv::drawContours将上图白色块内的像素值标记为大于1的整数,即cv::watershed所要用的markers:
![]()
👉8.运行分水岭算法,输出的marker map:
![]()
👉9.绘制最终分割结果:
![]()
4.cv::imshow
对于cv::imshow函数:
- 如果图像数据类型是
8U,则直接显示。 - 如果图像数据类型是
16U或32S,则cv::imshow函数会将每个像素值除以256,然后再显示。 - 如果图像数据类型是
32F或64F,则cv::imshow函数会将每个像素值乘以256,然后再显示。
5.cv::inRange
cv::inRange用于检查src中的元素值是否在lowerb和upperb之间。
👉对于单通道图像:
\[\texttt{dst} (I)= \texttt{lowerb} (I)_0 \leq \texttt{src} (I)_0 \leq \texttt{upperb} (I)_0\]👉对于双通道图像:
\[\texttt{dst} (I)= \texttt{lowerb} (I)_0 \leq \texttt{src} (I)_0 \leq \texttt{upperb} (I)_0 \land \texttt{lowerb} (I)_1 \leq \texttt{src} (I)_1 \leq \texttt{upperb} (I)_1\]更多通道的图像以此类推。如果$\texttt{src} (I)$在范围之内(每个通道都在范围之内),则$\texttt{dst} (I)$为255(即所有比特位上都是1;如果是三通道,就是$\{255,255,255 \}$);否则,$\texttt{dst} (I)$为0(即所有比特位上都是0;如果是三通道,就是$\{0,0,0 \}$)。因此,cv::inRange可用来做图像二值化操作。
1
2
3
4
5
6
void inRange(
InputArray src,
InputArray lowerb,
InputArray upperb,
OutputArray dst
);
