本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
深度卷积神经网络(Deep Convolutional Neural Networks,DCNNs)已经在计算机视觉领域内多种任务类型中达到了SOTA的结果,比如图像分类,目标检测,语义分割,人体姿态估计等。相比传统人工设计的representation,DCNNs的优势在于可以学到更丰富的representation。
最近研发的一些分类网络,包括AlexNet,VGGNet,GoogleNet,ResNet等,都遵循了LeNet-5的设计规则。该规则如Fig1(a)所示:逐渐减小feature map的空间大小,最后产生低分辨率的representation,并对其进行进一步的处理以执行分类任务。
而对位置比较敏感的任务通常需要高分辨率的representation,比如语义分割,人体姿态估计和目标检测等。如Fig1(b)所示,现有的技术通常采用将分类网络或类分类网络输出的低分辨率representation逐步恢复成高分辨率的策略,比如Hourglass,SegNet,DeconvNet,U-Net,SimpleBaseline以及编码-解码方法等。并且,dilated convolutions(空洞卷积,扩张卷积,膨胀卷积)被用来移除一些下采样层,从而产生中等分辨率的representation。

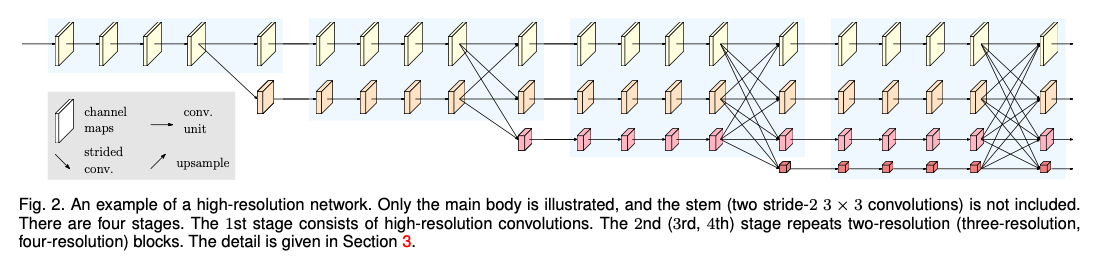
我们提出一种新的框架,即High-Resolution Net(HRNet),可以全程保持高分辨率的representation。我们从一个高分辨率的卷积流开始,一个接一个的添加从高分辨率降到低分辨率的卷积流,最后将并行的不同分辨率的流连接起来。最终的网络结构包括多个stage(本文为4个stage),第$n$个stage会包含$n$个流,每个流对应一种分辨率,如Fig2所示。我们通过一次又一次地在并行流之间交换信息来进行重复的多分辨率融合。
从HRNet学到的高分辨率representation不仅在语义上很强,而且在空间上也很精确。这源自两个方面。(i)我们连接从高分辨率到低分辨率的卷积流是以并行的方式,而不是以串行的方式。因此,我们的方法可以保持高分辨率,而不是从低分辨率恢复到高分辨率,因此学到的representation在空间上更为精确。(ii)大多数现有的融合方案都是通过上采样低分辨率从而获得高分辨率low-level和high-level的representation。相反,我们通过进行重复的多分辨率融合来提升高分辨率的representation,因此我们得到的高分辨率representation在语义上也很强。
我们提供了两个版本的HRNet。第一个版本为HRNetV1,只输出从高分辨率卷积流得到的高分辨率representation。我们遵循heatmap estimation framework,将其用于人体姿态估计。我们在COCO keypoint detection dataset上验证了其优越的表现。
另一个版本为HRNetV2,它结合了所有从高分辨率到低分辨率并行流的representation。我们将其用于语义分割。在PASCAL-Context,Cityscapes以及LIP上,相比大小相近的模型,我们的方法达到了SOTA,并且计算复杂度更低。在COCO pose estimation任务中,HRNetV1和HRNetV2的性能相似,但在语义分割任务中,HRNetV2表现更好。
此外,我们从HRNetV2输出的高分辨率representation中构建了一个multi-level representation,称之为HRNetV2p,并将其应用到最先进的检测框架中,这些检测框架包括Faster R-CNN,Cascade R-CNN,FCOS和CenterNet。还包括一些SOTA的joint detection和实例分割框架,比如Mask R-CNN,Cascade Mask R-CNN和Hybrid Task Cascade。结果表明,我们的方法提高了检测性能,尤其是对小物体的检测性能有了显著提高。
2.RELATED WORK
我们主要从三个方面回顾了与人体姿态估计、语义分割以及目标检测密切相关的representation学习技术:低分辨率representation学习,高分辨率representation恢复以及高分辨率的维持。此外,我们还提到了一些与多尺度融合(multi-scale fusion)相关的工作。
👉Learning low-resolution representations.
全卷积神经网络方法:FCN和OverFeat,都是通过移除分类网络中的全连接层来获得低分辨率的representation,然后评估其coarse segmentation maps。对segmentation maps的提升主要通过两种方式:1)组合从网络中间部分得到的low-level的中等分辨率的representation(比如FCN);2)迭代处理。类似的技术也被应用于边缘检测。
通过将原有的部分卷积替换为dilated convolutions从而使得全卷积神经网络可以得到中等分辨率的representation。对于不同大小的分割目标,可以通过特征金字塔来将得到的representation扩展为多尺度的representation。
👉Recovering high-resolution representations.
可以通过上采样将低分辨率的representation逐步恢复成高分辨率的representation。上采样子网络可以是下采样部分的对称版本。U-Net的扩展版本:full-resolution residual network,引入了一个额外的全分辨率流,该流携带着完整图像分辨率的信息,并且上采样和下采样子网络中的每个unit都和该流有信息上的交互(接收和发送)。
同样也有很多研究聚焦于和下采样不对称的上采样过程。比如RefineNet等。
👉Maintaining high-resolution representations.
我们的工作和一些同样也能生成高分辨率representation的工作密切相关,比如convolutional neural fabrics,interlinked CNNs,GridNet以及multi-scale DenseNet。
前两个工作,convolutional neural fabrics和interlinked CNNs,在以下几个方面缺少精细的设计:何时开始低分辨率并行流;并行流之间的信息怎么交换以及在何处交换;没有使用BatchNorm和残差连接,因此其并没有展示出令人满意的性能。GridNet像是多个U-Net的结合,其包含两个对称的信息交换阶段:第一个阶段信息只从高分辨率传递到低分辨率,第二个阶段信息只从低分辨率传递到高分辨率。这也限制了其分割质量。multi-scale DenseNet因为没有从低分辨率representation中接受信息,所以无法学到很强的高分辨representation。
👉Multi-scale fusion.
多尺度融合被广泛研究。最直接的方法是将多分辨率图像分别输入多个网络,然后将其输出聚合。Hourglass,U-Net和SegNet通过skip connections将下采样过程中low-level的特征组合到上采样过程中相同分辨率的high-level的特征上。PSPNet和DeepLabV2/3则是融合了通过pyramid pooling module和atrous spatial pyramid pooling得到的金字塔特征。我们的多尺度(即分辨率)融合模块也类似于两个pooling模块。但我们的pooling模块和PSPNet以及DeepLabV2/3的不同之处在于:(1)我们的融合可以输出四种分辨率representation,而不是仅仅只有一种分辨率;(2)受到deep fusion的启发,我们的融合模块重复了多次。
👉Our approach.
我们的网络并行连接high-to-low的卷积流。整个过程中都保持高分辨率representation,并通过反复融合来自多分辨率流的representation来生成具有强位置敏感性的可靠高分辨率representation。
本文对我们之前的会议论文(”K. Sun, B. Xiao, D. Liu, and J. Wang. Deep high-resolution representation learning for human pose estimation. In CVPR, 2019.”)进行了实质性的扩展,添加了更多的额外材料,以及和最近新的SOTA的目标检测和实例分割框架相比,展示了更多的目标检测结果。和之前的会议论文相比,本文主要的技术创新有三个方面。(1)我们将会议论文中提出的HRNetV1扩展到了两个版本:HRNetV2和HRNetV2p,这两个版本探索了所有的4种分辨率representation。(2)我们建立了多分辨率融合和regular convolution之间的联系,这为探索HRNetV2和HRNetV2p中所有四种分辨率representation的必要性提供了证据。(3)我们展示了HRNetV2和HRNetV2p相对于HRNetV1的优势,并介绍了HRNetV2和HRNetV2p在广泛的视觉问题中的应用,包括语义分割和目标检测。
3.HIGH-RESOLUTION NETWORKS
首先我们将图像输入到一个stem,其包含两个步长为2的$3\times 3$卷积,因此经过stem后分辨率降为原来的$\frac{1}{4}$,随后进入main body并得到同样分辨率的输出(即也是原始图像的$\frac{1}{4}$)。main body可见Fig2,其包含以下几部分:并行的多分辨率卷积,重复的多分辨率融合,以及representation head(见Fig4)。
3.1.Parallel Multi-Resolution Convolutions
我们用高分辨率流作为第一阶段的开始,然后一个接一个的添加high-to-low分辨率流以组成新的阶段,并行的多分辨率流之间还会有连接。因此,后一阶段的并行流的分辨率由前一阶段的分辨率和更低的分辨率组成。
网络结构的示例见Fig2,包含4个并行流,逻辑见下:
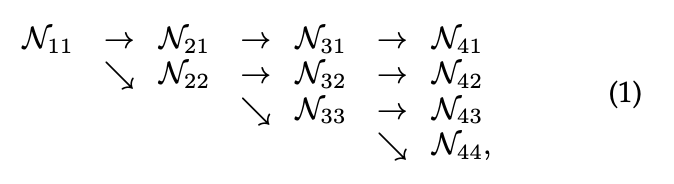
其中,$\mathcal{N}_{sr}$表示一个子流,$s$表示阶段,$r$表示分辨率索引。第一个流的分辨率索引为$r=1$,其表示第一个流的分辨率为$\frac{1}{2^{r-1}}$。
3.2.Repeated Multi-Resolution Fusions
融合模块的目标是在多分辨representation之间交换信息。融合重复了多次(例如,每4个residual unit就融合一次)。
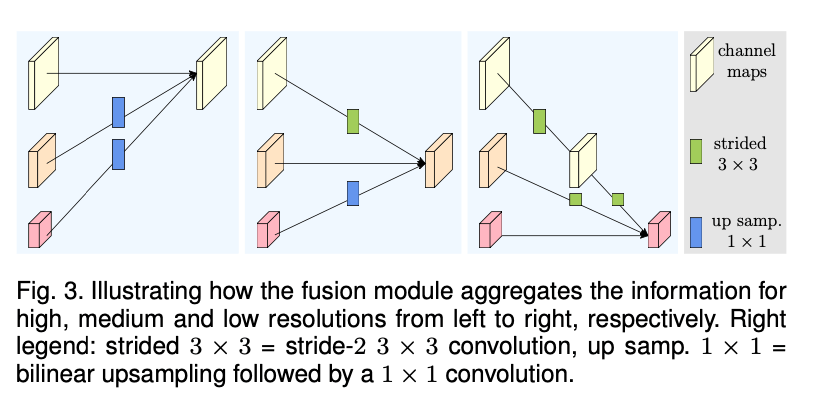
Fig3展示了一个融合3种分辨率representation的例子。其可以很容易的扩展到融合2种representation和融合4种representation。在Fig3中,输入包括3种representation:$\{ \mathbf{R}^i_r, r=1,2,3 \}$,$r$是分辨率索引,其对应的输出representation为$\{\mathbf {R}_r^o, r=1,2,3 \}$。每个输出representation都是三个输入representation经过处理后的总和:$\mathbf{R}_r^o=f_{1r}(\mathbf{R}_1^i)+f_{2r}(\mathbf{R}_2^i)+f_{3r}(\mathbf{R}_3^i)$。跨阶段(从阶段3到阶段4)的融合还有一个额外的输出:$\mathbf{R}_4^o=f_{14}(\mathbf{R}_1^i)+f_{24}(\mathbf{R}_2^i)+f_{34}(\mathbf{R}_3^i)$。
$f_{xr}(\cdot)$的形式取决于输入分辨率索引$x$和输出分辨率索引$r$。如果$x=r$,则有$f_{xr}(\mathbf{R})=\mathbf{R}$。如果$x<r$,则$f_{xr}(\mathbf{R})$对输入representation $\mathbf{R}$进行$(r-x)$次步长为2的$3\times 3$卷积来实现下采样。比如,一次步长为2 的$3\times 3$卷积可实现2倍下采样,2个连续的步长为2的$3\times 3$卷积可以实现4倍下采样。如果$x>r$,则$f_{xr}(\mathbf{R})$通过双线性插值进行上采样,并使用$1\times 1$卷积对齐channel的数量。图见Fig3。
3.3.Representation Head
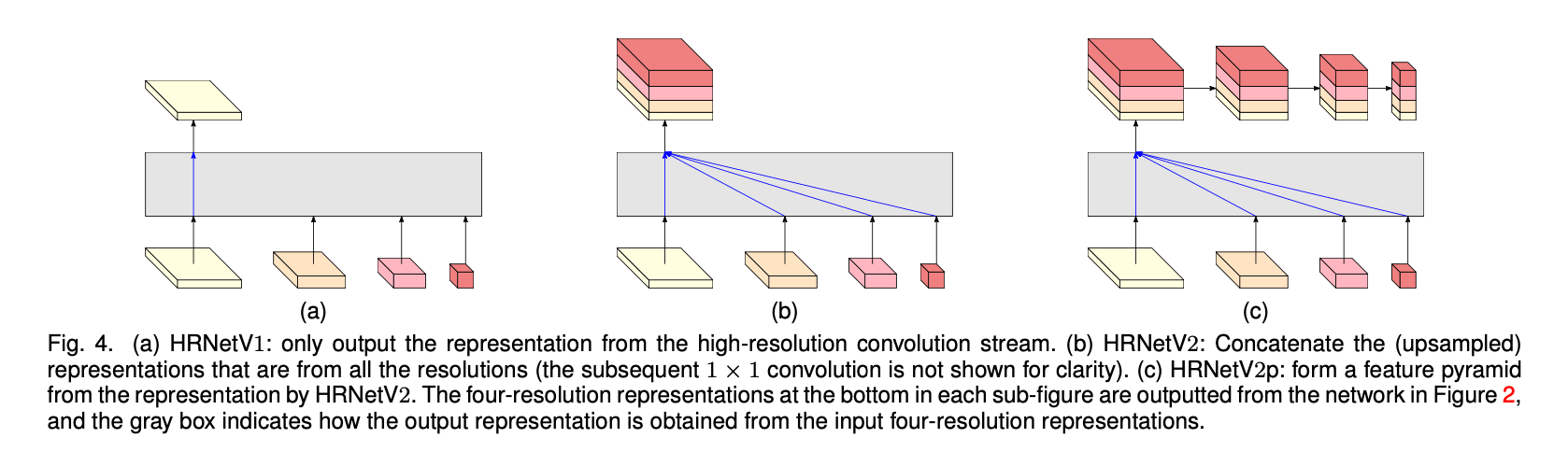
见Fig4,我们有3种representation head(接在Fig2的输出之后),我们将其分别称为HRNetV1,HRNetV2和HRNetV2p。
👉HRNetV1.
输出representation只来自于高分辨率流。另外3种representation会被忽略。见Fig4(a)。
👉HRNetV2.
我们将3种低分辨率的representation通过双线性插值上采样至高分辨率,但不改变其channel数量,最后把4种representation concat在一起,然后再接一个$1\times 1$卷积以混合这4种representation。见Fig4(b)。
👉HRNetV2p.
对HRNetV2得到的输出(称为feature pyramid)进行下采样。见Fig4(c)。
在本文中,我们将展示HRNetV1用于人体姿态估计的结果,HRNetV2用于语义分割的结果,HRNetV2p用于目标检测的结果。
3.4.Instantiation
详见APPENDIX A。
main body包含4个阶段以及4个并行卷积流。4个流的分辨率分别为原始图像的$\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32}$。阶段1包括4个residual unit,每个unit都是一个bottleneck的结构。阶段2、阶段3、阶段4分别包括1、4、3个modularized block。每个modularized block都包括4个residual unit。每个unit包括两个$3\times 3$卷积,每个卷积后都接一个BatchNorm和ReLU。
3.5.Analysis
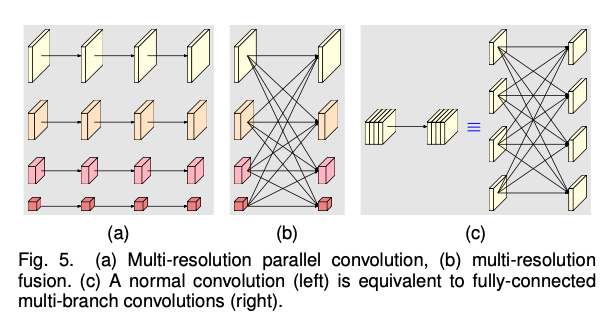
我们将modularized block分为两个部分:多分辨率并行卷积(Fig5(a))和多分辨率融合(Fig5(b))。多分辨率并行卷积类似于group convolution(分组卷积)。但在group convolution中分辨率都是一样的。多分辨率并行卷积会享有group convolution的一些好处。
多分辨率融合单元类似于常规卷积的多分支全连接形式,见Fig5(c)。常规的卷积可以被拆分为多个小的卷积。输入channel被划分为几个子集,输出channel也被划分为几个子集。输入和输出的子集以全连接的方式连接,每个连接都是一个常规卷积。输出channel的每个子集都是输入channel每个子集经过卷积后的总和。不同之处在于我们的多分辨率融合需要处理分辨率的变化。
4.HUMAN POSE ESTIMATION
人体姿态估计,也叫关键点检测,目的是为了从图像$\mathbf{I}$(大小为$W\times H \times 3$)中检测出$K$个关键点(比如手肘,手腕等)。我们遵循SOTA的框架,将问题转化为评估$K$个大小为$\frac{W}{4}\times \frac{H}{4}$的heatmap:$\{\mathbf{H}_1, \mathbf{H}_2, …, \mathbf{H}_K \}$,heatmap $\mathbf{H}_k$是第$k$个关键点的位置概率。
在该类任务上,HRNetV1和HRNetV2的性能几乎相同,因此我们选择计算复杂度更低的HRNetV1。损失函数被定义为预测的heatmap和GT heatmap之间的均方误差。通过标准差为2的2D高斯核来生成GT heatmap。一些例子的结果见Fig6。

Fig6为模型在COCO数据集上的结果,例子包含不同大小的人体、不同姿势以及不同的背景。
👉Dataset.
COCO数据集包含超过200,000张图片,250,000个人物实例,每个人标注有17个关键点。我们在COCO train2017上训练我们的模型,该数据集包含57K张图片和150K个人物实例。我们分别在val2017(包含5000张图片)和test-dev2017(包含20K张图片)上评估我们的模型。
👉Evaluation metric.
标准的评价指标为目标关键点相似性(Object Keypoint Similarity,OKS):
\[\text{OKS}=\frac{\sum_i \text{exp} [-d^2_i / (2s^2k_i^2)] \delta (v_i>0)}{\sum_i \delta (v_i>0)}\]其中,
- $i$表示第$i$个关键点。
- $d_i$为检测到的关键点和GT关键点(即人工标注值)之间的欧氏距离。
- $v_i$表示人工标注关键点是否可见。对于人工标注关键点,$v_i=0$表示关键点未标注,$v_i=1$表示关键点有遮挡但已经标注,$v_i=2$表示关键点无遮挡且已标注。
- $s$为目标尺度(object scale),即此目标在GT中所占面积(比如bounding box的面积)的平方根。
- $k_i$为第$i$个关键点的归一化因子(该因子是所有样本集中关键点由人工标注与真实值存在的标准差,该值越大表示此类型的关键点越难标注)。对COCO数据集中的5000个样本统计出17类关键点的归一化因子:鼻子0.026,眼睛0.025,耳朵0.035,肩膀0.079,手肘0.072,手腕0.062,臀部0.107,膝盖0.087,脚踝0.089。此值可以看作常数,如果使用的关键点类型不在此当中,则需要统计方法计算。
- $\delta$表示如果条件成立则为1,否则为0。
所有关键点都完美预测会有$\text{OKS}=1$,所有预测关键点都偏离真实值会有$\text{OKS}=0$。OKS类似于IoU,给定OKS,我们可以计算AP(average precision)和AR(average recall)。
每个真实值(17个关键点)都会和所有的预测值进行匹配(限制在同一幅图像中),配对的指标就是OKS,取OKS最大且OKS大于一定阈值(通常为0.5)的预测值和其真实值进行配对(所以存在一些真实值没有对应的预测值)。此时再设置另外一个阈值(通常在0.5~0.95之间),OKS大于该阈值的为TP,小于该阈值的为FP,而没有对应预测值的真实值算入FN,有了TP、FP和FN,便可以计算这幅图像的precision和recall了。所有图像precision和recall的均值便是AP和AR。通过对上述提到的第二个阈值进行修改以及可以分开评估不同大小的object,COCO数据集提供了以下几种评价指标:
- Average Precision(AP):
- $\text{AP}$:将第二个阈值分别设置为0.50,0.55,0.60,…,0.90,0.95等10个值,可以算出来10个AP,这10个AP的均值便是最终的AP。
- $\text{AP}^{\text{OKS}=.50}$:第二个阈值设置为0.5时得到的AP。
- $\text{AP}^{\text{OKS}=.75}$:第二个阈值设置为0.75时得到的AP。
- AP Across Scales:
- $\text{AP}^{\text{medium}}$:中等大小的object的AP。这里的中等大小指的是:$32^2 < \text{area} < 96^2$。因为过小的object($\text{area} < 32^2$)没有标注关键点,所以不考虑。
- $\text{AP}^{\text{large}}$:大obejct的AP,指的是$\text{area}>96^2$的object。
- Average Recall(AR):
- $\text{AR}$:将第二个阈值分别设置为0.50,0.55,0.60,…,0.90,0.95等10个值,可以算出来10个AR,这10个AR的均值便是最终的AR。
- $\text{AR}^{\text{OKS}=.50}$:第二个阈值设置为0.5时得到的AR。
- $\text{AR}^{\text{OKS}=.75}$:第二个阈值设置为0.75时得到的AR。
- AR Across Scales:
- $\text{AR}^{\text{medium}}$:中等大小($32^2 < \text{area} < 96^2$)的object的AR。
- $\text{AR}^{\text{large}}$:大obejct的AR,指的是$\text{area}>96^2$的object。
👉Training.
我们将human detection box的高宽比固定为4:3,然后将box从图像中裁剪出来并resize为固定大小:$256\times 192$或$384 \times 288$。数据扩展的方式包括随机旋转($[-45^{\circ},45^{\circ}]$)、随机缩放($[0.65,1.35]$)和翻转。借鉴论文“Z. Wang, W. Li, B. Yin, Q. Peng, T. Xiao, Y. Du, Z. Li, X. Zhang, G. Yu, and J. Sun. Mscoco keypoints challenge 2018. In Joint Recognition Challenge Workshop at ECCV 2018, 2018.”,还采用了半个身体的数据扩展方式。
我们使用Adam优化器。learning schedule遵循论文“B. Xiao, H. Wu, and Y. Wei. Simple baselines for human pose estimation and tracking. In ECCV, pages 472–487, 2018.”。基础学习率为1e-3,在第170个epoch时降为1e-4,在第200个epoch时降为1e-5。一共训练了210个epoch。训练使用了4块V100 GPU,训练HRNet-W32(HRNet-W48)一共花费了60(80)个小时。
👉Testing.
采用自上而下的两阶段形式:先使用person detector检测人物实例再检测关键点。
对于val和test-dev数据集,我们采用和SimpleBaseline一样的person detector。对于原始图像和其对应的翻转图像,我们会计算heatmap的平均。将heatmap中从最高响应值到第二高响应值的四分之一处作为预测关键点的位置。
👉Results on the val set.
我们将我们方法和其他SOTA方法的结果放在了表1中。HRNetV1-W32是从零开始训练的,输入大小为$256 \times 192$,AP达到了73.4,超过了相同输入大小的其他方法。(i)相比Hourglass,我们方法的AP高了6.5,但GFLOP低了一倍多,我们模型的参数数量稍多一些。(ii)和CPN(使用或不使用OHKM)相比,我们模型的大小和计算复杂度更高,但是比CPN的AP高了4.8,比CPN+OHKM的AP高了4.0。(iii)相比之前表现最好的方法SimpleBaseline,对于backbone为ResNet-50的SimpleBaseline,HRNetV1-W32的AP高出3.0,并且二者的模型大小和GFLOPs是相似的。对于backbone为ResNet-152的SimpleBaseline,HRNetV1-W32的AP仍然高出1.4,并且SimpleBaseline(backbone为ResNet-152)的模型大小(即#Params)和GFLOPs是HRNetV1-W32的两倍。
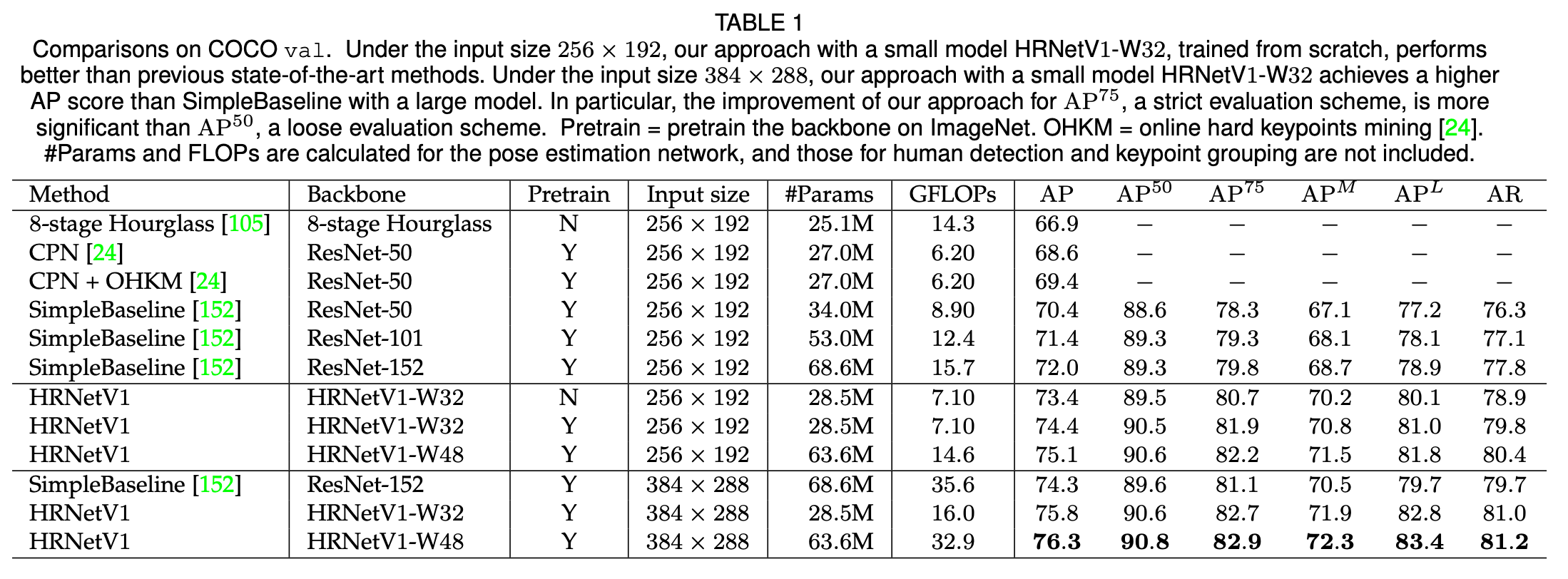
我们对模型进行了进一步的提升:(i)在ImageNet上进行预训练之后,AP获得了1.0的提升;(ii)HRNetV1-W32中的W指的是width,即channel数量,即APPENDIX A表14中的C。如果我们将C从32增加至48,即得到模型HRNetV1-W48,在输入大小分别为$256 \times 192$和$384 \times 288$时,HRNetV1-W48比HRNetV1-W32的AP分别高出0.7和0.5。
当输入大小从$256 \times 192$增加到$384 \times 288$时,HRNetV1-W32和HRNetV1-W48的AP分别提升了1.4和1.2,达到了75.8和76.3。当输入大小为$384 \times 288$时,相比backbone为ResNet-152的SimpleBaseline,HRNetV1-W32和HRNetV1-W48的AP分别高出1.5和2.0,但是其计算成本只有SimpleBaseline的45%和92.4%。
👉Results on the test-dev set.
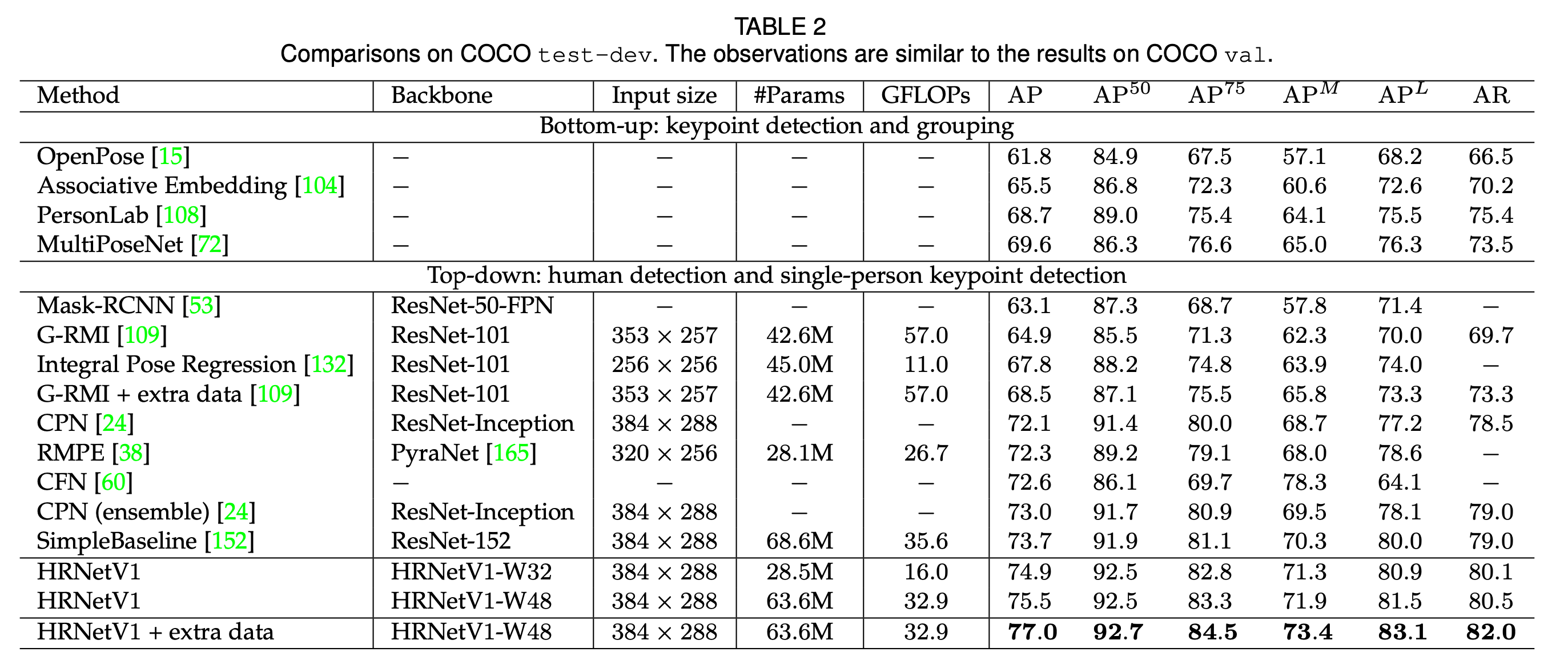
表2是我们的方法和现有SOTA方法在姿态估计任务上的表现。我们的方法明显优于自下而上的方法。HRNetV1-W32达到了74.9的AP。其明显优于其他所有自上而下的方法,并且在模型大小(#Params)和计算复杂度(GFLOPs)方面更有优势。我们的大模型HRNetV1-W48达到了最高的AP:75.5。和SimpleBaseline相比,HRNetV1-W32和HRNetV1-W48的AP分别高出1.2和1.8。如果使用来自AI Challenger的额外数据,我们的单个大模型可以达到77.0的AP。
5.SEMANTIC SEGMENTATION

语义分割其实就是为每个像素分配一个类别标签。我们方法的一些结果见Fig7。我们将输入图像喂给HRNetV2(见Fig4(b)),得到channel数量为15C(1+2+4+8=15)的representation,然后每个像素位置上的15C都通过一个线性分类器(使用softamx loss)得到segmentation map。将segmentation map通过双线性上采样(需4倍上采样)至原始分辨率,在训练和测试阶段都需要这样做。我们在两个场景的数据集上汇报了结果,PASCAL-Context和Cityscapes,以及一个人体解析数据集LIP。使用mean IoU(即mIoU)作为评价指标。
👉Cityscapes.
Cityscapes数据集包含5000张像素级别的高质量标注的场景图像。其中训练集2975张图像,验证集500张图像,测试集1525张图像。一共包含30个类别,其中19个类别被用于评估。除了使用mIoU,在测试集中,我们还汇报了另外三个指标的结果:IoU category(cat.)、iIoU class(cla.)以及iIoU category(cat.)。
数据扩展有随机裁剪(从$1024 \times 2048$到$512 \times 1024$),随机缩放($[0.5,2]$)以及随机水平翻转。我们使用SGD优化器,基础学习率为0.01,momentum=0.9,weight decay=0.0005。使用0.9次方用于学习率衰减。所有模型都训练了120K次迭代,batch size为12,使用了4块GPU以及syncBN。
syncBN(Synchronized Batch Normalization)是一种批量归一化(Batch Normalization,BN)的变种,用于并行训练深度神经网络时加速训练过程和提高模型的性能。
在传统的批量归一化中,每个GPU都会在其本地的mini-batch上计算每个通道的均值和方差,并使用这些值来标准化该mini-batch的数据。然而,在多GPU环境下,这种方式可能会导致不同的GPU上的数据在进行归一化时具有不同的统计特征,这会降低模型的性能。
syncBN通过跨多个GPU的所有数据计算每个通道的均值和方差,并将这些值用于所有GPU上的mini-batch数据的标准化。这样可以保证在所有GPU上对数据进行归一化时具有相同的统计特征,从而提高模型的性能和训练速度。
值得注意的是,syncBN的计算成本比传统的批量归一化更高,因为需要进行跨多个GPU的通信和计算。因此,在计算资源有限的情况下,使用syncBN可能会增加训练时间。
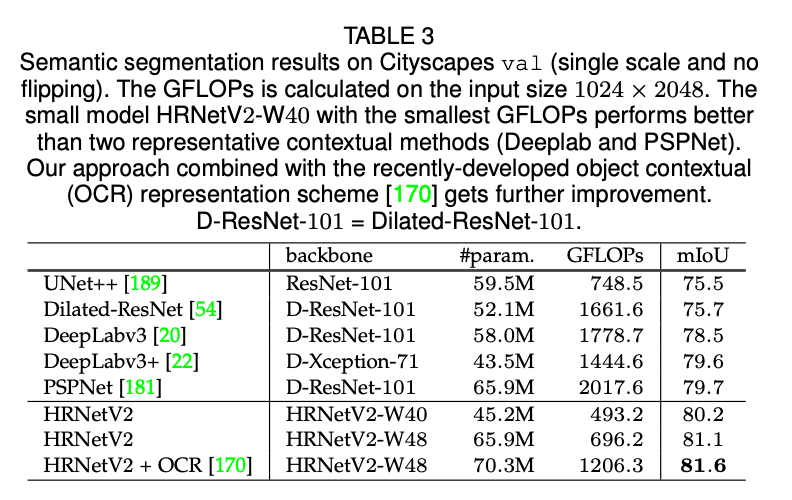
表3提供了在Cityscapes val数据集上几种代表性方法的结果。(i)HRNetV2-W40和DeepLabv3+的模型大小相近,但是计算复杂度更低,效果更好。相比UNet++、DeepLabv3和PSPNet/DeepLabv3+,HRNetV2-W40的mIoU分别高出4.7、1.7以及0.5左右。(ii)HRNetV2-W48的模型大小和PSPNet相近,但是计算复杂度低了很多,且性能方面有很大的提升。相比UNet++,mIoU提升了5.6个点;相比DeepLabv3,提升了2.6个点;相比PSPNet和DeepLabv3+,提升了大约1.4个点。接下来,我们将HRNetV2-W48在ImageNet上进行了预训练,其模型大小和基于Dilated-ResNet-101的多数模型大小相近。
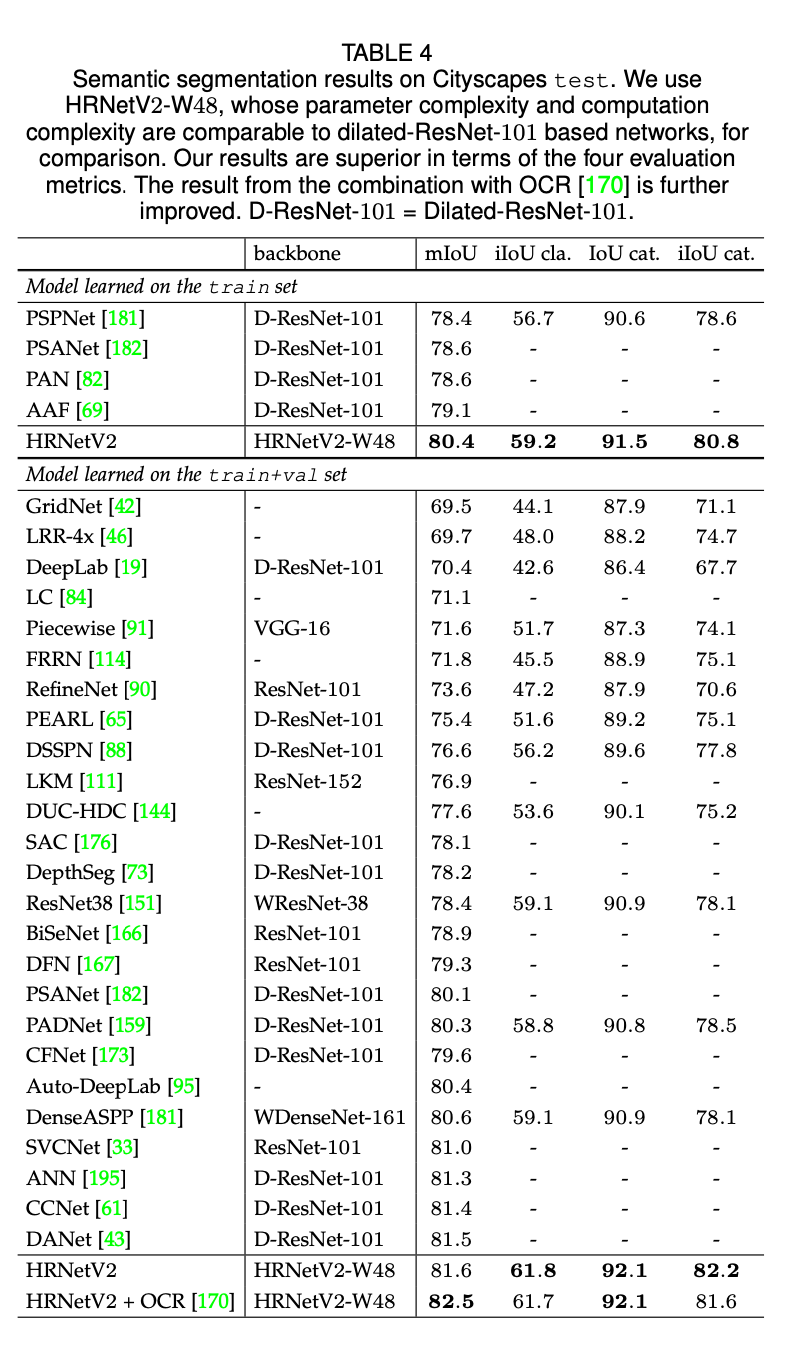
表4提供了我们的方法和其他SOTA方法在Cityscapes test数据集上的比较结果。所有的结果都使用了6种尺度以及翻转。训练分为两种情况,一种情况是在train数据集上进行训练,另一种情况是在train+val数据集上进行训练。不管哪种情况,HRNetV2-W48都取得了最好的结果。
👉PASCAL-Context.
PASCAL-Context训练集包括4998张场景图像,测试集包括5105张图像,一共有59个语义标签和一个背景标签。
数据扩展和学习率策略同Cityscapes。遵循广泛使用的训练策略,我们将图像resize到$480 \times 480$,初始学习率设为0.004,weight decay=0.0001。batch size=16,迭代次数为60K。
我们遵循标准的测试流程。将图像resize到$480 \times 480$,然后喂入我们的网络。最后得到的结果需要resize回原始分辨率。我们使用6个尺度+翻转来评估我们的方法和其他方法。
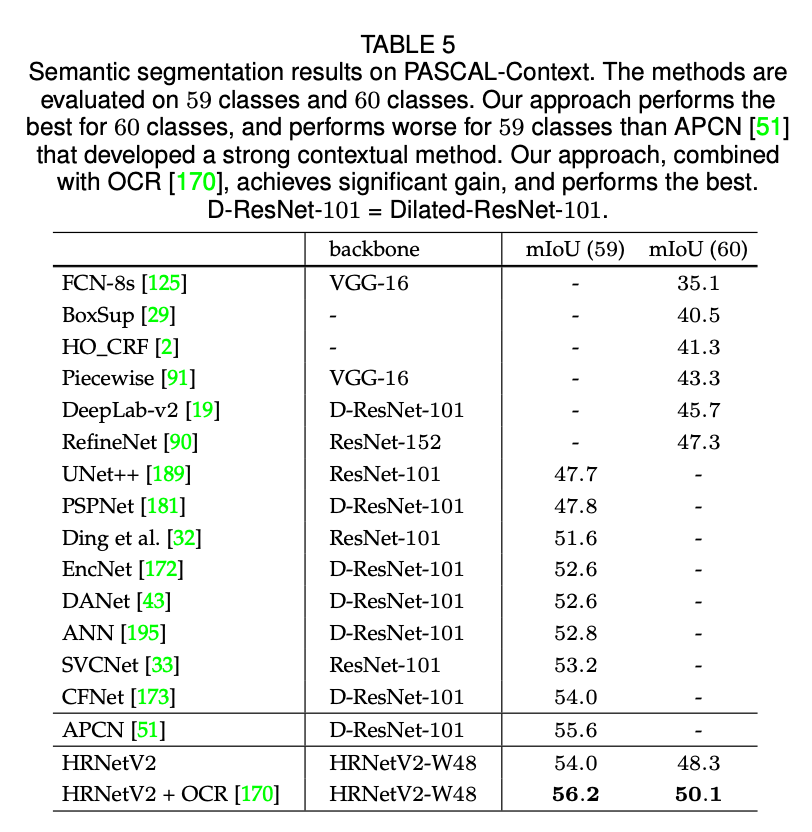
表5提供了我们方法和其他SOTA方法的比较结果。有两种评估策略:在59个类别上的mIoU和在60个类别(59个类别+背景)上的mIoU。在所有测试的方法中,HRNetV2-W48达到了最好的结果,只有APCN的性能比不使用OCR的HRNetV2-W48要好一点点。
👉LIP.
LIP数据集包含50,462张精心标注的人物图像,其中30,462张用于训练,10,000张用于验证。在20个类别(19个人物部位标签+1个背景标签)上进行评估。遵循标准的训练和测试设置,将图像resize到$473 \times 473$,用原始图像和翻转图像结果的平均进行性能评估。
数据扩展和学习率策略同Cityscapes。我们设初始学习率为0.007,momentum=0.9,weight decay=0.0005。batch size=40,迭代次数为110K。
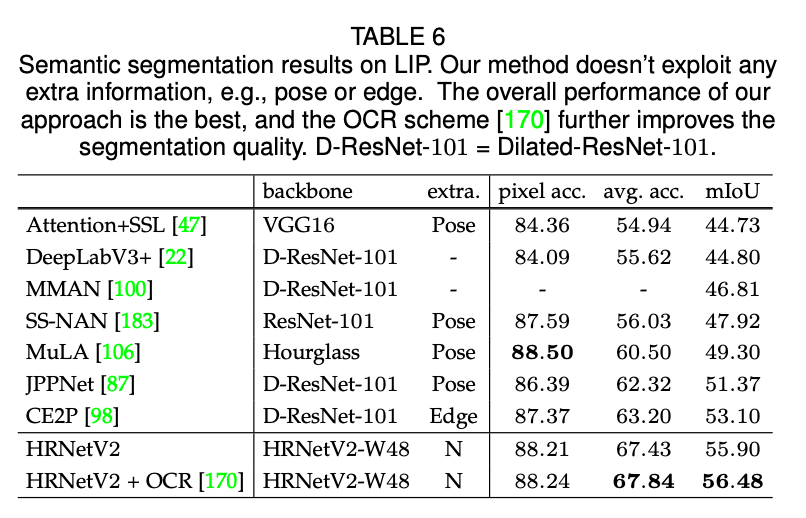
表6提供了我们方法和其他SOTA方法的比较结果。HRNetV2-W48的整体性能是最好的,并且参数量更少,计算成本更低。此外我们的模型没有使用额外的信息,比如pose或edge。
6.COCO OBJECT DETECTION
我们在MS COCO 2017检测数据集上进行评估,其包括118K张图像用于训练,5K张用于验证(val),约20K张用于测试(test-dev,但是不提供标注)。使用标准的COCO风格的评估指标。我们的一些结果见Fig8。

我们使用HRNetV2p(见Fig4(c))进行目标检测。数据扩展使用了标准的水平翻转。将输入图像resize到短边为800像素。inference在单尺度图像上进行。
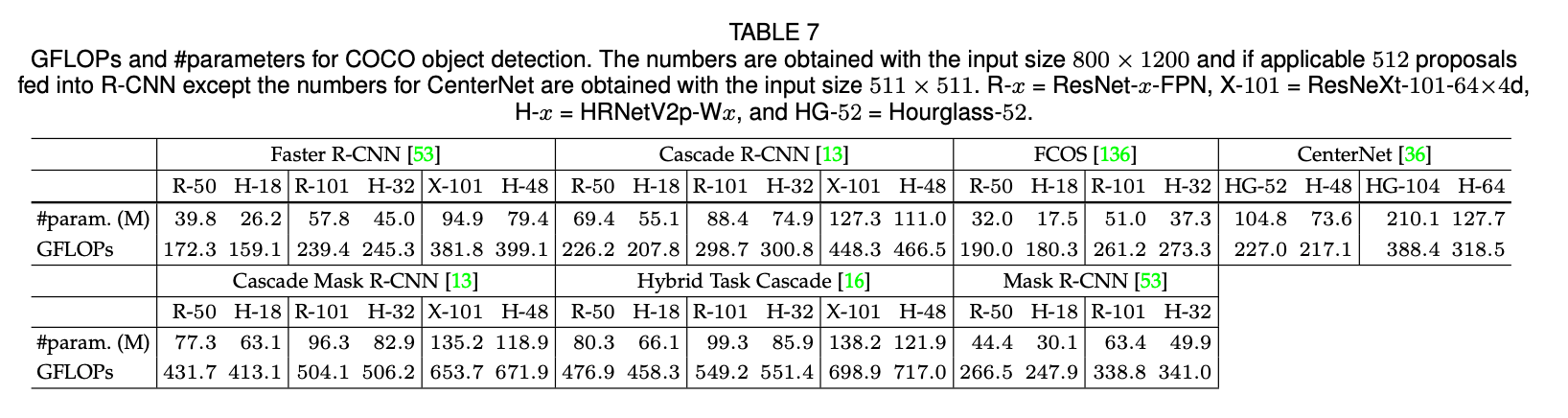
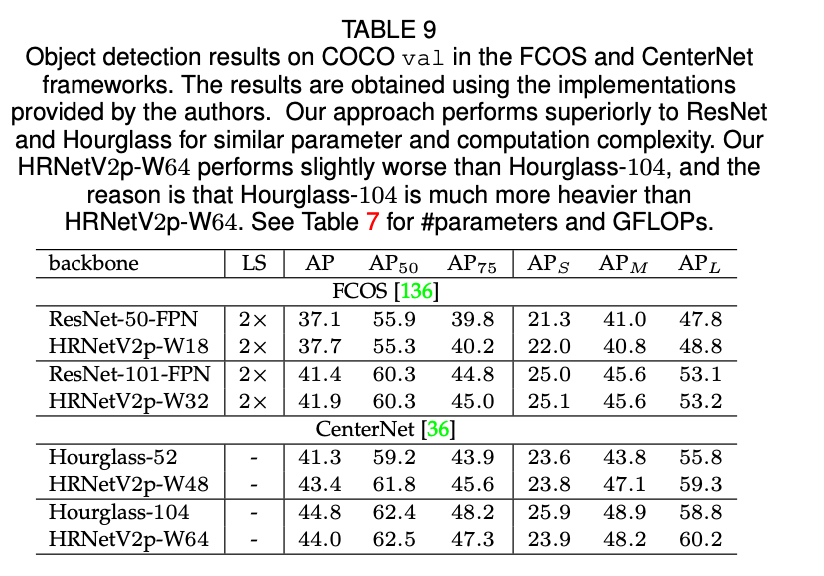
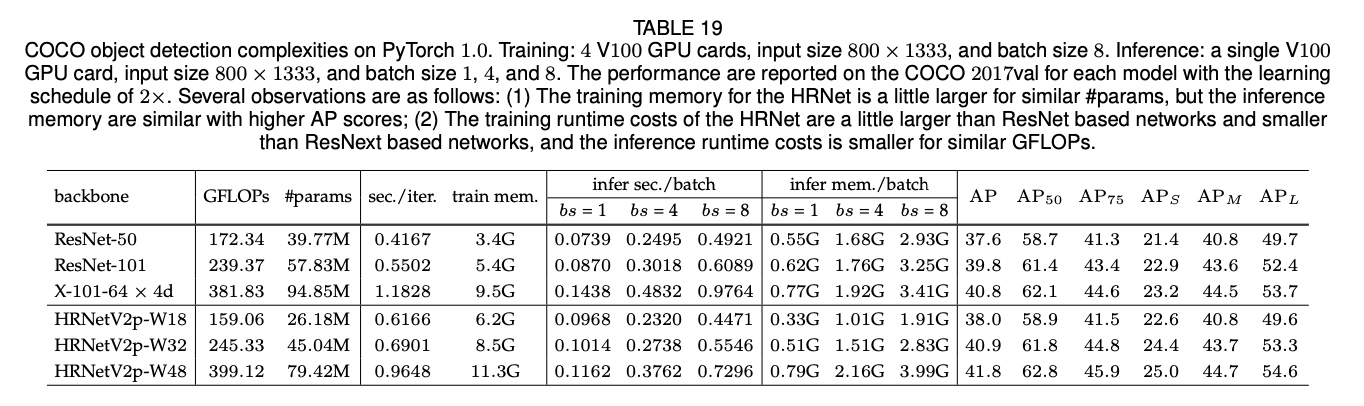
我们将HRNet和ResNet、ResNeXt进行了比较。我们将其作为backbone,在两个anchor-based的框架(Faster R-CNN和Cascade R-CNN)上以及两个anchor-free的框架(FCOS和CenterNet)上都基于COCO val数据集进行了性能评估。我们在公共的MMDetection platform上训练了基于HRNetV2p和基于ResNet的Faster R-CNN和Cascade R-CNN,使用MMDetection默认的训练设置,唯一修改的地方是采用了论文“K. He, R. B. Girshick, and P. Dolla ́r. Rethinking imagenet pre- training. CoRR, abs/1811.08883, 2018.”建议的2倍的学习率策略。FCOS和CenterNet的实现由原作者提供。表7总结了参数量和GFLOPs。表8和表9汇报了检测结果。
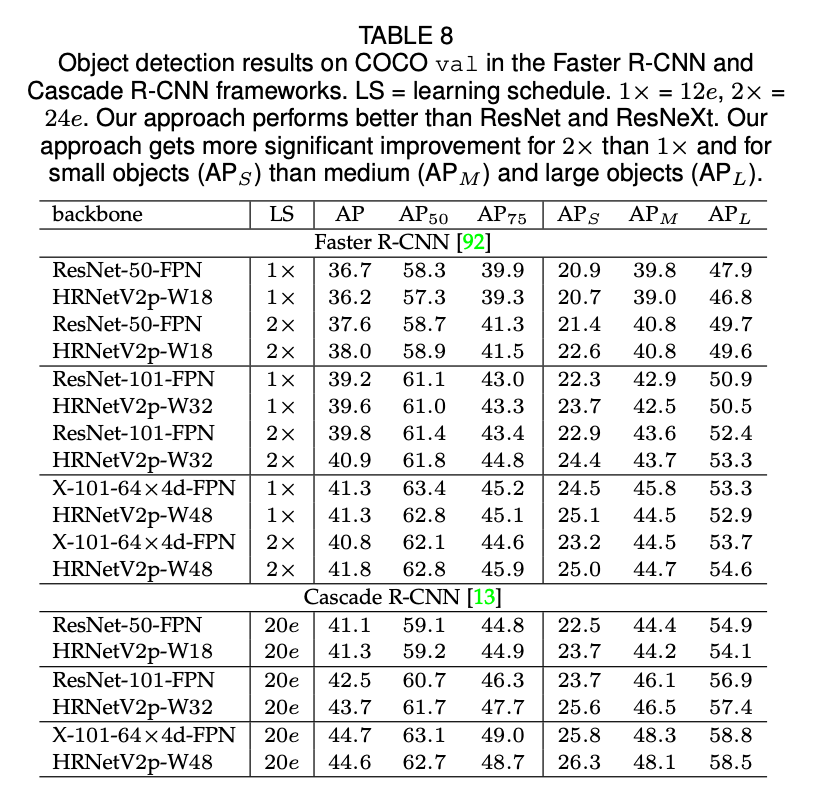
同时,我们也使用了另外三个框架(Mask R-CNN,Cascade Mask R-CNN和Hybrid Task Cascade)来评估关节点检测和实例分割。同样是使用公共的MMDetection platform,详见表10。
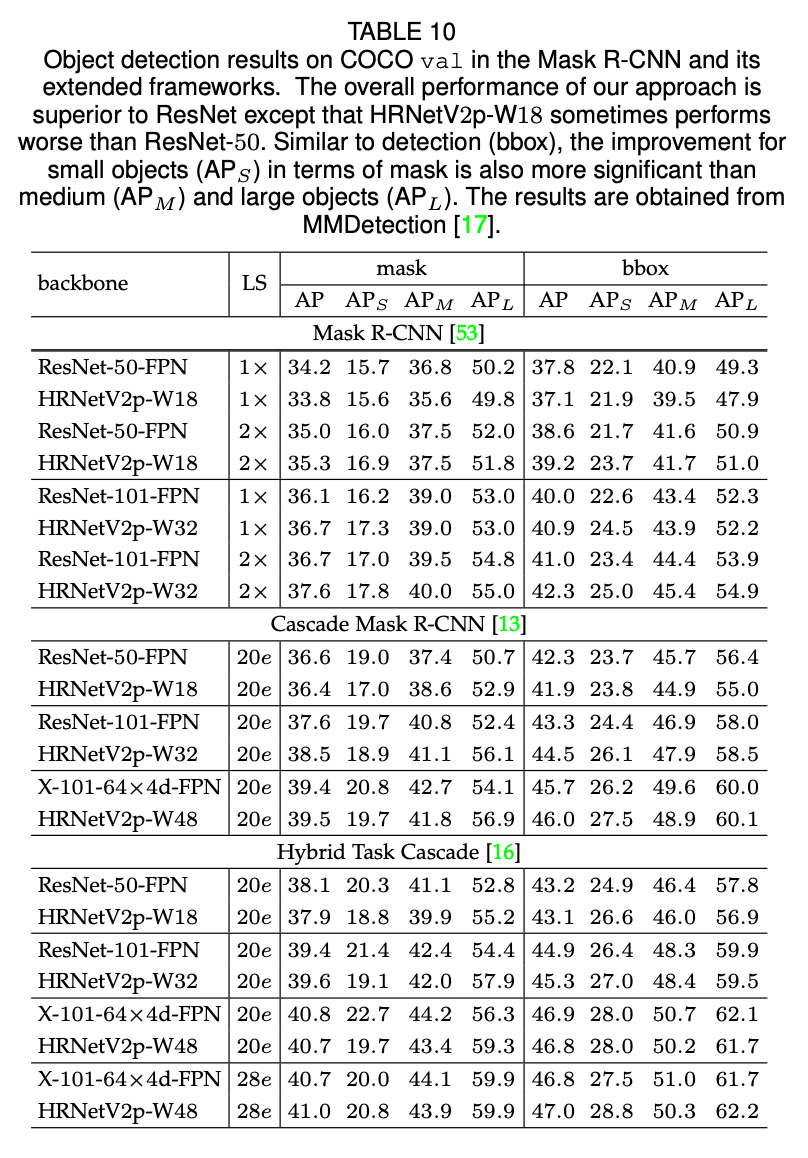
如表8和表9所示,总的来说,对于有着相近模型大小以及计算复杂度的HRNetV2和ResNet来说,HRNetV2在目标检测任务上的表现优于ResNet。对于一些case,比如$1\times$,HRNetV2p-W18的表现差于ResNet-50-FPN,这可能是因为优化迭代次数不足。如表10所示,HRNet在目标检测和实例分割方面优于ResNet和ResNeXt。对于个别情况,比如Hybrid Task Cascade框架下,HRNet的表现略差于ResNeXt-101-64x4d-FPN(LS=20e),但是优于LS=28e时的ResNeXt-101-64x4d-FPN。这也说明HRNet能从更长时间的训练中获取更大的收益。
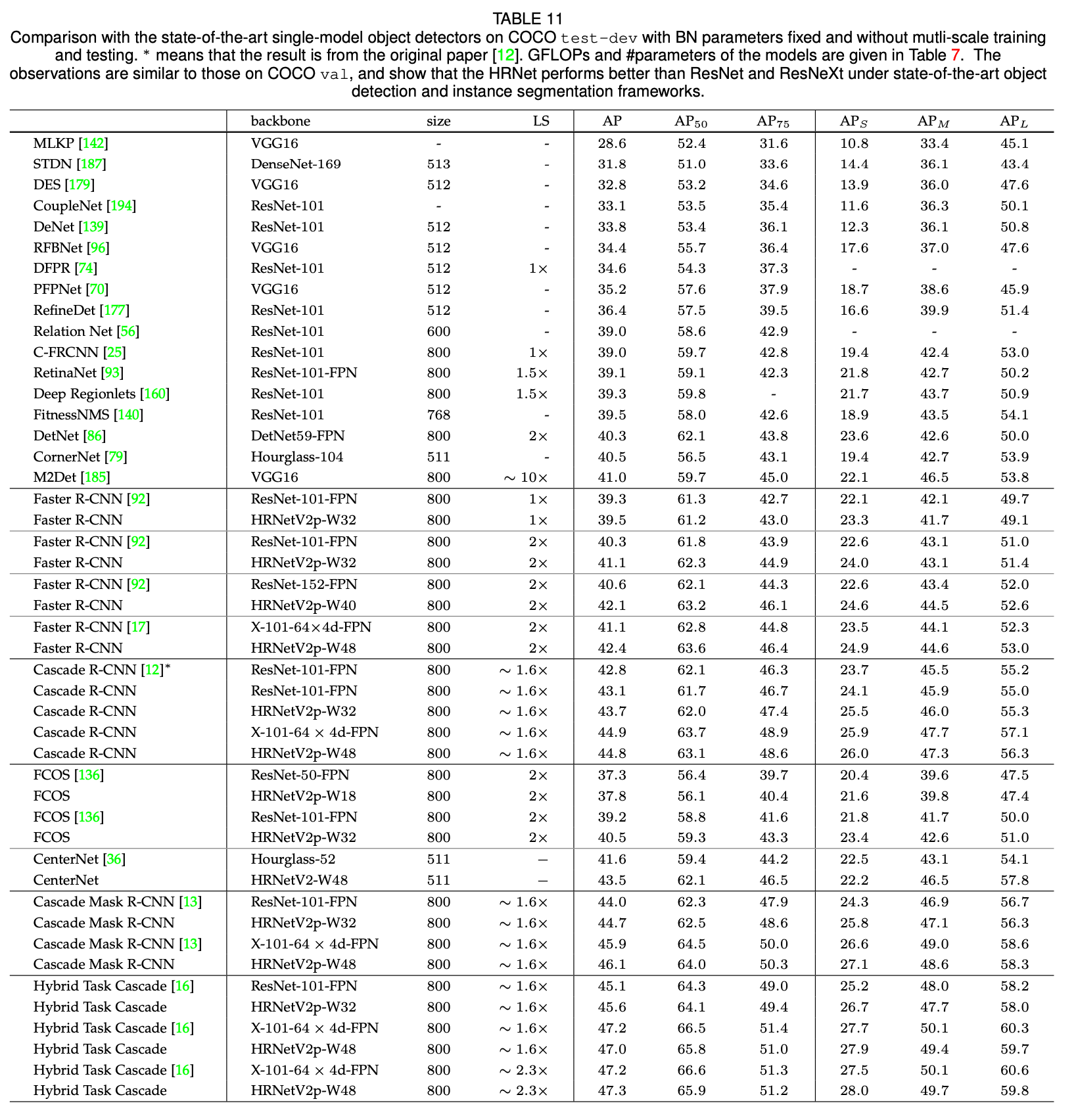
表11是我们的模型和其他SOTA模型(单个模型,不使用多尺度训练和多尺度预测)在COCO test-dev上的比较。对于Faster R-CNN框架,我们的网络比ResNets更好,并且参数量和计算复杂度是相似的:HRNetV2p-W32 vs. ResNet-101-FPN,HRNetV2p-W40 vs. ResNet-152-FPN,HRNetV2p-W48 vs. X-101-64x4d-FPN。对于Cascade R-CNN框架和CenterNet框架,HRNetV2的表现仍然是更好的那个。对于Cascade Mask R-CNN和Hybrid Task Cascade框架,HRNet的总体性能也是更好的。
7.ABLATION STUDY
我们在两项任务上进行了HRNet的消融实验:一个是COCO验证集上的人体姿态估计任务,另一个是Cityscapes验证集上的语义分割任务。我们使用HRNetV1-W32进行人体姿态估计,使用HRNetV2-W48进行语义分割。人体姿态估计任务的输入大小统一为$256 \times 192$。此外,我们还比较了HRNetV1和HRNetV2的结果。
👉Representations of different resolutions.
我们通过检查从高到低每种分辨率的heatmap的质量来研究representation分辨率对人体姿态估计性能的影响。
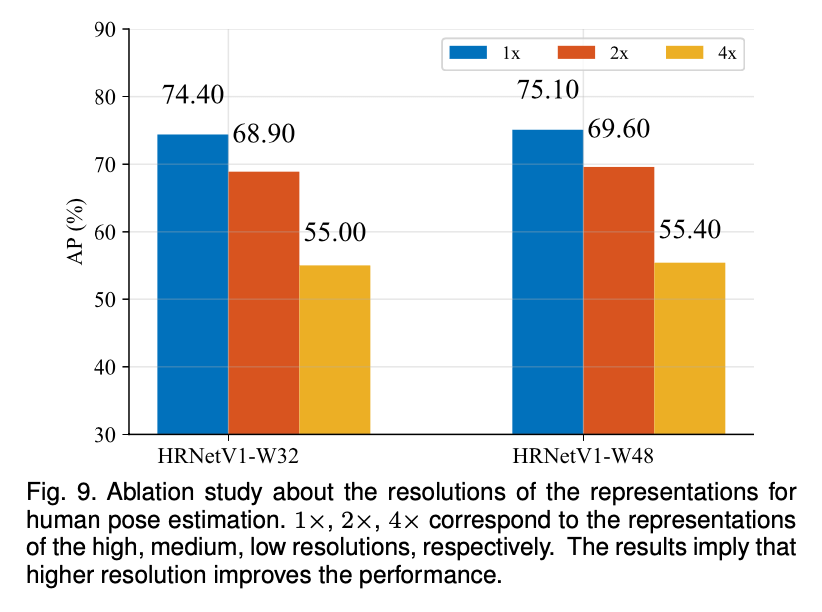
我们训练了两个经过ImageNet预训练过的HRNetV1。我们的网络会输出从高到低四种分辨率的response map。如果使用最低分辨率的输出map,AP值低于10。AP值在另外三个分辨率上的表现见Fig9。比较结果说明分辨率确实会影响关键点预测质量。
👉Repeated multi-resolution fusion.
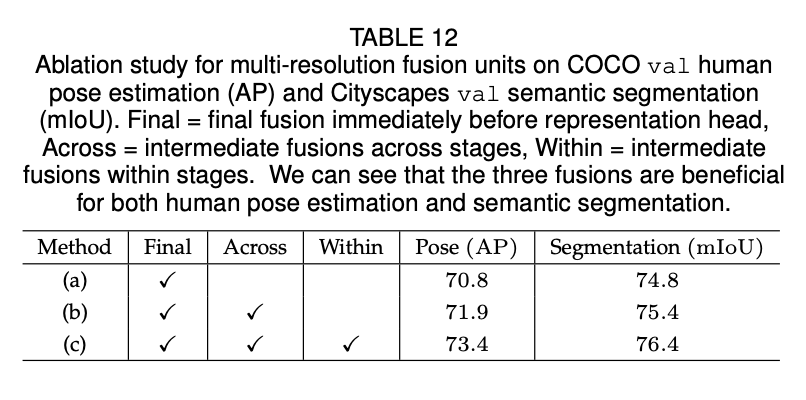
我们还分析了多次重复多分辨率融合的效果。我们研究了网络的三种变体。(a)无中间融合单元(即1次融合):多分辨率流之间没有融合,只有最后才会有一个最终的融合单元。(b)只有跨阶段时有融合单元(即3次融合),每个阶段内的并行流之间没有融合。(c)跨阶段和阶段内都有融合单元(一共8次融合):这是我们最终提出的方法。所有的网络都是从零开始训练。COCO人体姿态估计和Cityscapes语义分割的结果见表12,结果表明多分辨率融合是有用的,且越多的融合导致了更好的性能。
我们还探索了其他融合方式:(i)使用双线性下采样代替strided convolutions;(ii)使用乘法运算代替加法运算。在第一种情况下,COCO姿态估计任务的AP和Cityscapes分割任务的mIoU分数分别下降至72.6和74.2。原因在于下采样降低了representation map的volume size(width$\times$height$\times$#channels),而strided convolutions在volume size方面就做的很好。第二种情况的结果更差,分数分别降至54.7和66.0。可能的原因是乘法增加了训练难度。
👉Resolution maintenance.
我们研究了HRNet某一变体的性能,这一变体和当前模型的不同之处在于其一开始就是4个分辨率流,并且这4个流的深度都一样,融合机制和当前模型是一样的。我们将这一变体和当前模型(二者有着相近的参数量和GFLOPs)都从头开始训练。
对于人体姿态估计任务,在COCO val数据集上,该变体的AP为72.5,低于HRNetV1-W32的73.4。对于分割任务,在Cityscapes val数据集上,该变体的mIoU为75.7,低于HRNetV2-W48的76.4。我们认为原因是在早期阶段,从低分辨率流中提取到的low-level的特征帮助不大。此外,我们还测试了另一种变体,即只有高分辨率流,没有并行的低分辨率流,其也和当前模型有着相近的参数量和GFLOPs,但其在COCO和Cityscapes上的表现远差于当前模型。
V1 vs. V2.
我们在姿态估计、语义分割和COCO目标检测任务上,比较了HRNetV1和HRNetV2以及HRNetV2p。对于人体姿态估计任务,这几个模型性能相近。比如,HRNetV2-W32(不使用ImageNet预训练)达到了73.6的AP,稍高于HRNetV1-W32的73.4。
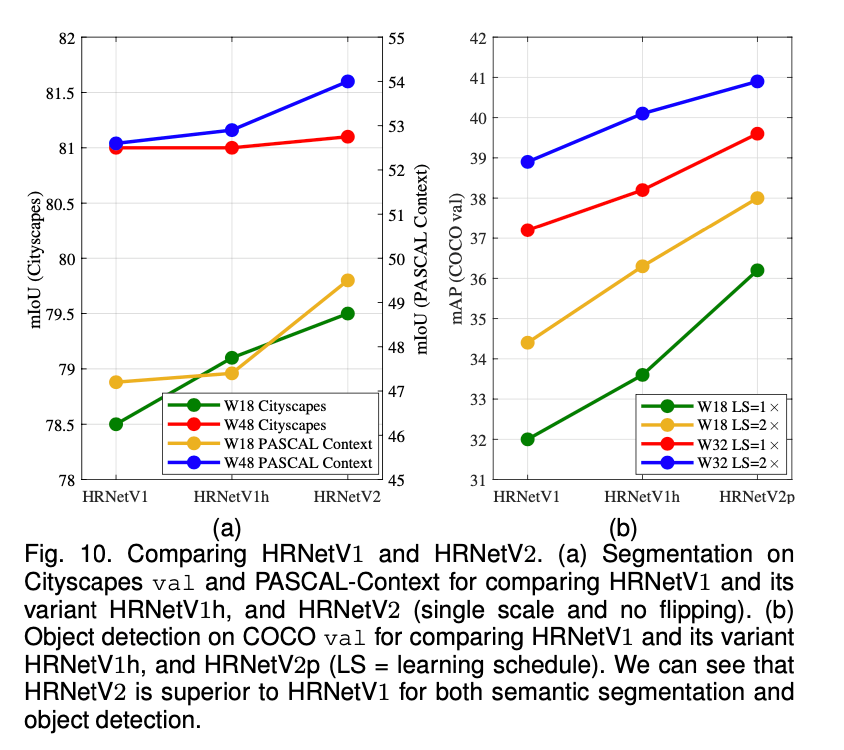
语义分割任务和目标检测任务的比较结果见Fig10(a)和Fig10(b),可以看到HRNetV2的性能明显优于HRNetV1,只是在Cityscapes的分割任务中,HRNetV2的大模型相较于小模型没有HRNetV1的收益高而已。我们还测试了另外一种变体,即HRNetV1h,其通过添加$1\times 1$卷积使得HRNetV1输出的高分辨率representation维度可以和HRNetV2的维度保持一致。Fig10(a)和Fig10(b)都显示HRNetV1h的性能略好于HRNetV1,这也表明我们在HRNetV2中聚合多个并行分辨率流的representation对性能的提升至关重要。
8.CONCLUSIONS
在本文中,我们提出一种高分辨率网络框架用于计算机视觉领域。其与现有的低分辨率分类网络和高分辨率representation学习网络有三个根本区别:(i)并行高分辨率和低分辨率,而不是串行;(ii)在整个过程中保持高分辨率,而不是从低分辨率中恢复高分辨率;(iii)重复融合多种分辨率的representation,得到具有强大位置敏感性的高分辨率representation。
在大量视觉识别任务上的优越结果表明,HRNet是CV领域内一个强大的backbone。
Discussions.
这里可能会有一种误解:分辨率越高,HRNet的内存成本也越大。但事实上,除了在目标检测任务的训练阶段,HRNet的内存成本稍大之外,其在人体姿态估计、语义分割和目标检测任务中的内存成本和现有SOTA技术相当。
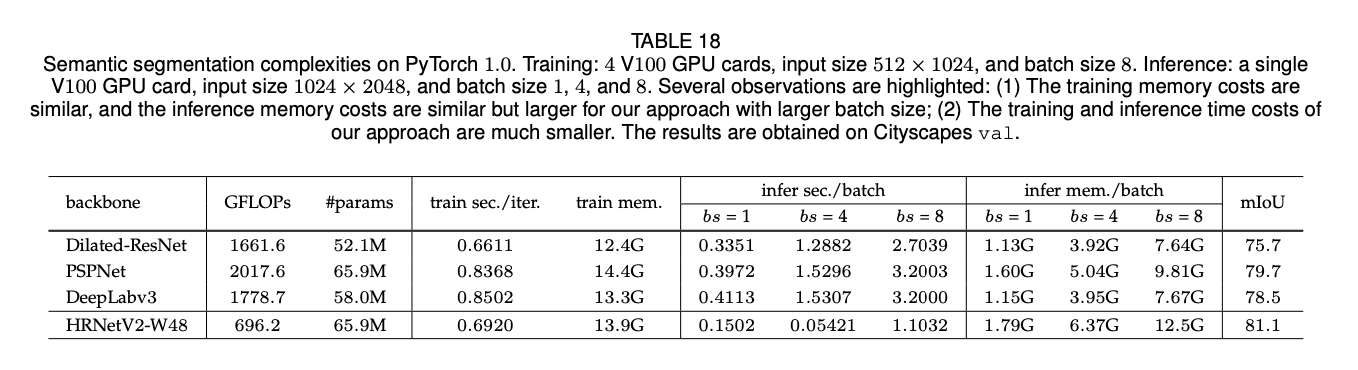
此外,我们还在PyTorch 1.0上比较了runtime成本。HRNet的训练和推理时间成本和现有SOTA技术相当,除了(1)用于分割的HRNet的推理时间会更短;(2)用于姿态估计的HRNet训练时间会稍长,但在支持静态图推理的MXNet 1.5.1平台上,其与SimpleBaseline时间成本相近。我们想强调的一点是,对于语义分割任务,HRNet的推理成本明显小于PSPNet和DeepLabv3。表13总结了内存和时间成本的比较结果。
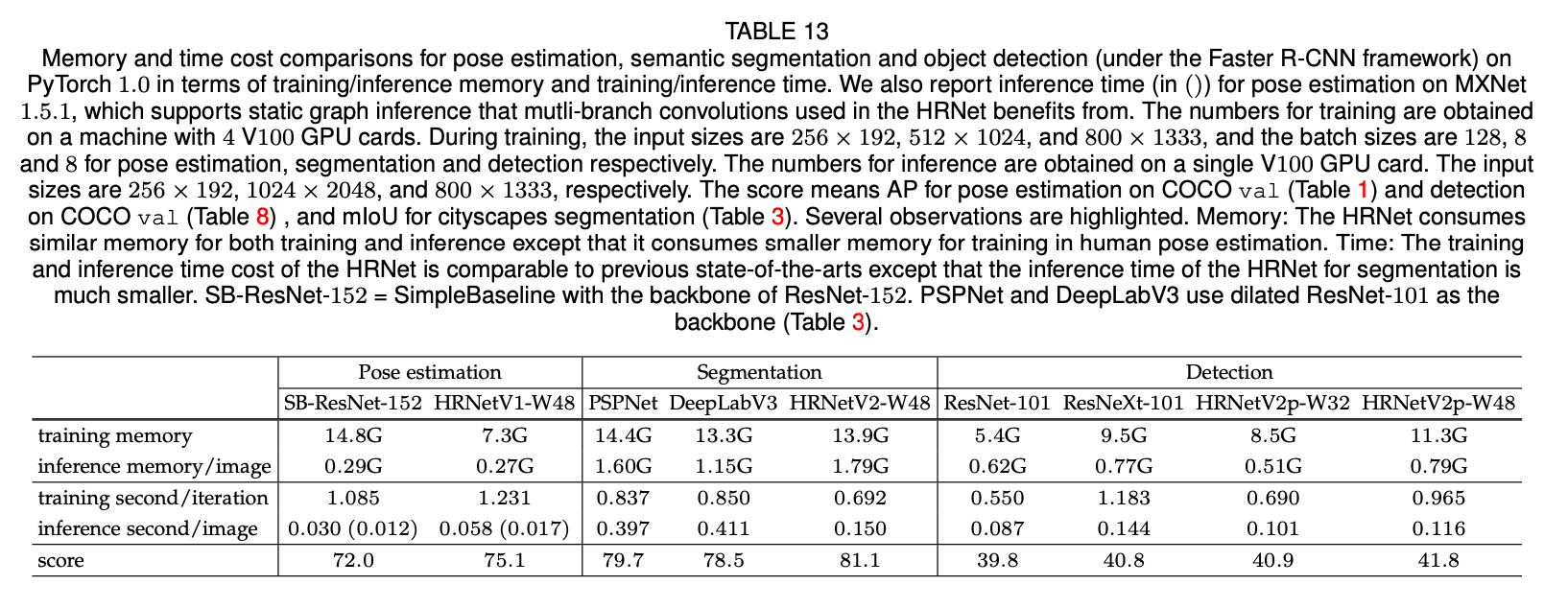
表13是基于PyTorch 1.0,在姿态估计、语义分割、目标检测(基于Faster R-CNN框架)等三个任务上的训练/推理的内存以及时间成本比较。我们还报告了基于MXNet 1.5.1,在姿态估计任务上的推理时间成本(见表13中括号内的数值),HRNet可以从MXNet支持的静态图推理中受益。训练使用了4块V100 GPU。对于训练阶段,姿态估计任务的输入大小为$256\times 192$,batch size=128;分割任务的输入大小为$512\times 1024$,batch size=8;目标检测任务的输入大小为$800\times 1333$,batch size=8。推理阶段只使用了一块V100 GPU。对于推理阶段,姿态估计任务的输入大小为$256\times 192$;分割任务的输入大小为$1024\times 2048$;目标检测任务的输入大小为$800\times 1333$。至于表13最后一行的score,对于姿态估计任务,其是基于COCO val数据集得到的AP值(见表1);对于目标检测任务,其是基于COCO val数据集得到的AP值(见表8);对于分割任务,其是基于cityscapes数据集得到的mIoU值(见表3)。这里重点介绍几个观察结果。和其他方法相比,无论是训练还是推理,HRNet的内存成本与之相当,甚至在姿态估计任务上,HRNet的训练内存成本更低。和其他方法相比,无论是训练还是推理,HRNet的时间成本也与之相当,甚至在分割任务上,HRNet的推理时间成本更低。SB-ResNet-152指的是backbone为ResNet-152的SimpleBaseline。PSPNet和DeepLabV3则使用ResNet-101作为backbone。
Future and followup works.
我们将继续研究HRNet和其他语义分割、实例分割技术的结合。在表3、表4、表5、表6中,我们列出了HRNet和OCR技术相结合的结果。我们也会研究进一步提高分辨率,例如提高到原始分辨率的$\frac{1}{2}$或直接使用原始分辨率。
我们也尝试了将HRNet和ASPP或PPM相结合,但其并没有在Cityscape上有性能提升,但是在PASCAL-Context和LIP上有轻微的性能提升。
HRNet的应用并不局限于我们已经列出的,HRNet也适用于其他位置敏感型的视觉应用,比如面部特征点检测、超分辨率、光流估计、深度估计等等。目前已经有了一些后续的工作,比如图像风格化、图像修复、图像增强、图像去雾、时间姿态估计和无人机目标检测等。
在单一模型下,稍微修改的HRNet搭配ASPP在Mapillary上实现了最佳的全景分割性能。在ICCV 2019的COCO + Mapillary Joint Recognition Challenge Workshop上、COCO DensePose challenge的获胜者以及几乎所有COCO关键点检测挑战的参与者都采用了HRNet。OpenImage实例分割挑战的获胜者(ICCV 2019)同样也采用了HRNet。
9.APPENDIX
APPENDIX A : NETWORK INSTANTIATION

我们目前的设计包括4个阶段(掐头去尾,不算stem和head),详细见表14。每个阶段包含若干个modularized block,并分别重复1,1,4,3次。阶段1有1个分支,阶段2有2个分支,阶段3有3个分支,阶段4有4个分支。每个分支代表一种分辨率,并且每个阶段中的每个分支都包含4个residual unit(这4个residual unit之间应该有残差连接)和一个多分辨率融合unit(见Fig3)。
表14中的$[\cdot] \times x \times y$,$[\cdot]$表示residual unit,$x$表示residual unit的重复次数,$y$表示modularized block的重复次数。$C$表示channel数量。
APPENDIX B : NETWORK PRETRAINING
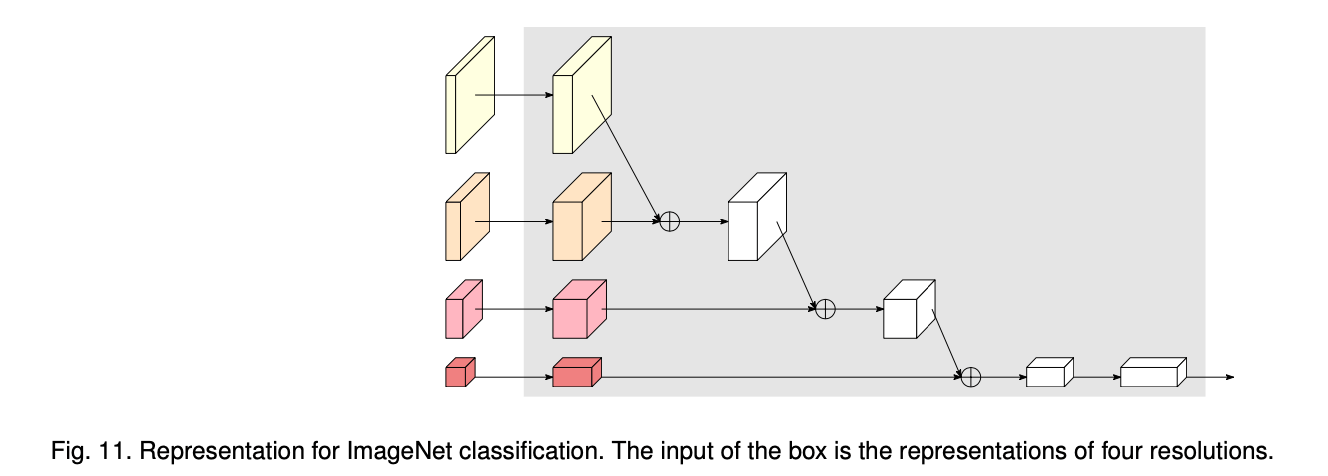
我们在ImageNet上预训练我们的网络,预训练需要添加一个额外的分类头,见Fig11。首先,分别将4个分辨率的feature map的channel数量从C、2C、4C、8C增加到128、256、512、1024。然后,将最高分辨率的representation通过步长为2的$3\times 3$卷积进行下采样,通道数变为256,并将其加到第二高分辨率的representation上。这一过程重复两次,最后得到一个1024通道的最低分辨率的representation。随后,我们使用$1\times 1$卷积将1024通道扩展至2048通道,后接一个global average pooling。最终输出的2048维度的representation被喂给分类器。
我们对训练图像采用的数据扩展方式同论文“Deep Residual Learning for Image Recognition”,模型训练了100个epoch,batch size=256。初始学习率设置为0.1,并且在第30、60、90个epoch时,学习率缩小10倍。使用SGD,weight decay为0.0001,momentum为0.9。测试采用标准的single-crop,即从每幅图像中裁剪出$224 \times 224$大小的图像。在验证集上评估了top-1和top-5错误率。
表15展示了我们在ImageNet上的分类效果。作为比较,我们还列出了ResNets的结果。我们考虑了两种类型的残差单元:一种是bottleneck结构,另一种是两个$3\times 3$卷积(详见ResNet原文中的Fig5)。我们使用PyTorch中的ResNets,但是把$7\times 7$的卷积换成了两个步长为2的$3\times 3$卷积,从而将分辨率降为原始分辨率的$\frac{1}{4}$,这样就和HRNet一致了。当残差单元为两个$3\times 3$卷积时,我们会额外添加一个bottleneck结构来将输出的feature map的维度从512增加至2048(原始结构见此处表1)。从表15中可以看到,在相近的参数量和GFLOPs情况下,HRNet的性能略优于ResNets。
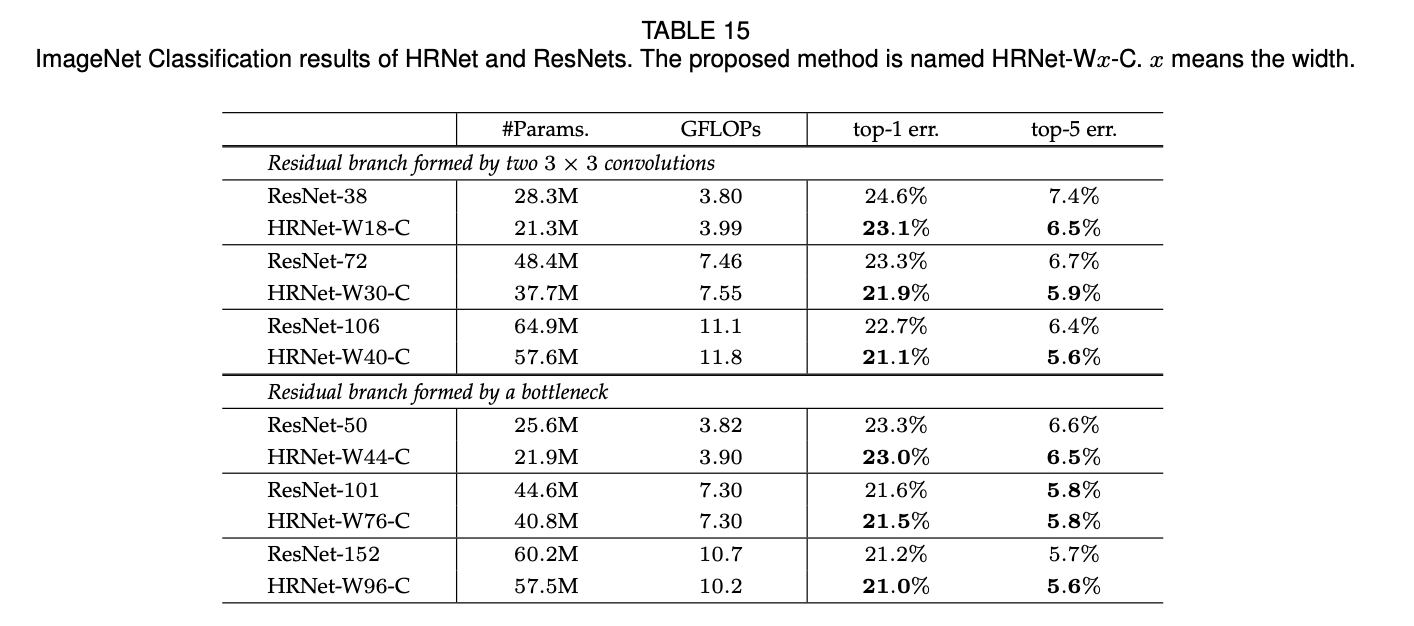
在表15中,我们将此处提出的方法称为HRNet-Wx-C,x就是width。除此之外,我们还比较了另外两种分类头的方法:(i)每个分辨率流得到的feature map都单独通过一个global pooling,然后将输出concat起来,所以最后就能得到一个15C维度(1+2+4+8)的representation向量,我们将其称为HRNet-Wx-Ci;(ii)每个分辨流得到的feature map都通过几个步长为2的残差单元(bottleneck结构,每个单元都将通道数翻倍)直至通道数增加至512,然后将所有分辨率流的输出concat起来,再通过一个average-pool,最终得到一个2048维度($512 \times 4$)的representation向量,我们将其称之为HRNet-Wx-Cii。我们做了消融实验,结果见表16。可以看出,我们提出的方法优于这两种。
APPENDIX C : TRAINING/INFERENCE COST
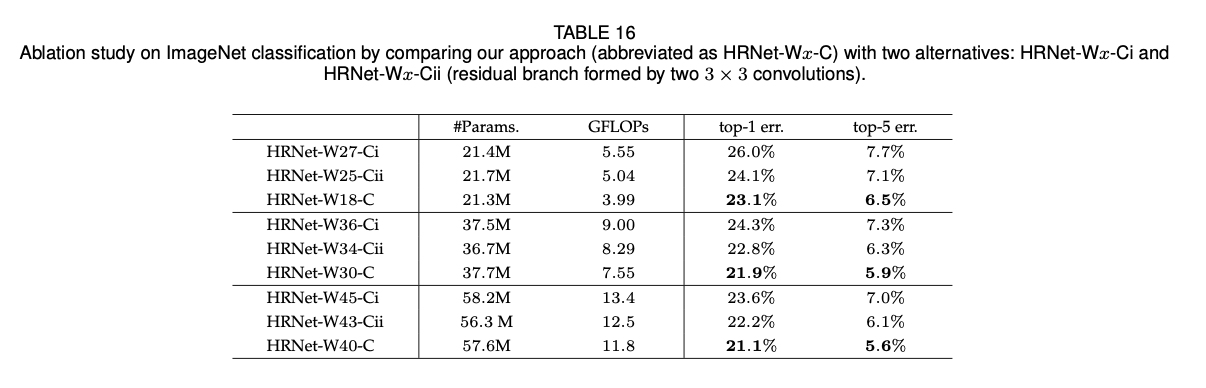
表17、表18和表19列出了HRNet和其他标准网络在PyTorch平台上训练以及推理时的GPU占用比较。从表17中可以看出,和其他人体姿态估计任务的SOTA模型相比,在参数量相近的情况下,HRNet的训练以及推理的内存成本都和其他模型相近或者更低。在表18中,对于语义分割任务来说,在相近参数量的情况下,HRNet的训练以及推理的内存成本和其他SOTA模型相近。在表19中,对于目标检测任务,在相近参数量情况下,HRNet的训练以及推理的内存成本比其他SOTA模型稍高或者相似。
此外,我们也提供了运行时间成本的比较。(1)对于语义分割任务,HRNet的训练时间成本更小,并且其推理时间成本小于PSPNet和DeepLabv3(见表18)。(2)对于目标检测任务,HRNet的训练时间成本高于基于ResNet的网络,但低于基于ResNext的网络。在相近GFLOPs下,HRNet的推理时间成本更小。详见表19。(3)对于人体姿态估计任务,HRNet的训练时间成本和其他方法相近,但HRNet的推理时间成本更大;但是在MXNet平台上,HRNet的训练以及推理时间成本和SimpleBaseline相近。
APPENDIX D : FACIAL LANDMARK DETECTION
面部关键点检测(facial landmark detection),又称面部对齐(face alignment)主要是从面部图像中检测关键点。我们在4个数据集上进行了评估:WFLW、AFLW、COFW、300W。我们主要使用归一化平均误差(normalized mean error,NME)进行评估。我们使用眼间距离作为WFLW、COFW和300W的归一化,使用面部bounding box作为AFLW的归一化。我们还报告了AUC和失败率。
我们遵循标准方案(见论文“W. Wu, C. Qian, S. Yang, Q. Wang, Y. Cai, and Q. Zhou. Look at boundary: A boundary-aware face alignment algorithm. In CVPR, pages 2129–2138, 2018.”)进行训练。所有的面部都通过提供的box根据中心位置进行裁剪,并resize到$256 \times 256$。我们数据扩展的方式有$\pm 30$度的旋转、0.75-1.25倍的缩放以及随机翻转。基础学习率为0.0001,在第30个和第50个epoch时分别降为0.00001和0.000001。训练使用了一块GPU,训练了60个epoch,batch size=16。和语义分割不同,heatmap并没有从$\frac{1}{4}$分辨率上采样至原始分辨率,损失函数在$\frac{1}{4}$原始分辨率的map上进行的优化。
在测试阶段,将heatmap中的最大值从$\frac{1}{4}$分辨率还原到原始分辨率,并向第二大值做$\frac{1}{4}$的偏移,从而得到最终预测的关键点位置。
我们使用HRNetV2-W18进行面部关键点检测,和广泛使用的backbone:ResNet-50和Hourglass相比,其参数量和计算成本更低或者相似。HRNetV2-W18的参数量为9.3M,GFLOPs=4.3G;ResNet-50的参数量为25.0M,GFLOPs=3.8G;Hourglass的参数量为25.1M,GFLOPs=19.1G。这些数字都是基于输入大小为$256 \times 256$获得的。需要注意的是,采用ResNet-50和Hourglass作为backbone的面部关键点检测方法还引入了额外的参数和计算开销。
👉WFLW.
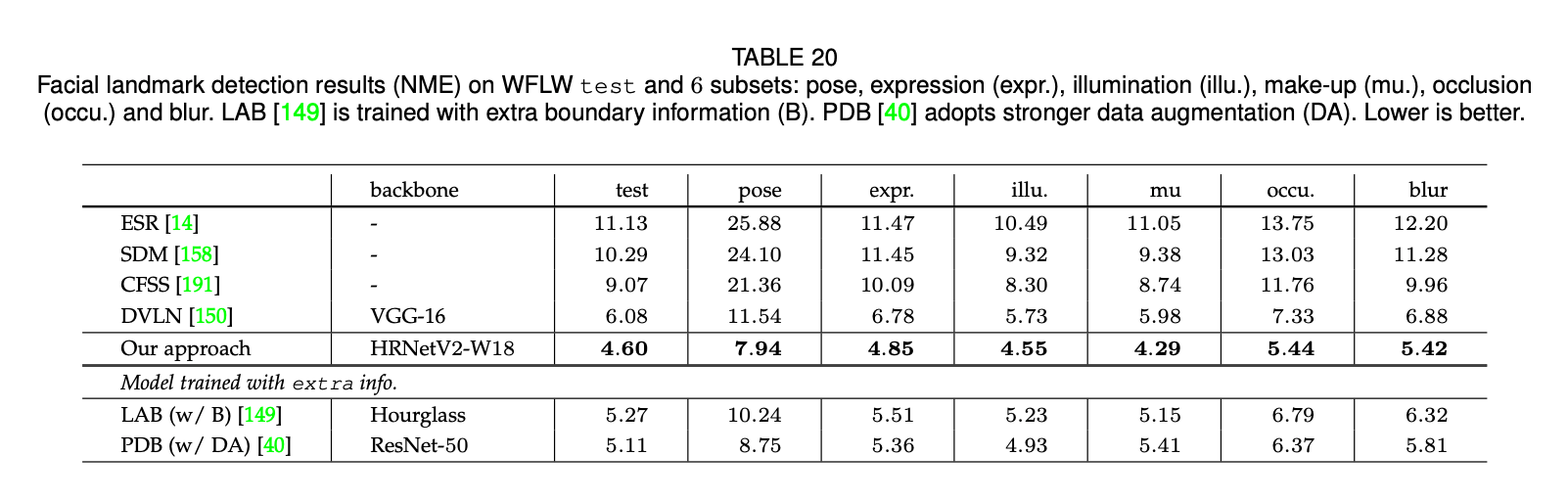
WFLW数据集是最近基于WIDER Face构建的数据集。该数据集包括7500张训练图像和2500张测试图像,每张图像有98个手动标注的关键点。我们在训练集和一些子集上汇报了结果,这些子集包括:large pose(326张图像)、expression(314张图像)、illumination(698张图像)、make-up(206张图像)、occlusion(736张图像)、blur(773张图像)。
表20展示了我们的方法和其他SOTA方法的比较。在测试集和所有子集上,我们的方法都明显优于其他方法,包括利用额外边界信息的LAB和使用更强数据扩展的PDB。
👉AFLW.
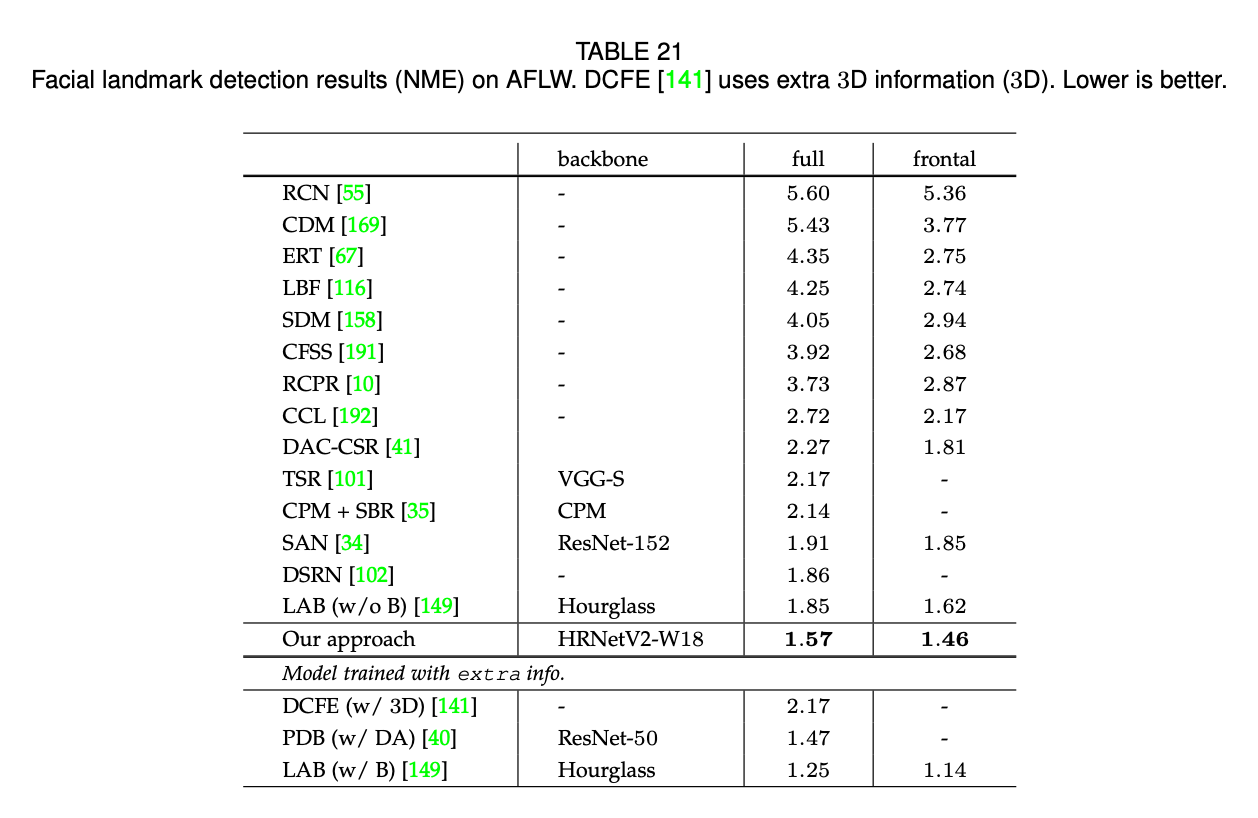
AFLW数据集是一个广泛使用的benchmark数据集,每张图像包括19个面部关键点。遵循论文“W. Wu, C. Qian, S. Yang, Q. Wang, Y. Cai, and Q. Zhou. Look at boundary: A boundary-aware face alignment algorithm. In CVPR, pages 2129–2138, 2018.”和论文“S. Zhu, C. Li, C. C. Loy, and X. Tang. Face alignment by coarse-to-fine shape searching. In CVPR, pages 4998–5006, 2015.”,我们在20000张训练图像上训练了我们的模型,然后在AFLW-Full数据集(4386张测试图像)和AFLW-Frontal数据集(从4386张测试图像中选出了1314张图像)上汇报了我们的结果。
表21展示了我们的方法和其他SOTA方法的比较。和不使用额外信息以及很强数据扩展的方法相比,我们方法的性能是最好的,甚至好于使用了额外3D信息的DCFE。我们的方法稍差于LAB(使用了额外边界信息)和PDB(使用很强的数据扩展)。
👉COFW.
COFW数据集包括1345张训练图像和507张测试图像,图像带有遮挡,每张图像包括29个面部关键点。
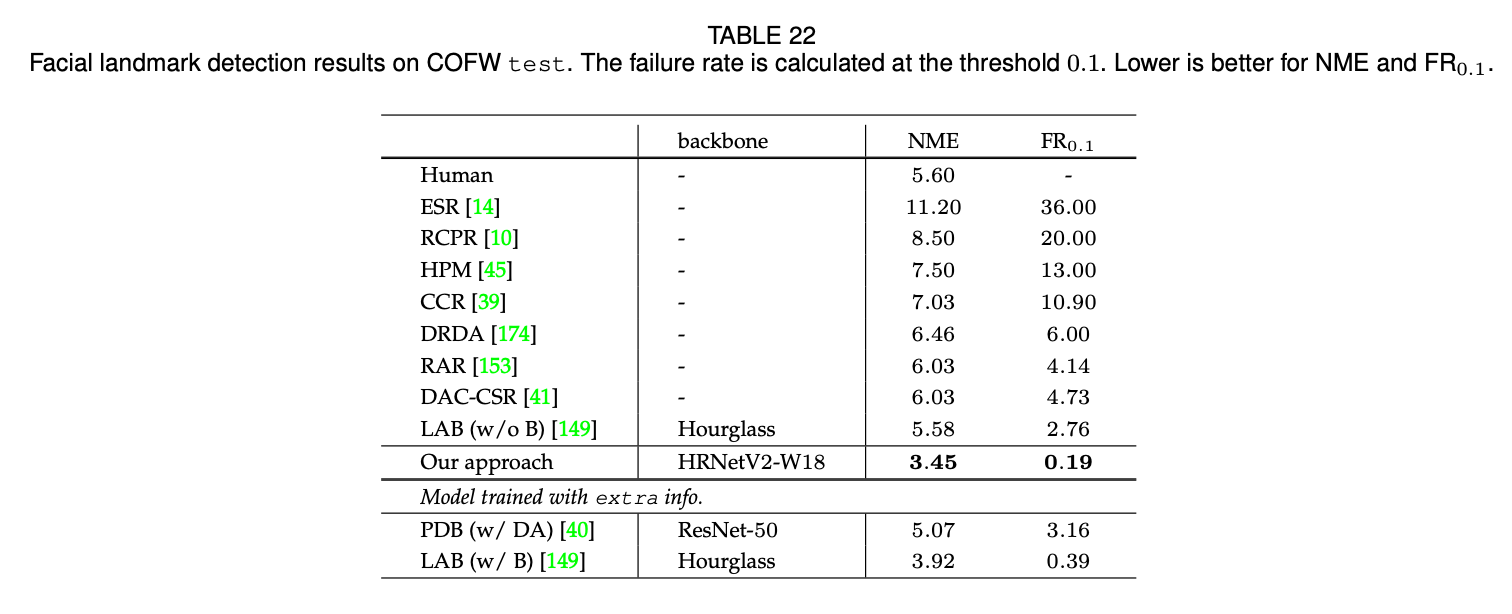
表22展示了我们的方法和其他SOTA方法的比较。HRNetV2明显优于其他方法。特别是,与使用了额外边界信息的LAB和使用了更强数据扩展的PDB相比,我们的方法也取得了更好的结果。
👉300W.
该数据集由HELEN、LFPW、AFW、XM2VTS和IBUG等多个数据集组成,每张面部图像包含68个关键点。遵循论文“S. Ren, X. Cao, Y. Wei, and J. Sun. Face alignment via regressing local binary features. IEEE Trans. Image Processing, 25(3):1233–1245, 2016.”,我们使用了3148张训练图像,其由HELEN、LFPW的子集以及AFW的全部组成。我们分别在full set和test set上评估了性能。full set包括689张图像,进一步分为一个常见子集(554张图像,来自HELEN和LFPW)和一个更有挑战性的子集(135张图像,来自IBUG)。用于比赛的官方test set,包含600张图像(300张室内图像,300张室外图像)。
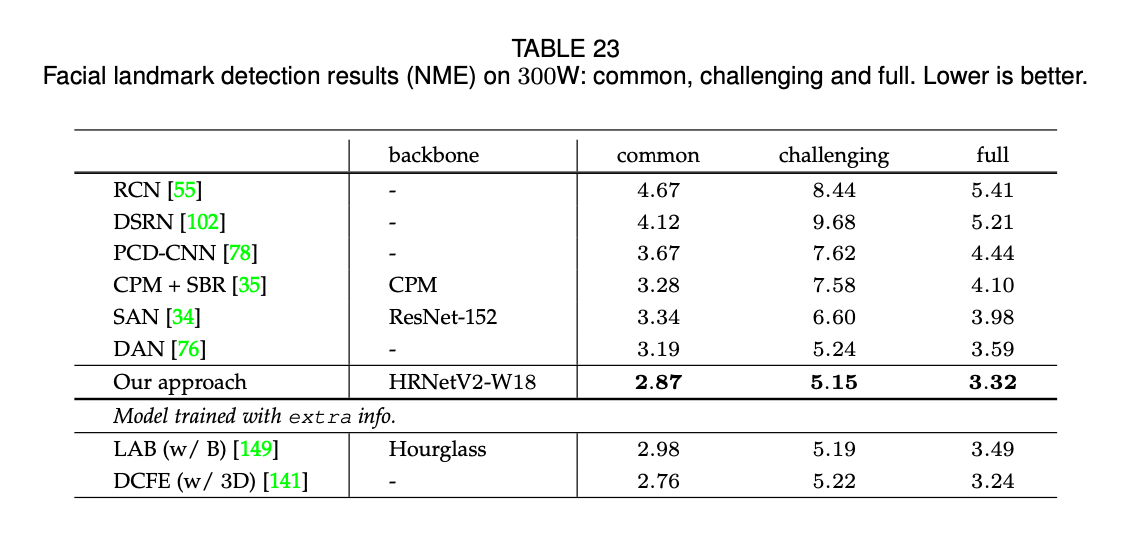
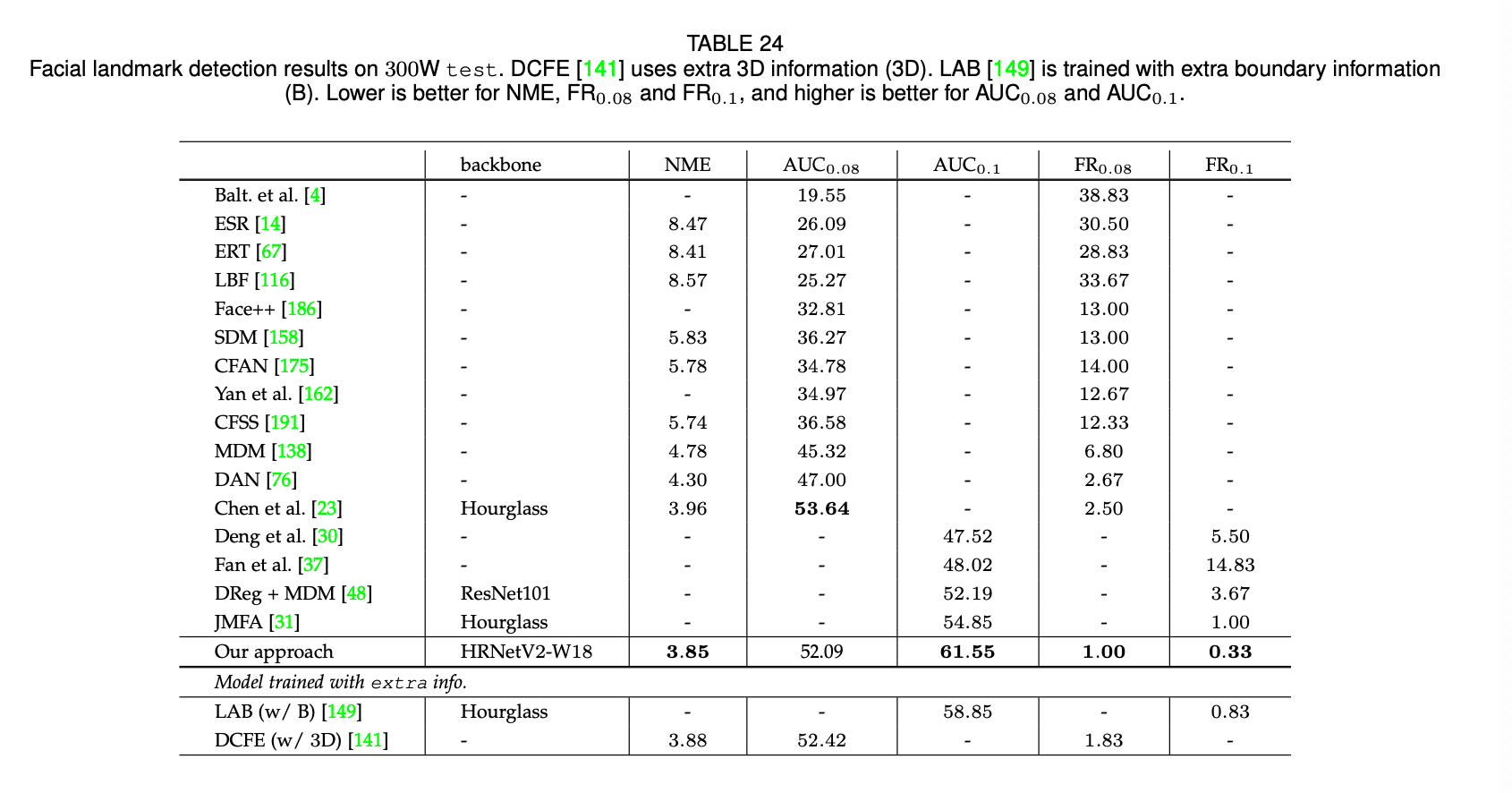
表23提供了在full set上的结果,分别评估了其在常见子集和挑战性子集上的性能。表24提供了在test set上的结果。和论文“Y. Chen, C. Shen, X. Wei, L. Liu, and J. Yang. Adversarial posenet: A structure-aware convolutional network for human pose estimation. In ICCV, pages 1221–1230, 2017.”中所用的方法相比,该论文使用了Hourglass作为backbone,参数量和计算复杂度都很大,我们的方法除了在$AUC_{0.08}$分数上略低于该论文的方法,在其余评估指标上都优于该论文的方法。对于没有使用额外信息和更强数据扩展的方法,HRNetV2的性能是最好的,甚至优于使用了额外边界信息的LAB和使用了额外3D信息的DCFE。
APPENDIX E : MORE OBJECT DETECTION AND INSTANCE RESULTS ON COCO VAL2017
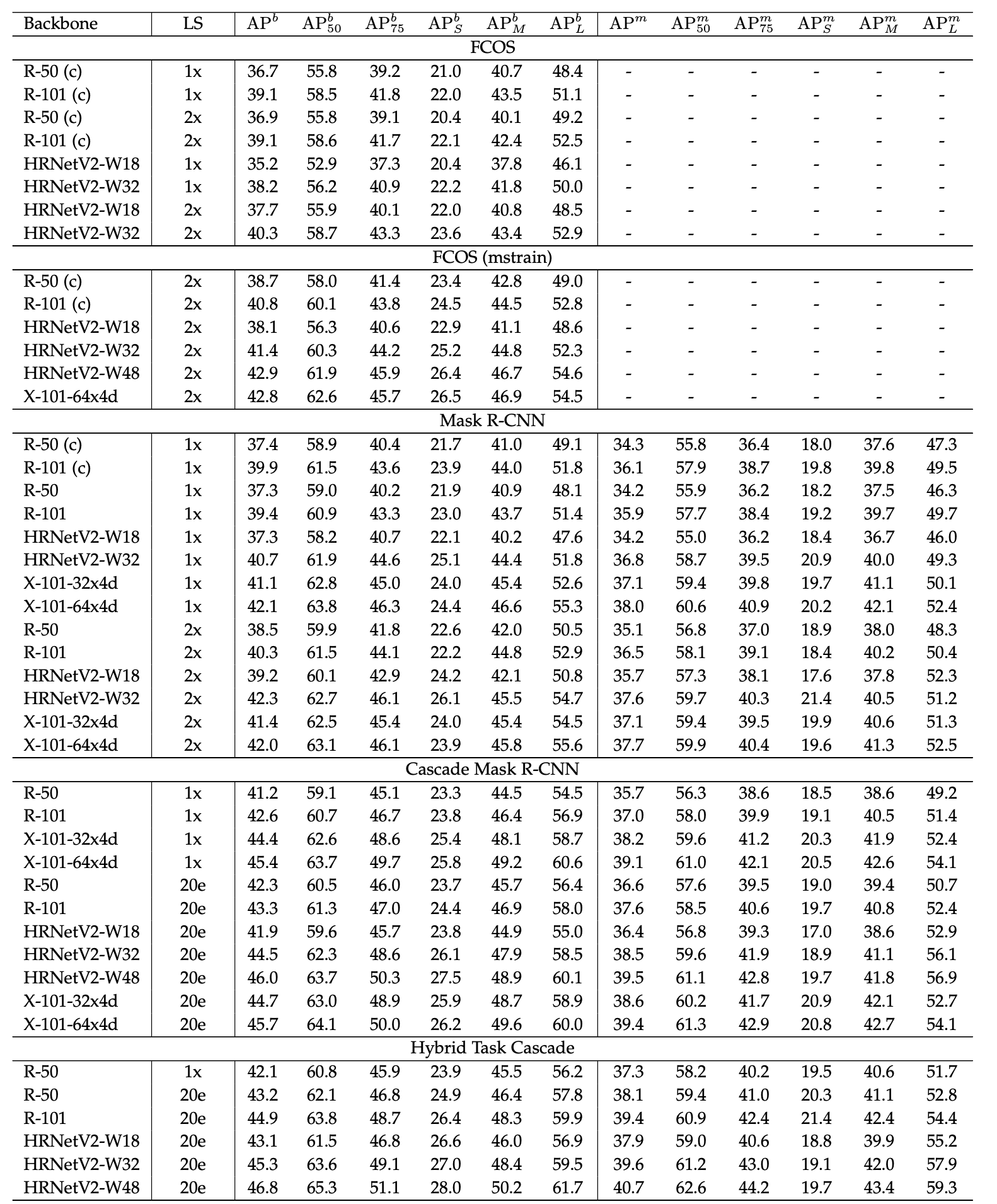
在COCO val上更多的目标检测和实例分割结果见表25。$AP^b$和$AP^m$分别指box mAP和mask mAP。除了HRNet的结果是在https://github.com/open-mmlab/mmdetection上运行代码获得的之外,大多数结果都来自论文“K. Chen, J. Wang, J. Pang, Y. Cao, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Xu, Z. Zhang, D. Cheng, C. Zhu, T. Cheng, Q. Zhao, B. Li, X. Lu, R. Zhu, Y. Wu, J. Dai, J. Wang, J. Shi, W. Ouyang, C. C. Loy, and D. Lin. Mmdetection: Open mmlab detection toolbox and benchmark. CoRR, abs/1906.07155, 2019.”。

10.原文链接
👽Deep High-Resolution Representation Learning for Visual Recognition
