本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
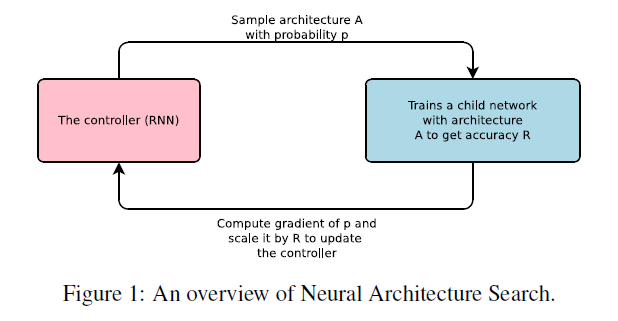
本文提出了NAS(Neural Architecture Search),是一种用于搜索最优网络结构的方法,见Fig1。
2.RELATED WORK
不再详述。
3.METHODS
3.1.GENERATE MODEL DESCRIPTIONS WITH A CONTROLLER RECURRENT NEURAL NETWORK
在NAS中,我们使用控制器来生成神经网络架构的超参数。为了灵活性,我们使用RNN作为控制器。个人理解因为神经网络是一层接一层的结构,就非常像一个序列生成问题,因此使用RNN就非常的合适。Fig2是一个例子,假设我们只考虑预测神经网络中卷积层的超参数:
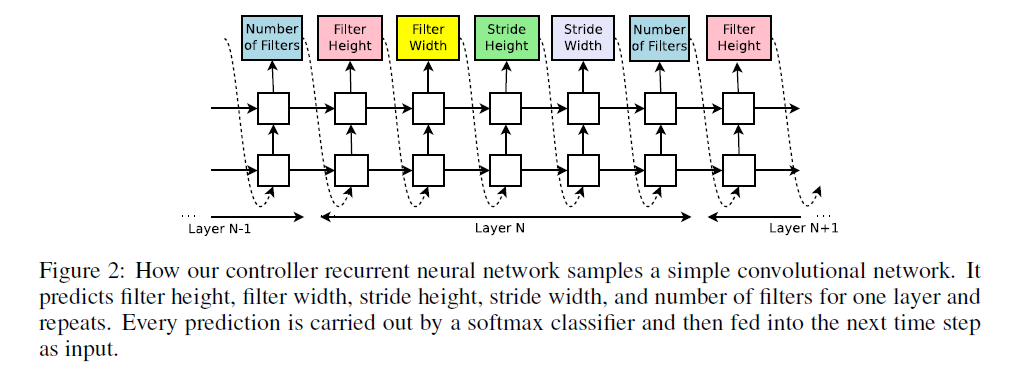
从Fig2可以看到,对于每个卷积层,控制器预测的超参数有卷积核的大小(Filter Height和Filter Width)、横纵两个方向的步长(Stride Height和Stride Width)以及卷积核的数量(Number of Filters)。主要注意的是,RNN的每个时间步通过softmax分类器得到输出,并作为下一时间步的输入。
在我们的实验中,当生成的网络层数超过某个阈值时,架构生成过程就会停止。该阈值会随着训练的进行而逐步增大。一旦控制器RNN完成某个结构的生成,就会构建并训练对应的神经网络。在收敛后,我们会在一个保留的验证集上记录该网络的准确率。随后,对控制器RNN的参数$\theta_c$进行优化,使验证集准确率最大化。下一部分将介绍更新参数$\theta_c$的方法,从而使控制器RNN随着时间推移生成越来越优的网络结构。
3.2.TRAINING WITH REINFORCE
RNN在每个时间步$t$都会生成一个用于构建子网络的超参数,那么我们将RNN所有时间步的输出按序记为$a_{1:T}$,一组$a_{1:T}$就对应一个子网络结构。每个子网络会在一个验证集上被训练至收敛,得到一个准确率$R$。我们可以把这个准确率$R$当作奖励信号,并使用强化学习来训练控制器。为了让控制器能够找到最优的子网络结构,我们最大化:
\[J(\theta_c) = E_{P(a_{1:T};\theta_c)} [R] \tag{1}\]式(1)中,$\theta_c$表示当前的RNN模型,我们可以构建一个batch,batch中的每个样本代表输出不同的$a_{1:T}$,即输出不同的子网络参数组合,$P(a_{1:T};\theta_c)$表示得到该组$a_{1:T}$的概率。每组$a_{1:T}$都能得到一个$R$,这些$R$的期望(即加权平均)就是$J$。最大化$J$的意义就是希望当前的RNN模型平均能采到更多的好模型。因此,式(1)可以简单理解为NAS框架的损失函数。
接下来,按照常规梯度下降法的思路,我们需要求$J$对$\theta_c$的梯度,但是由于$R$是不可微的,所以我们改用策略梯度算法(policy gradient method)。使用这篇论文“Ronald J.Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. In Machine Learning, 1992.”提出的REINFORCE规则来计算$J$对$\theta_c$的梯度:
\[\nabla_{\theta_c} J(\theta_c) = \sum_{t=1}^T E_{P(a_{1:T};\theta_c)} [ \nabla_{\theta_c} \log P(a_t \mid a_{(t-1):1} ; \theta_c) R ] \tag{2}\]但是在式(2)中,我们要计算期望,就要得到每一种可能的$a_{1:T}$输出以及其对应的$R$,这个架构搜索空间几乎是无限大的,因此我们用下式来近似期望:
\[\frac{1}{m} \sum_{k=1}^m \sum_{t=1}^T \nabla_{\theta_c} \log P (a_t \mid a_{(t-1):1};\theta_c) R_k \tag{3}\]$m$是batch的大小,即一个batch中采样的不同结构数量。一个batch就对应RNN一次参数的迭代更新。$t$是时间步。第$k$个网络结构在训练集上训练后,在验证集上得到的准确率为$R_k$。式(3)就可以使用常规的梯度下降法来更新$\theta_c$了。
式(3)是对梯度的无偏估计。但由于不同架构训练出来的验证精度差异,导致$R$的波动很大,直接乘$R$会让梯度方向抖动的很厉害,从而导致收敛慢和训练不稳定等问题。因此,我们引入baseline函数$b$来降低梯度估计的方差:
\[\frac{1}{m} \sum_{k=1}^m \sum_{t=1}^T \nabla_{\theta_c} \log P (a_t \mid a_{(t-1):1};\theta_c) (R_k - b) \tag{4}\]只要baseline函数$b$不依赖当前action(即正在被求梯度的那个$a_t$),那么式(4)仍然是对梯度的无偏估计。在本文中,作者将baseline函数$b$设置为之前$R$的EMA。
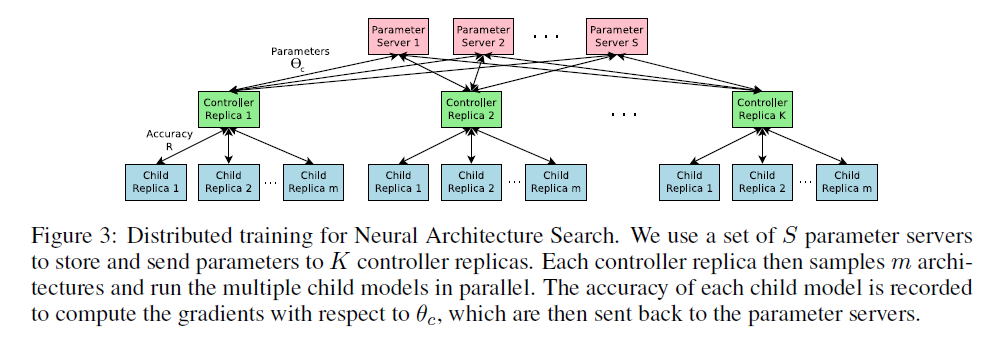
由于NAS需要大量训练许多不同的子网络,而训练一个子网络可能需要数个小时,因此采用分布式训练和异步参数更新的方法来加速控制器的学习过程。具体实现如Fig3所示,控制器的参数$\Theta_c$被切分成$S$份,分别存放在$S$个参数服务器上,$K$个控制器副本共享参数$\Theta_c$,对存放在参数服务器上的参数进行读取或梯度更新。此外,每个控制器副本采样$m$个子网络,这$m$个子网络并行训练,且训练达到一定数量的epoch时,就认为其已收敛。
3.3.INCREASE ARCHITECTURE COMPLEXITY WITH SKIP CONNECTIONS AND OTHER LAYER TYPES
在第3.1部分,我们设置的子网络结构搜索空间并不包含像ResNet或GoogLeNet等现代网络结构常用的skip connection和分支结构。
为了让控制器能够预测这些更复杂的网络结构,我们加入了anchor point,如Fig4所示:
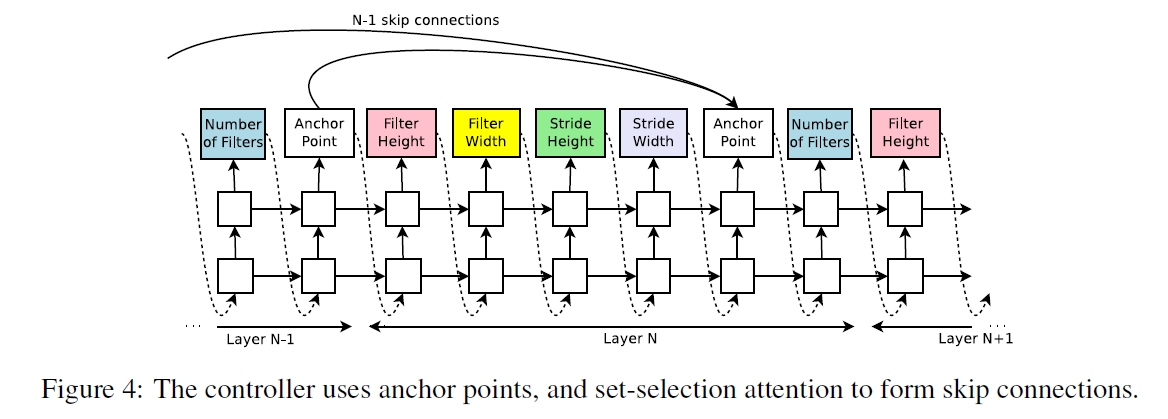
每一层都会插入一个anchor point。我们通过anchor point来判断当前层与之前每一层是否存在连接。
\[P(\text{Layer j is an input to layer i}) = \text{sigmoid} (v^T \tanh (W_{prev} * h_j + W_{curr} * h_i)) \tag{5}\]假设当前层为第$N$层,$h_j$表示控制器在第$j$层anchor point处的hiddenstate(即GRU或LSTM中的$a^{<t>}$),$j$的取值范围为$0$到$N-1$,也就是说会通过式(5)计算从第$0$层到第$N-1$层中的每一层与当前层$N$存在连接的可能性。$h_i$表示当前层$N$在anchor point处的hiddenstate。$W_{prev},W_{curr},v^T$是全局共享的一组可训练参数。
在我们的框架中,如果某一层有多个输入层,那么所有输入层会在通道维度上进行concat。但是skip connection可能会导致一些问题,比如相连接的两层维度不匹配,或者某一层没有任何输入或输出,为了避免这些问题,我们使用如下三个简单技巧:
- 如果某一层没有任何输入层(即前面的层都不与该层存在连接),则使用原始图像作为该层的输入层。
- 如果某一层没有与任何之后的层存在连接,即没有输出层,我们将这些层在anchor point的hiddenstate在最终层一起concat起来,然后作为最终的hiddenstate送入分类器。
- 如果被concat的两层维度不匹配,则用0进行padding。
除此之外,我们还可以让控制器预测学习率、pooling、local contrast normalization、BatchNorm等参数或结构。
3.4.GENERATE RECURRENT CELL ARCHITECTURES
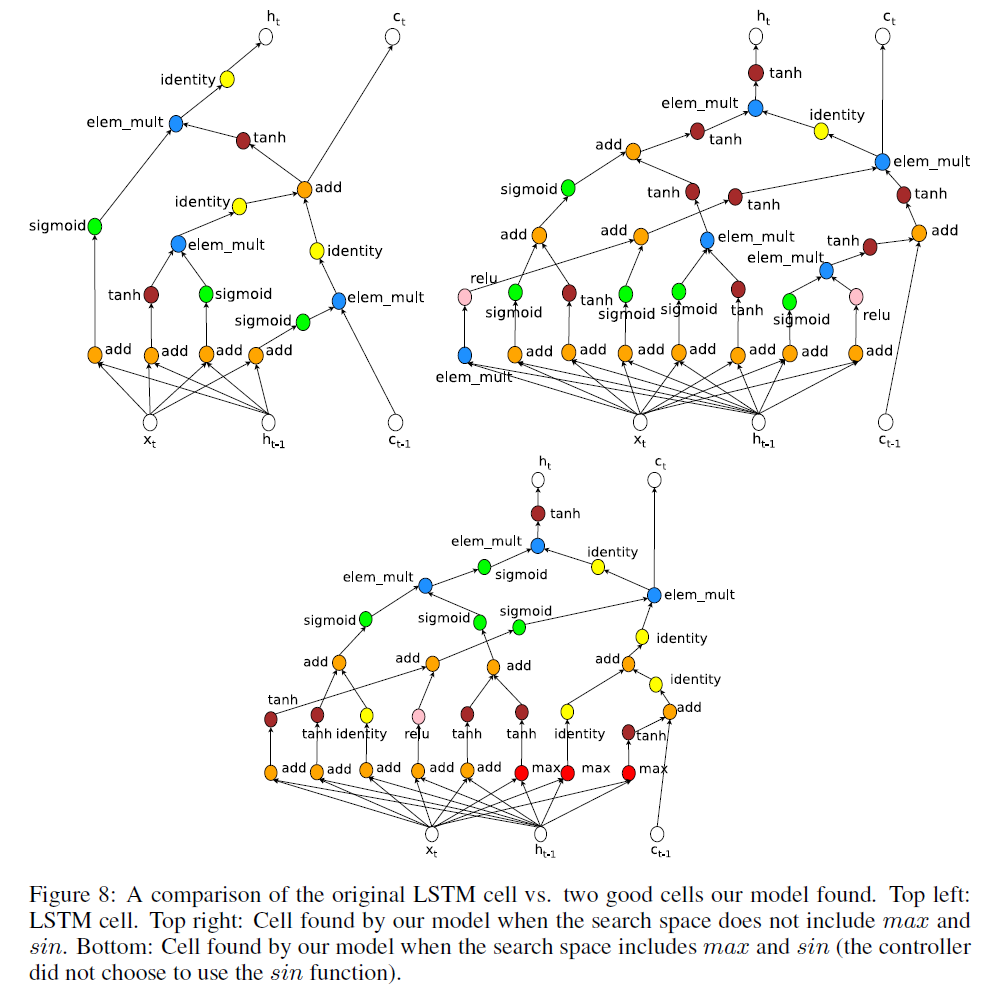
NAS中搜索的子网络除了可以是CNN,也可以是RNN。注意,无论NAS是预测CNN结构还是RNN结构,控制器一直都使用的是基于LSTM的RNN。
其实,NAS搜索的子网络就是像GRU或LSTM这样的RNN结构。如Fig5所示,作者这里用树形结构来表示RNN结构。
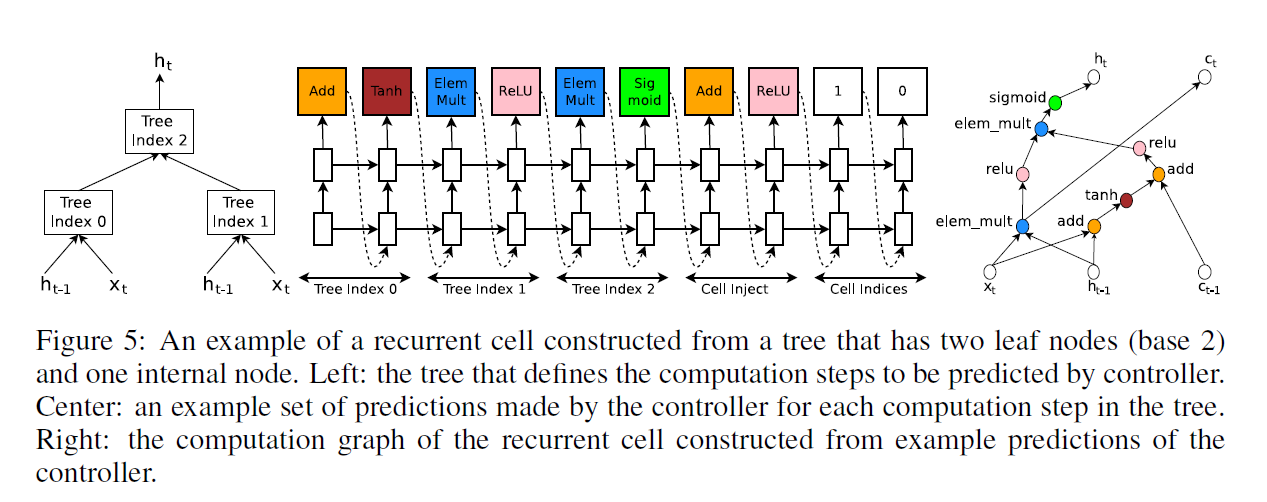
效仿LSTM,子网络预测的RNN结构的输入有$x_t,h_{t-1},c_{t-1}$($h_{t-1}$相当于这里的$a^{<t-1>}$),输出有$c_t,h_t$($h_{t}$相当于这里的$a^{<t>}$)。
Fig5左图定义了子网络所预测的RNN结构,一共有3个节点,先通过两种方式结合$x_t$和$h_{t-1}$,得到Tree Index 0和Tree Index 1,然后将这两个节点再结合得到Tree Index 2,最终输出$h_t$。这个树形结构可以事先定义好,并根据个人需要进行修改扩展。Fig5中间的图展示了控制器预测子网络结构的过程,可以结合Fig5右图一起看,具体解释见下:
-
控制器预测在节点Tree Index 0处,$x_t,h_{t-1}$的结合方式为Add,激活函数为Tanh,其节点输出为:
\[a_0 = \tanh (W_1 * x_t + W_2 * h_{t-1})\] -
控制器预测在节点Tree Index 1处,$x_t,h_{t-1}$的结合方式为ElemMult,激活函数为ReLU,其节点输出为:
\[a_1 = \text{ReLU} ((W_3 * x_t) \odot (W_4 * h_{t-1}))\] -
控制器预测的Cell Indices中的第二个数表示将$c_{t-1}$与哪个节点结合,其预测值范围为Tree Index的范围,本例中为$[0,1,2]$。预测值为0表示将$c_{t-1}$与Tree Index 0节点的输出结合,具体结合方式由Cell Inject预测。综上,有:
\[a_0^{new} = \text{ReLU} (a_0 + c_{t-1})\] -
控制器预测在节点Tree Index 2处,Tree Index 0和Tree Index 1的结合方式为ElemMult,激活函数为Sigmoid,注意此时Tree Index 0的输出已经结合了$c_{t-1}$,因此,最终$h_t$的计算为(因为该树形结构的最大节点编号为2,因此有$h_t=a_2$):
\[a_2 = \text{sigmoid} (a_0^{new} \odot a_1)\] -
控制器预测的Cell Indices中的第一个数表示从哪个节点获得$c_t$,其预测值范围也是Tree Index的范围,本例中为$[0,1,2]$。预测值为1表示$c_t$从Tree Index 1获得,即(注意是在激活函数之前):
\[c_t = (W_3 * x_t) \odot (W_4 * h_{t-1})\]
在Fig5所示的例子中,树形结构有两个叶子节点,因此称其为base2框架。在我们的实验中,我们使用base8框架,以确保RNN有足够的表达能力。
4.EXPERIMENTS AND RESULTS
当子网络为CNN时,我们使用CIFAR-10进行评估。当子网络为RNN时,我们使用Penn Treebank进行评估。
4.1.LEARNING CONVOLUTIONAL ARCHITECTURES FOR CIFAR-10
👉Dataset
首先,对所有图像进行whitening预处理,此外,将每张图像上采样,然后从中随机裁剪一个$32 \times 32$的区域,最后,对裁剪后的$32 \times 32$图像进行随机水平翻转。
👉Search space
使用ReLU激活函数,使用BatchNorm,允许skip connection。对于每一个卷积层,控制器会预测filter height(范围为$[1,3,5,7]$)、filter width(范围为$[1,3,5,7]$)和number of filters(范围为$[24,36,48,64]$)。对于步长,我们有两种策略,第一种策略是固定步长为1,第二种策略是允许控制器预测步长,范围为$[1,2,3]$。
👉Training details
控制器RNN是一个两层LSTM,每层hidden unit(即$h$)的维度是35。使用ADAM优化器,学习率为0.0006。控制器的权重初始化在$[-0.08,0.08]$之间均匀分布。对于第3.2部分提到的分布式训练,参数服务器的数量$S=20$,控制器副本的数量$K=100$,每个控制器副本采样$m=8$个子网络。这意味着同时有800个网络在800个GPU上训练。
个人注解:这里简单解释下,控制器RNN是一个两层的结构,层数的介绍请见:【深度学习基础】第四十四课:深层循环神经网络。此外,每个时间步是共享这个结构和参数的,并不是每个时间步都独占一个两层LSTM。
当控制器RNN预测一个子网络结构后,该子网络会训练50个epoch。最后5个epoch验证准确率的最大值的三次方作为reward,用于更新控制器。从训练集中随机采样5000张图像用于独立的验证集,剩余45000张图像用于训练。子网络在CIFAR-10上的训练设置和此处一样。
在训练过程中,控制器RNN会逐渐增加所预测CNN的层数。预测CNN的初始层数为6层,控制器RNN每采样1600个CNN结构,就将所预测CNN的层数增加2层。
👉Results
一共训练采样了12800个子网络结构,最终选择最高验证集准确率的子网络结构。然后对该子网络进行进一步的优化,首先对学习率、weight decay、batchnorm epsilon、学习率衰减策略等进行小规模的grid search(即对这些参数设置进行进一步的优化),然后训练至收敛,并在测试集上评估。结果见表1。
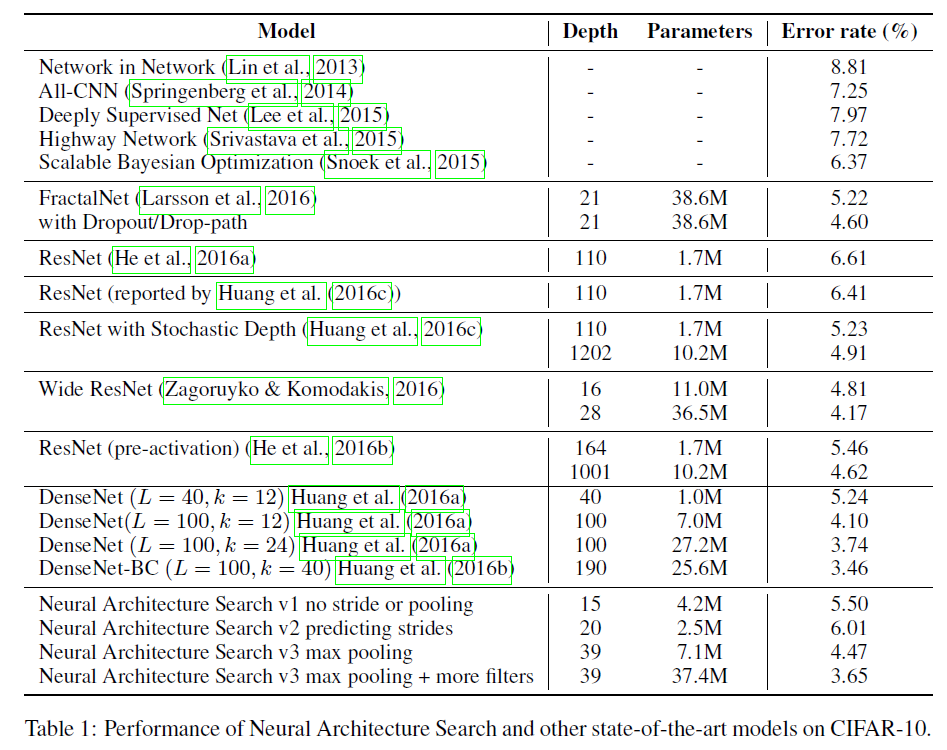
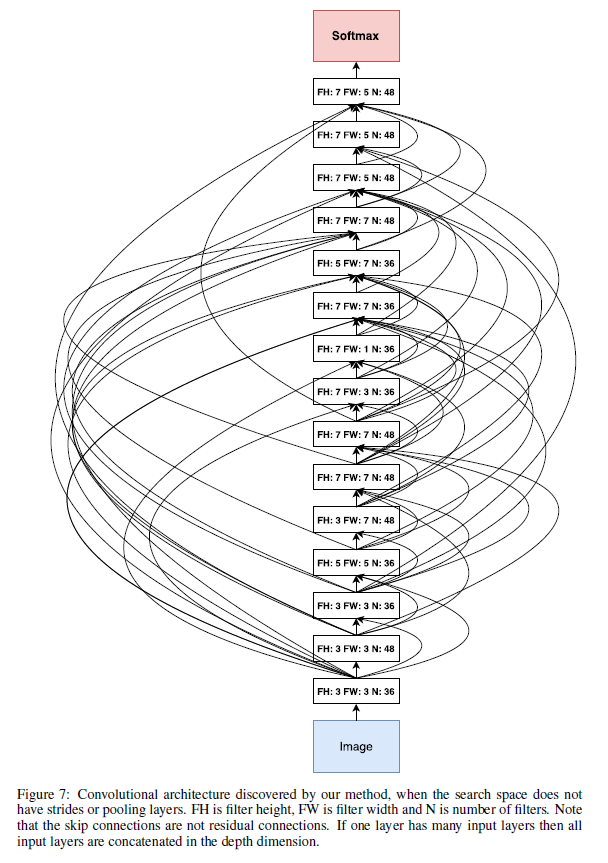
- “Neural Architecture Search v1 no stride or pooling”是让控制器不预测步长和pooling。该CNN结构见Fig7。
- “Neural Architecture Search v2 predicting strides”是允许控制器预测步长。
- “Neural Architecture Search v3 max pooling”是在第13层和第24层添加pooling。
- “Neural Architecture Search v3 max pooling + more filters”是在”Neural Architecture Search v3 max pooling”的基础上,增加每个卷积层的卷积核数量。
4.2.LEARNING RECURRENT CELLS FOR PENN TREEBANK
👉Dataset
Penn Treebank(PTB)数据集是一个广泛使用的语言建模的benchmark。在这个数据集上,LSTM的表现通常优于其他模型,并且进一步提升它们的性能是比较困难的。由于PTB是一个较小的数据集,因此需要使用正则化方法来避免过拟合。首先,我们使用了embedding dropout和recurrent dropout技术。此外,我们还尝试将这些方法与输入/输出embedding共享,使用这种方法会在文中被标记为”shared embeddings”。
👉Search space
按照第3.4部分的方法,控制器会按顺序为树中的每个节点预测一个组合方式和一个激活函数。组合方式的预测范围为$[add, elem\_mult]$,激活函数的预测范围为$[identity,tanh,sigmoid,relu]$。RNN cell的输入对的数量被称为base number,即叶子节点数量,在实验中被设置为8。当base number为8时,整个搜索空间大约包含$6 \times 10^{16}$种不同的框架。
👉Training details
训练过程与CIFAR-10实验基本相同,只是做了一些修改。控制器RNN的学习率设为0.0005。对于分布式训练,参数设置如下:$S=20,K=400,m=1$。这意味着在任何时刻都有400个网络在400个CPU上并行训练。在异步训练中,参数服务器收到多个副本传回的梯度,在累计收到10个梯度时,参数服务器才会对参数进行一次更新,这样更新时可以综合考虑这10个梯度,比如求平均,以降低噪声。
在实验中,每个子网络训练35个epoch。每个子网络都是一个两层RNN。reward函数为:
\[\frac{c}{(\text{validation perplexity})^2}\]其中,$c$是一个常数,通常设为80。perplexity指标的解释可见:Calculating the text generation loss。
在控制器训练完成之后,选择验证集perplexity最低的RNN作为最佳结构。然后对该最佳结构通过grid search来进一步优化其参数,被搜索优化的参数有学习率、权重初始化、dropout rate、decay epoch。
👉Results
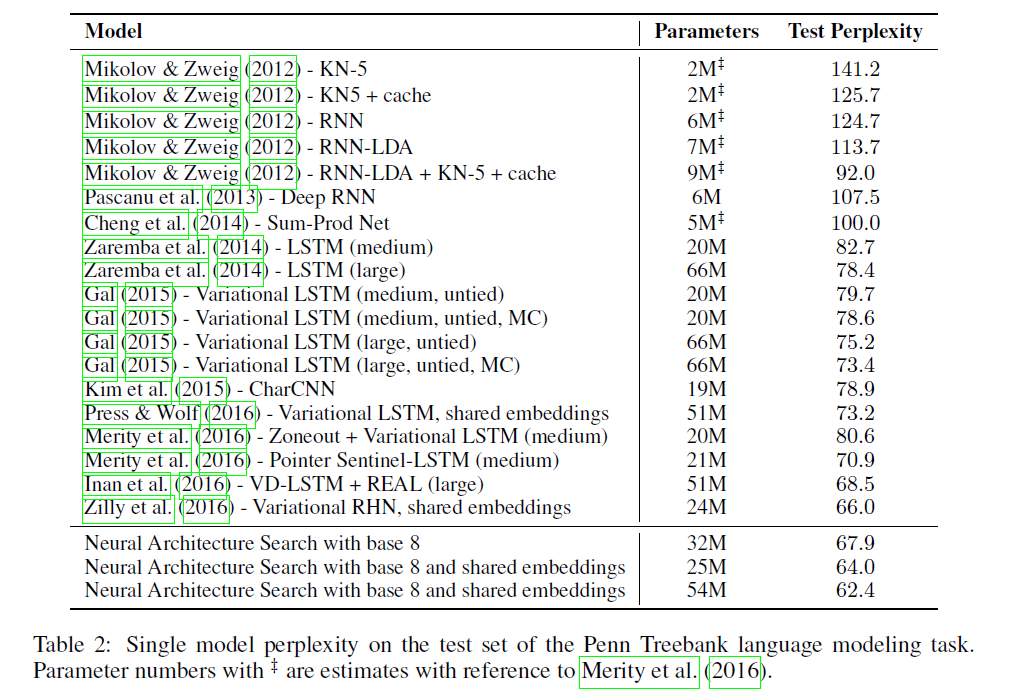
NAS新发现的RNN结构见下:
👉Transfer Learning Results
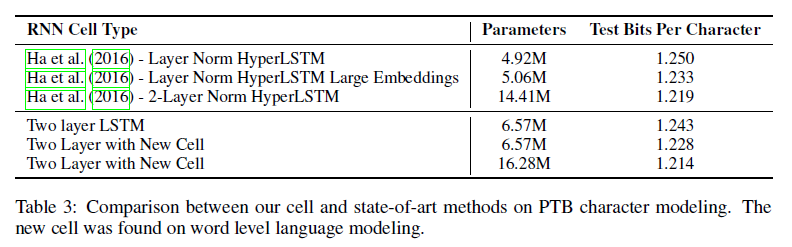
本部分主要验证了NAS所搜索到的RNN结构的泛化性。
👉Control Experiment 1 – Adding more functions in the search space
为了验证NAS的鲁棒性,我们在搜索空间中做了如下扩展:1)在组合函数的列表中加入max;2)在激活函数的列表中加入sin。然后重新运行实验,结果表明,即使搜索空间变得更大,模型仍然能够取得差不多的性能,使用max和sin的最佳结构见Fig8。
👉Control Experiment 2 – Comparison against Random Search
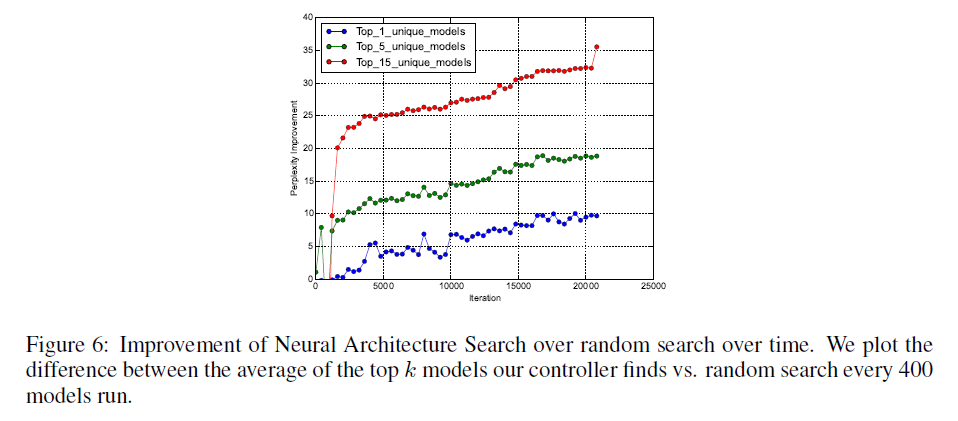
除了使用策略梯度算法(见第3.2部分)之外,也可以使用随机搜索来寻找最优网络结构。在Fig6中,我们展示了随着训练过程推进,使用策略梯度算法相比随机搜索所带来的perplexity改进。
5.CONCLUSION
不再赘述。
