【机器学习基础】系列博客为参考周志华老师的《机器学习》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.探索与利用
与一般监督学习不同,强化学习任务的最终奖赏是在多步动作之后才能观察到,这里我们不妨先考虑比较简单的情形:最大化单步奖赏,即仅考虑一步操作。需注意的是,即便在这样的简化情形下,强化学习仍与监督学习有显著不同,因为机器需通过尝试来发现各个动作产生的结果,而没有训练数据告诉机器应当做哪个动作。
欲最大化单步奖赏需考虑两个方面:一是需知道每个动作带来的奖赏,二是要执行奖赏最大的动作。若每个动作对应的奖赏是一个确定值,那么尝试一遍所有的动作便能找出奖赏最大的动作。然而,更一般的情形是,一个动作的奖赏值是来自于一个概率分布,仅通过一次尝试并不能确切地获得平均奖赏值。
实际上,单步强化学习任务对应了一个理论模型,即“K-摇臂赌博机”(K-armed bandit,亦称“K-摇臂老虎机”)。如图16.3所示,K-摇臂赌博机有$K$个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。
若仅为获知每个摇臂的期望奖赏,则可采用“仅探索”(exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖赏期望的近似估计。若仅为执行奖赏最大的动作,则可采用“仅利用”(exploitation-only)法:按下目前最优的(即到目前为止平均奖赏最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个。显然,“仅探索”法能很好地估计每个摇臂的奖赏,却会失去很多选择最优摇臂的机会;“仅利用”法则相反,它没有很好地估计摇臂期望奖赏,很可能经常选不到最优摇臂。因此,这两种方法都难以使最终的累积奖赏最大化。
事实上,“探索”(即估计摇臂的优劣)和“利用”(即选择当前最优摇臂)这两者是矛盾的,因为尝试次数(即总投币数)有限,加强了一方则会自然削弱另一方,这就是强化学习所面临的“探索-利用窘境”(Exploration-Exploitation dilemma)。显然,欲累积奖赏最大,则必须在探索与利用之间达成较好的折中。
2.$\epsilon$-贪心
$\epsilon$-贪心法基于一个概率来对探索和利用进行折中:每次尝试时,以$\epsilon$的概率进行探索,即以均匀概率随机选取一个摇臂;以$1-\epsilon$的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个)。
令$Q(k)$记录摇臂$k$的平均奖赏。若摇臂$k$被尝试了$n$次,得到的奖赏为$v_1,v_2,…,v_n$,则平均奖赏为:
\[Q(k)=\frac{1}{n} \sum_{i=1}^n v_i \tag{1}\]若直接根据式(1)计算平均奖赏,则需记录$n$个奖赏值。显然,更高效的做法是对均值进行增量式计算,即每尝试一次就立即更新$Q(k)$。不妨用下标来表示尝试的次数,初始时$Q_0 (k) = 0$。对于任意的$n \geqslant 1$,若第$n-1$次尝试后的平均奖赏为$Q_{n-1}(k)$,则在经过第$n$次尝试获得奖赏$v_n$后,平均奖赏应更新为:
\[\begin{align} Q_n (k) &= \frac{1}{n} ((n-1)\times Q_{n-1}(k)+v_n) \tag{2} \\&= Q_{n-1}(k) + \frac{1}{n} (v_n - Q_{n-1} (k)) \tag{3} \end{align}\]这样,无论摇臂被尝试多少次都仅需记录两个值:已尝试次数$n-1$和最近平均奖赏$Q_{n-1}(k)$。$\epsilon$-贪心算法描述如图16.4所示:

- 第2步:$Q(i)$和$count(i)$分别记录摇臂$i$的平均奖赏和选中次数。
- 第4步:$rand()$在$[0,1]$中生成随机数。
- 第9步:本次尝试的奖赏值。
- 第11步:式(2)更新平均奖赏。
若摇臂奖赏的不确定性较大,例如概率分布较宽时,则需更多的探索,此时需要较大的$\epsilon$值;若摇臂的不确定性较小,例如概率分布较集中时,则少量的尝试就能很好地近似真实奖赏,此时需要的$\epsilon$较小。通常令$\epsilon$取一个较小的常数,如0.1或0.01。然而,若尝试次数非常大,那么在一段时间后,摇臂的奖赏都能很好地近似出来,不再需要探索,这种情形下可让$\epsilon$随着尝试次数的增加而逐渐减小,例如令$\epsilon = 1 / \sqrt{t}$。
3.Softmax
Softmax算法基于当前已知的摇臂平均奖赏来对探索和利用进行折中。若各摇臂的平均奖赏相当,则选取各摇臂的概率也相当;若某些摇臂的平均奖赏明显高于其他摇臂,则它们被选取的概率也明显更高。
Softmax算法中摇臂概率的分配是基于Boltzmann分布:
\[P(k)=\frac{e^{\frac{Q(k)}{\tau}}}{\sum_{i=1}^K e^{\frac{Q(i)}{\tau}}} \tag{4}\]其中,$Q(i)$记录当前摇臂的平均奖赏;$\tau > 0$称为“温度”,$\tau$越小则平均奖赏高的摇臂被选取的概率越高。$\tau$趋于0时Softmax将趋于“仅利用”,$\tau$趋于无穷大时Softmax则将趋于“仅探索”。Softmax算法描述如图16.5所示。

- 第2步:$Q(i)$和$count(i)$分别记录摇臂$i$的平均奖赏和选中次数。
- 第4步:根据式(4)。
- 第5步:本次尝试的奖赏值。
- 第7步:式(2)更新平均奖赏。
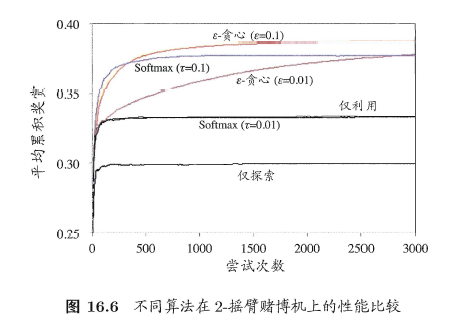
$\epsilon$-贪心算法与Softmax算法孰优孰劣,主要取决于具体应用。为了更直观地观察它们的差别,考虑一个简单的例子:假定2-摇臂赌博机的摇臂1以0.4的概率返回奖赏1,以0.6的概率返回奖赏0;摇臂2以0.2的概率返回奖赏1,以0.8的概率返回奖赏0。图16.6显示了不同算法在不同参数下的平均累积奖赏,其中每条曲线对应于重复1000次实验的平均结果。可以看出,Softmax($\tau=0.01$)的曲线与“仅利用”的曲线几乎重合。
对于离散状态空间、离散动作空间上的多步强化学习任务,一种直接的办法是将每个状态上动作的选择看作一个$K$-摇臂赌博机问题,用强化学习任务的累积奖赏来代替$K$-摇臂赌博机算法中的奖赏函数,即可将赌博机算法用于每个状态:对每个状态分别记录各动作的尝试次数、当前平均累积奖赏等信息,基于赌博机算法选择要尝试的动作。然而这样的做法有很多局限,因为它没有考虑强化学习任务马尔可夫决策过程的结构。
