本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
在2D Human Pose Estimation (HPE)领域中,基于2D heatmap的方法是绝对的主流。
尽管基于heatmap的方法取得了很大的成功,但是其存在着严重的量化误差,这是由将连续的坐标值映射到离散的二维下采样heatmap上引起的。这种量化误差带来了几个众所周知的缺点:
- 代价高昂的上采样层被用于增加feature map的分辨率以减轻量化误差。
- 额外的后处理来refine预测结果(比如:DARK)。
- 由于严重的量化误差,低分辨率输入的性能很差。
因为高分辨率的2D heatmap会带来高昂的计算成本,为了降低量化误差,有些研究采用的方法是将二维heatmap降低到一维,然后再提高其分辨率。但为了实现这一目的,网络框架也变得更为复杂,见Fig1。
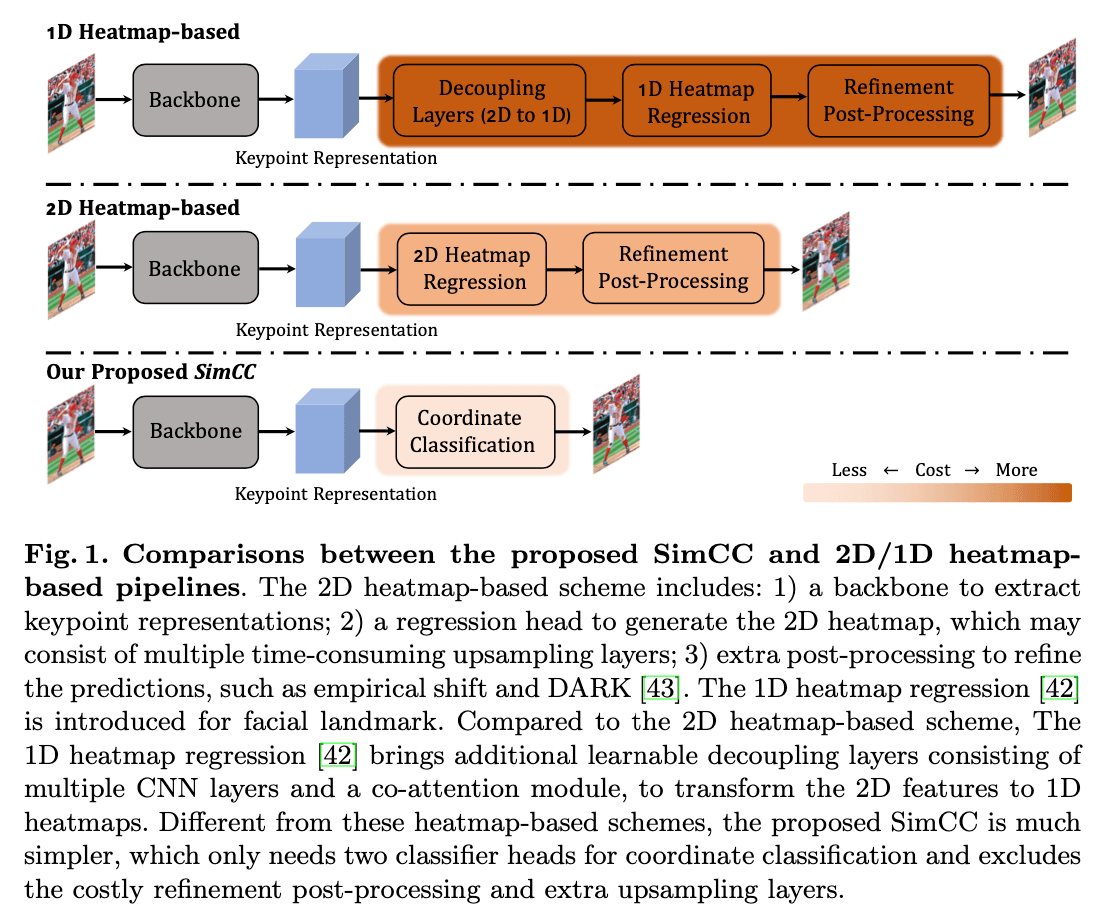
在Fig1中,基于2D heatmap的方法通常以下几部分:1)一个backbone用于提取keypoint representations;2)一个regression head用于产生2D heatmap,其中可能会包含多个耗时的上采样层;3)额外的后处理用于refine预测结果,比如empirical shift和DARK。和基于2D heatmap的方法相比,基于1D heatmap的方法添加了额外的可学习的解耦层(decoupling layer),该层由多个CNN层和一个co-attention模块组成,用于将2D特征转换成1D heatmap。与这些基于heatmap的方法不同,我们提出的SimCC要简单许多,它只需要两个分类器头(轻量级,每个头只需要一个线性层)用于坐标分类,并且没有使用昂贵的后处理和上采样操作。
SimCC的全称是Simple Coordinate Classification。SimCC将HPE视为两个分类任务,一个是横坐标的分类,一个是纵坐标的分类。SimCC首先需要部署一个基于CNN或基于Transformer的backbone用于提取keypoint representations。使用所获得的keypoint representations,SimCC分别独立的对横纵坐标进行坐标分类,以产生最终的预测结果。为了降低量化误差,SimCC将每个像素均匀地划分为多个bin,从而实现了亚像素级别的定位精度。
2.Related Work
不再赘述。
3.SimCC: Reformulating HPE from Classification Perspective
Fig2为SimCC的框架结构:
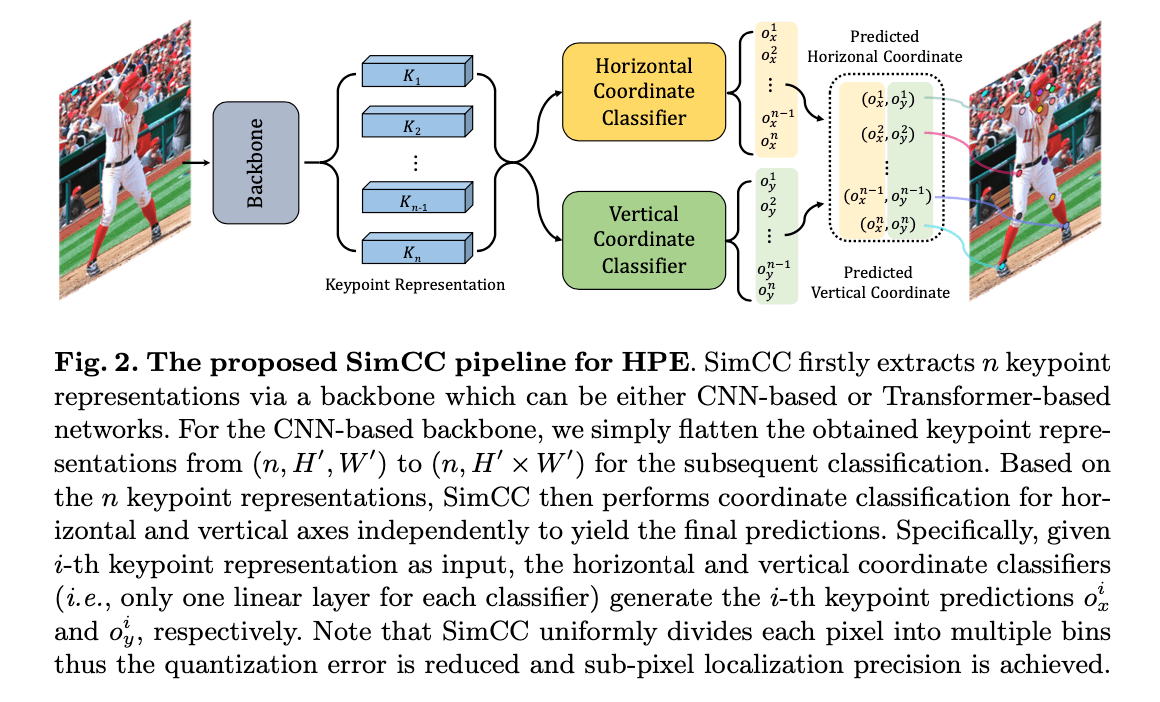
👉Backbone.
设输入图像大小为$H \times W \times 3$,其通过一个基于CNN或基于Transformer的backbone(比如:HRNet,TokenPose)得到$n$个keypoint representations,分别对应$n$个keypoint。
👉Head.
如Fig2所示,在backbone之后分别接了横纵坐标分类器(每个分类器只有一个线性层)来进行坐标分类。对于基于CNN的backbone,我们将其输出的keypoint representations的维度从$(n,H’,W’)$变为$(n,H’\times W’)$,然后再进行分类。
👉Coordinate classification.
为了实现分类,我们将每个连续坐标值统一离散为一个整数,作为模型训练的类标签:$c_x \in [1,N_x],c_y \in [1,N_y]$。其中,$N_x = W \cdot k,N_y=H\cdot k$,分别代表水平轴和垂直轴的bin数量。$k$是分割因子(splitting factor),设置$k \geqslant 1$来降低量化误差,从而实现亚像素级别的定位精度。
说下自己的理解,这段主要是在说怎么做训练标签。如下图所示,假设这张图大小为$H=W=3$,我们设$k=2$,则横纵坐标轴各分成6个bin,即$N_x = N_y =6$。红色点为keypoint的GT,在不分bin的情况下坐标为$(1,1)$,分完bin后坐标为$(c_x,c_y)=(3,3)$,相比之前,会更精细。这样预测得到的坐标也是亚像素级别的了。
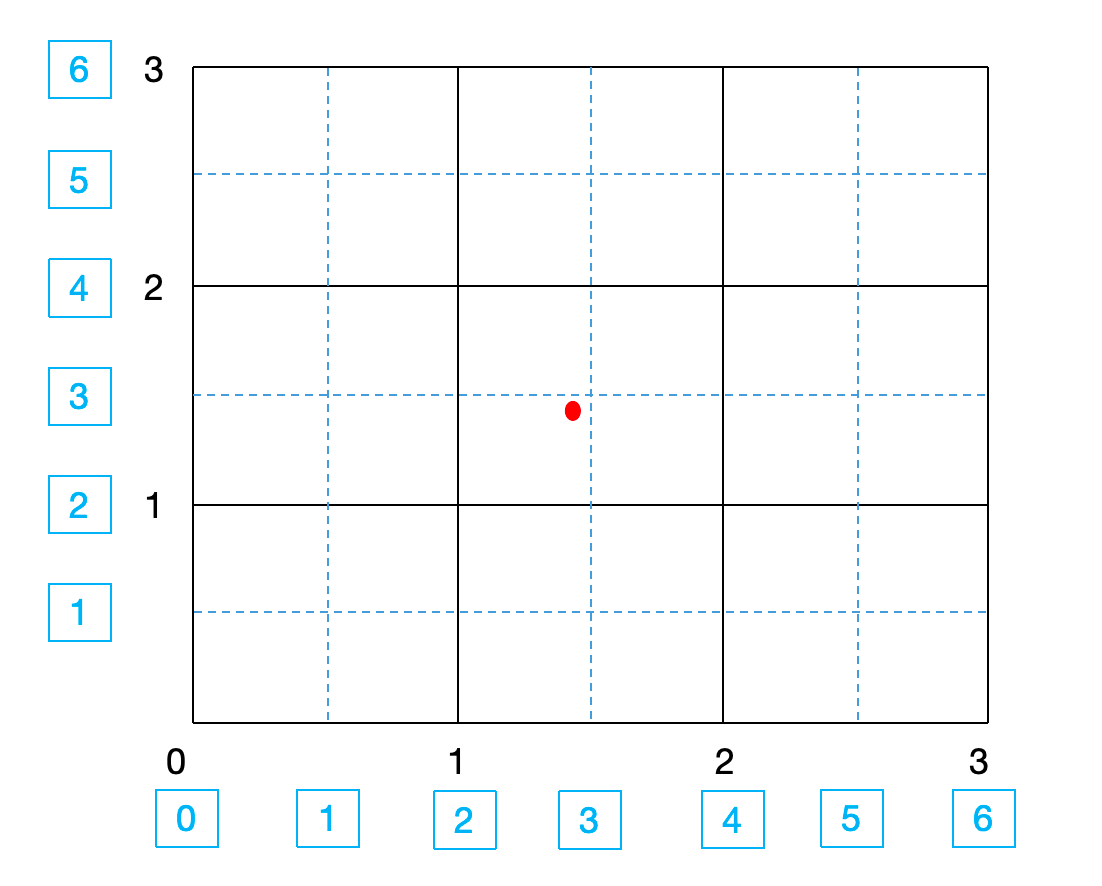
然后说下坐标分类器,其实就是一个线性层,对于第$i$个keypoint representation(长度为$(H’ \times W’)$),在经过横坐标分类器后得到$o_x^i$,在经过纵坐标分类器后得到$o_y^i$。$(o_x^i,o_y^i)$即为第$i$个keypoint的预测结果。此外,训练的损失函数为KL散度。
👉Label smoothing.
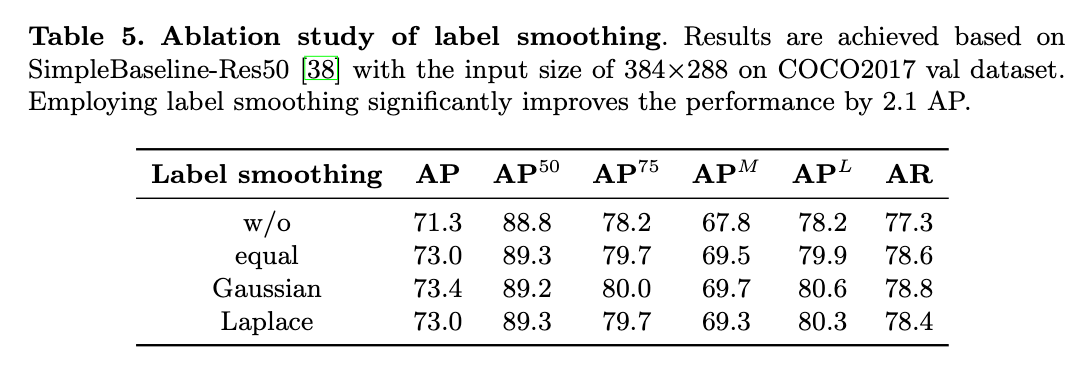
在传统的分类任务中,label smoothing常被用来提升模型性能。因此我们也将其应用到了SimCC,在本文中我们将其称之为equal label smoothing。但是equal label smoothing不加区别的,即平等的惩罚错误标签,忽略了相邻标签在HPE任务中的空间相关性(个人理解:这里的标签其实就是坐标,照理来说,对GT附近的点的惩罚力度不应该和离GT很远的点的惩罚力度一样)。为了解决这个问题,我们探索了基于Laplace或Gaussian的label smoothing。除非特殊说明,SimCC默认使用equal label smoothing。
3.1.Comparisons to 2D heatmap-based approaches
👉Quantization error.
如果heatmap保持和输入(通常分辨率较高)一样的大小,会使得计算成本巨大,因此基于2D heatmap的方法通常将输入进行$\lambda$次下采样,而这也放大了量化误差。相反,SimCC将每个像素均匀地划分为$k(\geqslant 1)$个bin,这降低了量化误差,并获得了亚像素级别的定位精度。
👉Refinement post-processing.
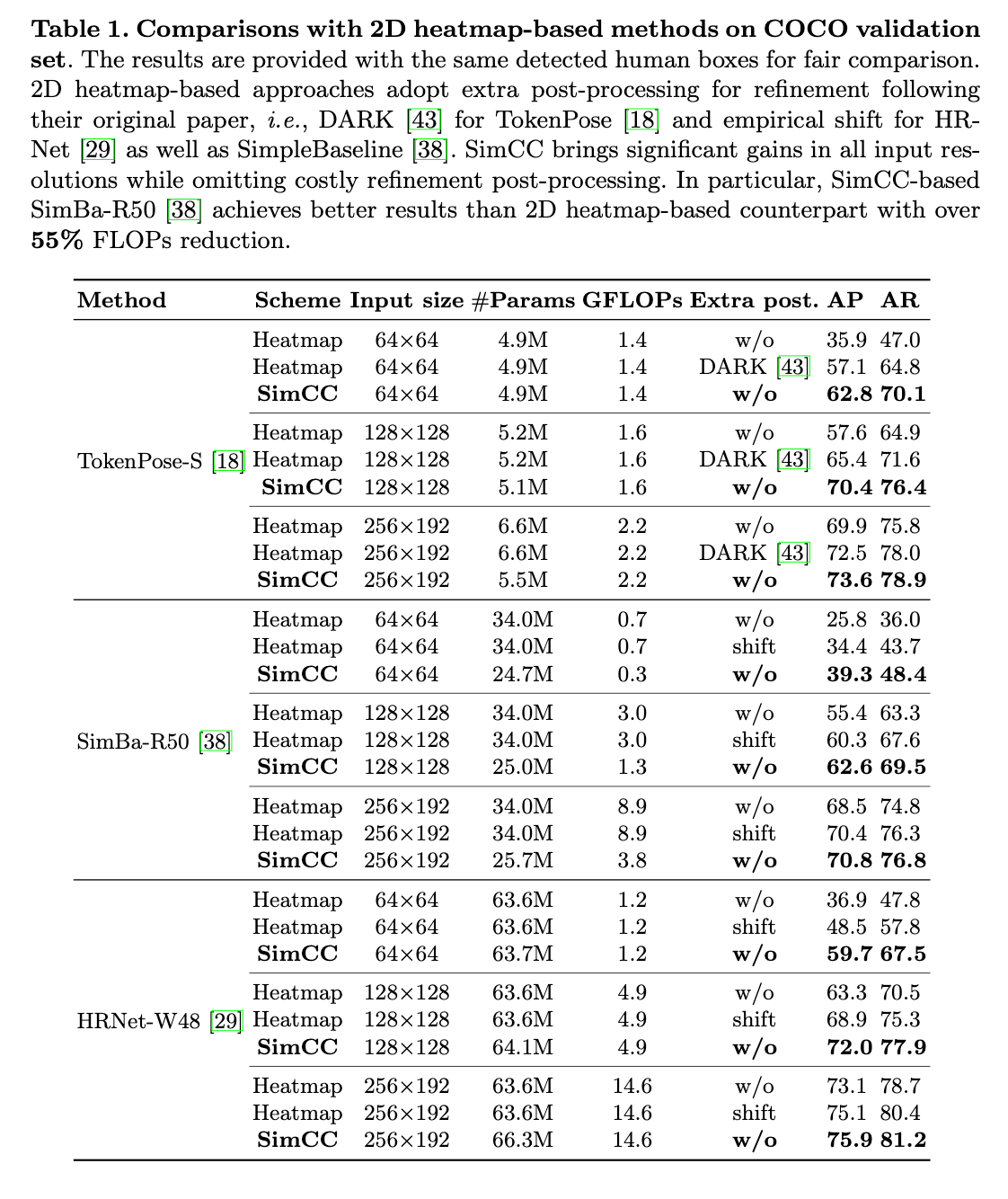
基于heatmap的方法非常依赖额外的后处理(比如empirical shift和DARK)来降低量化误差。如表1所示,如果去掉后处理,基于heatmap的方法性能严重下降。并且这些后处理通常计算成本都很高。相比之下,SimCC则省略了后处理。
👉Low/high resolution robustness.
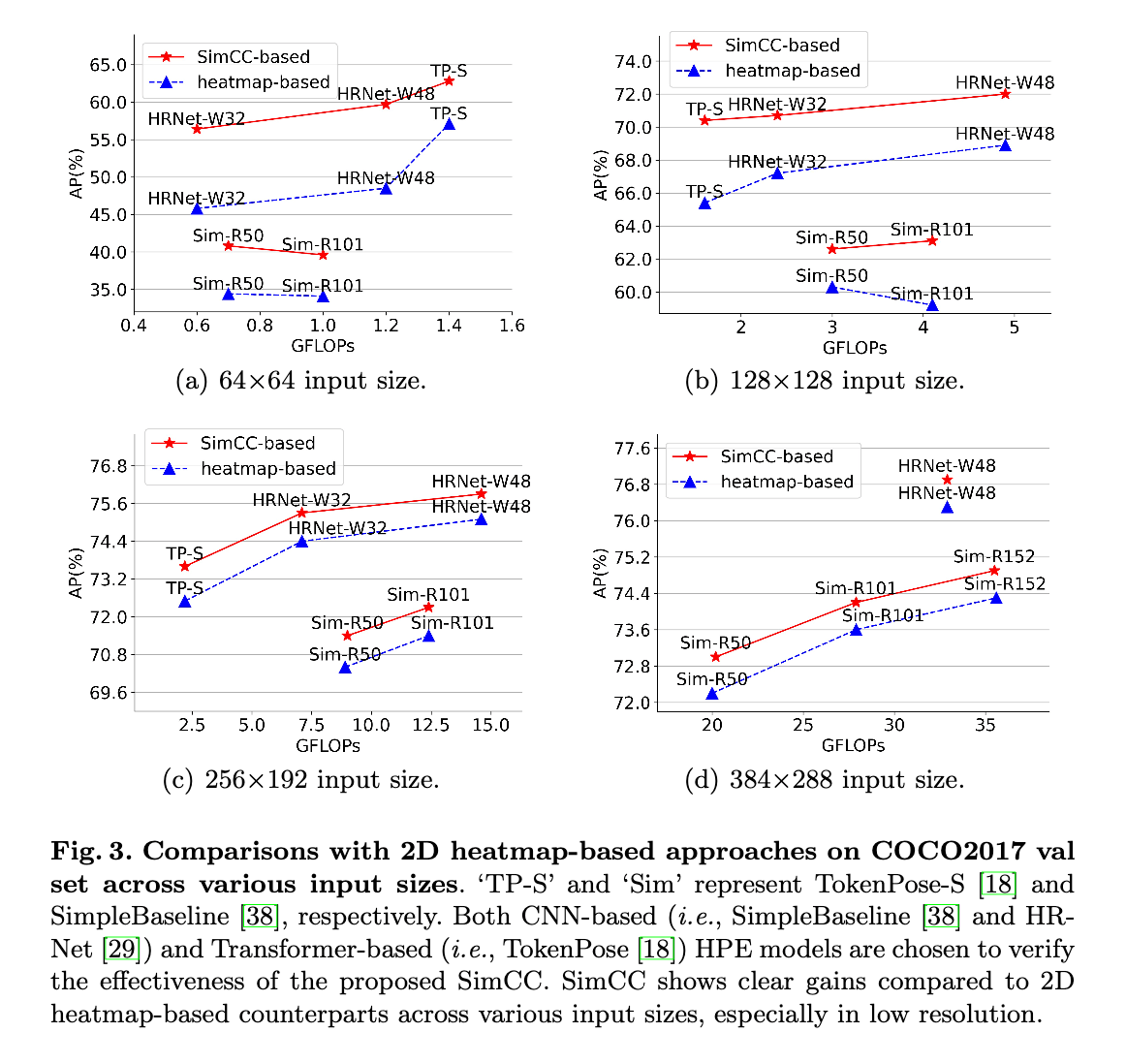
可视化比较结果见Fig3。因为更低的量化误差,所以在同等分辨率下,基于SimCC的方法明显优于基于heatmap的方法,尤其是低分辨率的情况。
👉Speed.
SimCC省去了反卷积模块,这加快了推理速度。
4.Experiments
我们在3个benchmark数据集上进行了测试:COCO,CrowdPose和MPII。
4.1.COCO Keypoint Detection
使用的数据集和数据扩展方式都和HRNet一样。
👉Evaluation metric.
评估指标使用OKS。
👉Baselines.
我们选择了最近SOTA的一些方法作为baseline,基于CNN的方法选择SimpleBaseline和HRNet,基于Transformer的方法选择TokenPose。
👉Implementation details.
对于这些baseline方法,我们都遵循原始论文中的setting。对于SimpleBaseline,基础学习率设为$1e-3$,然后在第90和第120个epoch时降为$1e-4$和$1e-5$,一共训练140个epoch。对于HRNet,基础学习率设为$1e-3$,在第170和第200个epoch时降为$1e-4$和$1e-5$,一共训练210个epoch。需要注意的是,TokenPose-S的训练遵循HRNet。本文使用two-stage自上而下的pipeline:先检测人物实例,再检测keypoint。模型训练使用了label smoothing(equal label smoothing的平滑因子默认设为0.1)。实验使用了4块NVIDIA Tesla V100 GPU。
👉Results on the COCO val set.
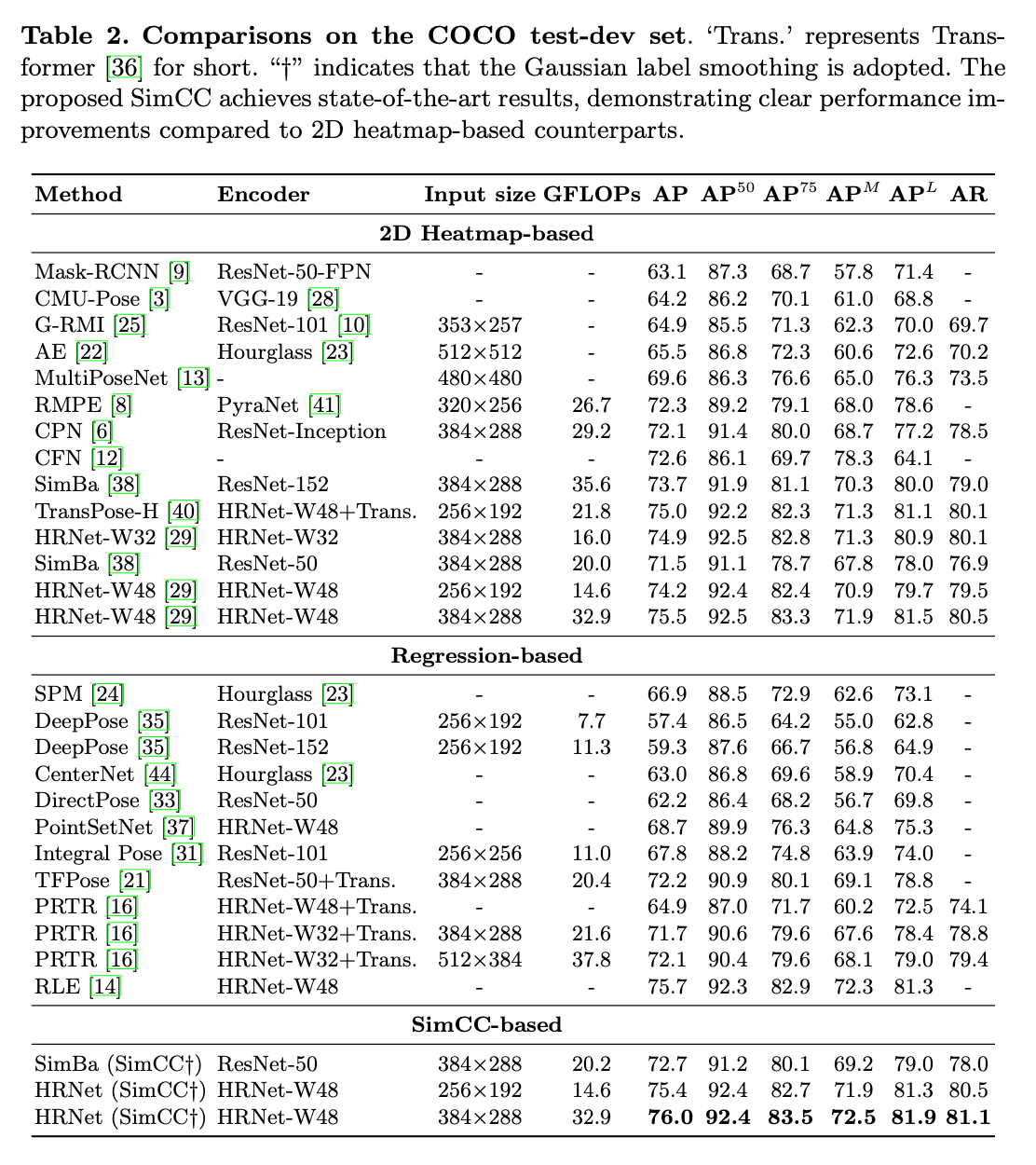
👉Results on the COCO test-dev set.
👉Inference speed.
我们测试了300个样本的平均推理速度。测试所用的CPU均为Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz。
- SimpleBaseline:使用SimpleBaseline-Res50模型,输入图像大小为$256 \times 192$,基于SimCC的版本AP提升了0.4(70.8 vs. 70.4),速度提升了23.5%(21 vs. 17 FPS)。
- TokenPose&HRNet:因为SimpleBaseline使用的是encoder-decoder框架,所以我们可以直接把它的decoder部分(反卷积)替换为SimCC的分类器头。但是HRNet和TokenPose没有类似decoder的额外独立模块。因此,对于HRNet,我们直接把分类器头接在了原始框架的后面,而对于TokenPose,我们则把MLP head替换为了SimCC。这些修改相对于原始框架都非常小,对于HRNet,计算成本仅仅有一点点的提高,而对于TokenPose,模型参数量甚至减少了(见表1)。因此,SimCC所带来的对推理速度的影响并不明显。比如以HRNet-W48为例,输入图像大小为$256 \times 192$,heatmap和SimCC的推理速度分别为4.5 FPS和4.8 FPS。
👉Is 1D heatmap regression a promising solution for HPE?

4.2.Ablation Study
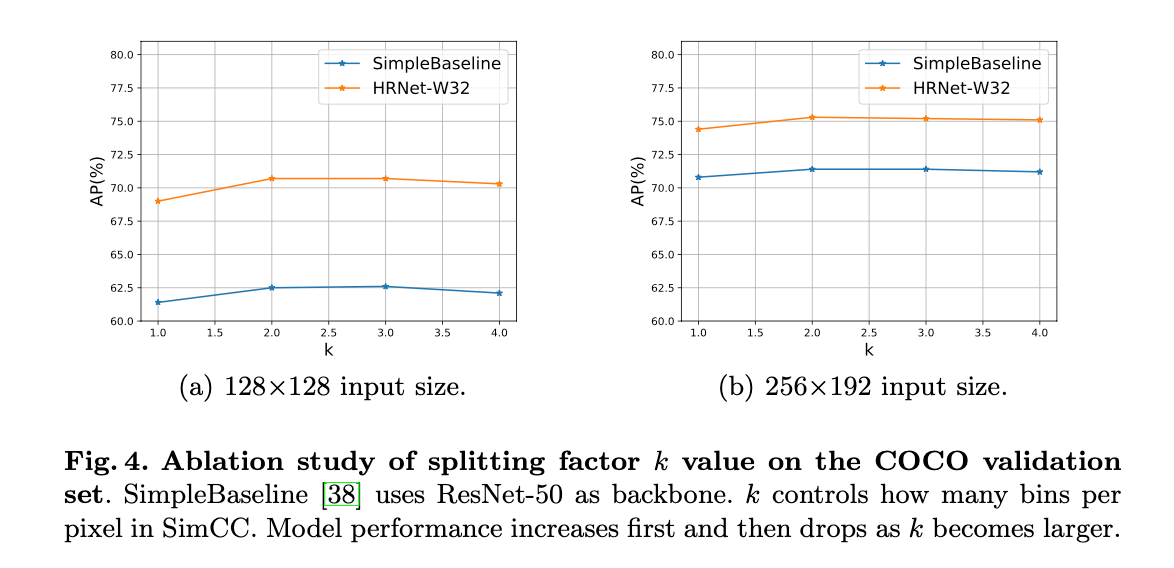
👉Splitting factor k.
$k$越大,SimCC的量化误差越小。但是,随着$k$的变大,模型训练也变得越来越困难。因此我们取不同的$k$值进行了实验,见Fig4。
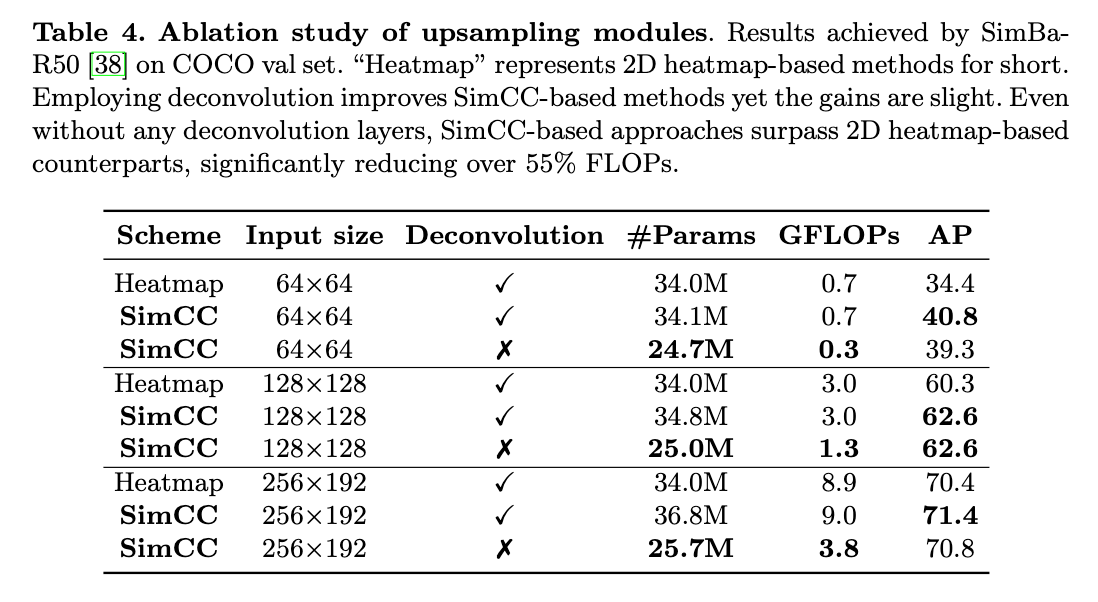
👉Upsampling modules.
基于SimpleBaseline框架,我们测试了SimCC搭配上采样和省去上采样的性能。表4是在COCO 2017 val数据集上的测试结果。
👉Label smoothing.
不同标签平滑方式的测试结果见表5。
4.3.CrowdPose
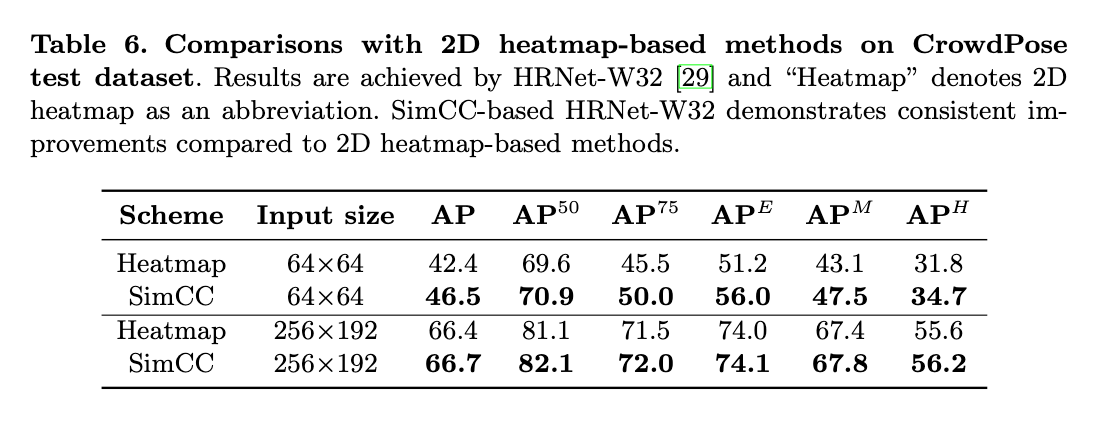
CrowdPose数据集包含20K张图像和80K个人物实例,相比COCO数据集,其场景内人物更多更密集。训练集、验证集和测试集分别包含10K、2K和8K张图像。评估指标和COCO一样,额外的,$AP^E$是简单样本的AP值,$AP^H$是困难样本的AP值。人物检测的模型使用YoloV3,batch size=64。在CrowdPose数据集上的测试结果见表6。
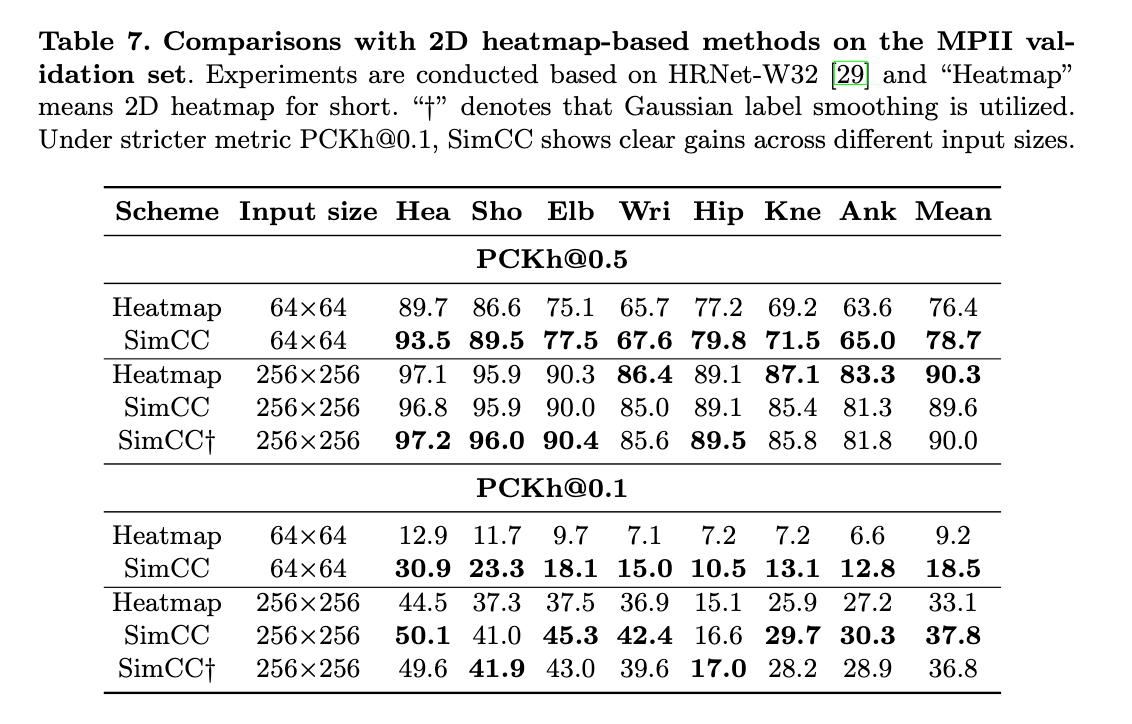
4.4.MPII Human Pose Estimation
MPII Human Pose数据集包含40K个人物样本,每个人有16个关节点标签。采用和COCO数据集一样的数据扩展方式。
👉Results on the validatoin set.
5.Limitation and Future Work
不再详述。
6.Conclusion
不再详述。
7.原文链接
👽SimCC:a Simple Coordinate Classification Perspective for Human Pose Estimation
