本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
官方github repo:RTMDet。
官方文档:RTMDET 原理和实现全解析。
我们的目的旨在突破YOLO系列模型的极限,提出一个新的用于目标检测的实时模型家族,称为RTMDet(Real-Time Models for object Detection,RTM也可以理解为Release To Manufacture),其还可以进行实例分割和旋转目标的检测,这是以前的工作没有探索过的。
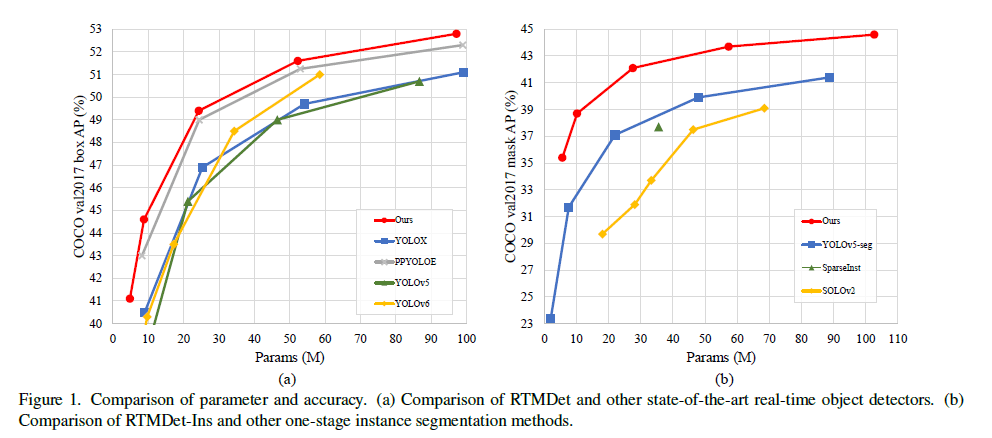
Fig1左为RTMDet在目标检测任务上的表现,Fig1右为RTMDet-Ins在实例分割任务上的表现。
2.Related Work
不再赘述。
3.Methodology
3.1.Macro Architecture
RTMDet是一个one-stage的目标检测模型,其宏观框架包括backbone、neck、head等几部分,如Fig2所示。最近的YOLOv4和YOLOX都使用CSPDarkNet作为backbone,CSPDarkNet block如Fig3(a)所示。neck部分则从backbone中提取多尺度特征金字塔,并使用和backbone相同的building block,通过自上而下和自下而上的特征传播来增强pyramid feature map。最后,head部分基于每种尺度的feature map来预测目标的bounding box和类别。
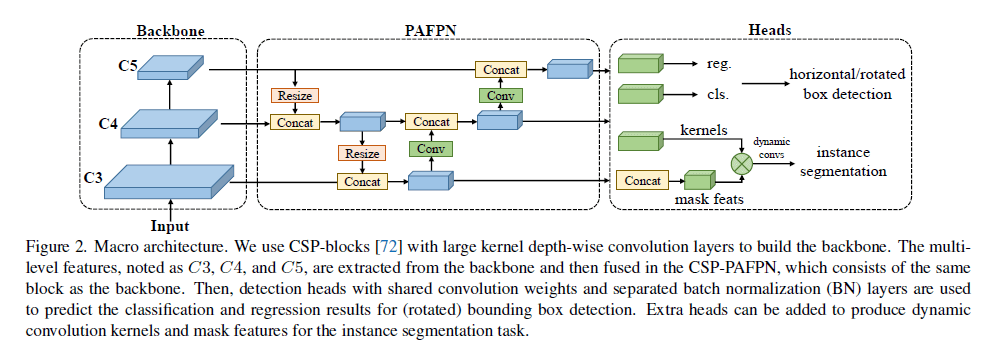
Fig2中的PAFPN指的就是PANet。下面是更详细的框架图:
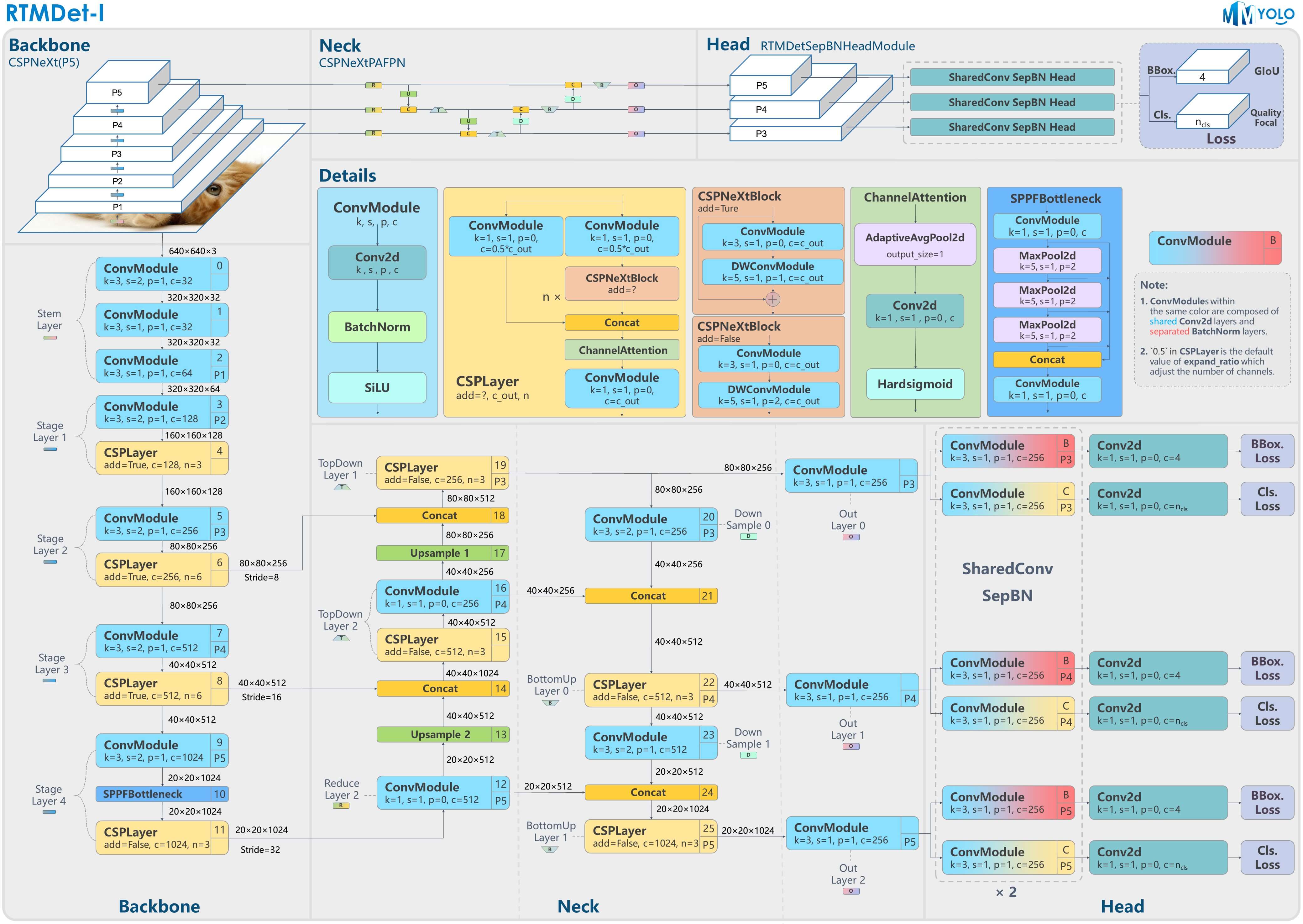
3.2.Model Architecture
👉Basic building block.
backbone中大的有效的感受野有利于dense prediction的任务,比如目标检测和分割,因为它有助于更全面的捕捉上下文信息。然而,之前的研究为了增大感受野通常也会带来昂贵的计算成本,这限制了其在实时目标检测任务中的应用。因此,我们引入了深度卷积(depth-wise convolution),在合理的计算成本内有效的增大感受野,如Fig3(b)所示。这一方法显著提高了模型精度。我们将形如Fig3(b)的结构称为CSPNeXt Block,Fig3(a)称为basic block。
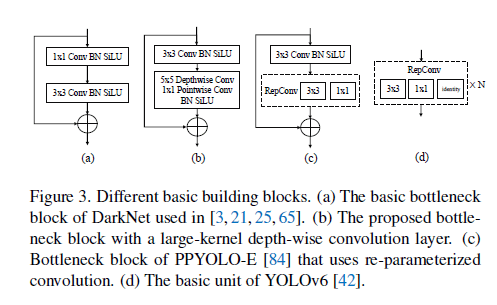
一些实时目标检测模型,比如YOLOv6和PPYOLO-E,使用了重参数化(re-parameterized)的$3 \times 3$卷积(见Fig3(c)和Fig3(d)),这一操作虽然提高了精度,但也使得训练速度变慢,训练占用内存变多。与之相比,large-kernel(作者使用$5 \times 5$大小的kernel)的depth-wise卷积是一种更简单有效的选择,其训练成本更低。
接下来说下几种卷积方式的不同,首先是常规的卷积操作:
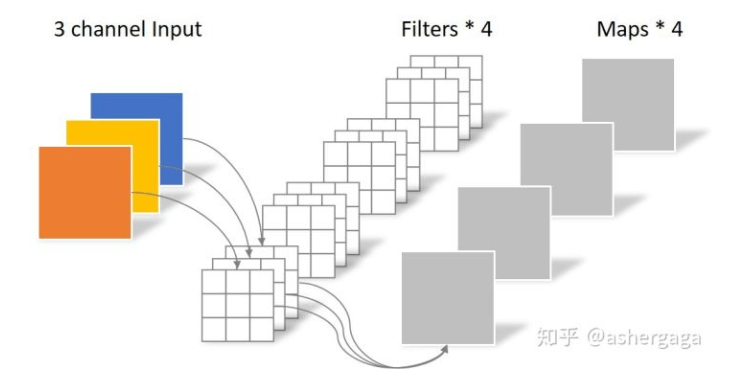
然后是depth-wise卷积:
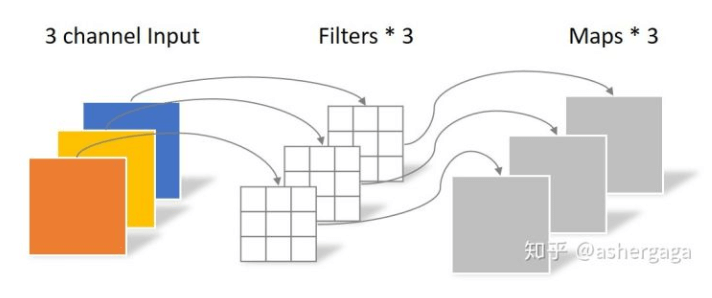
depth-wise卷积完全是在二维平面内进行的,卷积核的数量和上一层的通道数相同(通道和卷积核一一对应)。最后是point-wise卷积:
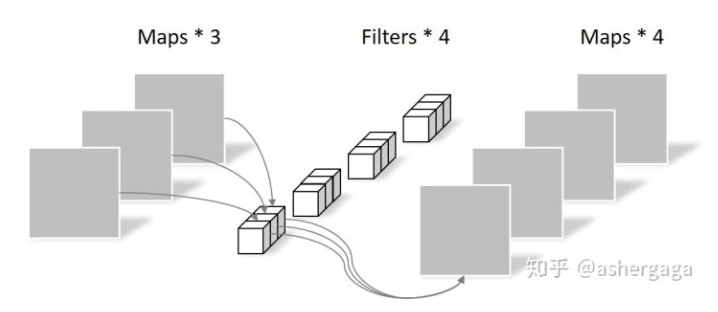
point-wise卷积就是$1 \times 1$卷积,它的卷积核尺寸为$1 \times 1 \times M$,$M$为上一层的通道数。所以这里的卷积运算会将上一步的feature map在深度方向上进行加权组合,生成新的feature map。有几个卷积核就有几个输出feature map。
👉Balance of model width and depth.
相比basic block,CSPNeXt block在depth-wise卷积后增加了额外的point-wise卷积,这使得每个block内的层数增加了,这阻碍了每一层的并行计算,从而降低了推理速度。为了解决这个问题,对于backbone中的每个stage,我们减少了block的数量并适当增加了block的width,最终在不牺牲精度的情况下提高了推理速度。
👉Balance of backbone and neck.
多尺度的特征金字塔是检测不同尺度目标的关键。为了增强多尺度的特征,EfficientDet、NASFPN等工作在改进neck时往往聚焦于如何修改特征融合的方式,但其引入过多的连接会增加检测器的延时,并增加内存开销。我们选择不引入额外的连接,而是改变backbone与neck间参数量的配比。我们通过实验发现,当neck在整个模型中的参数量占比更高时,延时更低,且对精度的影响很小。
👉Shared detection head.
从第3.1部分的框架图中可以看出,在head部分,借鉴了YOLOX中解耦头的设计,其中,卷积层的权重是共享的(BBox分支共享一套参数,Cls分支共享一套参数),即图中的”SharedConv”;但BN的参数是不共享的,即图中的”SepBN”。在推理阶段,BN直接使用训练阶段的统计数据。
3.3.Training Strategy
👉Label assignment and losses.
正负样本匹配策略或者称为标签匹配策略(Label Assignment)是目标检测模型训练中最核心的问题之一,更好的标签匹配策略往往能够使得网络更好学习到物体的特征以提高检测能力。
早期的样本标签匹配策略一般都是基于空间以及尺度信息的先验来决定样本的选取。典型案例如下:
- FCOS中先限定网格中心点在GT内筛选后然后再通过不同特征层限制尺寸来决定正负样本。
- RetinaNet则是通过anchor与GT的最大IoU匹配来划分正负样本。
- YOLOv5的正负样本则是通过样本的宽高比先筛选一部分,然后通过位置信息选取GT中心落在的grid以及临近的两个作为正样本。
但是上述方法都是属于基于先验的静态匹配策略,就是样本的选取方式是根据人的经验规定的。不会随着网络的优化而进行自动优化选取到更好的样本,近些年涌现了许多优秀的动态标签匹配策略:
这些算法将预测的Bboxes与GT的IoU和分类分数或者是对应分类Loss和回归Loss拿来计算matching cost矩阵再通过top-k的方式动态决定样本选取以及样本个数。通过这种方式,在网络优化的过程中会自动选取对分类或者回归更加敏感有效的位置的样本,它不再只依赖先验的静态的信息,而是使用当前的预测结果去动态寻找最优的匹配,只要模型的预测越准确,匹配算法求得的结果也会更优秀。但是在网络训练的初期,网络的分类以及回归是随机初始化,这个时候还是需要先验来约束,以达到冷启动的效果。
最近的一些动态样本匹配策略,比如SimOTA,通常使用和训练loss一致的cost function作为匹配标准。但我们发现其具有一定的局限性,并不一定是最优的,因此,我们提出了一种基于SimOTA的动态软标签分配策略,其cost function为:
\[C = \lambda_1 C_{cls} + \lambda_2 C_{reg} + \lambda_3 C_{center} \tag{1}\]其中,$C_{cls}$为classification cost,$C_{center}$为region prior cost,$C_{reg}$为regression cost。默认情况下,$\lambda_1 = 1, \lambda_2 = 3, \lambda_3 = 1$。
先前的方法通常使用二值标签来计算$C_{cls}$,但这存在一定局限性,所以我们将soft label引入到$C_{cls}$计算中:
\[C_{cls} = CE (P, Y_{soft}) \times (Y_{soft} - P)^2 \tag{2}\]其中,$P$是预测的类别结果(比如softmax的输出),$Y_{soft}$是GT box和预测的bounding box的IoU,我们将$Y_{soft}$视为类别的soft label。这部分的源码见下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 生成分类标签
gt_onehot_label = (
F.one_hot(gt_labels.to(torch.int64),
pred_scores.shape[-1]).float().unsqueeze(0).repeat(
num_valid, 1, 1))
valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
# 不单单将分类标签为01,而是换成与 gt 的 iou
soft_label = gt_onehot_label * pairwise_ious[..., None]
# 使用 quality focal loss 计算分类损失 cost ,与实际的分类损失计算保持一致
scale_factor = soft_label - valid_pred_scores.sigmoid()
soft_cls_cost = F.binary_cross_entropy_with_logits(
valid_pred_scores, soft_label,
reduction='none') * scale_factor.abs().pow(2.0)
soft_cls_cost = soft_cls_cost.sum(dim=-1)
比如一共有3个类别,bounding box的类别预测结果$P=[0.1,0.3,0.6]$,类别GT的one-hot编码为$[0,0,1]$,预测的bounding box和GT box的IoU为0.9,那么$Y_{soft} = [0,0,1] * IoU = [0,0,0.9]$。如果我们对照着上述代码看的话,soft_label就是$[0.,0.,0.9]$,valid_pred_scores就是$[0.1,0.3,0.6]$,scale_factor就是式(2)中第2项括号中的内容,注意这里把valid_pred_scores进行了sigmoid处理,即通过公式$\frac{1}{1+e^{-x}}$,得到valid_pred_scores.sigmoid()为$[0.5250, 0.5744, 0.6457]$,得到的scale_factor为$[-0.5250, -0.5744, 0.2543]$,其平方是对每个元素的平方,所以scale_factor.abs().pow(2.0)为$[0.2756, 0.3300, 0.0647]$,这就是式(2)第二项的计算结果。第一项CE的计算结果为$[0.7444, 0.8544, 0.4975]$,和第二项相乘便可得到$[0.2052, 0.2819, 0.0322]$,将这3个数相加得到最终的soft_cls_cost,为0.5193。
软标签分类损失避免了二值标签引起的噪声和不稳定匹配。
$C_{reg}$的计算如下:
\[C_{reg}=-\log (IoU) \tag{3}\]这部分源码见下:
1
2
3
4
# 计算回归 bboxes 和 gts 的 iou
pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
# iou越小,cost越大
iou_cost = -torch.log(pairwise_ious + EPS) * 3
$C_{center}$的计算如下:
\[C_{center} = \alpha ^{\lvert x_{pred} – x_{gt} \rvert - \beta } \tag{4}\]默认超参数$\alpha = 10, \beta=3$。
这部分的源码见下:
1
2
3
4
5
6
7
8
9
10
# valid_prior Tensor[N,4] 表示anchor point
# 4分别表示 x, y, 以及对应的特征层的 stride, stride
gt_center = (gt_bboxes[:, :2] + gt_bboxes[:, 2:]) / 2.0
valid_prior = priors[valid_mask]
strides = valid_prior[:, 2]
# 计算gt与anchor point的中心距离并转换到特征图尺度
distance = (valid_prior[:, None, :2] - gt_center[None, :, :]
).pow(2).sum(-1).sqrt() / strides[:, None]
# 以10为底计算位置的软化损失,限定在gt的6个单元格以内
soft_center_prior = torch.pow(10, distance - 3)
从源码中可以看出,$\lvert x_{pred} – x_{gt} \rvert $是GT box中心点到预测bounding box中心点的距离。
以上是SimOTA中计算cost所用的cost function,接下来说下模型训练所用的loss设计。训练loss一共包括2部分:cls loss和bbox loss。权重比例是cls loss : bbox loss = 1 : 2。bbox loss使用GIoU loss。cls loss使用QFL(Quality Focal Loss),接下来详细介绍下QFL。QFL将目标的定位质量(比如预测的bounding box和GT box的IoU)直接融合到分类损失中,解决了传统目标检测中分类与定位任务之间存在的不一致问题。其基于focal loss进行优化:
\[\text{QFL}(\sigma) = - \lvert y - \sigma \rvert^{\beta} ((1-y)\log (1-\sigma) + y \log (\sigma))\]其中,$\beta \geqslant 0$,$\sigma$就是预测的类别概率,$-((1-y)\log (1-\sigma) + y \log (\sigma))$其实就是一个CE loss,$y$是soft label,即预测的bounding box和GT box的IoU,如果是负样本,则$y=0$。
👉Cached Mosaic and MixUp.
MixUp和CutMix虽然好用,但有两个问题。第一个问题,在每次迭代时,我们都需要加载多张图片来生成训练样本,这就引入了更多的数据加载成本,并且会拖慢训练速度。第二个问题,生成的训练样本是有噪声的,可能不属于数据集的真实分布,这影响了模型学习。
Mosaic和MixUp涉及到多张图片的混合,它们的耗时会是普通数据增强的$K$倍($K$为混入图片的数量)。如在YOLOv5中,每次做Mosaic时,4张图片的信息都需要从硬盘中重新加载。而RTMDet只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。另外通过调整cache的大小以及pop的方式,也可以调整增强的强度。
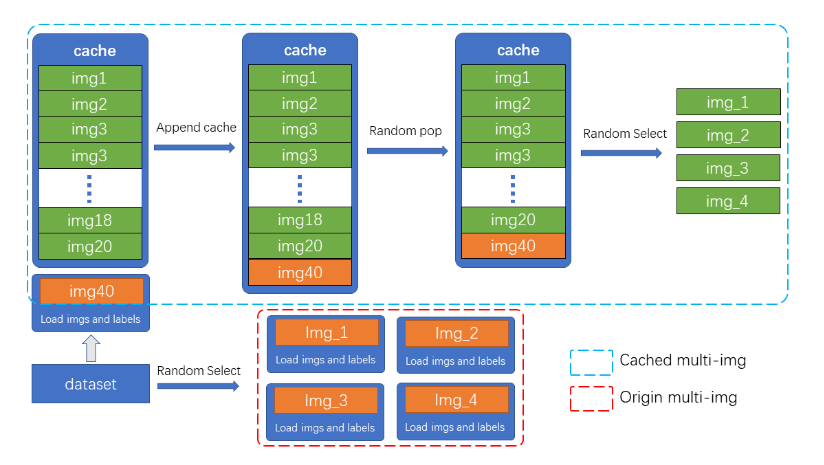
如图所示,cache队列中预先存储了$N$张已加载的图像与标签数据,每一个训练step中只需加载一张新的图片及其标签数据并更新到cache队列中(cache队列中的图像可重复,如图中出现两次img3),同时如果cache队列长度超过预设长度,则随机pop一张图(为了Tiny模型训练更稳定,在Tiny模型中不采用随机pop的方式,而是移除最先加入的图片),当需要进行混合数据增强时,只需要从cache中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
cache队列的最大长度$N$为可调整参数,根据经验性的原则,当为每一张需要混合的图片提供十个缓存时,可以认为提供了足够的随机性,而Mosaic增强是四张图混合,因此cache数量默认$N=40$,同理MixUp的cache数量默认为20,Tiny模型需要更稳定的训练条件,因此其cache数量也为其余规格模型的一半(MixUp为10,Mosaic为20)。
👉Two-stage training.
为了降低strong数据增强所带来的“噪声”样本的副作用,YOLOX探索了一种two-stage的训练策略,在第一个stage中,使用strong数据增强,包括Mosaic、MixUp、随机旋转和shear;在第二个stage中,使用weak数据增强,包括随机resize和flip。但由于在训练的初始阶段使用了随机旋转和shear,这会导致输入和变换后的标注框产生错位,因此YOLOX在第二个stage引入额外的L1 loss来纠正reg分支的性能。为了解耦数据增强和损失函数,使数据增强策略更具有通用性,在第一个stage(共280个epoch)中,我们没有使用随机旋转和shear,但我们将混合的图片数量增加至8张,以补偿数据增强的强度。在第二个stage(共20个epoch)中,我们使用了Large Scale Jittering(LSJ)。为了训练稳定性,我们使用AdamW优化器。
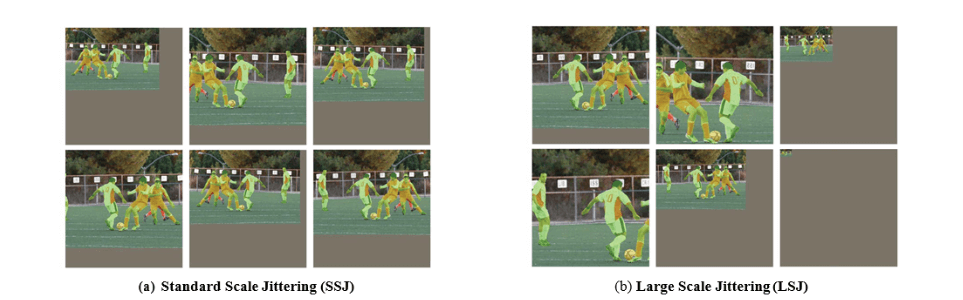
Standard Scale Jittering(SSJ)会对图像进行resize和crop操作,其resize的比例为0.8~1.25。而LSJ对原始图像resize的比例范围会更大:0.1~2.0。如果resize后的图像小于原始图像,则会用灰色像素进行padding。两种scale jittering方式都会使用水平翻转。
这里附上官方给出的数据增强流程:
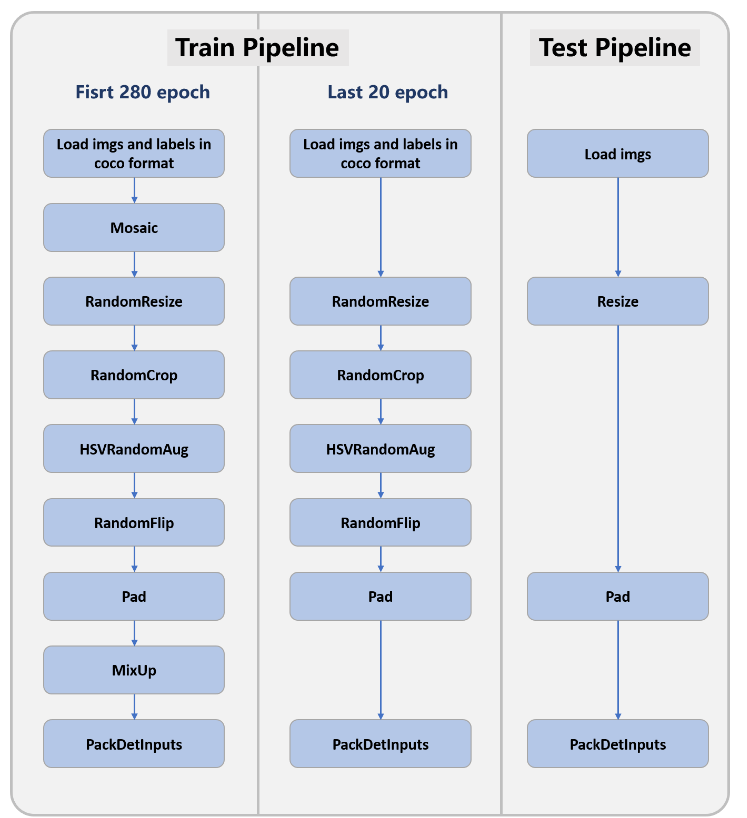
特殊注意:大模型M\L\X使用的是LSJ(resize范围为$[0.1,2.0]$),而小模型S\Tiny使用的是SSJ(resize范围为$[0.5,2.0]$)。
3.4.Extending to other tasks
👉Instance segmentation.
这部分的具体实现没太明白,按照原文翻译过来。
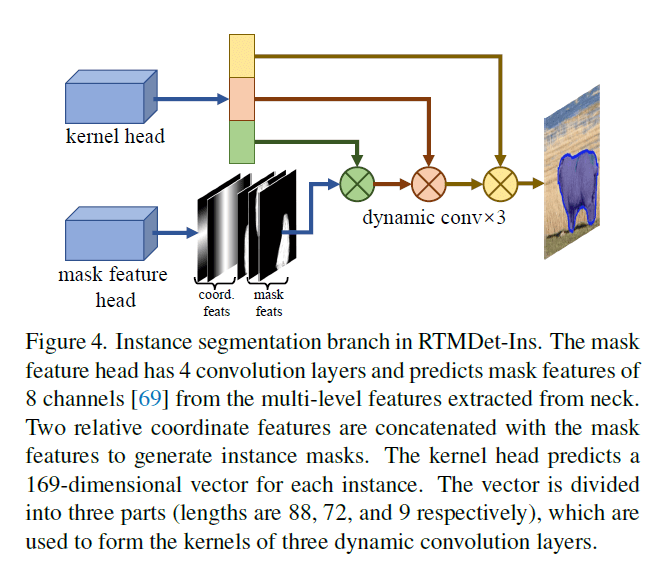
RTMDet通过简单的修改就可以进行实例分割,我们将其称为RTMDet-Ins。如Fig4所示,在RTMDet的基础上,添加了一个额外的分支,这个分支包含一个kernel prediction head和一个mask feature head,这类似于CondInst。mask feature head使用4个卷积层从multi-level features中提取 mask features,通道数都是8。kernel prediction head对每个实例预测得到一个169维的向量,这个向量会被分成3个动态卷积核(长度分别为88、72和9)。为了进一步利用mask标注中固有的先验信息,我们在计算动态标签分配时使用mask的质心,而不是box的中心。使用dice loss。
CondInst:Zhi Tian, Chunhua Shen, and Hao Chen. Conditional convolutions for instance segmentation. In European conference on computer vision, pages 282–298. Springer, 2020.。
👉Rotated object detection.
由于旋转目标检测和常规(水平)目标检测之间固有的相似性,将RTMDet适配为旋转目标检测器(即RTMDet-R)只需要3步:
- 在reg分支中添加$1 \times 1$卷积用于预测旋转角度。
- 修改bounding box coder以支持旋转box。
- 把GIoU loss替换为旋转IoU loss。
RTMDet-R共享了RTMDet的大部分参数,因此在通用检测数据集(例如COCO数据集)上预训练的RTMDet模型权重可以作为RTMDet-R的初始化。
4.Experiments
4.1.Implementation Details
👉Object detection and instance segmentation.
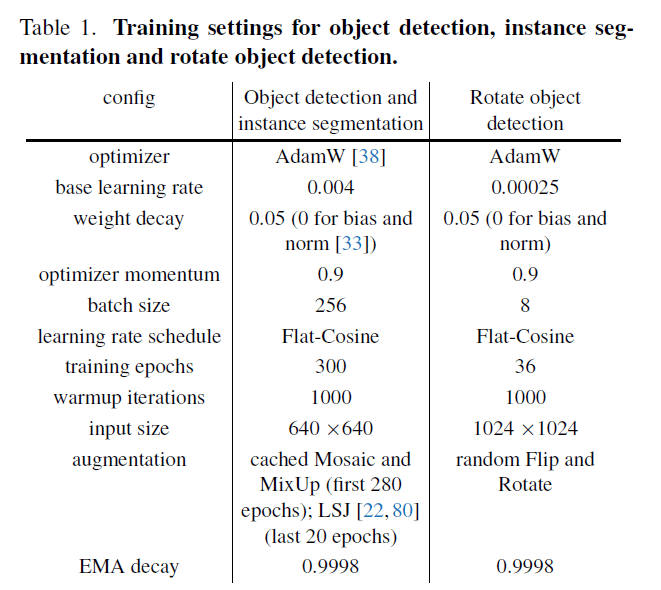
我们在COCO数据集上进行了实验,该数据集的train2017包含118K张图片,val2017包含5K张图片。我们在train2017上训练了300个epoch,在val2017上进行了验证。超参设置见表1。
我们所有目标检测和实例分割的模型都使用了8块NVIDIA A100 GPU。目标检测任务的评估指标使用bbox AP,实例分割任务的评估指标使用mask AP。
Flat-Cosine就是在训练的前半段先保持学习率不变,在训练的后半段开始执行cosine learning rate decay。
在目标检测的测试阶段,我们用0.001的阈值筛选bounding box用于NMS,保留最高的300个box用于验证。这和YOLOv5、YOLOv6、YOLOv7是一致的。但为了加快消融实验,我们把阈值提高到0.05,只保留最高的100个box,这导致AP下降约0.3%。
👉Rotated object detection.
我们在DOTA数据集上进行测试,该数据集包括2.8K张航空图像,共188K个实例,这些图像是通过具有多个分辨率的不同传感器获得的。超参数见表1。对于single-scale的训练和测试,我们将原始图像裁剪为$1024 \times 1024$大小的patch,patch之间会有256个像素的重叠。对于multi-scale的训练和测试,原始图像会被分别resize到原来的0.5、1.0和1.5倍,然后再裁剪为$1024 \times 1024$的patch,patch之间会有500个像素的重叠。大部分的旋转目标检测模型在一块NVIDIA V100 GPU上进行训练,只有大模型使用了2块NVIDIA V100 GPU。对于评估指标,我们采用和PASCAL VOC2007一样的mAP计算,除此之外还使用了旋转IoU计算。
👉Benchmark settings.
所有模型的latency测试都基于半浮点精度(FP16)、一块NVIDIA 3090 GPU、TensorRT 8.4.3、cuDNN 8.2.0。推理的batch size为1。
4.2.Benchmark Results
Object detection.
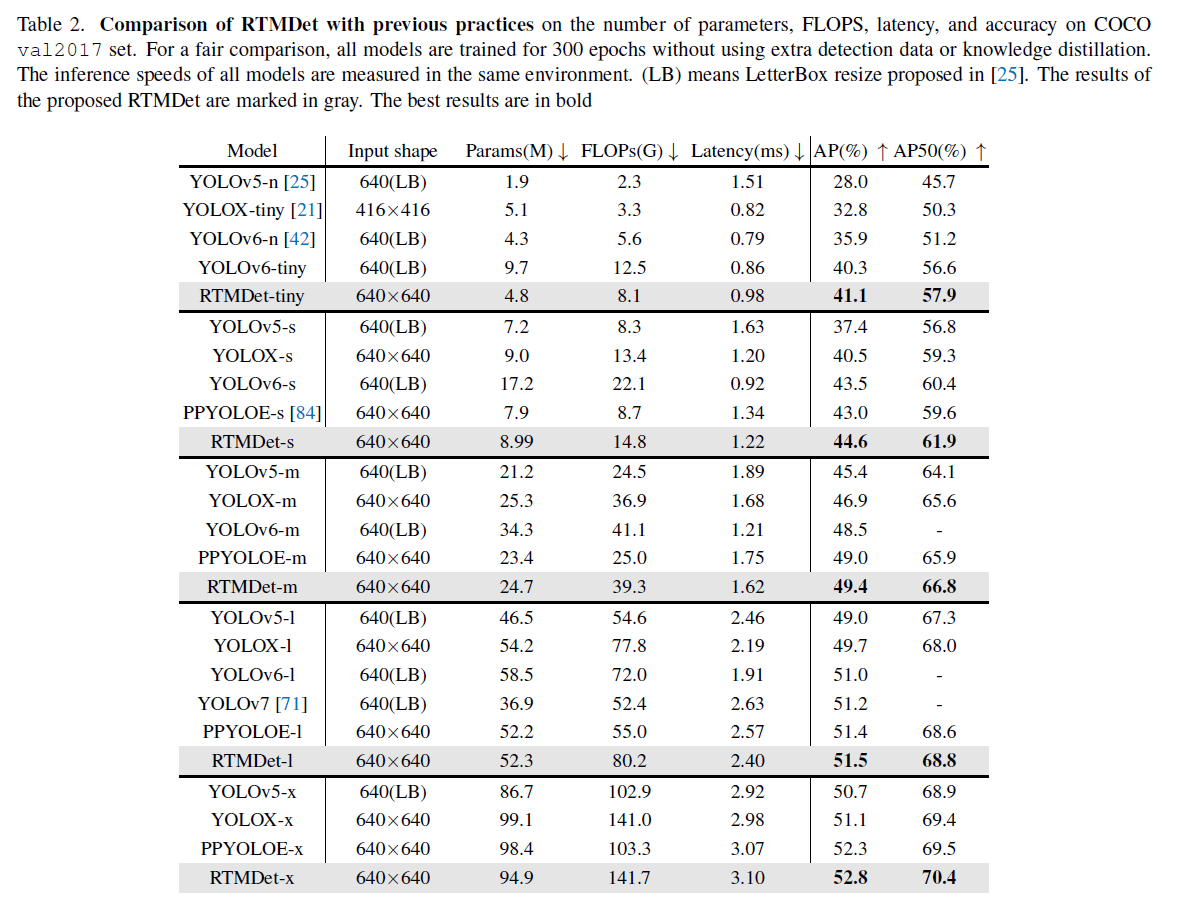
Instance segmentation.
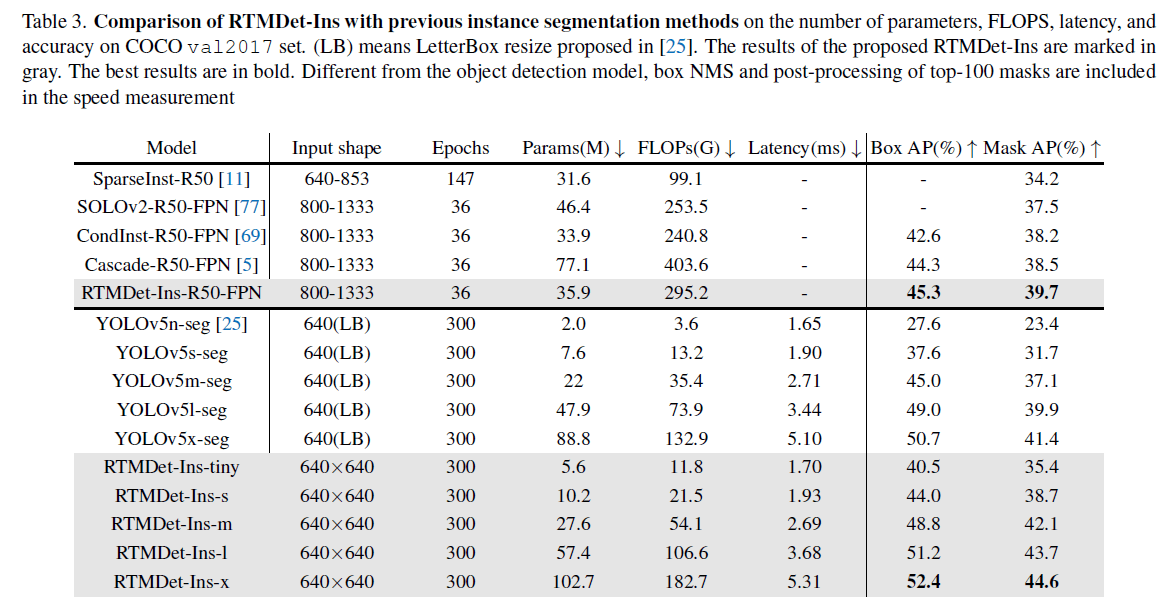
Rotated object detection.
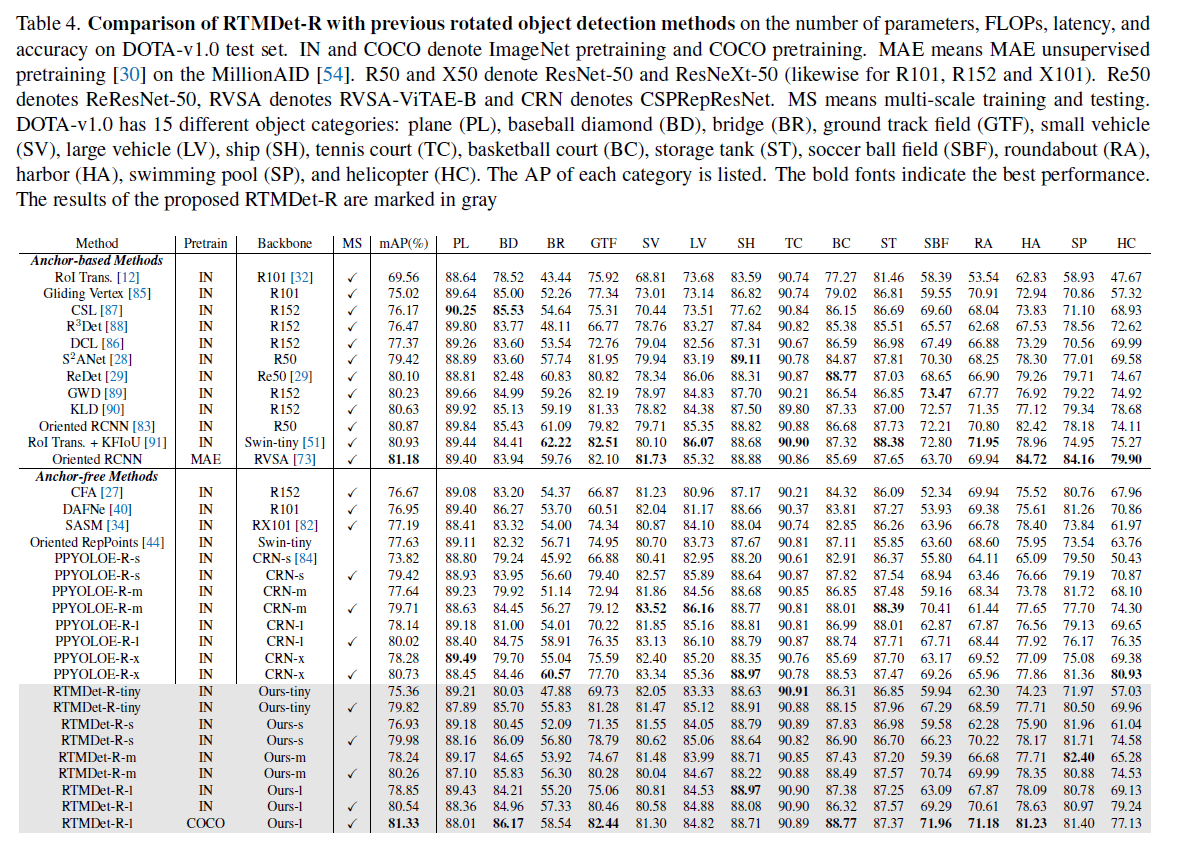
4.3.Ablation Study of Model Arhitecture
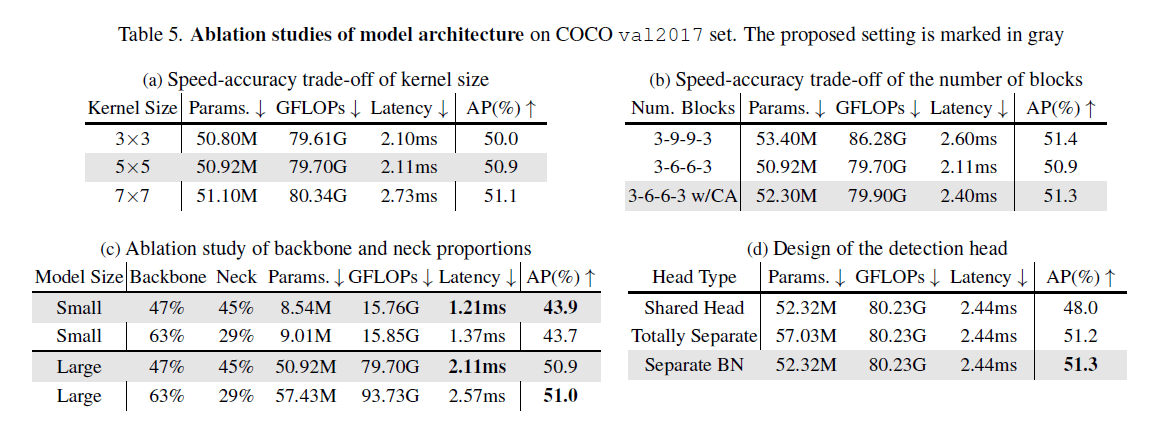
👉Large kernel matters.
对CSPNeXtBlock中的kernel大小进行消融实验,结果见Fig5(a)。
👉Balance of multiple feature scales.
对backbone的stage1-4中的block数量进行消融实验,结果见Fig5(b)。使用depth-wise卷积增加了网络深度,降低了推理速度。因此我们把block数从3-9-9-3降到3-6-6-3,这一修改使latency降低了20%,但这也导致AP下降了0.5%,因此我们通过CA(Channel Attention)进行了补偿。这样下来,相比3-9-9-3,3-6-6-3 w/CA只降低了0.1%的AP,但latency有了7%的提升。
CA模块为1层AdaptiveAvgPool2d+1层$1 \times 1$的Conv2d+Hardsigmoid激活函数。
Hardsigmoid激活函数的定义和图像:
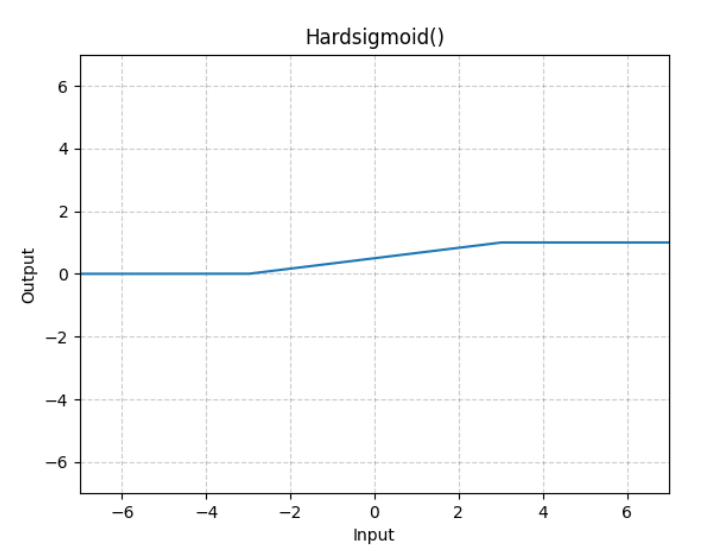
个人理解:假设CA的输入维度为$w\times h \times channel$。
AdaptiveAvgPool2d的output_size=1,这就相当于AdaptiveAvgPool2d输出的大小为$1\times 1 \times channel$,经过后面的Conv2d和Hardsigmoid之后维度依旧是$1 \times 1 \times channel$,然后和CA的输入相乘,使得CA的输出大小还是$w\times h \times channel$。
👉Balance of backbone and neck.
backbone和neck的参数占比的消融实验见Fig5(c)。
👉Detection head.
对于head,我们测试了不同的参数共享策略,见Fig5(d)。
4.4.Ablation Study of Training Strategy
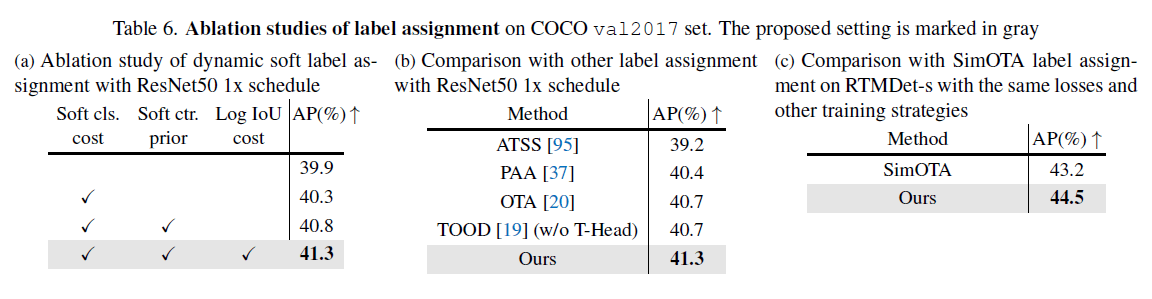
👉Label assignment.
👉Data augmentation.
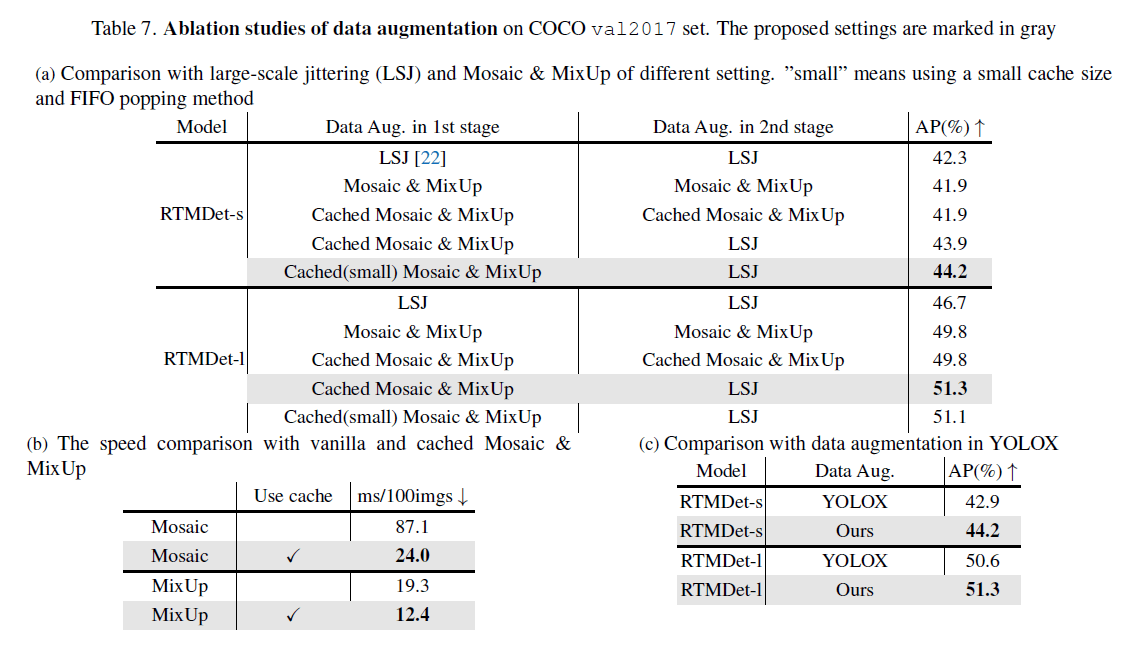
表7(a)中,1st stage表示前280个epoch,2nd stage表示后20个epoch。
👉Optimization strategy.

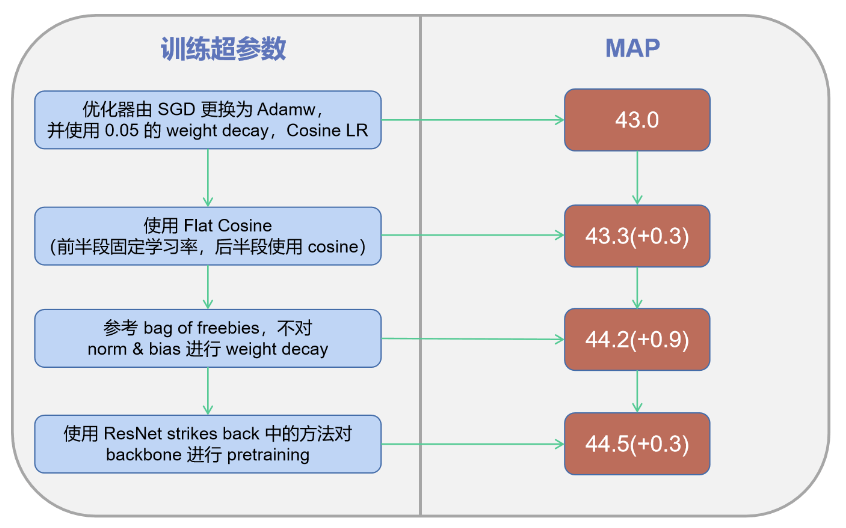
最后一条的预训练使用ImageNet。
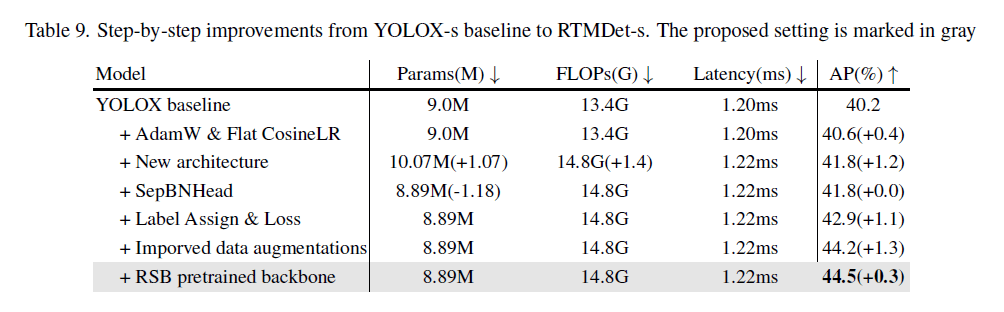
4.5.Step-by-step Results
5.Conclusion
RTMDet在工业级应用中展示了精度和速度之间的优越平衡。
6.A.Appendix
6.1.A.1.Benchmark Results
👉Comparison with PPYOLOE-R.
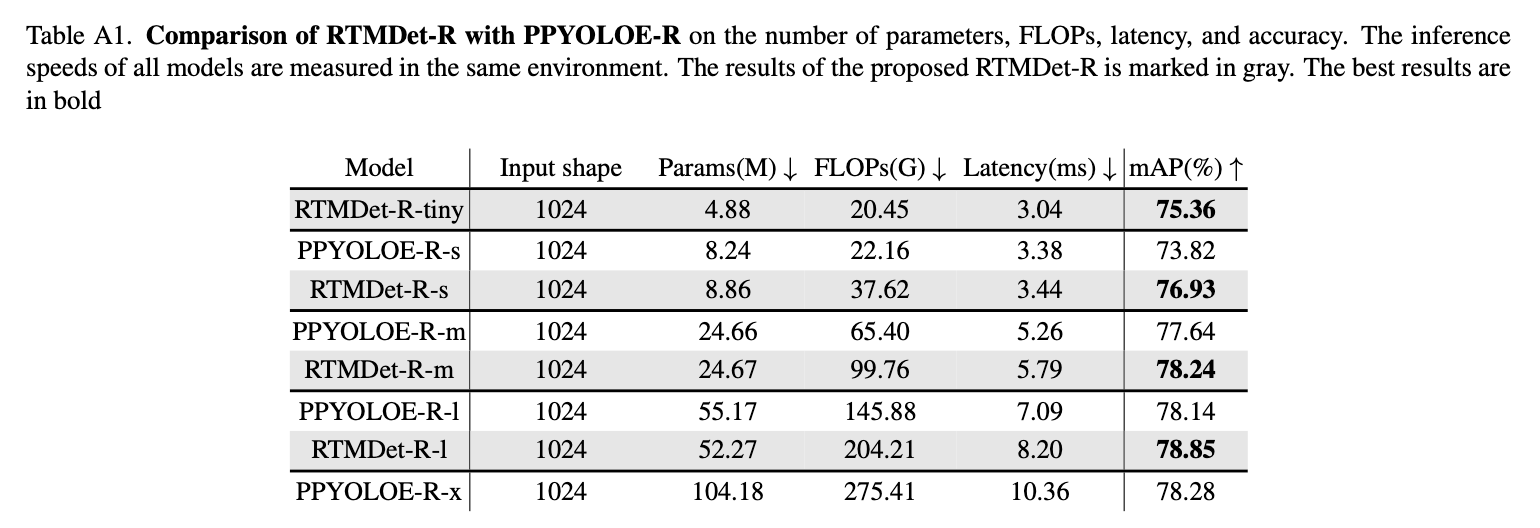
RTMDet-R的代码和模型可见MMRotate。
MMRotate:Yue Zhou, Xue Yang, Gefan Zhang, Jiabao Wang, Yanyi Liu, Liping Hou, Xue Jiang, Xingzhao Liu, Junchi Yan, Chengqi Lyu, Wenwei Zhang, and Kai Chen. Mmrotate: A rotated object detection benchmark using pytorch. In Proceedings of the 30th ACM International Conference on Multimedia, page 7331–7334, 2022.。
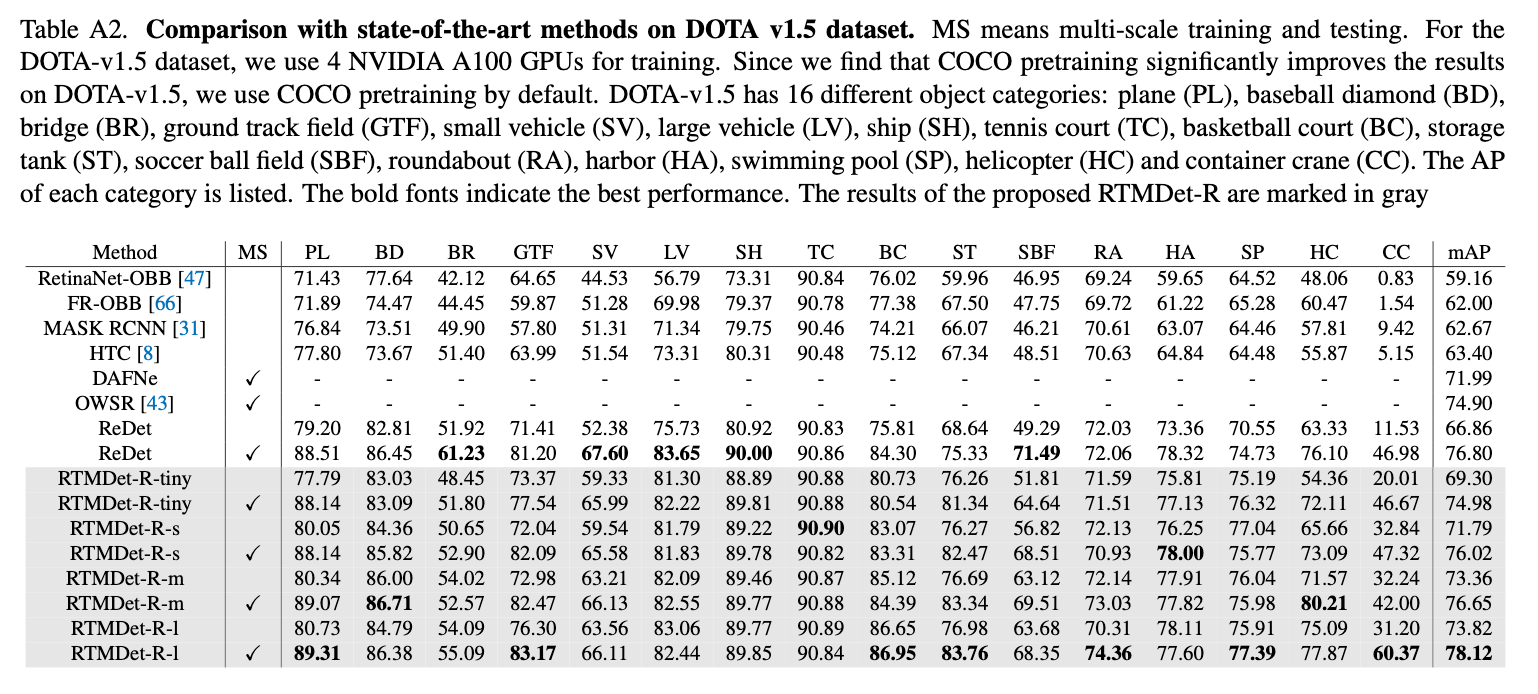
👉Results on DOTA-v1.5.
👉Results on HRSC2016.

7.原文链接
👽RTMDet:An Empirical Study of Designing Real-Time Object Detectors
