【机器学习基础】系列博客为参考周志华老师的《机器学习》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.任务与奖赏
图16.1给出了强化学习的一个简单图示。强化学习任务通常用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述:机器处于环境$E$中,状态空间为$X$,其中每个状态$x \in X$是机器感知到的环境的描述,如在种瓜任务上这就是当前瓜苗长势的描述;机器能采取的动作构成了动作空间$A$,如种瓜过程中有浇水、施不同的肥、使用不同的农药等多种可供选择的动作;若某个动作$a \in A$作用在当前状态$x$上,则潜在的转移函数$P$将使得环境从当前状态按某种概率转移到另一个状态,如瓜苗状态为缺水,若选择动作浇水,则瓜苗长势会发生变化,瓜苗有一定的概率恢复健康,也有一定的概率无法恢复;在转移到另一个状态的同时,环境会根据潜在的“奖赏”(reward)函数$R$反馈给机器一个奖赏,如保持瓜苗健康对应奖赏$+1$,瓜苗凋零对应奖赏$-10$,最终种出了好瓜对应奖赏$+100$。综合起来,强化学习任务对应了四元组$E = <X,A,P,R>$,其中$P:X \times A \times X \to \mathbb{R}$指定了状态转移概率,$R: X \times A \times X \to \mathbb{R}$指定了奖赏,在有的应用中,奖赏函数可能仅与状态转移有关,即$R:X\times X \to \mathbb{R}$。
图16.2给出了一个简单例子:给西瓜浇水的马尔可夫决策过程。该任务中只有四个状态(健康、缺水、溢水、凋亡)和两个动作(浇水、不浇水),在每一步转移后,若状态是保持瓜苗健康则获得奖赏1,瓜苗缺水或溢水奖赏为-1,这时通过浇水或不浇水可以恢复健康状态,当瓜苗凋亡时奖赏是最小值-100且无法恢复。图中箭头表示状态转移,箭头旁的$a,p,r$分别表示导致状态转移的动作、转移概率以及返回的奖赏。容易看出,最优策略在“健康”状态选择动作“浇水”、在“溢水”状态选择动作“不浇水”、在“缺水”状态选择动作“浇水”、在“凋亡”状态可选择任意动作。
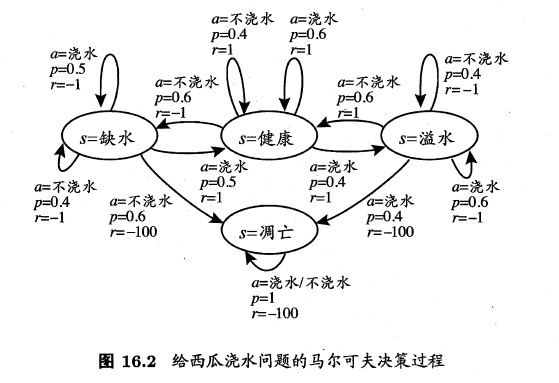
这里简单解释下图16.2怎么理解。以状态“缺水”为例,有4个朝外的箭头,表示可能发生的状态转移。如果动作选择“浇水”,那么有0.5的概率状态依旧是“缺水”,此时奖赏-1;如果动作选择“浇水”,还有0.5的概率状态会变为“健康”,此时奖赏+1;如果动作选择“不浇水”,那么有0.4的概率状态依旧是“缺水”,此时奖赏-1;如果动作选择“不浇水”,还会有0.6的概率状态变为“凋亡”,此时奖赏-100。
需注意“机器”与“环境”的界限,例如在种西瓜任务中,环境是西瓜生长的自然世界;在下棋对弈中,环境是棋盘与对手;在机器人控制中,环境是机器人的躯体与物理世界。总之,在环境中状态的转移、奖赏的返回是不受机器控制的,机器只能通过选择要执行的动作来影响环境,也只能通过观察转移后的状态和返回的奖赏来感知环境。
机器要做的是通过在环境中不断地尝试而学得一个“策略”(policy)$\pi$,根据这个策略,在状态$x$下就能得知要执行的动作$a=\pi (x)$,例如看到瓜苗状态是缺水时,能返回动作“浇水”。策略有两种表示方法:一种是将策略表示为函数$\pi:X\to A$,确定性策略常用这种表示;另一种是概率表示$\pi : X \times A \to \mathbb{R}$,随机性策略常用这种表示,$\pi (x,a)$为状态$x$下选择动作$a$的概率,这里必须有$\sum_a \pi (x,a)=1$。
策略的优劣取决于长期执行这一策略后得到的累积奖赏,例如某个策略使得瓜苗枯死,它的累积奖赏会很小,另一个策略种出了好瓜,它的累积奖赏会很大。在强化学习任务中,学习的目的就是要找到能使长期累积奖赏最大化的策略。长期累积奖赏有多种计算方式,常用的有“$T$步累积奖赏”$\mathbb{E}[\frac{1}{T} \sum_{t=1}^T r_t]$和“$\gamma$折扣累积奖赏”$\mathbb{E}[\sum_{t=0}^{+\infty} \gamma^t r_{t+1}]$,其中$r_t$表示第$t$步获得的奖赏值,$\mathbb{E}$表示对所有随机变量求期望。
