本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
当前SOTA的目标检测方法,均是以下流程的变体:
- 首先生成候选bbox;
- 对每个box内的像素或特征进行重采样;
- 然后应用高质量的分类器。
这种方法虽然精度高,但它们对计算资源的需求过大,很难满足实时性的要求。目前已经有很多研究对流程的各个阶段进行加速,但至今为止,显著提升速度往往都要以大幅降低检测精度为代价。
2.The Single Shot Detector (SSD)
2.1.Model
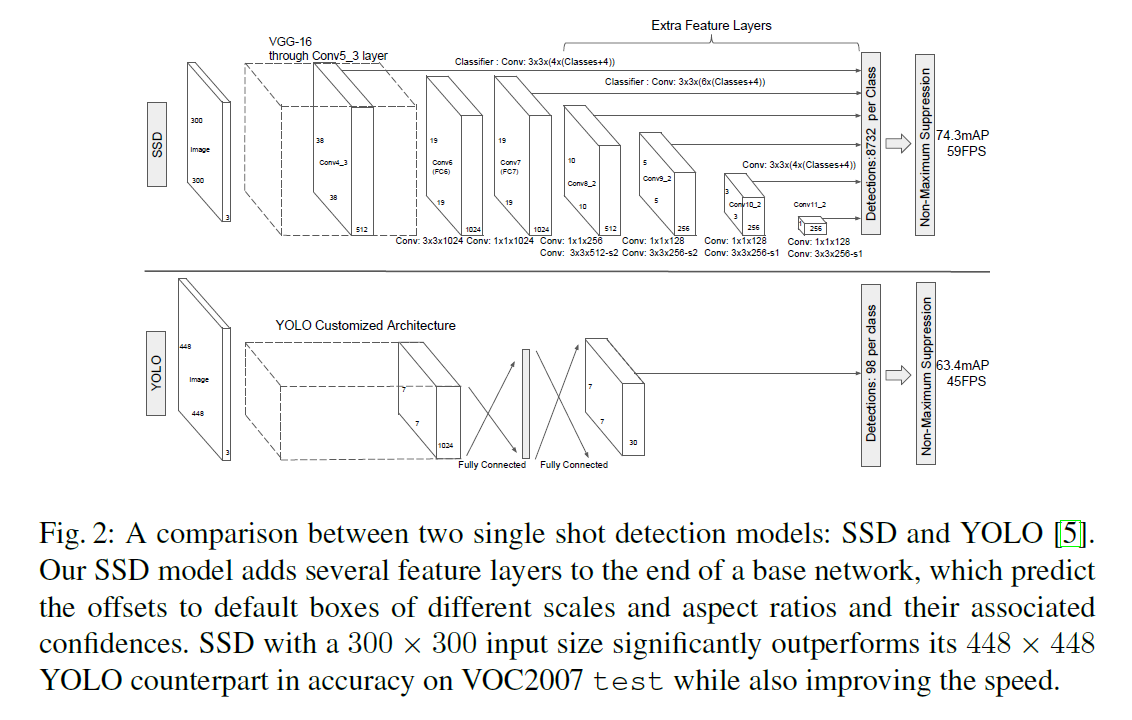
SSD的网络结构如Fig2所示,有如下特点:
- 使用VGG16作为base网络,当然也可使用其他base网络。
- 在base网络的末端添加了额外的卷积层,随着网络的加深,feature map的尺寸越来越小。
- 应用了多尺度feature map进行预测。
- 在如Fig2所示的SSD结构中:
- Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2参与了最终的预测。
- Conv4_3、Conv10_2和Conv11_2中每个点设置4个anchor,剩余的其他预测层默认每个点设置6个anchor。
- 对于所有参与预测的卷积层来说,其feature map的大小为$m \times n \times p$($p$为通道数),所用的卷积核大小为$f \times f \times p$(在Fig2中,$f=3$),所用的卷积核数量,也就是输出通道数为$k(c+4)$($k$为每个点设置的anchor个数、$c$为类别数,$4$为bbox的偏移量,如Fig1所示)。
- 以Conv4_3为例,可以得到$38 \times 38 \times 4 = 5776$个预测bbox。所以我们可以计算最终一共能得到的预测bbox的数量为:
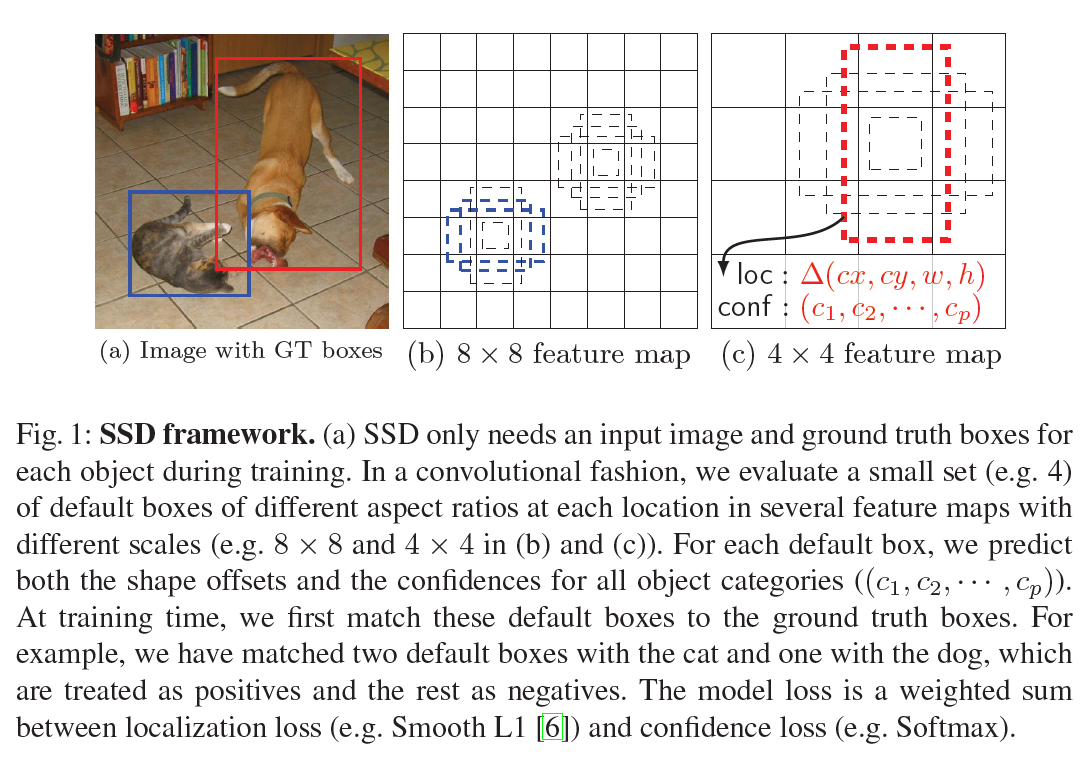
如Fig1所示,在训练阶段,我们首先需要将anchor box和GT box进行匹配,以区分正负样本。如Fig1(b)所示,猫对应的两个蓝色anchor box被判定为正样本。如Fig1(c)所示,狗对应的一个红色anchor box被判定为正样本。模型损失函数是定位损失(比如Smooth L1)和置信度损失(比如Softmax)的加权和。
2.2.Training
Matching strategy
如果anchor box和任意GT box的IoU大于0.5,则视为正样本。
Training objective
$x_{ij}^p=\{1,0 \}$表示对于类别$p$,第$i$个anchor box和第$j$个GT box是否匹配(即IoU是否大于0.5),如果匹配成功,则值为1,否则值为0。对于类别$p$的第$j$个GT box,至少匹配一个anchor box,即有:
\[\sum_i x_{ij}^p \geqslant 1\]模型损失函数为:
\[L(x,c,l,g) = \frac{1}{N} \left( L_{conf} (x,c) + \alpha L_{loc} (x,l,g) \right) \tag{1}\]$N$是正样本的数量。如果$N = 0$,则损失为0。$l$表示预测的bbox,$g$表示GT box。定位损失使用Smooth L1:
\[L_{loc}(x,l,g) = \sum_{i \in Pos}^N \sum_{m \in \{ cx,cy,w,h \}} x_{ij}^k \text{smooth}_{\text{L1}} (l_i^m - \hat{g}_j^m) \\ \hat{g}_j^{cx}=(g_j^{cx}-d_i^{cx})/d_i^w \quad \hat{g}_j^{cy}=(g_j^{cy}-d_i^{cy})/d_i^h \\ \hat{g}_j^w = \log \left( \frac{g_j^w}{d_i^w} \right) \quad \hat{g}_j^h = \log \left( \frac{g_j^h}{d_i^h} \right) \tag{2}\]置信度损失的计算:
\[L_{conf}(x,c) = -\sum_{i \in Pos}^N x_{ij}^p \log (\hat{c}_i^p) - \sum_{i \in Neg} \log (\hat{c}_i^0) \quad \text{where} \ \hat{c}_i^p = \frac{\exp (c_i^p)}{ \sum_p \exp (c_i^p)} \tag{3}\]权重项$\alpha = 1$。
Choosing scales and aspect ratios for default boxes
假设我们使用$m$个feature map进行预测,对于每个feature map,我们按照如下公式来设置anchor box的尺度:
\[s_k = s_{min} + \frac{s_{max}-s_{min}}{m-1} (k-1), \quad k \in [1,m] \tag{4}\]其中,$s_{min}=0.2,s_{max}=0.9$,也就是说,第1个用于预测的feature map,我们将anchor box的尺度设为0.2,第$m$个用于预测的feature map,我们将anchor box的尺度设为0.9。除了不同尺度,我们还考虑到了不同长宽比:$a_r \in \{ 1,2,3,\frac{1}{2},\frac{1}{3} \}$。通过如下公式计算每个anchor box的大小:
\[w_k^a = s_k \sqrt{a_r} \quad h_k^a = s_k / \sqrt{a_r}\]当$a_r = 1$时,对该anchor box新增一个尺度$s_k’=\sqrt{s_k s_{k+1}}$,因此,对于feature map上的一个像素位来说,一共有6个anchor box。每个anchor box的中心点为:
\[(\frac{i+0.5}{\lvert f_k \rvert},\frac{j+0.5}{\lvert f_k \rvert})\]其中,$\lvert f_k \rvert$是第$k$个feature map的大小,且有$i,j \in [0,\lvert f_k \rvert)$。
Hard negative mining
由于很多anchor box都属于负样本,从而造成了正负样本不平衡的情况。为了解决这个问题,我们将所有负样本按照置信度损失从高到底进行排序,按照正负样本为1:3的比例选择置信度损失最高的一些负样本。我们发现这样做能更快的收敛并且训练也更加平稳。
Data augmentation
每张训练图像随机选择以下一种数据扩展方式:
- 使用整个原始图像。
- 取一个和目标的IoU至少为0.1、0.3、0.5、0.7或0.9的一个patch。
- 随机取一个patch。
每个patch的大小是原始图像大小的$[0.1,1]$(随机取值),且长宽比在$\frac{1}{2}$到$2$之间。如果某个GT box的中心落在patch内,则仅保留该GT box与patch的重叠部分。最后,每个patch被resize到固定大小,并有50%的几率被水平翻转,此外,还会施加一些类似于文章“Howard, A.G.: Some improvements on deep convolutional neural network based image classification. arXiv preprint arXiv:1312.5402 (2013)”中所述的光度畸变操作。
3.Experimental Results
Base network
我们的所有实验都基于在ILSVRC CLS-LOC数据集上预训练过的VGG16。在fine-tune阶段,使用SGD,初始学习率为$10^{-3}$,momentum为0.9,weight decay为0.0005,batch size为32。不同数据集使用不同的学习率衰减策略。原始的训练和测试代码基于Caffe实现,地址为https://github.com/weiliu89/caffe/tree/ssd。
3.1.PASCAL VOC2007
我们在VOC2007 test数据集(4952张图像)上,和Fast R-CNN以及Faster R-CNN进行了比较。所有方法都基于同样的预训练VGG16网络。
SSD300模型的框架见Fig2。我们使用conv4_3、conv7(fc7)、conv8_2、conv9_2、conv10_2和conv11_2来预测bbox的位置和置信度。鉴于conv4_3的特征值量级和其他预测层不一致,这会影响收敛速度和检测效果,所以对于conv4_3,我们在每个空间位置上,沿通道方向进行了L2归一化,之后再乘上一个常量系数,这样使得特征值都在20左右。此外,将conv4_3的尺度单独设为0.1,其余预测层按照式(4)设置尺度。对于SSD512模型,我们额外添加了conv12_2用于预测,设置$s_{min}$等于0.15,将conv4_3的尺度单独设为0.07。新添加的卷积层的参数都使用xavier初始化。对于conv4_3、conv10_2和conv11_2,忽略了长宽比$\frac{1}{3}$和$3$,所以feature map的每个像素点只设置了4个anchor box。对于其他预测层,设置默认的6个anchor box。前40k次迭代使用$10^{-3}$的学习率,接下来分别使用$10^{-4}$和$10^{-5}$的学习率再各训练10k次迭代。
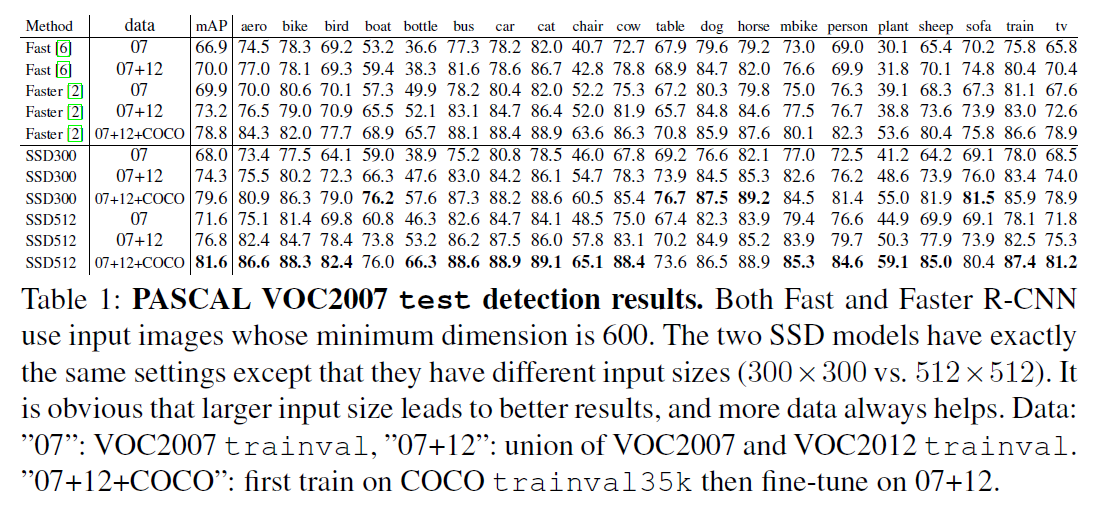
SSD300指的是输入图像尺寸为$300 \times 300$,SSD512指的是输入图像尺寸为$512 \times 512$。
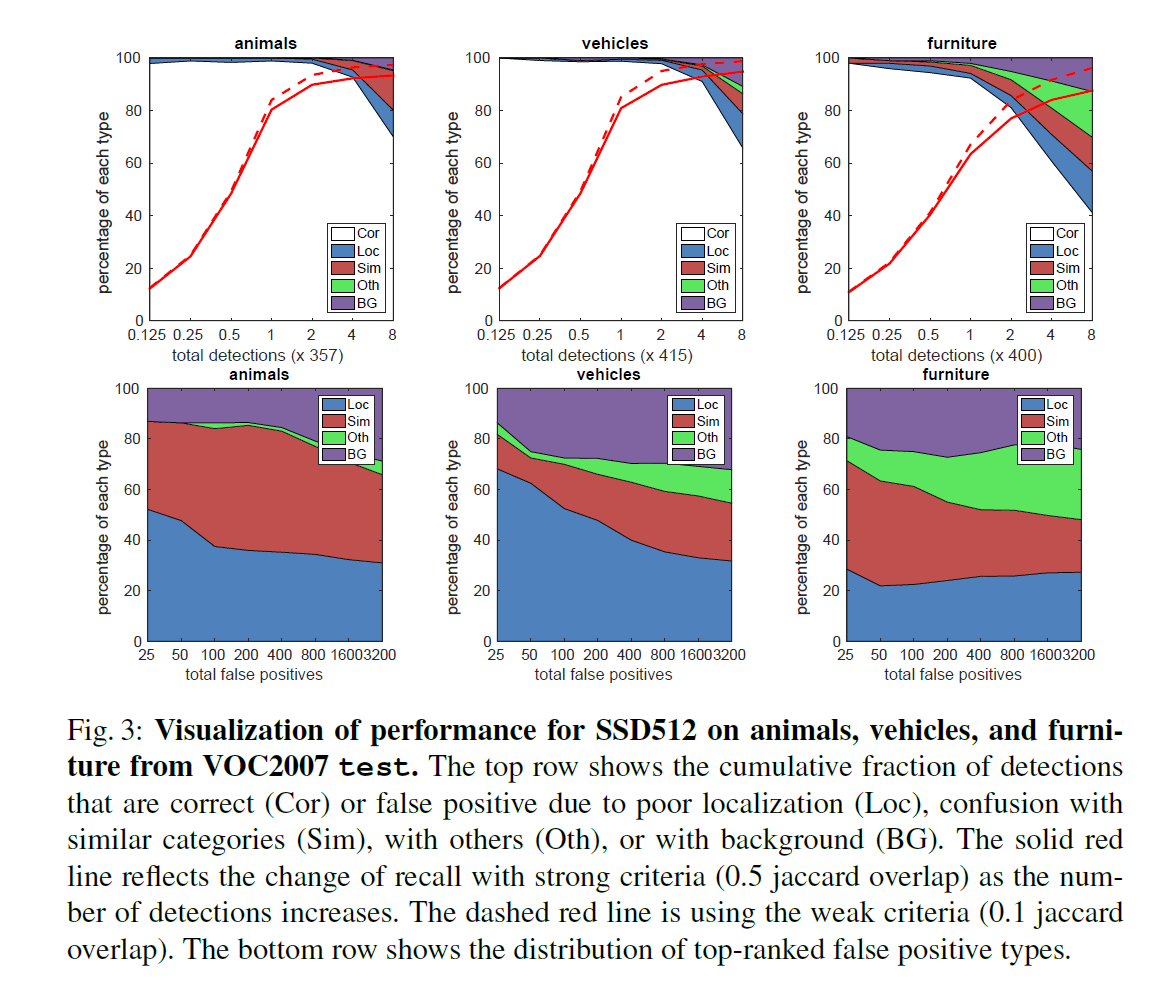
Fig3是对预测性能和错误类型的可视化分析,这里只列出了animals、vehicles和furniture三个类别的分析结果。
先看第一行,以第一行第一列为例,animals这个类别一共标注了357个GT box,通过设置概率阈值,判定为animals类别的预测bbox数量会发生变化,横轴从左到右相当于是把概率阈值从高变低,从而使得判定为animals类别的预测bbox越来越多。比如,横轴的0.125就表示约有$357 \times 0.125 \approx 45$个预测bbox被判定为了animals类别。图例中的Cor表示预测正确的bbox(类别和位置均预测正确),Loc表示类别预测正确但位置不准确的bbox(即和GT box的IoU过低),Sim表示bbox被错误预测为了其他相似的类别,Oth表示bbox被错误预测为了完全不相关的类别,BG表示bbox被错误预测为了背景。从图中可以看出,随着增加预测为animals类别的bbox的数量,各种类型的错误数量也随之增加。图中红色实线为IoU阈值为0.5时的recall曲线,红色虚线为IoU阈值为0.1时的recall曲线。图的纵轴表示百分比。
再看第二行,以第二行第一列为例,横轴表示不同数量的假阳,纵轴表示不同错误类型占据的比例。
从Fig3的第一行可以看出,大量的白色区域表示SSD对各种目标类别都有很不错的检测能力。与R-CNN相比,SSD的Loc错误更少,但Sim错误更多。
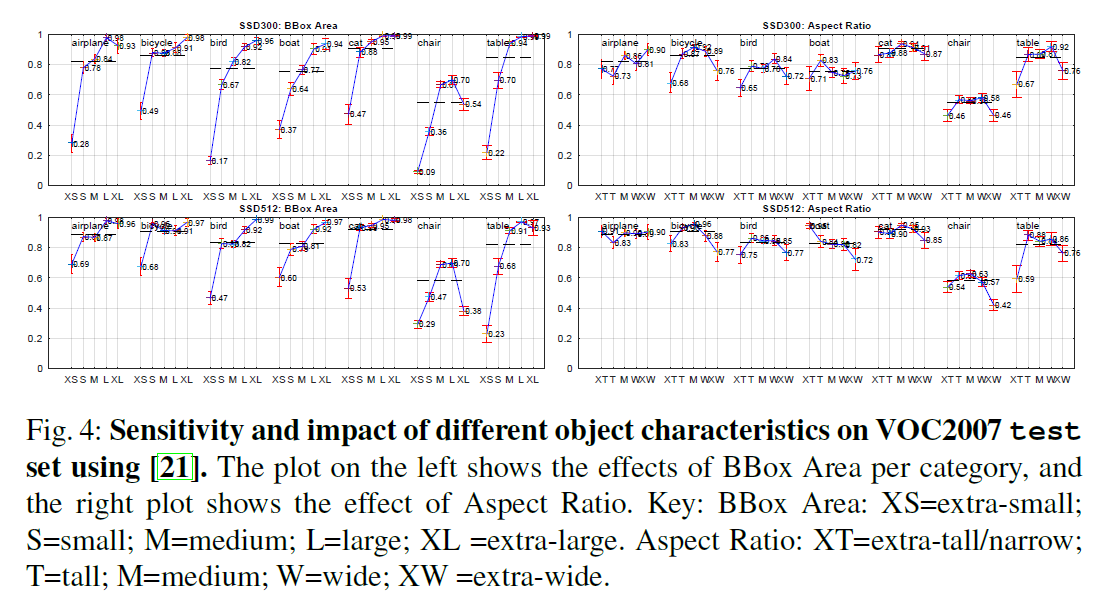
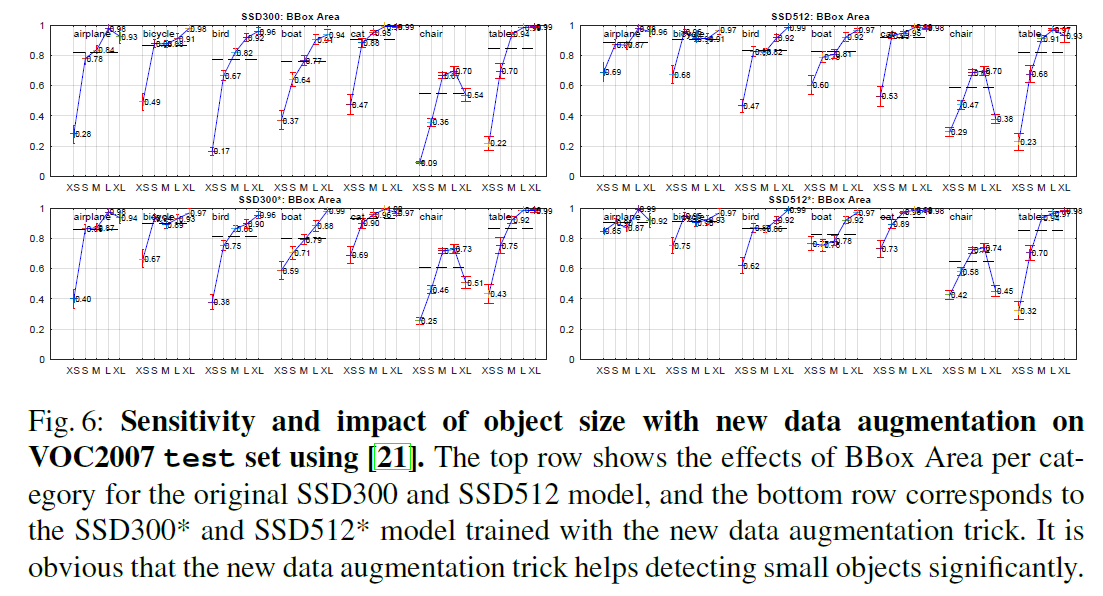
从Fig4可以看出,SSD对bbox的尺寸非常敏感。相比大尺寸目标,其在小尺寸目标上的表现更差。
3.2.Model analysis

“use atrous”指的是是否使用空洞卷积。

3.3.PASCAL VOC2012
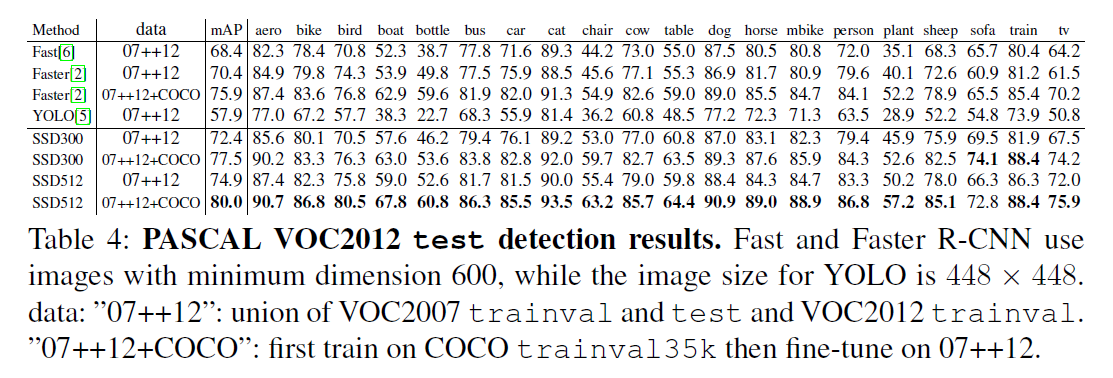
在SSD训练阶段,前60k次迭代使用$10^{-3}$的学习率,后20k次迭代使用$10^{-4}$的学习率。对于SSD512模型,添加额外的conv12_2用于预测,设置$s_{min}=0.1$,将conv4_3的尺度单独设置为0.04。
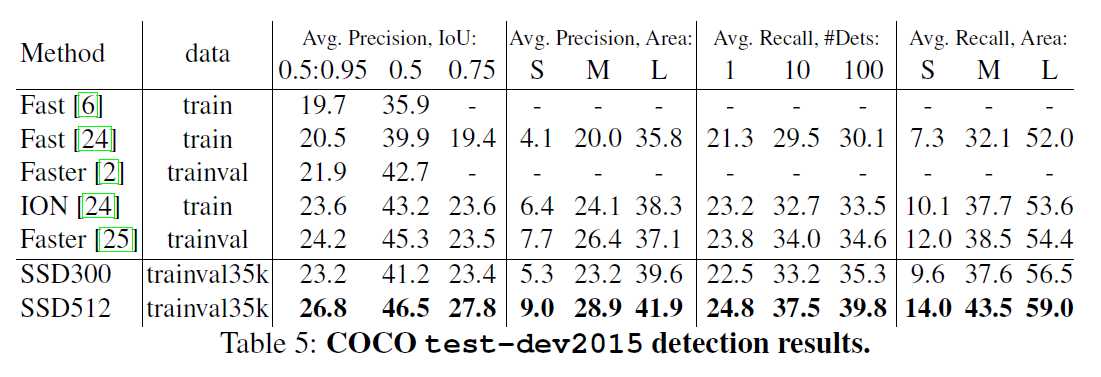
3.4.COCO
为了进一步验证SSD框架,我们在COCO数据集上对SSD300和SSD512进行了训练。因为COCO数据集中的目标尺寸要比PASCAL VOC小,所以我们使用了更小的anchor box。我们遵循第2.2部分提到的策略,但是将最小尺度从0.2降低到了0.15,将conv4_3的尺度单独设置为0.07(即对于$300 \times 300$的图像来说,大约是21个像素)。此外,对于SSD512模型,添加额外的conv12_2用于预测,并设置$s_{min}=0.1$,将conv4_3的尺度单独设置为0.04。
使用trainval35k作为训练集。前160k次迭代的学习率为$10^{-3}$,接下来40k次迭代的学习率为$10^{-4}$,再接下来40k次迭代的学习率为$10^{-5}$。

3.5.Preliminary ILSVRC results
在ILSVRC DET数据集上也进行了测试,在此不再详述。
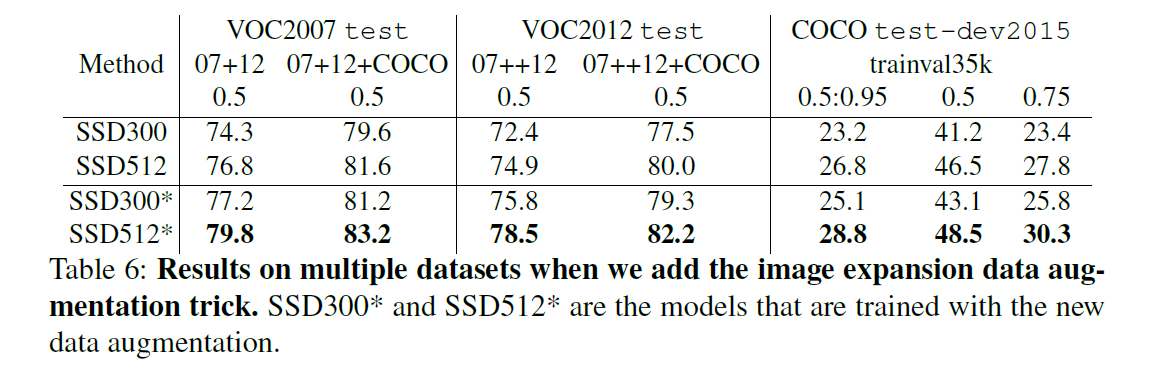
3.6.Data Augmentation for Small Object Accuracy
为了提升在小尺寸目标上的预测精度,我们采用了一种新的数据扩展方式,具体做法是将原始图像放置在一个大小为原图16倍、以均值填充的画布上,然后再执行随机裁剪。这一扩展方式也使得训练样本数量翻倍,因此我们也将训练迭代次数加倍。
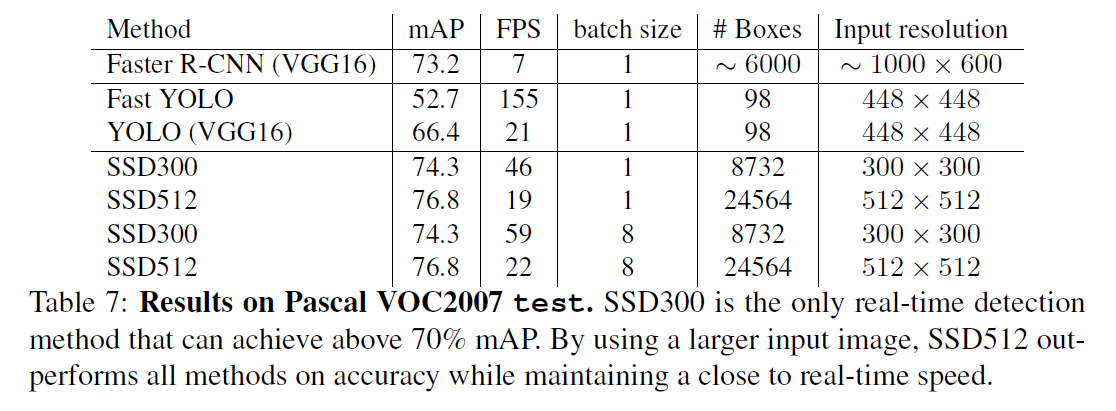
3.7.Inference time
鉴于SSD会产生大量的候选框,因此在推理阶段必须高效的执行NMS。首先使用置信度阈值0.01来过滤掉大多数候选框,然后对每个类别以IoU大于0.45进行NMS,并保留每张图像得分最高的200个检测结果。
4.Related Work
不再详述。
5.Conclusions
不再详述。
